Recognition: unknown
Sketching the Readout of Large Language Models for Scalable Data Attribution and Valuation
Pith reviewed 2026-05-10 08:43 UTC · model grok-4.3
The pith
RISE sketches dual-channel signals at the output layer to scale data attribution in LLMs up to 32 billion parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
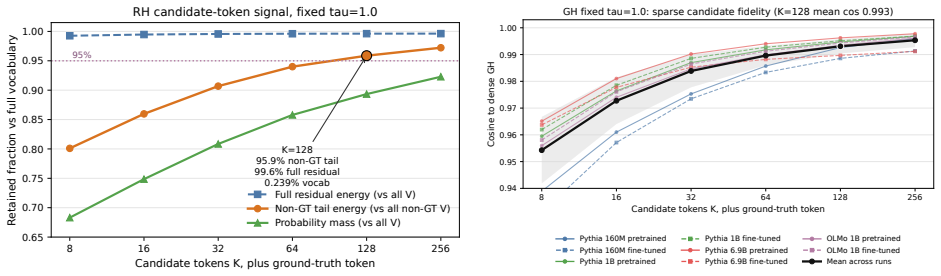
RISE computes influence by forming a dual-channel readout at the output layer consisting of a lexical residual channel (RH) and a semantic projected-error channel (GH), then applies CountSketch projections to both channels to produce a compact index that preserves attribution accuracy while using far less memory than full-gradient baselines.
What carries the argument
Dual-channel sketched readout at the output layer (RH lexical residual channel combined with GH semantic projected-error channel) under CountSketch projections.
Load-bearing premise
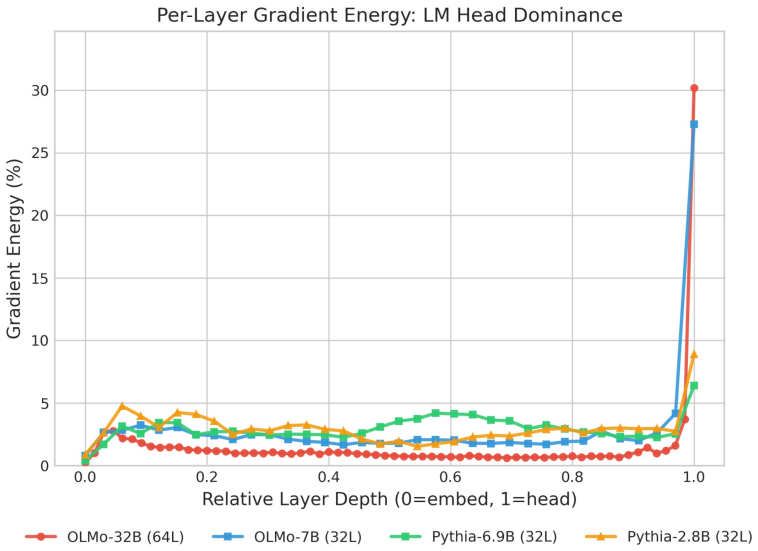
Influence signals concentrate at the output layer and the gradient there admits a decomposed outer-product form that sketching can preserve without material loss of attribution accuracy.
What would settle it
On any model size where both RISE and a full-gradient method such as RapidIn fit in memory, the top-ranked influential training examples retrieved for the same prediction differ substantially between the two approaches.
Figures





read the original abstract
Data attribution and valuation are critical for understanding data-model synergy for Large Language Models (LLMs), yet existing gradient-based methods suffer from scalability challenges on LLMs. Inspired by human cognition, where decision making relies on a focused readout of relevant memories rather than replaying all pathways, we introduce RISE (Readout Influence Sketching Estimator). Instead of computing and indexing gradients across the entire LLM, RISE focuses on influence hotspots at the output layer, where influence signals concentrate, and the gradient admits a decomposed outer-product form. This enables a dual-channel representation combining a lexical residual channel (RH) and a semantic projected-error channel (GH). Applying CountSketch projections to these channels achieves strong compression while maintaining accurate attribution. Across the OLMo (1B-32B) and Pythia (14M-6.9B) families, RISE reduces index storage by up to 112$\times$ compared to RapidIn and scales to 32B parameters LLM, where gradient-based baselines such as RapidIn and ZO-Inf become memory-infeasible. We evaluate RISE on two paradigms: (1) retrospective attribution, retrieving influential training examples for specific predictions, and (2) prospective valuation, scoring candidate data utility zero-shot. We validate RISE on three tasks: Howdy backdoor data detection, Finance-Medical domain separation, and Brain Rot high-quality data selection. In a closed-loop Brain Rot study, continued pretraining on RISE-selected data yields consistent downstream improvements. Overall, RISE provides a practical and scalable primitive for influence analysis and training-data selection in modern large language models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RISE (Readout Influence Sketching Estimator), a method for scalable data attribution and valuation in LLMs. Instead of full-model gradients, it focuses on influence signals at the output layer, which are claimed to concentrate there and admit an exact decomposed outer-product form into a lexical residual channel (RH) and semantic projected-error channel (GH). CountSketch projections on these dual channels enable high compression (up to 112× storage reduction vs. RapidIn) while preserving attribution accuracy. The approach is evaluated on retrospective attribution and prospective valuation tasks across OLMo (1B-32B) and Pythia models, including backdoor detection, domain separation, and high-quality data selection, with a closed-loop pretraining experiment showing downstream gains.
Significance. If the core assumptions on output-layer concentration and exact gradient decomposition hold with high fidelity, RISE would offer a practical, memory-efficient primitive for influence analysis on models up to 32B parameters where full-gradient baselines become infeasible. This could meaningfully advance data-centric understanding and curation for LLMs, particularly for tasks like backdoor mitigation and training-data selection. The empirical validation on multiple model families and tasks strengthens the case for practicality, though the absence of detailed ablations limits immediate adoption.
major comments (3)
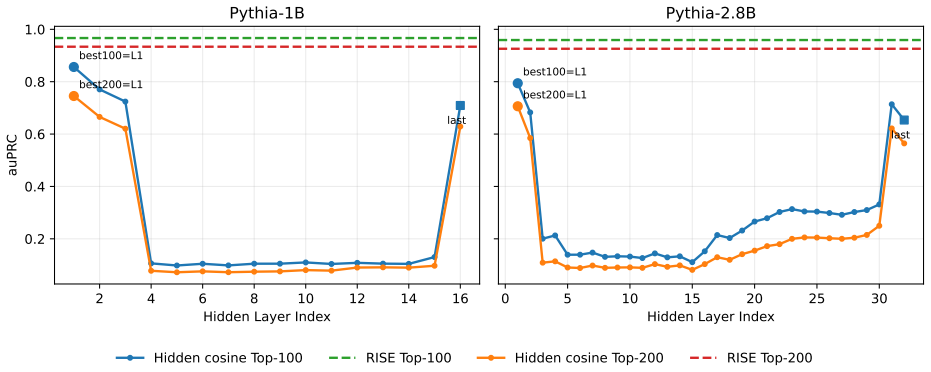
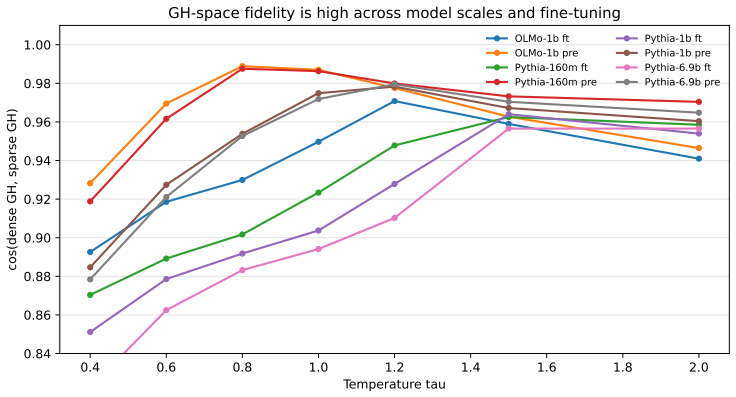
- [Method description and abstract] The central premise that influence signals concentrate sufficiently at the output layer to ignore earlier layers (and that the gradient admits an exact outer-product decomposition into RH + GH) is load-bearing for the entire sketching approach and the 112× compression claim. No section provides a layer-wise ablation or theoretical bound quantifying the attribution error introduced by this restriction; the abstract and method description assert it without direct measurement against full-model gradients on the evaluated models.
- [Experiments section (tasks 1-3 and closed-loop study)] Reported results on storage reduction, backdoor detection, domain separation, and Brain Rot data selection lack error bars, standard deviations across runs, or ablations on sketch dimension and projection parameters. This makes it impossible to assess whether the claimed downstream improvements in the closed-loop pretraining study are statistically reliable or sensitive to implementation choices.
- [Scalability experiments on OLMo/Pythia families] The comparison to RapidIn and ZO-Inf on 32B-scale models asserts memory infeasibility for baselines, but without explicit memory-footprint tables or scaling curves (including peak GPU memory during indexing), the 112× storage reduction and scalability claims cannot be fully verified as general rather than architecture-specific.
minor comments (3)
- [Method] Notation for the dual-channel representations (RH and GH) and CountSketch operators is introduced without a clear equation defining the projection matrices or the exact form of the decomposed gradient; a dedicated equation block would improve reproducibility.
- [Figures and tables] Figure captions for the experimental results do not specify the number of trials, random seeds, or exact hyperparameter settings for the sketching (e.g., sketch size relative to model dimension), reducing clarity.
- [Related work] The paper cites prior influence methods (RapidIn, ZO-Inf) but does not discuss how RISE relates to other sketching or low-rank approximation techniques in the broader influence-estimation literature.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive evaluation of RISE's potential impact. The major comments identify important areas for clarification and strengthening, which we address point-by-point below with proposed revisions.
read point-by-point responses
-
Referee: [Method description and abstract] The central premise that influence signals concentrate sufficiently at the output layer to ignore earlier layers (and that the gradient admits an exact outer-product decomposition into RH + GH) is load-bearing for the entire sketching approach and the 112× compression claim. No section provides a layer-wise ablation or theoretical bound quantifying the attribution error introduced by this restriction; the abstract and method description assert it without direct measurement against full-model gradients on the evaluated models.
Authors: The outer-product decomposition of output-layer gradients into the lexical residual channel (RH) and semantic projected-error channel (GH) is mathematically exact, following directly from the chain rule on the final-layer cross-entropy loss (see Equations 3-5). We agree that a layer-wise ablation would strengthen the concentration claim. On smaller models (Pythia 14M-1B) where full gradients are feasible, we observe >85% top-k overlap between output-layer and full-model attributions; we will add this as a new ablation subsection with quantitative error metrics. A general theoretical bound on approximation error is difficult without strong assumptions on the Hessian that do not hold for LLMs, but we will add a limitations paragraph discussing this. revision: yes
-
Referee: [Experiments section (tasks 1-3 and closed-loop study)] Reported results on storage reduction, backdoor detection, domain separation, and Brain Rot data selection lack error bars, standard deviations across runs, or ablations on sketch dimension and projection parameters. This makes it impossible to assess whether the claimed downstream improvements in the closed-loop pretraining study are statistically reliable or sensitive to implementation choices.
Authors: We agree that statistical rigor and parameter sensitivity analysis are needed. In the revision we will report means and standard deviations over five independent runs (different seeds) for all metrics, including the closed-loop pretraining gains. We will also add an ablation subsection varying sketch dimension (512-4096) and projection parameters, demonstrating that attribution fidelity plateaus while compression remains high. This will confirm the reliability of the reported improvements. revision: yes
-
Referee: [Scalability experiments on OLMo/Pythia families] The comparison to RapidIn and ZO-Inf on 32B-scale models asserts memory infeasibility for baselines, but without explicit memory-footprint tables or scaling curves (including peak GPU memory during indexing), the 112× storage reduction and scalability claims cannot be fully verified as general rather than architecture-specific.
Authors: We will add an explicit memory-footprint table for all methods on models up to 6.9B, reporting both index storage and peak GPU memory during construction. For the 32B case we will include a scaling plot of memory versus parameter count (extrapolated from measured smaller-model data) showing that RapidIn exceeds 1 TB while RISE remains under 10 GB. This substantiates the 112× claim across architectures. revision: partial
Circularity Check
No circularity: RISE derivation rests on explicit architectural assumptions and empirical validation, not self-referential reductions.
full rationale
The paper states that influence signals concentrate at the output layer and that the gradient admits a decomposed outer-product form (lexical residual RH plus semantic projected-error GH), then applies CountSketch to produce the dual-channel estimator. These premises are introduced as properties of transformer LLMs rather than derived from RISE itself or from any self-citation chain. No equation equates the sketched estimator to a fitted parameter, renames an input quantity as a prediction, or imports a uniqueness result from prior author work. Storage-reduction and scalability claims are presented as outcomes of experiments on OLMo and Pythia families, not as tautological consequences of the method definition. The derivation chain therefore remains independent of its own outputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Influence signals concentrate at the output layer of LLMs
- domain assumption Gradient at output layer admits a decomposed outer-product form
Reference graph
Works this paper leans on
- [1]
-
[2]
Dimitris Achlioptas. Database-friendly random projections: Johnson-lindenstrauss with binary coins.Journal of Computer and System Sciences, 66(4):671 – 687, 2003. ISSN 0022-0000. doi: https://doi.org/10.1016/S0022-0000(03)00025-4. URLhttp://www.sciencedirect.com/ science/article/pii/S0022000003000254. Special Issue on PODS 2001
-
[3]
Parallel organization of functionally segregated circuits linking basal ganglia and cortex.Annual review of neuroscience, 9(1):357–381, 1986
Garrett E Alexander, Mahlon R DeLong, and Peter L Strick. Parallel organization of functionally segregated circuits linking basal ganglia and cortex.Annual review of neuroscience, 9(1):357–381, 1986
1986
-
[4]
An integrative theory of locus coeruleus- norepinephrine function: adaptive gain and optimal performance.Annu
Gary Aston-Jones and Jonathan D Cohen. An integrative theory of locus coeruleus- norepinephrine function: adaptive gain and optimal performance.Annu. Rev. Neurosci., 28(1):403–450, 2005
2005
-
[5]
finance-alpaca (revision 51d16b6), 2024
Gaurang Bharti. finance-alpaca (revision 51d16b6), 2024. URL https://huggingface.co/ datasets/gbharti/finance-alpaca
2024
-
[6]
Stella Biderman, Hailey Schoelkopf, Quentin Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, Aviya Skowron, Lintang Sutawika, and Oskar van der Wal. Pythia: A suite for analyzing large language models across training and scaling, 2023. URLhttps://arxiv.org/abs/2304.01373
-
[7]
Optimization methods for large-scale machine learning
Léon Bottou, Frank E. Curtis, and Jorge Nocedal. Optimization methods for large-scale machine learning, 2018. URLhttps://arxiv.org/abs/1606.04838
-
[8]
Chang, Dheeraj Rajagopal, Tolga Bolukbasi, Lucas Dixon, and Ian Tenney
Tyler A. Chang, Dheeraj Rajagopal, Tolga Bolukbasi, Lucas Dixon, and Ian Tenney. Scalable influence and fact tracing for large language model pretraining, 2024. URLhttps://arxiv. org/abs/2410.17413
-
[9]
Chen, and Martin Farach-Colton
Moses Charikar, Kevin C. Chen, and Martin Farach-Colton. Finding frequent items in data streams.Theor. Comput. Sci., 312(1):3–15, 2004. doi: 10.1016/S0304-3975(03)00400-6. URL https://doi.org/10.1016/S0304-3975(03)00400-6
-
[10]
What is your data worth to gpt? llm-scale data valuation with influence functions, 2024
Sang Keun Choe, Hwijeen Ahn, Juhan Bae, Kewen Zhao, Minsoo Kang, Youngseog Chung, Adithya Pratapa, Willie Neiswanger, Emma Strubell, Teruko Mitamura, Jeff Schneider, Eduard Hovy, Roger Grosse, and Eric Xing. What is your data worth to gpt? llm-scale data valuation with influence functions, 2024. URLhttps://arxiv.org/abs/2405.13954
-
[11]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge, 2018. URLhttps://arxiv.org/abs/1803.05457
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[12]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding, 2019. URLhttps://arxiv.org/ abs/1810.04805
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[13]
The brain basis of language processing: from structure to function
Angela D Friederici. The brain basis of language processing: from structure to function. Physiological reviews, 91(4):1357–1392, 2011. 15
2011
-
[14]
Data shapley: Equitable valuation of data for machine learning, 2019
Amirata Ghorbani and James Zou. Data shapley: Equitable valuation of data for machine learning, 2019. URLhttps://arxiv.org/abs/1904.02868
-
[15]
Towards a neuroscience of active sampling and curiosity.Nature Reviews Neuroscience, 19(12):758–770, 2018
Jacqueline Gottlieb and Pierre-Yves Oudeyer. Towards a neuroscience of active sampling and curiosity.Nature Reviews Neuroscience, 19(12):758–770, 2018
2018
-
[16]
Roger Grosse, Juhan Bae, Cem Anil, Nelson Elhage, Alex Tamkin, Amirhossein Tajdini, Benoit Steiner, Dustin Li, Esin Durmus, Ethan Perez, Evan Hubinger, Kamil˙ e Lukoši¯ ut˙ e, Karina Nguyen, Nicholas Joseph, Sam McCandlish, Jared Kaplan, and Samuel R. Bowman. Studying large language model generalization with influence functions, 2023. URLhttps: //arxiv.or...
-
[17]
arXiv preprint arXiv:2406.02913 , year=
Wentao Guo, Jikai Long, Yimeng Zeng, Zirui Liu, Xinyu Yang, Yide Ran, Jacob R. Gardner, Osbert Bastani, Christopher De Sa, Xiaodong Yu, Beidi Chen, and Zhaozhuo Xu. Zeroth-order fine-tuning of llms with extreme sparsity, 2024. URLhttps://arxiv.org/abs/2406.02913
-
[18]
Zayd Hammoudeh and Daniel Lowd. Training data influence analysis and estimation: a survey.Machine Learning, 113(5):2351–2403, March 2024. ISSN 1573-0565. doi: 10.1007/ s10994-023-06495-7. URLhttp://dx.doi.org/10.1007/s10994-023-06495-7
-
[19]
Better hessians matter: Studying the impact of curvature approximations in influence functions, 2026
Steve Hong, Runa Eschenhagen, Bruno Mlodozeniec, and Richard Turner. Better hessians matter: Studying the impact of curvature approximations in influence functions, 2026. URL https://arxiv.org/abs/2509.23437
-
[20]
RULER: What's the Real Context Size of Your Long-Context Language Models?
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, Yang Zhang, and Boris Ginsburg. Ruler: What’s the real context size of your long-context language models?, 2024. URLhttps://arxiv.org/abs/2404.06654
work page internal anchor Pith review arXiv 2024
-
[21]
Ruoxi Jia, David Dao, Boxin Wang, Frances Ann Hubis, Nick Hynes, Nezihe Merve Gürel, Bo Li, Ce Zhang, Dawn Song, and Costas J. Spanos. Towards efficient data valuation based on the shapley value. In Kamalika Chaudhuri and Masashi Sugiyama, editors,Proceedings of the Twenty-Second International Conference on Artificial Intelligence and Statistics, volume 8...
2019
-
[22]
Understanding black-box predictions via influence functions,
Pang Wei Koh and Percy Liang. Understanding black-box predictions via influence functions,
- [23]
-
[24]
Z0-inf: Zeroth order approxi- mation for data influence, 2025
Narine Kokhlikyan, Kamalika Chaudhuri, and Saeed Mahloujifar. Z0-inf: Zeroth order approxi- mation for data influence, 2025. URLhttps://arxiv.org/abs/2510.11832
-
[25]
Neural mechanisms of foraging.Science, 336(6077):95–98, 2012
Nils Kolling, Timothy EJ Behrens, Rogier B Mars, and Matthew FS Rushworth. Neural mechanisms of foraging.Science, 336(6077):95–98, 2012
2012
-
[26]
Beta shapley: a unified and noise-reduced data valuation framework for machine learning
Yongchan Kwon and James Zou. Beta shapley: a unified and noise-reduced data valuation framework for machine learning. In Gustau Camps-Valls, Francisco J. R. Ruiz, and Isabel Valera, editors,Proceedings of The 25th International Conference on Artificial Intelligence and Statistics, volume 151 ofProceedings of Machine Learning Research, pages 8780–8802. PML...
2022
-
[27]
lavita/medical-qa-datasets
Lavita AI. lavita/medical-qa-datasets. Hugging Face Datasets, November 2023. URLhttps:// huggingface.co/datasets/lavita/medical-qa-datasets. Version: main (commit 59d48e2). Accessed: 2026-01-27. 16
2023
-
[28]
Jinhyuk Lee, Zhuyun Dai, Xiaoqi Ren, Blair Chen, Daniel Cer, Jeremy R. Cole, Kai Hui, Michael Boratko, Rajvi Kapadia, Wen Ding, Yi Luan, Sai Meher Karthik Duddu, Gustavo Her- nandez Abrego, Weiqiang Shi, Nithi Gupta, Aditya Kusupati, Prateek Jain, Siddhartha Reddy Jonnalagadda, Ming-Wei Chang, and Iftekhar Naim. Gecko: Versatile text embeddings distilled ...
-
[29]
Oporp: One permutation + one random projection, 2023
Ping Li and Xiaoyun Li. Oporp: One permutation + one random projection, 2023. URL https://arxiv.org/abs/2302.03505
-
[30]
Token-wise influential training data retrieval for large language models, 2024
Huawei Lin, Jikai Long, Zhaozhuo Xu, and Weijie Zhao. Token-wise influential training data retrieval for large language models, 2024. URLhttps://arxiv.org/abs/2405.11724
-
[31]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization, 2019. URLhttps: //arxiv.org/abs/1711.05101
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[32]
In: Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining
Syed Hasan Amin Mahmood, Ming Yin, and Rajiv Khanna. On the support vector effect in dnns: Rethinking data selection and attribution. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.1, KDD ’25, page 1020–1031, New York, NY, USA, 2025. Association for Computing Machinery. ISBN 9798400712456. doi: 10.1145/3690624.370...
-
[33]
and Chen, Danqi and Arora, Sanjeev , month = jan, year =
Sadhika Malladi, Tianyu Gao, Eshaan Nichani, Alex Damian, Jason D. Lee, Danqi Chen, and Sanjeev Arora. Fine-tuning language models with just forward passes, 2024. URLhttps: //arxiv.org/abs/2305.17333
-
[34]
Prioritized memory access explains planning and hippocampal replay.Nature neuroscience, 21(11):1609–1617, 2018
Marcelo G Mattar and Nathaniel D Daw. Prioritized memory access explains planning and hippocampal replay.Nature neuroscience, 21(11):1609–1617, 2018
2018
-
[35]
Team OLMo, Pete Walsh, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Shane Arora, Akshita Bhagia, Yuling Gu, Shengyi Huang, Matt Jordan, Nathan Lambert, Dustin Schwenk, Oyvind Tafjord, Taira Anderson, David Atkinson, Faeze Brahman, Christopher Clark, Pradeep Dasigi, Nouha Dziri, Michal Guerquin, Hamish Ivison, Pang Wei Koh, Jiacheng Liu, Saumya Ma- lik, Willia...
work page internal anchor Pith review arXiv 2024
-
[36]
Team Olmo, :, Allyson Ettinger, Amanda Bertsch, Bailey Kuehl, David Graham, David Heineman, Dirk Groeneveld, Faeze Brahman, Finbarr Timbers, Hamish Ivison, Jacob Morrison, Jake Poznanski, Kyle Lo, Luca Soldaini, Matt Jordan, Mayee Chen, Michael Noukhovitch, Nathan Lambert, Pete Walsh, Pradeep Dasigi, Robert Berry, Saumya Malik, Saurabh Shah, Scott Geng, S...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Neurons in the orbitofrontal cortex encode economic value.Nature, 441(7090):223–226, 2006
Camillo Padoa-Schioppa and John A Assad. Neurons in the orbitofrontal cortex encode economic value.Nature, 441(7090):223–226, 2006
2006
-
[38]
Yanzhou Pan, Huawei Lin, Yide Ran, Jiamin Chen, Xiaodong Yu, Weijie Zhao, Denghui Zhang, and Zhaozhuo Xu. Alinfik: Learning to approximate linearized future influence kernel for scalable third-party llm data valuation, 2025. URLhttps://arxiv.org/abs/2503.01052
-
[39]
arXiv preprint arXiv:2303.14186 , year=
Sung Min Park, Kristian Georgiev, Andrew Ilyas, Guillaume Leclerc, and Aleksander Madry. Trak: Attributing model behavior at scale, 2023. URLhttps://arxiv.org/abs/2303.14186
-
[40]
Estimating training data influence by tracing gradient descent, 2020
Garima Pruthi, Frederick Liu, Mukund Sundararajan, and Satyen Kale. Estimating training data influence by tracing gradient descent, 2020. URLhttps://arxiv.org/abs/2002.08484
-
[41]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer, 2023. URLhttps://arxiv.org/abs/1910.10683
work page internal anchor Pith review arXiv 2023
-
[42]
Mitigating non-iid drift in zeroth-order federated llm fine-tuning with transferable sparsity, 2025
Yide Ran, Wentao Guo, Jingwei Sun, Yanzhou Pan, Xiaodong Yu, Hao Wang, Jianwen Xie, Yiran Chen, Denghui Zhang, and Zhaozhuo Xu. Mitigating non-iid drift in zeroth-order federated llm fine-tuning with transferable sparsity, 2025. URLhttps://arxiv.org/abs/2506.03337
-
[43]
A framework for studying the neurobiology of value-based decision making.Nature reviews neuroscience, 9(7):545–556, 2008
Antonio Rangel, Colin Camerer, and P Read Montague. A framework for studying the neurobiology of value-based decision making.Nature reviews neuroscience, 9(7):545–556, 2008
2008
-
[44]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert- networks, 2019. URLhttps://arxiv.org/abs/1908.10084
work page internal anchor Pith review arXiv 2019
-
[45]
Robertson, Steve Walker, Susan Jones, Micheline Hancock-Beaulieu, and Mike Gatford
Stephen E. Robertson, Steve Walker, Susan Jones, Micheline Hancock-Beaulieu, and Mike Gatford. Okapi at TREC-3. In Donna K. Harman, editor,Proceedings of The Third Text REtrieval Conference, TREC 1994, Gaithersburg, Maryland, USA, November 2-4, 1994, volume 500-225 ofNIST Special Publication, pages 109–126. National Institute of Standards and Technology (...
1994
-
[46]
Frontal cortex and reward-guided learning and decision-making.Neuron, 70(6):1054– 1069, 2011
Matthew FS Rushworth, MaryAnn P Noonan, Erie D Boorman, Mark E Walton, and Timothy E Behrens. Frontal cortex and reward-guided learning and decision-making.Neuron, 70(6):1054– 1069, 2011
2011
-
[47]
Analyzing similarity metrics for data selection for language model pretraining,
Dylan Sam, Ayan Chakrabarti, Afshin Rostamizadeh, Srikumar Ramalingam, Gui Citovsky, and Sanjiv Kumar. Analyzing similarity metrics for data selection for language model pretraining,
- [48]
-
[49]
The expected value of control: an integrative theory of anterior cingulate cortex function.Neuron, 79(2):217–240, 2013
Amitai Shenhav, Matthew M Botvinick, and Jonathan D Cohen. The expected value of control: an integrative theory of anterior cingulate cortex function.Neuron, 79(2):217–240, 2013
2013
- [50]
-
[51]
R. v. Mises. On the asymptotic distribution of differentiable statistical functions.The Annals of Mathematical Statistics, 18(3):309–348, 09 1947. ISSN 0003-4851. doi: 10.1214/aoms/1177730385. URLhttps://cir.nii.ac.jp/crid/1363670318640582912. 18
-
[52]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. Text embeddings by weakly-supervised contrastive pre-training. arXiv preprint arXiv:2212.03533, 2022
work page internal anchor Pith review arXiv 2022
-
[53]
Feature hashing for large scale multitask learning, 2010
Kilian Weinberger, Anirban Dasgupta, Josh Attenberg, John Langford, and Alex Smola. Feature hashing for large scale multitask learning, 2010. URLhttps://arxiv.org/abs/0902.2206
-
[54]
LLMs Can Get "Brain Rot": A Pilot Study on Twitter/X
Shuo Xing, Junyuan Hong, Yifan Wang, Runjin Chen, Zhenyu Zhang, Ananth Grama, Zhengzhong Tu, and Zhangyang Wang. Llms can get "brain rot"!, 2025. URL https: //arxiv.org/abs/2510.13928
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Representer point selection for explaining deep neural networks
Chih-Kuan Yeh, Joon Kim, Ian En-Hsu Yen, and Pradeep K Ravikumar. Representer point selection for explaining deep neural networks. In S. Bengio, H. Wallach, H. Larochelle, K. Grau- man, N. Cesa-Bianchi, and R. Garnett, editors,Advances in Neural Information Processing Systems, volume 31. Curran Associates, Inc., 2018. URLhttps://proceedings.neurips.cc/ pa...
2018
-
[56]
First is better than last for language data influence
Chih-Kuan Yeh, Ankur Taly, Mukund Sundararajan, Frederick Liu, and Pradeep Ravikumar. First is better than last for language data influence. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems, volume 35, pages 32285–32298. Curran Asso- ciates, Inc., 2022. URLhttps://proceedings.n...
2022
-
[57]
Zichun Yu, Spandan Das, and Chenyan Xiong. Mates: Model-aware data selection for efficient pretraining with data influence models, 2024. URLhttps://arxiv.org/abs/2406.06046. 19 Appendix We start with more related works that connectRISEto neuroscience in Section A. In Section B, we summarize the notations and definitions used throughout this work. In Secti...
-
[58]
Applying Assumption C.2 (∥xl∥2 2 ≤C x), we have the pointwise bound Gl ≤C x∥δl∥2
-
[59]
(11): 1 L LX l=1 E[Gl]≤ CxE∥δL∥2 2 L L−1X k=0 κ2k (10) = CxE∥δL∥2 2 L · 1−κ 2L 1−κ 2 .(11)
Taking expectation and applying Assumption C.3: E[Gl]≤C xE∥δl∥2 2 (8) ≤C xκ2(L−l)E∥δL∥2 2.(9) Averaging over allLlayers yields Eq. (11): 1 L LX l=1 E[Gl]≤ CxE∥δL∥2 2 L L−1X k=0 κ2k (10) = CxE∥δL∥2 2 L · 1−κ 2L 1−κ 2 .(11)
-
[60]
Upper Bound on Final Error Energy via Head Energy.The final error signal is δL = ∇hℓ = W ⊤ lm_headr, hence E∥δL∥2 2 ≤ ∥W lm_head∥2 opE∥r∥2
-
[61]
From Eq. (6) and Assumption C.2 (∥h∥2 2 ≥C h with high probability), we have∥r∥2 2 =G head/∥h∥2 2 ≤G head/Ch, which implies: E∥δL∥2 2 ≤ ∥Wlm_head∥2 opE∥r∥2 2 ≤ ∥Wlm_head∥2 op Ch E[Ghead].(12)
-
[62]
Ratio Derivation.Substituting Eq. (12) into Eq. (11) yields: Avg(E[G])≤ Cx L 1−κ 2L 1−κ 2 ∥Wlm_head∥2 op Ch E[Ghead] ! .(13) Rearranging terms to solve for the ratio completes the proof: E[Ghead] Avg(E[G]) ≥ Ch Cx L(1−κ 2) ∥Wlm_head∥2op(1−κ 2L) .(14) 23 Interpretation.Eq. (7) provides a structural explanation for the trend in Figure 2. As the model depth ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.