Recognition: unknown
MOMENTA: Mixture-of-Experts Over Multimodal Embeddings with Neural Temporal Aggregation for Misinformation Detection
Pith reviewed 2026-05-10 06:44 UTC · model grok-4.3
The pith
MOMENTA detects multimodal misinformation by modeling text-image inconsistencies and their evolution over time with mixture-of-experts and temporal aggregation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
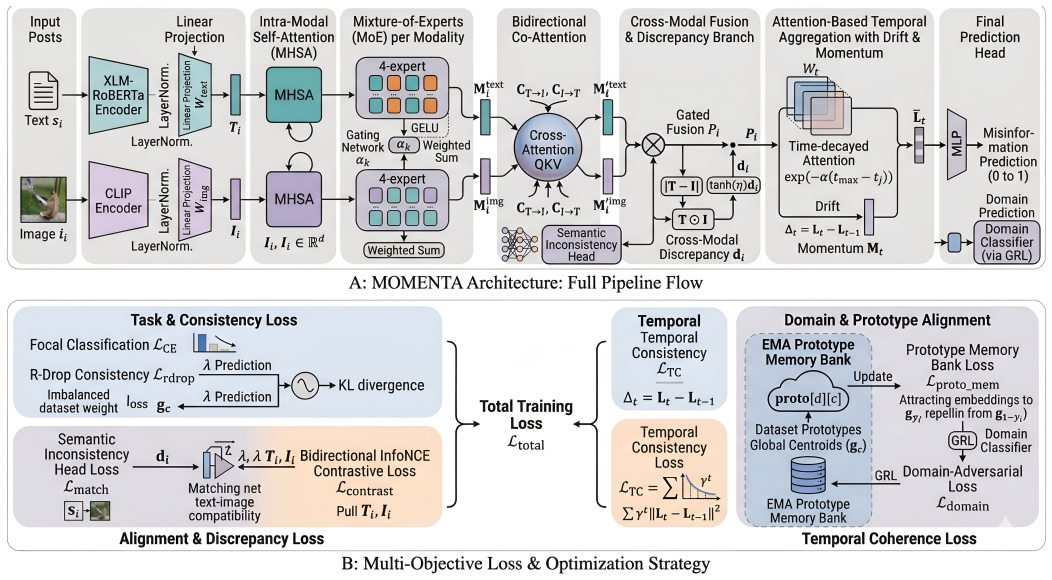
MOMENTA is a unified framework that captures modality heterogeneity with mixture-of-experts modules, cross-modal inconsistency with bidirectional co-attention and a discrepancy-aware branch, narrative evolution with attention-based temporal aggregation using drift and momentum encoding over time windows, and cross-domain generalization with domain-adversarial learning and a prototype memory bank. The model is trained end-to-end with a multi-objective loss that enforces classification accuracy, cross-modal alignment, contrastive learning, temporal consistency, and domain robustness, producing strong results on Fakeddit, MMCoVaR, Weibo, and XFacta across accuracy, F1, AUC, and MCC.
What carries the argument
The MOMENTA architecture, which routes multimodal embeddings through modality-specific mixture-of-experts, aligns them with bidirectional co-attention, flags disagreements in a discrepancy branch, and aggregates them temporally with drift and momentum encoding to track how inconsistencies develop.
If this is right
- Detectors become able to flag content where the falsehood lives in the mismatch between text and image rather than in either alone.
- Systems gain sensitivity to both rapid daily fluctuations and slower weekly trends in how false stories develop.
- Performance holds up when moving to new social media domains or languages without complete retraining.
- The multi-objective training produces representations that remain useful for alignment, consistency, and classification at the same time.
Where Pith is reading between the lines
- The temporal aggregation could be extended to forecast the likely spread trajectory of a new post if future time steps were added.
- Pairing the content-focused model with graph signals from user interactions might capture amplification effects that the current architecture leaves implicit.
- The modular expert and memory design points toward reusable building blocks for related tasks such as video rumor verification.
Load-bearing premise
That jointly optimizing all the specialized components will capture the essential misinformation signals without overfitting or introducing new biases on the evaluated datasets.
What would settle it
Evaluating MOMENTA on a new, previously unseen dataset from an additional platform or language and finding no consistent gains over strong baselines in accuracy, F1-score, or AUC would show the integrated approach does not deliver the claimed robustness.
Figures




read the original abstract
The widespread dissemination of multimodal content on social media has made misinformation detection increasingly challenging, as misleading narratives often arise not only from textual or visual content alone, but also from semantic inconsistencies between modalities and their evolution over time. Existing multimodal misinformation detection methods typically model cross-modal interactions statically and often show limited robustness across heterogeneous datasets, domains, and narrative settings. To address these challenges, we propose MOMENTA, a unified framework for multimodal misinformation detection that captures modality heterogeneity, cross-modal inconsistency, temporal dynamics, and cross-domain generalization within a single architecture. MOMENTA employs modality-specific mixture-of-experts modules to model diverse misinformation patterns, bidirectional co-attention to align textual and visual representations in a shared semantic space, and a discrepancy-aware branch to explicitly capture semantic disagreement between modalities. To model narrative evolution, we introduce an attention-based temporal aggregation mechanism with drift and momentum encoding over overlapping time windows, enabling the framework to capture both short-term fluctuations and longer-term trends in misinformation propagation. In addition, domain-adversarial learning and a prototype memory bank improve domain invariance and stabilize representation learning across datasets. The model is trained using a multi-objective optimization strategy that jointly enforces classification performance, cross-modal alignment, contrastive learning, temporal consistency, and domain robustness. Experiments on Fakeddit, MMCoVaR, Weibo, and XFacta show that MOMENTA achieves strong, consistent results across accuracy, F1-score, AUC, and MCC, highlighting its effectiveness for multimodal misinformation detection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MOMENTA, a unified multimodal framework for misinformation detection that integrates modality-specific mixture-of-experts modules, bidirectional co-attention for cross-modal alignment, a discrepancy-aware branch for semantic disagreement, attention-based temporal aggregation with drift and momentum encoding over overlapping time windows, domain-adversarial learning, and a prototype memory bank. The model is trained via multi-objective optimization enforcing classification, cross-modal alignment, contrastive learning, temporal consistency, and domain robustness. Experiments on Fakeddit, MMCoVaR, Weibo, and XFacta report strong, consistent performance across accuracy, F1-score, AUC, and MCC.
Significance. If the performance claims hold under rigorous controls, MOMENTA could meaningfully advance multimodal misinformation detection by jointly addressing modality heterogeneity, cross-modal inconsistency, narrative temporal dynamics, and cross-domain generalization within one architecture, potentially improving robustness over static cross-modal baselines.
major comments (2)
- [Experimental Evaluation] Experimental Evaluation: The central claim of strong, consistent results across four datasets rests on the joint optimization of multiple components, yet the manuscript provides no ablation studies, component-wise contribution metrics, sensitivity analysis, or isolating experiments (e.g., removing the temporal aggregation or domain-adversarial term). This is load-bearing because the skeptic's concern about synergistic effects without overfitting cannot be assessed without such evidence.
- [Method] Method (architecture description): The attention-based temporal aggregation with drift and momentum encoding and the prototype memory bank are presented as key innovations, but no equations or implementation details are given for how drift/momentum are computed over overlapping windows or how the memory bank interacts with the multi-objective loss, making it impossible to verify reproducibility or rule out dataset-specific biases.
minor comments (2)
- [Abstract] Abstract: The phrase 'strong, consistent results' is repeated without any quantitative anchors or explicit baseline comparisons; adding one or two headline numbers would improve clarity.
- [Introduction/Method] Notation and terminology: Terms such as 'drift and momentum encoding' and 'prototype memory bank' are introduced without immediate formal definitions or references to prior work on similar concepts; a dedicated notation table or early equation block would help.
Simulated Author's Rebuttal
We thank the referee for the thorough and constructive review. We address each major comment below and will incorporate the suggested revisions to improve the manuscript's clarity, reproducibility, and evidential support.
read point-by-point responses
-
Referee: The central claim of strong, consistent results across four datasets rests on the joint optimization of multiple components, yet the manuscript provides no ablation studies, component-wise contribution metrics, sensitivity analysis, or isolating experiments (e.g., removing the temporal aggregation or domain-adversarial term). This is load-bearing because the skeptic's concern about synergistic effects without overfitting cannot be assessed without such evidence.
Authors: We agree that ablation studies are necessary to rigorously demonstrate the contribution of each component and to address potential concerns about overfitting or unexamined synergies. The current manuscript reports overall performance but does not include these isolating experiments. In the revised version, we will add a dedicated ablation subsection that systematically removes each module (modality-specific MoE, bidirectional co-attention, discrepancy-aware branch, temporal aggregation with drift/momentum, domain-adversarial training, and prototype memory bank) and reports the resulting drops in accuracy, F1, AUC, and MCC on all four datasets. We will also include sensitivity analysis for key hyperparameters such as number of experts, temporal window overlap, and loss coefficients. revision: yes
-
Referee: The attention-based temporal aggregation with drift and momentum encoding and the prototype memory bank are presented as key innovations, but no equations or implementation details are given for how drift/momentum are computed over overlapping windows or how the memory bank interacts with the multi-objective loss, making it impossible to verify reproducibility or rule out dataset-specific biases.
Authors: We acknowledge that the manuscript currently provides only high-level descriptions of these components without the explicit equations or implementation details required for full reproducibility. In the revision, we will expand the Method section with precise mathematical formulations: the drift and momentum computations over overlapping time windows, the attention-based aggregation formula, the prototype memory bank update rule and similarity metric, and the exact manner in which the memory bank term is incorporated into the multi-objective loss. We will also add pseudocode for the temporal aggregation and memory bank operations to eliminate ambiguity. revision: yes
Circularity Check
No circularity: empirical model proposal with performance claims resting solely on dataset evaluations
full rationale
The paper introduces MOMENTA as a composite neural architecture (modality-specific MoE, bidirectional co-attention, discrepancy branch, temporal aggregation with drift/momentum, domain-adversarial training, prototype memory) and reports accuracy/F1/AUC/MCC numbers on Fakeddit, MMCoVaR, Weibo, and XFacta. No equations, uniqueness theorems, or first-principles derivations are presented that could reduce by construction to fitted inputs, self-citations, or renamed empirical patterns. All load-bearing claims are experimental outcomes; the architecture description contains no self-referential prediction loops or ansatz smuggling. This is the standard non-circular case for an empirical systems paper.
Axiom & Free-Parameter Ledger
free parameters (2)
- Number of experts and attention heads
- Weights in the multi-objective loss
axioms (2)
- domain assumption Misinformation frequently arises from cross-modal semantic inconsistencies and narrative evolution over time
- domain assumption Domain-adversarial training plus prototype memory can produce representations invariant across heterogeneous datasets
invented entities (2)
-
Drift and momentum encoding
no independent evidence
-
Prototype memory bank
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Spread of (mis)information in social net- works.Games and Economic Behavior, 70(2):194– 227, 2010
Daron Acemoglu, Asuman Ozdaglar, and Ali Paran- dehGheibi. Spread of (mis)information in social net- works.Games and Economic Behavior, 70(2):194– 227, 2010
2010
-
[2]
Ox- ford University Press, Oxford, 2011
Luciano Floridi.The Philosophy of Information. Ox- ford University Press, Oxford, 2011
2011
-
[3]
Stimpson, Sungchul Park, Emily H
Jim P. Stimpson, Sungchul Park, Emily H. Adhikari, David B. Nelson, and Alexander N. Ortega. Perceived health misinformation on social media and public trust in health care.Medical Care, 63(9):686–693, 2025
2025
-
[4]
Perceptions of health misinformation on social media: Cross-sectional sur- vey study.JMIR Infodemiology, 4:e51127, 2024
Anna Gaysynsky, Nicole Senft Everson, Kathryn He- ley, and Wen-Ying Sylvia Chou. Perceptions of health misinformation on social media: Cross-sectional sur- vey study.JMIR Infodemiology, 4:e51127, 2024
2024
-
[5]
Almeida, Natasha Azzopardi- Muscat, Marcos André Gonçalves, Maria Björklund, and David Novillo-Ortiz
Israel Júnior Borges do Nascimento, Ana Beatriz Pizarro, Jussara M. Almeida, Natasha Azzopardi- Muscat, Marcos André Gonçalves, Maria Björklund, and David Novillo-Ortiz. Infodemics and health mis- information: A systematic review of reviews.Bul- letin of the World Health Organization, 100(9):544– 561, 2022
2022
-
[6]
Stephan Lewandowsky, Ullrich K. H. Ecker, John Cook, Stephan Van Der Linden, Jon Roozenbeek, and Naomi Oreskes. Misinformation and the epistemic in- tegrity of democracy.Current Opinion in Psychology, 54:101711, 2023
2023
-
[7]
Echochambers, fakenews, andsocial epistemology
JenniferLackey. Echochambers, fakenews, andsocial epistemology. In S. Bernecker, A. K. Flowerree, and T. Grundmann, editors,The Epistemology of Fake News. Oxford University Press, New York, 2021
2021
-
[8]
E-catch: Event-centric cross-modal attention with temporal consistency and class-imbalance handling for misinformation detection, 2025
Ahmad Mousavi, Yeganeh Abdollahinejad, Roberto Corizzo, Nathalie Japkowicz, and Zois Boukouvalas. E-catch: Event-centric cross-modal attention with temporal consistency and class-imbalance handling for misinformation detection, 2025
2025
-
[9]
Detecting out-of-context multimodal misin- formation with interpretable neural-symbolic model, 2023
Yizhou Zhang, Loc Trinh, Defu Cao, Zijun Cui, and Yan Liu. Detecting out-of-context multimodal misin- formation with interpretable neural-symbolic model, 2023
2023
-
[10]
Event-based multi-modal fusion for on- line misinformation detection in high-impact events
Javad Rajabi, Sunday Okechukwu, Ahmad Mousavi, Roberto Corizzo, Charles C Cavalcante, and Zois Boukouvalas. Event-based multi-modal fusion for on- line misinformation detection in high-impact events. In2024 IEEE International Conference on Big Data (BigData), pages 3301–3308. IEEE, 2024
2024
-
[11]
Not all fake news is written: A dataset and analysis of misleading video headlines
Yoo Yeon Sung, Jordan Boyd-Graber, and Naeemul Hassan. Not all fake news is written: A dataset and analysis of misleading video headlines. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Pro- ceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 16241–16258, Singapore, December 2023. Association for Computa- tion...
2023
-
[12]
Unsupervised cross-lingual representation learning at scale
Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Fran- cisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer, and Veselin Stoyanov. Unsupervised cross-lingual representation learning at scale. InPro- ceedings of the 58th Annual Meeting of the Associa- tion for Computational Linguistics, pages 8440–8451. Association ...
2020
-
[13]
Learning transferable visual models from natural language su- pervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sas- try, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language su- pervision. InProceedings of the 38th International Conference on Machine Learning, volume 139 ofPro- ceedin...
-
[14]
Yu, and Chaozhuo Li
Litian Zhang, Xiaoming Zhang, Ziyi Zhou, Xi Zhang, Philip S. Yu, and Chaozhuo Li. Knowledge-aware multimodal pre-training for fake news detection.In- formation Fusion, 114:102715, 2025
2025
-
[15]
Modality interactive mixture-of-experts for fake news detection
Yifan Liu, Yaokun Liu, Zelin Li, Ruichen Yao, Yang Zhang, and Dong Wang. Modality interactive mixture-of-experts for fake news detection. InPro- ceedings of the ACM Web Conference 2025. ACM, 2025
2025
-
[16]
Misd- moe: A multimodal misinformation detection frame- work with adaptive feature selection
Moyang Liu, Kaiying Yan, Yukun Liu, Ruibo Fu, Zhengqi Wen, Xuefei Liu, and Chenxing Li. Misd- moe: A multimodal misinformation detection frame- work with adaptive feature selection. InProceedings of The 4th NeurIPS Efficient Natural Language and Speech Processing Workshop, volume 262 ofProceed- ings of Machine Learning Research, pages 114–122. PMLR, 2024
2024
-
[17]
Domain-adversarialtrainingofneuralnetworks.Jour- nal of Machine Learning Research, 17(59):1–35, 2016
Yaroslav Ganin, Evgeniya Ustinova, Hana Ajakan, Pascal Germain, Hugo Larochelle, François Lavi- olette, Mario Marchand, and Victor Lempitsky. Domain-adversarialtrainingofneuralnetworks.Jour- nal of Machine Learning Research, 17(59):1–35, 2016
2016
-
[18]
Aduo-generativeapproachto explainable mul- timodal covid-19 misinformation detection
Lanyu Shang, Ziyi Kou, Yang Zhang, and Dong Wang. Aduo-generativeapproachto explainable mul- timodal covid-19 misinformation detection. InPro- ceedings of the ACM Web Conference 2022 (WWW ’22), pages 3623–3631. ACM, 2022. 13
2022
-
[19]
defend: Explainable fake news detec- tion
Kai Shu, Limeng Cui, Suhang Wang, Dongwon Lee, and Huan Liu. defend: Explainable fake news detec- tion. InProceedings of the 25th ACM SIGKDD In- ternational Conference on Knowledge Discovery and Data Mining (KDD ’19), pages 395–405. ACM, 2019
2019
-
[20]
Fung, and Heng Ji
Keyang Xuan, Li Yi, Fan Yang, Ruochen Wu, Yi R. Fung, and Heng Ji. Lemma: Towards lvlm-enhanced multimodal misinformation detection with external knowledge augmentation, 2024
2024
-
[21]
Mmfakebench: A mixed-source multimodal misinformation detection benchmark for lvlms,
Xuannan Liu, Zekun Li, Peipei Li, Shuhan Xia, Xing Cui, Linzhi Huang, Huaibo Huang, Weihong Deng, and Zhaofeng He. Mmfakebench: A mixed-source multimodal misinformation detection benchmark for lvlms.arXiv preprint arXiv:2406.08772, 2024
-
[22]
Xfacta: Contemporary, real-world dataset and evaluation for multimodal misinformation detection with multimodal llms, 2025
Yuzhuo Xiao, Zeyu Han, Yuhan Wang, and Huaizu Jiang. Xfacta: Contemporary, real-world dataset and evaluation for multimodal misinformation detection with multimodal llms, 2025
2025
-
[23]
User comment-guided cross-modal attention for inter- pretable multimodal fake news detection.Applied Sci- ences, 15(14):7904, 2025
Zepu Yi, Chenxu Tang, and Songfeng Lu. User comment-guided cross-modal attention for inter- pretable multimodal fake news detection.Applied Sci- ences, 15(14):7904, 2025
2025
-
[24]
Ken: Knowledge augmentation and emotion guidance network for multimodal fake news detection, 2025
Peican Zhu, Yubo Jing, Le Cheng, Keke Tang, and Yangming Guo. Ken: Knowledge augmentation and emotion guidance network for multimodal fake news detection, 2025
2025
-
[25]
J. N. John, Sara E. Gorman, Heidi J. Larson, and Kathleen Hall Jamieson. Understanding interven- tions to address infodemics through epidemiologi- cal, socioecological, andenvironmentalhealthmodels: Framework analysis.JMIR Infodemiology, 5:e67119, 2025
2025
-
[26]
Jain and K
K. Jain and K. Achuthan. Modeling the dynamics of misinformation spread: A multi-scenario analysis in- corporating user awareness and generative ai impact. Frontiers in Computer Science, 7:1570085, 2025
2025
-
[27]
Assess- ing the impact of misinformation during the spread of infectious diseases.Scientific Reports, 15:34740, 2025
Alejandro Bernardin and Tomas Perez-Acle. Assess- ing the impact of misinformation during the spread of infectious diseases.Scientific Reports, 15:34740, 2025
2025
-
[28]
Focal loss for dense object detection
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. Focal loss for dense object detection. InProceedings of the IEEE International Conference on Computer Vision (ICCV), pages 2980– 2988, 2017
2017
-
[29]
R-drop: Regularized dropout for neural net- works
Xiaobo Liang, Lijun Wu, Juntao Li, Yue Wang, Qi Meng, Tao Qin, Wei Chen, Min Zhang, and Tie- Yan Liu. R-drop: Regularized dropout for neural net- works. InAdvances in Neural Information Processing Systems, volume 34, pages 10890–10905, 2021
2021
-
[30]
Kai Nakamura, Sharon Levy, and William Yang Wang. r/fakeddit: A new multimodal benchmark dataset for fine-grained fake news detection.arXiv preprint arXiv:1911.03854, 2019
-
[31]
Mingxuan Chen, Xinqiao Chu, and K. P. Subbalak- shmi. Mmcovar: Multimodal covid-19 vaccine focused data repository for fake news detection and a baseline architecture for classification, 2021
2021
-
[32]
J. Lv, Y. Gao, L. Li, et al. Multi-modal fake news detection: A comprehensive survey on deep learning technology, advances, and challenges.Journal of King Saud University Computer and Information Sciences, 37:306, 2025
2025
-
[33]
A system- atic analysis of performance measures for classifica- tion tasks.Information Processing & Management, 45(4):427–437, 2009
Marina Sokolova and Guy Lapalme. A system- atic analysis of performance measures for classifica- tion tasks.Information Processing & Management, 45(4):427–437, 2009
2009
-
[34]
Theadvantages of the matthews correlation coefficient (mcc) over f1 score and accuracy in binary classification evaluation
DavideChiccoandGiuseppeJurman. Theadvantages of the matthews correlation coefficient (mcc) over f1 score and accuracy in binary classification evaluation. BMC Genomics, 21(1):6, 2020
2020
-
[35]
The precision- recall plot is more informative than the roc plot when evaluating binary classifiers on imbalanced datasets
Takaya Saito and Marc Rehmsmeier. The precision- recall plot is more informative than the roc plot when evaluating binary classifiers on imbalanced datasets. PLOS ONE, 10(3):e0118432, 2015
2015
-
[36]
Weinberger
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q. Weinberger. On calibration of modern neural net- works. InProceedings of the 34th International Con- ference on Machine Learning, volume 70 ofProceed- ings of Machine Learning Research, pages 1321–1330. PMLR, 2017
2017
-
[37]
Finding the best classification threshold in imbalanced classification.Big Data Research, 5:2– 8, 2016
Quan Zou, Shihe Xie, Zhen Lin, Meijuan Wu, and Yizhou Ju. Finding the best classification threshold in imbalanced classification.Big Data Research, 5:2– 8, 2016
2016
-
[38]
Kathigi, M
A. Kathigi, M. Pujar, A. M. S. Akshatha, R. Shilpa, and S. S. Shirabadagi. Fake news detection using weighted fine-tuned bert and sparse recurrent neural network.Journal of Computer Science, 21(12):2951– 2964, 2025
2025
-
[39]
Disentangling fact from sen- timent: A dynamic conflict-consensus framework for multimodal fake news detection, 2025
Weilin Zhou, Zonghao Ying, Junjie Mu, Shengwei Tian, Quanchen Zou, Deyue Zhang, Dongdong Yang, and Xiangzheng Zhang. Disentangling fact from sen- timent: A dynamic conflict-consensus framework for multimodal fake news detection, 2025
2025
-
[40]
Modality interactive mixture-of-experts for fake news detection, 2025
Yifan Liu, Yaokun Liu, Zelin Li, Ruichen Yao, Yang Zhang, and Dong Wang. Modality interactive mixture-of-experts for fake news detection, 2025. 14
2025
-
[41]
Jindong Wang, Cuiling Lan, Chang Liu, Yidong Ouyang, Tao Qin, Wang Lu, Yiqiang Chen, Wenjun Zeng, and Philip S. Yu. Generalizing to unseen do- mains: A survey on domain generalization.IEEE Transactions on Knowledge and Data Engineering, 35(8):8052–8072, 2023
2023
-
[42]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.arXiv preprint arXiv:1701.06538, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[43]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23(120):1–39, 2022
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23(120):1–39, 2022
2022
-
[44]
Inductive representa- tion learning on temporal graphs
Da Xu, Chuanwei Ruan, Evren Korpeoglu, Sushant Kumar, and Kannan Achan. Inductive representa- tion learning on temporal graphs. InInternational Conference on Learning Representations, 2020
2020
-
[45]
Bronstein
Federico Monti, Fabrizio Frasca, Davide Eynard, Da- mon Mannion, and Michael M. Bronstein. Fake news detection on social media using geometric deep learn- ing. InInternational Conference on Learning Repre- sentations, 2019
2019
-
[46]
Tent: Fully test-time adaptation by entropy minimization
Dequan Wang, Evan Shelhamer, Shaoteng Liu, Bruno Olshausen, and Trevor Darrell. Tent: Fully test-time adaptation by entropy minimization. InInternational Conference on Learning Representations, 2021
2021
-
[47]
Fake news detection on social media: A dataminingperspective.ACM SIGKDD Explorations Newsletter, 19(1):22–36, 2017
Kai Shu, Amy Sliva, Suhang Wang, Jiliang Tang, and Huan Liu. Fake news detection on social media: A dataminingperspective.ACM SIGKDD Explorations Newsletter, 19(1):22–36, 2017. 15
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.