Recognition: unknown
Towards In-Context Tone Style Transfer with A Large-Scale Triplet Dataset
Pith reviewed 2026-05-10 08:19 UTC · model grok-4.3
The pith
A scorer-curated dataset of 100,000 triplets and a jointly conditioned diffusion model enable in-context tone style transfer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that a data-construction pipeline using a tone style scorer produces a usable 100,000-triplet dataset and that feeding both content and reference images jointly into a diffusion model, together with reward feedback from the same scorer, yields tone transfers with higher stylistic fidelity and visual quality than prior separate-feature approaches.
What carries the argument
The tone style scorer that enforces triplet consistency and the in-context joint-conditioning mechanism inside the diffusion model that leverages generative semantic priors.
Load-bearing premise
The tone style scorer can reliably enforce strict stylistic consistency across all 100,000 triplets without introducing systematic biases or artifacts that affect downstream model training.
What would settle it
An independent audit that finds a substantial fraction of the TST100K triplets lack matching tone styles between the reference and the stylized ground truth would falsify the dataset quality claim and the resulting performance gains.
Figures













read the original abstract
Tone style transfer for photo retouching aims to adapt the stylistic tone of the reference image to a given content image. However, the lack of high-quality large-scale triplet datasets with stylized ground truth forces existing methods to rely on self-supervised or proxy objectives, which limits model capability. To mitigate this gap, we design a data construction pipeline to build TST100K, a large-scale dataset of 100,000 content-reference-stylized triplets. At the core of this pipeline, we train a tone style scorer to ensure strict stylistic consistency for each triplet. In addition, existing methods typically extract content and reference features independently and then fuse them in a decoder, which may cause semantic loss and lead to inappropriate color transfer and degraded visual aesthetics. Instead, we propose ICTone, a diffusion-based framework that performs tone transfer in an in-context manner by jointly conditioning on both images, leveraging the semantic priors of generative models for semantic-aware transfer. Reward feedback learning using the tone style scorer is further incorporated to improve stylistic fidelity and visual quality. Experiments demonstrate the effectiveness of TST100K, and ICTone achieves state-of-the-art performance on both quantitative metrics and human evaluations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TST100K, a dataset of 100,000 content-reference-stylized triplets for tone style transfer constructed via a data pipeline centered on a trained tone style scorer that enforces stylistic consistency. It proposes ICTone, a diffusion-based model performing in-context tone transfer through joint conditioning on content and reference images, augmented by reward feedback learning with the scorer, and reports state-of-the-art results on quantitative metrics and human evaluations.
Significance. If the central claims hold, the work supplies a large-scale supervised dataset that could shift tone style transfer from self-supervised proxies to direct triplet training, while the joint-conditioning diffusion approach and reward mechanism offer a concrete way to leverage generative priors for semantic-aware color transfer and improved aesthetics. The dataset construction itself would be a reusable contribution if its quality is independently verified.
major comments (2)
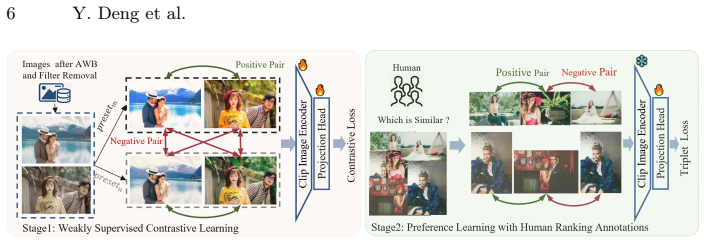
- [Data Construction Pipeline] Data Construction Pipeline (abstract and §3): the tone style scorer is load-bearing for both TST100K quality and the reward signal in ICTone, yet the manuscript provides no architecture details, training procedure, held-out accuracy, or human correlation study to confirm it produces triplets with genuine stylistic consistency rather than scorer-induced artifacts (e.g., palette bias or edge-case failures). Without these, the SOTA claims rest on an unvalidated component.
- [Experiments] Experiments section: the abstract asserts SOTA on quantitative metrics and human evaluations, but supplies no numerical values, baseline tables, or ablation results isolating the contributions of TST100K, joint conditioning, and reward feedback. This prevents assessment of whether the reported gains are attributable to the proposed method or to post-hoc selection.
minor comments (1)
- [Abstract] The abstract would be clearer if it included at least one key quantitative result (e.g., PSNR or LPIPS delta) to ground the SOTA claim.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. We address each major comment below and will revise the manuscript accordingly to improve clarity and completeness.
read point-by-point responses
-
Referee: [Data Construction Pipeline] Data Construction Pipeline (abstract and §3): the tone style scorer is load-bearing for both TST100K quality and the reward signal in ICTone, yet the manuscript provides no architecture details, training procedure, held-out accuracy, or human correlation study to confirm it produces triplets with genuine stylistic consistency rather than scorer-induced artifacts (e.g., palette bias or edge-case failures). Without these, the SOTA claims rest on an unvalidated component.
Authors: We agree that additional details on the tone style scorer are essential for validating the dataset construction and reward mechanism. In the revised manuscript, we will expand §3 to include the scorer's network architecture, training procedure and hyperparameters, held-out accuracy on a validation set, and results from a human study measuring correlation with stylistic consistency judgments. These additions will directly address concerns regarding potential artifacts and strengthen the foundation for the reported results. revision: yes
-
Referee: [Experiments] Experiments section: the abstract asserts SOTA on quantitative metrics and human evaluations, but supplies no numerical values, baseline tables, or ablation results isolating the contributions of TST100K, joint conditioning, and reward feedback. This prevents assessment of whether the reported gains are attributable to the proposed method or to post-hoc selection.
Authors: We acknowledge that the current presentation of results lacks the explicit numerical tables and ablations needed for full assessment. We will revise the Experiments section to include detailed quantitative tables comparing against baselines, with specific metric values, as well as ablation studies that isolate the effects of TST100K, joint conditioning, and the reward feedback component. This will allow readers to evaluate the source of performance gains and support the state-of-the-art claims more rigorously. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes an empirical pipeline: constructing TST100K via a tone style scorer, then training ICTone (diffusion model with joint conditioning and reward feedback from the same scorer) and reporting SOTA on metrics plus human evals. No equations, derivations, or predictions are presented that reduce by construction to fitted inputs or self-citations. The scorer is used for data filtering and reward, but performance claims rest on external benchmarks and human judgment rather than internal self-consistency loops. This matches the default expectation of a non-circular ML paper whose results are falsifiable outside its own fitted values.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Afifi, M., Brown, M.S.: Deep white-balance editing. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 1397–1406 (2020)
2020
-
[2]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
An, J., Huang, S., Song, Y., Dou, D., Liu, W., Luo, J.: Artflow: Unbiased im- age style transfer via reversible neural flows. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 862–871 (2021)
2021
-
[3]
In: Proceedings of the AAAI Conference on Artificial Intelligence
An, J., Xiong, H., Huan, J., Luo, J.: Ultrafast photorealistic style transfer via neural architecture search. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 34, pp. 10443–10450 (2020)
2020
-
[4]
In: European Conference on Computer Vision
Bossard, L., Guillaumin, M., Gool, L.V.: Food-101 – mining discriminative com- ponents with random forests. In: European Conference on Computer Vision. pp. 446–461. Springer (2014)
2014
-
[5]
In: CVPR 2011
Bychkovsky, V., Paris, S., Chan, E., Durand, F.: Learning photographic global tonal adjustment with a database of input/output image pairs. In: CVPR 2011. pp. 97–104. IEEE (2011)
2011
-
[6]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Chen, H., Wang, Z., Yang, Y., Sun, Q., Ma, K.: Learning a deep color difference metric for photographic images. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 22242–22251 (2023)
2023
-
[7]
In: Proceedings of the IEEE/CVF winter conference on applications of computer vision
Chiu, T.Y., Gurari, D.: Photowct2: Compact autoencoder for photorealistic style transfer resulting from blockwise training and skip connections of high-frequency residuals. In: Proceedings of the IEEE/CVF winter conference on applications of computer vision. pp. 2868–2877 (2022)
2022
-
[8]
In: Forty-first international conference on machine learning (2024)
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transformers for high-resolution image synthesis. In: Forty-first international conference on machine learning (2024)
2024
-
[9]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Gatys, L.A., Ecker, A.S., Bethge, M.: Image style transfer using convolutional neural networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 2414–2423 (2016)
2016
-
[10]
John Wiley & Sons (2012)
Gevers, T., Gijsenij, A., Van de Weijer, J., Geusebroek, J.M.: Color in computer vision: fundamentals and applications. John Wiley & Sons (2012)
2012
-
[11]
arXiv preprint arXiv:2506.13465 (2025)
Gong, Z., Wu, Z., Tao, Q., Li, Q., Loy, C.C.: Sa-lut: spatial adaptive 4d look-up table for photorealistic style transfer. arXiv preprint arXiv:2506.13465 (2025)
-
[12]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Ho, M.M., Zhou, J.: Deep preset: Blending and retouching photos with color style transfer. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 2113–2121 (2021)
2021
-
[13]
ICLR1(2), 3 (2022)
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: Lora: Low-rank adaptation of large language models. ICLR1(2), 3 (2022)
2022
-
[14]
In: European Conference on Computer Vision
Johnson, J., Alahi, A., Fei-Fei, L.: Perceptual losses for real-time style transfer and super-resolution. In: European Conference on Computer Vision. pp. 694–711. Springer (2016)
2016
-
[15]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Ke, Z., Liu, Y., Zhu, L., Zhao, N., Lau, R.W.: Neural preset for color style trans- fer. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 14173–14182 (2023)
2023
-
[16]
Advances in neural information processing systems33, 18661–18673 (2020) 16 Y
Khosla, P., Teterwak, P., Wang, C., Sarna, A., Tian, Y., Isola, P., Maschinot, A., Liu, C., Krishnan, D.: Supervised contrastive learning. Advances in neural information processing systems33, 18661–18673 (2020) 16 Y. Deng et al
2020
-
[17]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops
Kinli, F., Ozcan, B., Kirac, F.: Instagram filter removal on fashionable images. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops. pp. 736–745 (June 2021)
2021
-
[18]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Larchenko, M., Lobashev, A., Guskov, D., Palyulin, V.V.: Color transfer with mod- ulated flows. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 4464–4472 (2025)
2025
-
[19]
In: The Fourteenth International Conferenceon LearningRepresentations(2026),https://openreview.net/forum? id=AyJPSnE1bq
Li, D., Wu, T., Lin, B., Chen, Z., Zhang, Y., Li, Y., Cheng, M.M., Li, X.: WOW- seg: A word-free open world segmentation model. In: The Fourteenth International Conferenceon LearningRepresentations(2026),https://openreview.net/forum? id=AyJPSnE1bq
2026
-
[20]
arXiv preprint arXiv:2507.01926 (2025)
Li, Y., Li, X., Zhang, Z., Bian, Y., Liu, G., Li, X., Xu, J., Hu, W., Liu, Y., Li, L., et al.: Ic-custom: Diverse image customization via in-context learning. arXiv preprint arXiv:2507.01926 (2025)
-
[21]
Advances in neural information processing systems30(2017)
Li,Y.,Fang,C.,Yang,J.,Wang,Z.,Lu,X.,Yang,M.H.:Universalstyletransfervia feature transforms. Advances in neural information processing systems30(2017)
2017
-
[22]
In: European Conference on Computer Vision
Li, Y., Liu, M.Y., Li, X., Yang, M.H., Kautz, J.: A closed-form solution to pho- torealistic image stylization. In: European Conference on Computer Vision. pp. 453–468 (2018)
2018
-
[23]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Liang, J., Zeng, H., Cui, M., Xie, X., Zhang, L.: Ppr10k: A large-scale portrait photo retouching dataset with human-region mask and group-level consistency. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 653–661 (2021)
2021
-
[24]
In: European Conference on Computer Vision
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft COCO: Common objects in context. In: European Conference on Computer Vision. pp. 740–755. Springer (2014)
2014
-
[25]
Jarvisart: Liberating human artistic creativity via an intelligent photo retouching agent
Lin, Y., Lin, Z., Lin, K., Bai, J., Pan, P., Li, C., Chen, H., Wang, Z., Ding, X., Li, W., Yan, S.: Jarvisart: Liberating human artistic creativity via an intelligent photo retouching agent. arXiv preprint arXiv:2506.17612 (2025)
-
[26]
arXiv e-prints pp
Liu,R.,Zhao,E.,Liu,Z.,Feng,A.,Easley,S.J.:Universalphotorealisticstyletrans- fer: A lightweight and adaptive approach. arXiv e-prints pp. arXiv–2309 (2023)
2023
-
[27]
In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition
Luan, F., Paris, S., Shechtman, E., Bala, K.: Deep photo style transfer. In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4990–4998 (2017)
2017
-
[28]
Luo, M.R., Cui, G., Rigg, B.: The development of the cie 2000 colour-difference for- mula: Ciede2000. Color Research & Application: Endorsed by Inter-Society Color Council, The Colour Group (Great Britain), Canadian Society for Color, Color Science Association of Japan, Dutch Society for the Study of Color, The Swedish Colour Centre Foundation, Colour Soc...
2000
-
[29]
ACM Transactions on Multimedia Computing, Communications and Applications 20(8), 1–29 (2024)
Lv, C., Zhang, D., Geng, S., Wu, Z., Huang, H.: Color transfer for images: A survey. ACM Transactions on Multimedia Computing, Communications and Applications 20(8), 1–29 (2024)
2024
-
[30]
CRC press (2021)
Marschner, S., Shirley, P.: Fundamentals of computer graphics. CRC press (2021)
2021
-
[31]
In: 4th European conference on visual media pro- duction
Pitié, F., Kokaram, A.: The linear monge-kantorovitch linear colour mapping for example-based colour transfer. In: 4th European conference on visual media pro- duction. pp. 1–9. IET (2007)
2007
-
[32]
In: Tenth IEEE International Con- ference on Computer Vision (ICCV’05) Volume 1
Pitie, F., Kokaram, A.C., Dahyot, R.: N-dimensional probability density function transfer and its application to color transfer. In: Tenth IEEE International Con- ference on Computer Vision (ICCV’05) Volume 1. vol. 2, pp. 1434–1439. IEEE (2005) In-Context Tone Style Transfer with A Large-Scale Triplet Dataset 17
2005
-
[33]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
2021
-
[34]
IEEE Computer graphics and applications21(5), 34–41 (2002)
Reinhard, E., Adhikhmin, M., Gooch, B., Shirley, P.: Color transfer between im- ages. IEEE Computer graphics and applications21(5), 34–41 (2002)
2002
-
[35]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022)
2022
-
[36]
In: Proceedings of the 31st ACM International Conference on Multimedia
Sheng, X., Li, L., Chen, P., Wu, J., Dong, W., Yang, Y., Xu, L., Li, Y., Shi, G.: Aesclip: Multi-attribute contrastive learning for image aesthetics assessment. In: Proceedings of the 31st ACM International Conference on Multimedia. pp. 1117– 1126 (2023)
2023
-
[37]
arXiv preprint arXiv:2104.06954 , year =
Skorokhodov, I., Sotnikov, G., Elhoseiny, M.: Aligning latent and image spaces to connect the unconnectable. arXiv preprint arXiv:2104.06954 (2021)
-
[38]
Measuring style similarity in diffusion models
Somepalli, G., Gupta, A., Gupta, K., Palta, S., Goldblum, M., Geiping, J., Shri- vastava, A., Goldstein, T.: Measuring style similarity in diffusion models. arXiv preprint arXiv:2404.01292 (2024)
-
[39]
IEEE Access10, 68281–68290 (2022)
Soria, X., Pomboza-Junez, G., Sappa, A.D.: Ldc: Lightweight dense cnn for edge detection. IEEE Access10, 68281–68290 (2022)
2022
-
[40]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wang, Y., Liu, R., Lin, J., Liu, F., Yi, Z., Wang, Y., Ma, R.: Omnistyle: Filter- ing high quality style transfer data at scale. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 7847–7856 (2025)
2025
-
[41]
IEEE Transactions on Image Process- ing13(4), 600–612 (2004)
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. IEEE Transactions on Image Process- ing13(4), 600–612 (2004)
2004
-
[42]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wen, L., Gao, C., Zou, C.: Cap-vstnet: Content affinity preserved versatile style transfer. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 18300–18309 (2023)
2023
-
[43]
Advances in Neural Information Processing Systems37, 46294–46318 (2024)
Wu, J., Wang, Y., Li, L., Zhang, F., Xue, T.: Goal conditioned reinforcement learning for photo finishing tuning. Advances in Neural Information Processing Systems37, 46294–46318 (2024)
2024
-
[44]
Wu, S., Huang, M., Wu, W., Cheng, Y., Ding, F., He, Q.: Less-to-more gener- alization: Unlocking more controllability by in-context generation. arXiv preprint arXiv:2504.02160 (2025)
-
[45]
In: Proceedings of the 2006 ACM international conference on Virtual reality continuum and its applica- tions
Xiao, X., Ma, L.: Color transfer in correlated color space. In: Proceedings of the 2006 ACM international conference on Virtual reality continuum and its applica- tions. pp. 305–309 (2006)
2006
-
[46]
Advances in Neural Information Processing Systems36, 15903–15935 (2023)
Xu, J., Liu, X., Wu, Y., Tong, Y., Li, Q., Ding, M., Tang, J., Dong, Y.: Imagere- ward: Learning and evaluating human preferences for text-to-image generation. Advances in Neural Information Processing Systems36, 15903–15935 (2023)
2023
-
[47]
In: European Con- ference on Computer Vision Workshops
Yeo, W.H., Oh, W.T., Kang, K.S., Kim, Y.I., Ryu, H.C.: Cair: fast and lightweight multi-scale color attention network for instagram filter removal. In: European Con- ference on Computer Vision Workshops. pp. 714–728. Springer (2022)
2022
-
[48]
In: Proceedings of the IEEE/CVF international conference on computer vision
Yoo, J., Uh, Y., Chun, S., Kang, B., Ha, J.W.: Photorealistic style transfer via wavelet transforms. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 9036–9045 (2019)
2019
-
[49]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effec- tiveness of deep features as a perceptual metric. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 586–595. IEEE (2018) 18 Y. Deng et al
2018
-
[50]
Zhang, X., Li, D., Dong, X., Wu, T., Yu, H., Wang, J., Li, Q., Li, X.: Unichange: Unifying change detection with multimodal large language model. arXiv preprint arXiv:2511.02607 (2025)
-
[51]
arXiv preprint arXiv:2602.20980 , year=
Zhang, Y., Li, D., Li, Y., Zhang, X., Xie, T., Cheng, M., Li, X.: Crystal: Sponta- neous emergence of visual latents in mllms. arXiv preprint arXiv:2602.20980 (2026)
-
[52]
Zhang, Z., Xie, J., Lu, Y., Yang, Z., Yang, Y.: In-context edit: Enabling instruc- tional image editing with in-context generation in large scale diffusion transformer. arXiv preprint arXiv:2504.20690 (2025) In-Context Tone Style Transfer with A Large-Scale Triplet Dataset 19 Appendix – Dataset Construction...............................................19...
-
[53]
(8) D Additional Experiments D.1 Details of Evaluation Metrics We evaluate all methods using four metrics, including content preservation (CP), color difference (∆E), deep color difference (CD), and aesthetic quality (Aes). Among them,∆Eand CD are used to evaluate the fidelity of tone style transfer, CP measures structural consistency, and Aes reflects th...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.