Recognition: unknown
Co-Design of CNN Accelerators for TinyML using Approximate Matrix Decomposition
Pith reviewed 2026-05-10 07:24 UTC · model grok-4.3
The pith
A genetic algorithm applies approximate matrix decomposition to pre-trained CNNs to generate multiplier-less FPGA accelerators that cut inference latency by 33% at 1.3% average accuracy cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose a framework that applies approximate matrix decomposition to a given CNN in order to optimize hardware implementations subject to strict constraints and without any need of re-training or fine-tuning steps. The genetic algorithm-driven framework explores different matrix decompositions and resulting multiplier-less CNN accelerator designs for FPGA targets. A comprehensive evaluation of different TinyML benchmarks demonstrates our framework's efficacy in generating latency-optimized implementations that satisfy strict accuracy and resource constraints, achieving an average 33% latency improvement with an average accuracy loss of 1.3% compared to typical systolic array-based FPGA 0.
What carries the argument
The genetic algorithm that searches over approximate matrix decompositions of CNN weight matrices to produce multiplier-less shift-add accelerator mappings for FPGA.
Where Pith is reading between the lines
- The same decomposition search could be ported to ASIC targets by swapping the FPGA cost model inside the genetic algorithm.
- Decomposition search might extend beyond CNNs to other matrix-dominated layers such as transformers.
- Hybrid use with existing post-training quantization methods could compound the latency gains.
- The approach opens a path to automated accelerator generation for new models as soon as they are trained, without waiting for dataset release.
Load-bearing premise
The genetic algorithm can reliably locate matrix decompositions that keep accuracy within acceptable limits for arbitrary pre-trained CNNs without retraining or training data.
What would settle it
Running the framework on a fresh set of TinyML CNN models and measuring that the generated accelerators deliver less than 20% average latency reduction or more than 3% average accuracy loss relative to systolic-array baselines.
Figures
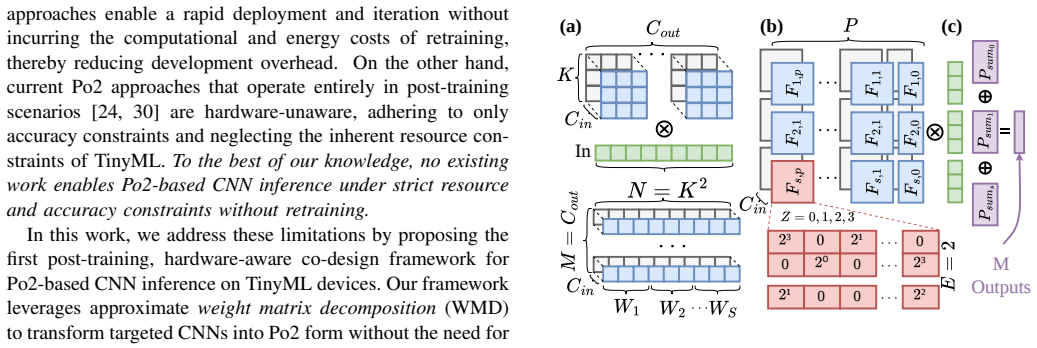






read the original abstract
The paradigm shift towards local and on-device inference under stringent resource constraints is represented by the tiny machine learning (TinyML) domain. The primary goal of TinyML is to integrate intelligence into tiny, low-cost devices under strict resource, energy, and latency constraints. However, the ultra-resource-constrained nature of these devices can lead to increased inference execution time, which can be detrimental in latency critical applications. At the same time, TinyML applications are often associated with sensitive data. As such, latency optimization approaches that rely on training samples are infeasible when such data is unavailable, proprietary, or sensitive, highlighting a pressing need for optimization approaches that do not require access to the training dataset and can be applied directly to pre-trained models. Replacing costly multiplications with more hardware-efficient operations, such as shifts and additions, has been proposed as an effective method for reducing inference latency. However, post-training power-of-two (Po2) approaches are scarce and, in many cases, lead to unacceptable accuracy loss. In this work, we propose a framework that applies approximate matrix decomposition to a given CNN in order to optimize hardware implementations subject to strict constraints and without any need of re-training or fine-tuning steps. The genetic algorithm-driven framework explores different matrix decompositions and resulting multiplier-less CNN accelerator designs for FPGA targets. A comprehensive evaluation of different TinyML benchmarks demonstrates our framework's efficacy in generating latency-optimized implementations that satisfy strict accuracy and resource constraints, achieving an average 33% latency improvement with an average accuracy loss of 1.3% compared to typical systolic array-based FPGA accelerators.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a genetic algorithm-based framework for co-designing CNN accelerators on FPGAs for TinyML by applying approximate matrix decompositions to pre-trained models. This replaces multiplications with shifts and additions in a post-training, dataset-free manner to reduce inference latency under strict resource constraints. The central claim is that the approach yields latency-optimized designs satisfying accuracy and resource limits, with an average 33% latency improvement and 1.3% accuracy loss versus typical systolic-array FPGA baselines across TinyML benchmarks.
Significance. If the reported empirical outcomes are substantiated with full experimental details, the work would contribute meaningfully to TinyML hardware acceleration by demonstrating a viable dataset-free optimization path that respects privacy constraints common in edge deployments. The co-design of approximation choices with FPGA mapping via GA search is a targeted strength for multiplierless implementations.
major comments (2)
- [Evaluation / Results section (and abstract)] The central empirical claim (33% latency gain, 1.3% accuracy loss) is presented without any description of the TinyML benchmarks, the accuracy metric, statistical significance, number of runs, or the precise baseline systolic-array FPGA implementation (e.g., array dimensions, clock frequency, or resource utilization). This information is load-bearing for assessing whether the numbers support the efficacy claim across benchmarks.
- [Framework / Genetic Algorithm description (likely §3)] The genetic algorithm's fitness function and accuracy-preservation mechanism are insufficiently specified to support the post-training, dataset-free claim. Because no training data or fine-tuning is used, the proxy for accuracy (e.g., reconstruction error or held-out samples) must be shown to generalize; without this, it is unclear whether the GA reliably discovers decompositions that maintain acceptable accuracy for arbitrary pre-trained CNNs.
minor comments (2)
- [Abstract] The abstract refers to 'typical systolic array-based FPGA accelerators' without defining the reference architecture parameters.
- [Throughout manuscript] Ensure consistent definition of acronyms (CNN, FPGA, TinyML, Po2) on first use and clarify any notation for matrix decomposition factors.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will revise the manuscript to provide the requested clarifications and details.
read point-by-point responses
-
Referee: [Evaluation / Results section (and abstract)] The central empirical claim (33% latency gain, 1.3% accuracy loss) is presented without any description of the TinyML benchmarks, the accuracy metric, statistical significance, number of runs, or the precise baseline systolic-array FPGA implementation (e.g., array dimensions, clock frequency, or resource utilization). This information is load-bearing for assessing whether the numbers support the efficacy claim across benchmarks.
Authors: We agree that these experimental details are necessary to substantiate the reported results. In the revised manuscript, we will expand the Evaluation section to explicitly list the TinyML benchmarks (specific CNN models and tasks), define the accuracy metric used, report the number of runs and any statistical measures, and provide full specifications of the baseline systolic-array FPGA implementation including array dimensions, clock frequency, and resource utilization. These additions will also be referenced in the abstract where appropriate. revision: yes
-
Referee: [Framework / Genetic Algorithm description (likely §3)] The genetic algorithm's fitness function and accuracy-preservation mechanism are insufficiently specified to support the post-training, dataset-free claim. Because no training data or fine-tuning is used, the proxy for accuracy (e.g., reconstruction error or held-out samples) must be shown to generalize; without this, it is unclear whether the GA reliably discovers decompositions that maintain acceptable accuracy for arbitrary pre-trained CNNs.
Authors: We acknowledge the need for a more precise description of the GA components to support the dataset-free approach. We will revise the framework section to explicitly define the fitness function (which incorporates hardware latency and resource estimates along with a reconstruction error proxy derived from the approximate matrix decomposition) and elaborate on the accuracy-preservation mechanism. The revision will include discussion of how the reconstruction error serves as a generalizable proxy for the pre-trained models evaluated. revision: yes
Circularity Check
No circularity: empirical GA search results are not derived by construction
full rationale
The paper describes a genetic-algorithm framework that searches for approximate matrix decompositions to produce multiplier-less CNN accelerators. The headline performance numbers (average 33% latency reduction, 1.3% accuracy loss) are reported as outcomes of running that search on a set of TinyML benchmarks; they are not obtained by fitting parameters to the same quantities being predicted, nor by any self-referential equation or uniqueness theorem imported from the authors' prior work. No load-bearing self-citation chain, ansatz smuggled via citation, or renaming of a known result appears in the provided abstract or described method. The derivation chain is therefore self-contained as an empirical optimization procedure.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
OLLA: Optimizing the lifetime and location of arrays to reduce the memory usage of neural networks,
B. Steiner, M. Elhoushi, J. Kahn, and J. Hegarty, “OLLA: Optimizing the lifetime and location of arrays to reduce the memory usage of neural networks,”The Computing Research Repository (CoRR), 2022. arXiv: 2210.12924[cs.LG]
-
[2]
Scaling for edge inference of deep neural networks,
X. Xu, Y . Ding, S. X. Hu, M. Niemier, J. Cong, Y . Hu, and Y . Shi, “Scaling for edge inference of deep neural networks,”Nature Electron- ics, vol. 1, no. 4, pp. 216–222, 2018.DOI: 10.1038/s41928-018-0059-3
-
[3]
TinyML design contest for life-threatening ventricular arrhythmia detection,
Z. Jia, D. Li, C. Liu, L. Liao, X. Xu, L. Ping, and Y . Shi, “TinyML design contest for life-threatening ventricular arrhythmia detection,” IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems (TCAD), vol. 43, no. 1, pp. 127–140, 2024.DOI: 10.1109/ TCAD.2023.3309744
-
[4]
A. B. Nassif, M. A. Talib, Q. Nasir, and F. M. Dakalbab, “Machine learning for anomaly detection: A systematic review,”IEEE Access, vol. 9, pp. 78 658–78 700, 2021.DOI: 10.1109/ACCESS.2021.3083060
-
[5]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp
J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, “You only look once: Unified, real-time object detection,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (Las Vegas, NV , USA), IEEE, 2016, pp. 779–788.DOI: 10.1109/CVPR.2016. 91
-
[6]
Accessed: Mar
STMicroelectronics,X-CUBE-AI – artificial intelligence (AI) soft- ware expansion for STM32CubeMX, https://www.st.com/en/embedded- software/x-cube-ai.html, version DB3788 – Rev 11, 2024. Accessed: Mar. 28, 2026
2024
-
[7]
CMSIS-NN: Efficient neural network kernels for ARM Cortex-M CPUs,
L. Lai, N. Suda, and V . Chandra, “CMSIS-NN: Efficient neural network kernels for Arm Cortex-M CPUs,”The Computing Research Repository (CoRR), 2018. arXiv: 1801.06601[cs.NE]
-
[8]
Available: https://doi.org/10.48550/arXiv.1802.04799
T. Chen et al., “TVM: An automated end-to-end optimizing compiler for deep learning,”The Computing Research Repository (CoRR), 2018. arXiv: 1802.04799[cs.LG]
-
[9]
MCUNet: Tiny deep learning on IoT devices,
J. Lin, W. Chen, Y . Lin, J. Cohn, C. Gan, and S. Han, “MCUNet: Tiny deep learning on IoT devices,” inProceedings of the 34th International Conference on Neural Information Processing Systems (NeurIPS), (Vancouver, Canada), H. Larochelle, M. Ranzato, R. Hadsell, M. Bal- can, and H. Lin, Eds., Curran Associates Inc., 2020, pp. 11 711–11 722
2020
-
[10]
In2025 IEEE/ACM International Conference On Computer Aided Design (ICCAD)
G. Mentzos, V . A. Frey, K. Balaskas, G. Zervakis, and J. Henkel, “R2T-Tiny: Runtime-reconfigurable throughput-optimized TinyML for hybrid inference acceleration on FPGA SoCs,” inProceedings of the IEEE/ACM International Conference on Computer Aided Design (IC- CAD), (Munich, Germany), IEEE, 2025, pp. 1–9.DOI: 10 . 1109 / ICCAD66269.2025.11240939
-
[11]
Transformer Based Intrusion Detection for IoT Networks
L. Lamberti, L. Bellone, L. Macan, E. Natalizio, F. Conti, D. Palossi, and L. Benini, “Distilling tiny and ultrafast deep neural networks for autonomous navigation on nano-UA Vs,”IEEE Internet of Things Journal, vol. 11, no. 20, pp. 33 269–33 281, 2024.DOI: 10.1109/JIOT. 2024.3431913
-
[12]
HFL: Hardware Fuzzing Loop with Reinforce- ment Learning,
C. Turetta, M. Toqeer Ali, F. Demrozi, and G. Pravadelli, “A lightweight CNN for real-time pre-impact fall detection,” inProceedings of the Conference on Design, Automation and Test in Europe (DATE), (Lyon, France), 2025, pp. 1–7.DOI: 10.23919/DATE64628.2025.10993022
-
[13]
MLPerf Tiny Benchmark,
C. R. Banbury et al., “MLPerf Tiny Benchmark,” inProceedings of the Neural Information Processing Systems Track on Datasets and Bench- marks, J. Vanschoren and S. Yeung, Eds., 2021. [Online]. Available: https://datasets-benchmarks-proceedings.neurips.cc/paper/2021/hash/ da4fb5c6e93e74d3df8527599fa62642-Abstract-round1.html
2021
-
[14]
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam, “MobileNets: Efficient convolu- tional neural networks for mobile vision applications,”The Computing Research Repository (CoRR), 2017. arXiv: 1704.04861v1[cs.CV]
work page internal anchor Pith review arXiv 2017
-
[15]
Deep residual learning for image recognition
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (Las Vegas, NV , USA), IEEE, 2016, pp. 770–778.DOI: 10.1109/CVPR.2016.90
-
[16]
F. N. Iandola, S. Han, M. W. Moskewicz, K. Ashraf, W. J. Dally, and K. Keutzer, “SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and<0.5MB model size,”The Computing Research Repos- itory (CoRR), 2016. arXiv: 1602.07360[cs.CV]
-
[17]
S. Han, H. Mao, and W. J. Dally, “Deep compression: Compressing deep neural networks with pruning, trained quantization and Huffman coding,”The Computing Research Repository (CoRR), 2016. arXiv: 1510.00149[cs.CV]
work page internal anchor Pith review arXiv 2016
-
[18]
A. Garofalo, G. Tagliavini, F. Conti, L. Benini, and D. Rossi, “XpulpNN: Enabling energy efficient and flexible inference of quan- tized neural networks on RISC-V based IoT end nodes,”IEEE Transac- tions on Emerging Topics in Computing, vol. 9, no. 3, pp. 1489–1505, 2021.DOI: 10.1109/TETC.2021.3072337
-
[19]
Optimizing structured-sparse matrix multiplication in RISC-V vector processors,
V . Titopoulos, K. Alexandridis, C. Peltekis, C. Nicopoulos, and G. Dim- itrakopoulos, “Optimizing structured-sparse matrix multiplication in RISC-V vector processors,”IEEE Transactions on Computers, vol. 74, no. 4, pp. 1446–1460, 2025.DOI: 10.1109/TC.2025.3533083
-
[20]
FracBNN: Accurate and FPGA-efficient binary neural networks with fractional ac- tivations,
Y . Zhang, J. Pan, X. Liu, H. Chen, D. Chen, and Z. Zhang, “FracBNN: Accurate and FPGA-efficient binary neural networks with fractional ac- tivations,” inProceedings of the ACM/SIGDA International Symposium on Field-Programmable Gate Arrays (FPGA), (Virtual Event, USA), ACM, 2021, pp. 171–182.DOI: 10.1145/3431920.3439296
-
[21]
Hassan, David Lo, and Shanping Li
E. Wang, J. J. Davis, P. Y . K. Cheung, and G. A. Constantinides, “LUTNet: Learning FPGA configurations for highly efficient neural network inference,”IEEE Transactions on Computers, vol. 69, no. 12, pp. 1795–1808, 2020.DOI: 10.1109/TC.2020.2978817
-
[22]
FINN: A framework for fast, scalable bina- rized neural network inference,
Y . Umuroglu, N. J. Fraser, G. Gambardella, M. Blott, P. Leong, M. Jahre, and K. Vissers, “FINN: A framework for fast, scalable bina- rized neural network inference,” inProceedings of the ACM/SIGDA International Symposium on Field-Programmable Gate Arrays (FPGA), (Monterey, CA, USA), ACM, 2017, pp. 65–74.DOI: 10.1145/3020078. 3021744
-
[23]
ShiftAddNet: A hardware-inspired deep network,
H. You, X. Chen, Y . Zhang, C. Li, S. Li, Z. Liu, Z. Wang, and Y . Lin, “ShiftAddNet: A hardware-inspired deep network,” inProceedings of the 34th International Conference on Neural Information Processing Systems (NeurIPS), (Vancouver, Canada), vol. 33, Curran Associates, Inc., 2020, pp. 2771–2783. [Online]. Available: https : / / proceedings . neurips . ...
2020
-
[24]
A. Lehnert, P. Holzinger, S. Pfenning, R. M ¨uller, and M. Reichenbach, “Most resource efficient matrix vector multiplication on FPGAs,”IEEE Access, vol. 11, pp. 3881–3898, 2023.DOI: 10.1109/ACCESS.2023. 3234622
-
[25]
Linear computa- tion coding for convolutional neural networks,
R. R. M ¨uller, H. Rosenberger, and M. Reichenbach, “Linear computa- tion coding for convolutional neural networks,” inProceedings of the IEEE Statistical Signal Processing Workshop (SSP), (Hanoi, Vietnam), IEEE, 2023, pp. 562–565.DOI: 10.1109/SSP53291.2023.10207943
-
[26]
Developing real-time streaming transformer transducer for speech recognition on large-scale dataset
R. R. M ¨uller, B. G ¨ade, and A. Bereyhi, “Linear computation coding,” inProceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), (Toronto, Canada), IEEE, 2021, pp. 5065–5069.DOI: 10.1109/ICASSP39728.2021.9414317
-
[27]
Hinet: Half instance normalization network for image restoration
M. Elhoushi, Z. Chen, F. Shafiq, Y . H. Tian, and J. Y . Li, “DeepShift: Towards multiplication-less neural networks,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), (Virtual Event), IEEE, 2021, pp. 2359–2368. DOI: 10.1109/CVPRW53098.2021.00268
-
[28]
Incremental network quantization: Towards lossless CNNs with low-precision weights,
A. Zhou, A. Yao, Y . Guo, L. Xu, and Y . Chen, “Incremental network quantization: Towards lossless CNNs with low-precision weights,” in Proceedings of the International Conference on Learning Representa- tions (ICLR), (Toulon, France), OpenReview.net, 2017
2017
-
[29]
S. Aanjankumar, M. K. Muchahari, S. Urooj, I. Kaur, R. K. Dhanaraj, H. A. Mengash, S. Poonkuntran, and P. R. Kaveri, “Enhanced consumer healthcare data protection through AI-driven TinyML and privacy- preserving techniques,”IEEE Access, vol. 13, pp. 97 428–97 440, 2025. DOI: 10.1109/ACCESS.2025.3573076
-
[30]
ShiftCNN: Generalized low-precision architecture for inference of convolutional neural networks,
D. A. Gudovskiy and L. Rigazio, “ShiftCNN: Generalized low-precision architecture for inference of convolutional neural networks,”The Computing Research Repository (CoRR), 2017. arXiv: 1706 . 02393 [cs.CV]
2017
-
[31]
Eyeriss v2: A flexible accelerator for emerging deep neural networks on mobile devices,
Y .-H. Chen, T.-J. Yang, J. Emer, and V . Sze, “Eyeriss v2: A flexible accelerator for emerging deep neural networks on mobile devices,” IEEE Journal on Emerging and Selected Topics in Circuits and Systems, vol. 9, no. 2, pp. 292–308, 2019.DOI: 10.1109/JETCAS.2019.2910232
-
[32]
In-datacenter performance analysis of a tensor processing unit,
N. P. Jouppi et al., “In-datacenter performance analysis of a tensor processing unit,” inProceedings of the 44th Annual International Sym- posium on Computer Architecture (ISCA), (Toronto, Canada), ACM, 2017, pp. 1–12.DOI: 10.1145/3079856.3080246
-
[33]
Accessed: Mar
Arm,Arm® Ethos™-U55 NPU Technical Reference Manual, ver- sion r2p0, 2022. Accessed: Mar. 28, 2026. [Online]. Available: https: //developer.arm.com/Processors/Ethos-U55
2022
-
[34]
W. S. Ng, W. Ling Goh, and Y . Gao, “High accuracy and low latency mixed precision neural network acceleration for TinyML applications on resource-constrained FPGAs,” inProceedings of the IEEE Interna- tional Symposium on Circuits and Systems (ISCAS), (Singapore), 2024, pp. 1–5.DOI: 10.1109/ISCAS58744.2024.10558440
-
[35]
ShiftAddLLM: Accelerating pretrained LLMs via post-training multiplication-less reparameterization,
H. You, Y . Guo, Y . Fu, W. Zhou, H. Shi, X. Zhang, S. Kundu, A. Yazdanbakhsh, and Y . C. Lin, “ShiftAddLLM: Accelerating pretrained LLMs via post-training multiplication-less reparameterization,”The Computing Research Repository (CoRR), 2024. arXiv: 2406 . 05981 [cs.LG]
2024
- [36]
-
[37]
J. Blank and K. Deb, “Pymoo: Multi-objective optimization in Python,” IEEE Access, vol. 8, pp. 89 497–89 509, 2020.DOI: 10.1109/ACCESS. 2020.2990567
-
[38]
A survey of quantization methods for efficient neural network inference,
A. Gholami, S. Kim, Z. Dong, Z. Yao, M. W. Mahoney, and K. Keutzer, “A survey of quantization methods for efficient neural network inference,” inLow-Power Computer Vision: Improve the Efficiency of Artificial Intelligence, G. Thiruvathukal, Y .-H. Lu, J. Kim, Y . Chen, and B. Chen, Eds., Chapman and Hall/CRC, 2022, pp. 291–326.DOI: 10.1201/9781003162810 11
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.