Recognition: unknown
GAViD: A Large-Scale Multimodal Dataset for Context-Aware Group Affect Recognition from Videos
Pith reviewed 2026-05-10 08:55 UTC · model grok-4.3
The pith
A new dataset supplies 5091 multimodal video clips with context annotations to support group affect recognition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
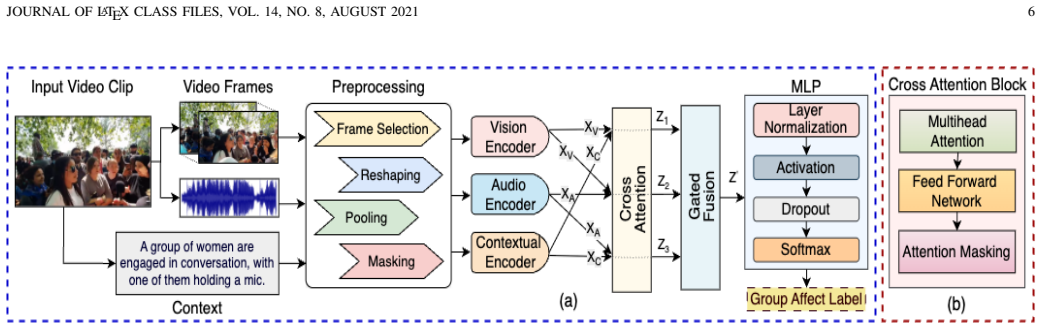
The central claim is that the GAViD dataset of 5091 video clips, equipped with video, audio, and contextual information and labeled for ternary valence and discrete emotions plus action cues, supplies the missing foundation for training context-aware models. The Context-Aware Group Affect Recognition Network (CAGNet) trained on this data achieves 63.20 percent accuracy on held-out test clips, matching current state-of-the-art levels for the task.
What carries the argument
The GAViD dataset acts as the central object, supplying aligned multimodal streams and context annotations that let CAGNet incorporate surrounding information into its predictions of group valence and emotion.
If this is right
- Models can now be trained to weigh contextual cues when deciding group emotional states rather than relying on visual and audio features alone.
- The combination of generated metadata and human action cues provides richer supervision signals for learning how behaviors and surroundings shape collective affect.
- Public release of the clips, labels, and code removes the data barrier that previously slowed progress on in-the-wild group affect tasks.
- CAGNet performance shows that multimodal fusion with explicit context yields results on par with existing specialized methods.
Where Pith is reading between the lines
- Researchers could test whether the same clips support fine-grained analysis of emotion transitions over time rather than static labels.
- The dataset structure may transfer to related problems such as predicting group consensus or detecting conflict in social videos.
- Adding longitudinal clips from the same groups could reveal how affect evolves across repeated interactions.
- Systems trained on GAViD might improve downstream applications like automated moderation of online group calls or analysis of crowd responses at events.
Load-bearing premise
The human and VideoGPT annotations correctly capture the actual group affect and relevant context in the selected clips without major errors or selection biases.
What would settle it
An independent set of fresh human annotators labeling a random subset of the clips and showing low agreement with the published valence and emotion labels would falsify the assumption that the dataset annotations are reliable.
Figures



read the original abstract
Understanding affective dynamics in real-world social systems is fundamental to modeling and analyzing human-human interactions in complex environments. Group affect emerges from intertwined human-human interactions, contextual influences, and behavioral cues, making its quantitative modeling a challenging computational social systems problem. However, computational modeling of group affect in in-the-wild scenarios remains challenging due to limited large-scale annotated datasets and the inherent complexity of multimodal social interactions shaped by contextual and behavioral variability. The lack of comprehensive datasets annotated with multimodal and contextual information further limits advances in the field. To address this, we introduce the Group Affect from ViDeos (GAViD) dataset, comprising 5091 video clips with multimodal data (video, audio and context), annotated with ternary valence and discrete emotion labels and enriched with VideoGPT-generated contextual metadata and human-annotated action cues. We also present Context-Aware Group Affect Recognition Network (CAGNet) for multimodal context-aware group affect recognition. CAGNet achieves 63.20\% test accuracy on GAViD, comparable to state-of-the-art performance. The dataset and code are available at github.com/deepakkumar-iitr/GAViD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the GAViD dataset comprising 5091 video clips with multimodal (video, audio, context) data, annotated with ternary valence and discrete emotion labels, enriched with VideoGPT-generated contextual metadata and human-annotated action cues. It also presents the Context-Aware Group Affect Recognition Network (CAGNet) achieving 63.20% test accuracy on GAViD, claimed to be comparable to state-of-the-art performance.
Significance. If the annotations are shown to be reliable, GAViD would constitute a useful large-scale multimodal resource for in-the-wild group affect recognition, addressing a noted scarcity of such datasets and supporting reproducibility via public code and data release. The central performance claim, however, cannot be fully assessed without the missing validation and evaluation details.
major comments (3)
- [Abstract] Abstract: The single reported accuracy of 63.20% is presented without any evaluation protocol details (train/test split sizes, class distribution for discrete emotions, or metric definition), baseline comparisons, or error analysis, rendering the 'comparable to state-of-the-art' claim unverifiable from the given text.
- [Dataset annotation description (likely §3)] Dataset annotation description (likely §3): No inter-annotator agreement statistics, expert validation subset results, or bias audit on clip sourcing are provided for the ternary valence, discrete emotion, or action cue labels, which directly undermines the dataset's utility as a reliable proxy for true group affect.
- [CAGNet experiments (likely §4 or §5)] CAGNet experiments (likely §4 or §5): The manuscript supplies no ablation studies on multimodal/context components, comparisons to prior group affect methods on GAViD, or analysis of VideoGPT metadata quality, so the 63.20% figure cannot be interpreted as evidence of genuine progress.
minor comments (2)
- [Abstract] Abstract: The dataset acronym expansion 'Group Affect from ViDeos' uses inconsistent capitalization that should be standardized.
- [Introduction] Introduction: A brief comparison table to existing group affect datasets would clarify the claimed novelty in scale and multimodal context.
Simulated Author's Rebuttal
Thank you for the referee's constructive comments. We address each major point below and commit to revisions that will incorporate the suggested improvements to enhance the clarity and rigor of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The single reported accuracy of 63.20% is presented without any evaluation protocol details (train/test split sizes, class distribution for discrete emotions, or metric definition), baseline comparisons, or error analysis, rendering the 'comparable to state-of-the-art' claim unverifiable from the given text.
Authors: We agree that the abstract, being concise, does not provide the necessary evaluation protocol details, making the performance claim difficult to verify from the abstract alone. We will revise the abstract to include key details such as the train/test split sizes and the metric definition. Additionally, we will enhance the experiments section to include class distribution information, baseline comparisons to prior methods, and error analysis to substantiate the claim of comparability to state-of-the-art performance. revision: yes
-
Referee: [Dataset annotation description (likely §3)] Dataset annotation description (likely §3): No inter-annotator agreement statistics, expert validation subset results, or bias audit on clip sourcing are provided for the ternary valence, discrete emotion, or action cue labels, which directly undermines the dataset's utility as a reliable proxy for true group affect.
Authors: We acknowledge that the current description of the dataset annotation process does not include inter-annotator agreement statistics or other validation measures. We will add these in the revised manuscript, including inter-annotator agreement statistics for the valence, discrete emotion, and action cue labels, results from an expert validation subset, and a bias audit on the clip sourcing process. revision: yes
-
Referee: [CAGNet experiments (likely §4 or §5)] CAGNet experiments (likely §4 or §5): The manuscript supplies no ablation studies on multimodal/context components, comparisons to prior group affect methods on GAViD, or analysis of VideoGPT metadata quality, so the 63.20% figure cannot be interpreted as evidence of genuine progress.
Authors: We agree that additional analyses are required to properly interpret the reported accuracy. We will add ablation studies on the multimodal and context components of CAGNet, direct comparisons against prior group affect methods evaluated on GAViD, and an analysis of the VideoGPT-generated metadata quality in the revised manuscript. revision: yes
Circularity Check
No circularity: empirical dataset introduction and held-out accuracy measurement
full rationale
The paper introduces the GAViD dataset (5091 clips with annotations and metadata) and reports CAGNet's 63.20% test accuracy as an empirical result on held-out data. No derivation chain, equations, or self-citations reduce any claimed result to its inputs by construction. The accuracy is a direct measurement rather than a fitted or renamed quantity, and dataset properties are presented as collected facts, not derived tautologically. This is a standard non-circular dataset-plus-model paper.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Human and AI-generated annotations faithfully capture ground-truth group affect and context.
- domain assumption The 5091 clips constitute a representative sample of real-world group interactions.
Reference graph
Works this paper leans on
-
[1]
Group-Level Emotion Recognition Using a Unimodal Privacy-Safe Non-Individual Approach,
A. Petrovaet al., “Group-Level Emotion Recognition Using a Unimodal Privacy-Safe Non-Individual Approach,” inInternational Conference on Multimodal Interaction, 2020, pp. 813–820
2020
-
[2]
Emo- tion Recognition and Artificial Intelligence: A Systematic Review and Research Recommendations,
S. K. Khare, V . Blanes-Vidal, E. S. Nadimi, and U. R. Acharya, “Emo- tion Recognition and Artificial Intelligence: A Systematic Review and Research Recommendations,”Information fusion, vol. 102, p. 102019, 2024
2024
-
[3]
Development and Application of Emotion Recognition Technology: A Systematic Literature Review,
R. Guo, H. Guo, L. Wang, M. Chen, D. Yang, and B. Li, “Development and Application of Emotion Recognition Technology: A Systematic Literature Review,”BMC Psychology, vol. 12, no. 1, p. 95, 2024
2024
-
[4]
EmotiW 2020: Driver Gaze, Group Emo- tion, Student Engagement and Physiological Signal Based Challenges,
A. Dhall, G. Sharmaet al., “EmotiW 2020: Driver Gaze, Group Emo- tion, Student Engagement and Physiological Signal Based Challenges,” inInternational Conference on Multimodal Interaction, 2020, pp. 784– 789
2020
-
[5]
The Emotional Effectiveness of Advertisement,
F. J. Otamendi and D. L. Sutil Mart ´ın, “The Emotional Effectiveness of Advertisement,”Frontiers in Psychology, vol. 11, p. 2088, 2020
2088
-
[6]
Group Emotion Detection based on Social Robot Perception,
M. Quiroz, R. Pati ˜no, J. Diaz-Amado, and Y . c., “Group Emotion Detection based on Social Robot Perception,”Sensors, vol. 22, no. 10, p. 3749, 2022
2022
-
[7]
A Survey of Deep Learning for Group-level Emotion Recognition,
X. Huang, J. Xu, W. Zheng, Q. Mao, and A. Dhall, “A Survey of Deep Learning for Group-level Emotion Recognition,”arXiv preprint arXiv:2408.15276, 2024, accessed 15 Sep 2025
-
[8]
Affective Computing and the Road to an Emotionally Intelligent Metaverse,
F. Pervezet al., “Affective Computing and the Road to an Emotionally Intelligent Metaverse,”IEEE Open Journal of the Computer Society, 2024
2024
-
[9]
Facial Emotion Recog- nition for Photo and Video Surveillance based on Machine Learning and Visual Analytics,
O. Kalyta, O. Barmak, P. Radiuk, and I. Krak, “Facial Emotion Recog- nition for Photo and Video Surveillance based on Machine Learning and Visual Analytics,”Applied Sciences, vol. 13, no. 17, p. 9890, 2023
2023
-
[10]
https: //arxiv.org/abs/2403.08824
P. Kumar, A. Vedernikov, Y . Chen, W. Zheng, and X. Li, “Computational Analysis of Stress, Depression and Engagement in Mental Health: A Survey,”arXiv:2403.08824, 2025, Accessed 15 May 2025
-
[11]
Multimodal Group Emotion Recognition In-The-Wild Using Privacy-Compliant Features,
A. Augusma, D. Vaufreydaz, and F. Letu ´e, “Multimodal Group Emotion Recognition In-The-Wild Using Privacy-Compliant Features,” inInter- national Conference on Multimodal Interaction, 2023, pp. 750–754
2023
-
[12]
Multi-Modal Fusion Using Spatio-Temporal and Static Features for Group Emotion Recognition,
M. Sunet al., “Multi-Modal Fusion Using Spatio-Temporal and Static Features for Group Emotion Recognition,” inInt. Conf. on Multimodal Interaction, 2020, pp. 835–840
2020
-
[13]
Audio-visual Automatic Group Affect Analysis,
G. Sharma, A. Dhall, and J. Cai, “Audio-visual Automatic Group Affect Analysis,”IEEE Transactions on Affective Computing, vol. 14, no. 2, pp. 1056–1069, 2021
2021
-
[14]
Emotion Recognition in Context,
R. Kosti, J. M. Alvarez, A. Recasens, and A. Lapedriza, “Emotion Recognition in Context,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2017, pp. 1667–1675
2017
-
[15]
Social Event Context and Affect Prediction in Group Videos,
A. Malhotraet al., “Social Event Context and Affect Prediction in Group Videos,” inACII Workshops. IEEE, 2023, pp. 1–8
2023
-
[16]
Audio-Visual Classification of Group Emotion Valence Using Activity Recognition Networks,
J. R. Pintoet al., “Audio-Visual Classification of Group Emotion Valence Using Activity Recognition Networks,” inInternational Con- ference on Image Processing, Applications and Systems. IEEE, 2020, pp. 114–119
2020
-
[17]
Graph Neural Networks for Image Understanding Based on Multiple Cues: Group Emotion Recognition and Event Recognition as Use Cases,
X. Guo, L. Polania, B. Zhu, C. Boncelet, and K. Barner, “Graph Neural Networks for Image Understanding Based on Multiple Cues: Group Emotion Recognition and Event Recognition as Use Cases,” inIEEE/CVF Winter Conference on Applications of Computer Vision, 2020, pp. 2921–2930
2020
-
[18]
Implicit Knowledge Injectable Cross Attention Audio-Visual Model for Group Emotion Recognition,
Y . Wang, J. Wuet al., “Implicit Knowledge Injectable Cross Attention Audio-Visual Model for Group Emotion Recognition,” inInternational Conference on Multimodal Interaction, 2020, pp. 827–834
2020
-
[19]
Dynamic Domain Adaptation for Class-Aware Cross-Subject and Cross-Session EEG Emotion Recognition,
Z. Li, E. Zhuet al., “Dynamic Domain Adaptation for Class-Aware Cross-Subject and Cross-Session EEG Emotion Recognition,”IEEE Journal of Biomedical and Health Informatics, vol. 26, no. 12, pp. 5964– 5973, 2022
2022
-
[20]
A Survey on Evaluation of Large Language Models,
Y . Chang, X. Wang, J. Wang, Y . Wu, L. Yang, K. Zhu, H. Chen, X. Yi, C. Wang, Y . Wanget al., “A Survey on Evaluation of Large Language Models,”ACM Transactions on Intelligent Systems and Technology, vol. 15, no. 3, pp. 1–45, 2024
2024
-
[21]
FindingEmo: An Image Dataset for Emotion Recognition in the Wild,
L. Mertens, E. Yargholi, H. Op de Beeck, J. Van den Stock, and J. Vennekens, “FindingEmo: An Image Dataset for Emotion Recognition in the Wild,”Advances in Neural Information Processing Systems, vol. 37, pp. 4956–4996, 2024
2024
-
[22]
EmotiW 2018: Audio- video, Student Engagement and Group-Level Affect Prediction,
A. Dhall, A. Kaur, R. Goecke, and T. Gedeon, “EmotiW 2018: Audio- video, Student Engagement and Group-Level Affect Prediction,” in International Conf. on Multimodal Interaction, 2018, pp. 653–656
2018
-
[23]
From Individual to Group-Level Emotion Recognition: Emotiw 5.0,
A. Dhall, R. Goecke, S. Ghosh, J. Joshi, J. Hoey, and T. Gedeon, “From Individual to Group-Level Emotion Recognition: Emotiw 5.0,” in International Conference on Multimodal Interaction, 2017, pp. 524–528
2017
-
[24]
Automatic Group Happiness Intensity Analysis,
A. Dhall, R. Goecke, and T. Gedeon, “Automatic Group Happiness Intensity Analysis,”IEEE Transactions on Affective Computing, vol. 6, no. 1, pp. 13–26, 2015
2015
-
[25]
Group-level Arousal & Valence Recognition in Static Images: Face, Body & Context,
W. Mou, O. Celiktutan, and H. Gunes, “Group-level Arousal & Valence Recognition in Static Images: Face, Body & Context,” inFG Workshops, vol. 5, 2015, pp. 1–6
2015
-
[26]
A Video Dataset for Classroom Group Engagement Recognition,
W. Lu, Y . Yang, R. Song, Y . Chen, T. Wang, and C. Bian, “A Video Dataset for Classroom Group Engagement Recognition,”Scientific Data, vol. 12, no. 1, p. 644, 2025
2025
-
[27]
VEATIC: Video-based Emotion and Affect Tracking in Context Dataset,
Z. Ren, J. Ortega, Y . Wang, Z. Chen, Y . Guo, S. X. Yu, and D. Whit- ney, “VEATIC: Video-based Emotion and Affect Tracking in Context Dataset,” inIEEE/CVF Winter Conference on Applications of Computer Vision, 2024, pp. 4467–4477
2024
-
[28]
A Real-World Dataset of Group Emotion Experiences based on Physiological Data,
P. Bota, J. Brito, A. Fred, P. Cesar, and H. Silva, “A Real-World Dataset of Group Emotion Experiences based on Physiological Data,”Scientific Data, vol. 11, no. 1, p. 116, 2024
2024
-
[29]
GCE: An Audio-Visual Dataset for Group Cohesion and Emotion Analysis,
E. Lim, N.-H. Hoet al., “GCE: An Audio-Visual Dataset for Group Cohesion and Emotion Analysis,”Applied Sciences, vol. 14, no. 15, p. 6742, 2024
2024
-
[30]
Non- V olume Preserving-based Fusion to Group-Level Emotion Recognition on Crowd Videos,
K. G. Quach, N. Le, C. N. Duong, I. Jalata, K. Roy, and K. Luu, “Non- V olume Preserving-based Fusion to Group-Level Emotion Recognition on Crowd Videos,”Pattern Recognition, vol. 128, p. 108646, 2022
2022
-
[31]
AMIGOS: A Dataset for Affect, Personality and Mood Research on Individuals and Groups,
Miranda-Correaet al., “AMIGOS: A Dataset for Affect, Personality and Mood Research on Individuals and Groups,”IEEE transactions on affective computing, vol. 12, no. 2, pp. 479–493, 2018
2018
-
[32]
The MatchNMingle Dataset: A Novel Multi- Sensor Resource for the Analysis of Social Interactions and Group Dynamics In-The-Wild During Free-Standing Conversations and Speed Dates,
L. Cabrera-Quiroset al., “The MatchNMingle Dataset: A Novel Multi- Sensor Resource for the Analysis of Social Interactions and Group Dynamics In-The-Wild During Free-Standing Conversations and Speed Dates,”IEEE Transactions on Affective Computing, vol. 12, no. 1, pp. 113–130, 2018
2018
-
[33]
Novel Dataset for Fine-Grained Abnormal Behavior Understanding in Crowd,
H. Rabieeet al., “Novel Dataset for Fine-Grained Abnormal Behavior Understanding in Crowd,” inInternational Conference on Advanced Video and Signal Based Surveillance, 2016, pp. 95–101
2016
-
[34]
Salsa: A Novel Dataset for Multimodal Group Behavior Analysis,
X. Alameda-Pinedaet al., “Salsa: A Novel Dataset for Multimodal Group Behavior Analysis,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 38, no. 8, pp. 1707–1720, 2015
2015
-
[35]
Violent Flows: Real-Time Detection of Violent Crowd Behavior,
T. Hassner, Y . Itcher, and O. Kliper-Gross, “Violent Flows: Real-Time Detection of Violent Crowd Behavior,” inCVPR Workshops, 2012, pp. 1–6
2012
-
[36]
An Overview of the PETS 2009 Challenge,
J. Ferryman and A. Shahrokni, “An Overview of the PETS 2009 Challenge,” 2009
2009
-
[37]
ChatGPT for Good? On Opportunities and Challenges of Large Language Models for Education,
E. Kasneci, K. Seßler, S. K ¨uchemannet al., “ChatGPT for Good? On Opportunities and Challenges of Large Language Models for Education,” Learning and Individual Differences, vol. 103, p. 102274, 2023
2023
-
[38]
Group Emotion Recognition in the Wild using Pose Estimation and LSTM Neural Networks,
K. Slogrove and D. Van Der Haar, “Group Emotion Recognition in the Wild using Pose Estimation and LSTM Neural Networks,” inInt. Conf. on AI, Big Data, Computing and Data Communication Systems, 2022, pp. 1–6
2022
-
[39]
Towards A Robust Group-Level Emotion Recognition Via Uncertainty-Aware Learning,
Q. Zhu, Q. Mao, J. Zhang, X. Huang, and W. Zheng, “Towards A Robust Group-Level Emotion Recognition Via Uncertainty-Aware Learning,” IEEE Transactions on Affective Computing, 2025. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 10
2025
-
[40]
Group Level Audio- Video Emotion Recognition Using Hybrid Networks,
C. Liu, W. Jiang, M. Wang, and T. Tang, “Group Level Audio- Video Emotion Recognition Using Hybrid Networks,” inInternational Conference on Multimodal Interaction, 2020, pp. 807–812
2020
-
[41]
Group- level emotion recognition using hybrid deep models based on faces, scenes, skeletons and visual attentions,
X. Guo, B. Zhu, L. F. Polan ´ıa, C. Boncelet, and K. E. Barner, “Group- level emotion recognition using hybrid deep models based on faces, scenes, skeletons and visual attentions,” inProceedings of the 20th ACM international conference on multimodal interaction, 2018, pp. 635–639
2018
-
[42]
Real-time video emotion recognition based on reinforcement learning and domain knowl- edge,
K. Zhang, Y . Li, J. Wang, E. Cambria, and X. Li, “Real-time video emotion recognition based on reinforcement learning and domain knowl- edge,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 32, no. 3, pp. 1034–1047, 2021
2021
-
[43]
Multimodal spatiotemporal semisupervised trans- former network for video-based group-level emotion recognition,
X. Huang and J. Xu, “Multimodal spatiotemporal semisupervised trans- former network for video-based group-level emotion recognition,”IEEE Transactions on Computational Social Systems, 2025
2025
-
[44]
An- alyzing Group-Level Emotion With Global Alignment Kernel Based Approach,
X. Huang, A. Dhall, R. Goecke, M. Pietik ¨ainen, and G. Zhao, “An- alyzing Group-Level Emotion With Global Alignment Kernel Based Approach,”IEEE Transactions on Affective Computing, vol. 13, no. 2, pp. 713–728, 2019
2019
-
[45]
Hierarchical Group-Level Emotion Recognition,
K. Fujii, D. Sugimura, and T. H., “Hierarchical Group-Level Emotion Recognition,”IEEE Transactions on Multimedia, vol. 23, pp. 3892– 3906, 2020
2020
-
[46]
ConGNN: Context-Consistent Cross-Graph Neural Network for Group Emotion Recognition in The Wild,
Y . Wanget al., “ConGNN: Context-Consistent Cross-Graph Neural Network for Group Emotion Recognition in The Wild,”Information Sciences, vol. 610, pp. 707–724, 2022
2022
-
[47]
Fusing Multimodal Streams for Improved Group Emotion Recognition in Videos,
D. Kumar, P. Dhamdhere, and B. Raman, “Fusing Multimodal Streams for Improved Group Emotion Recognition in Videos,” inInternational Conference on Pattern Recognition. Springer, 2025, pp. 403–418
2025
-
[48]
F. B. B. Bingham. (2000) Fast Forward Moving Picture Experts Group. https://ffmpeg.org/. Accessed 15 May 2025
2000
-
[49]
Emotions Revealed,
P. Ekman, “Emotions Revealed,”Emotions Revealed: Recognizing Faces and Feelings to Improve Communication and Emotional Life. XVII, vol. 267, 2003
2003
-
[50]
Labelbox for education,
Labelbox, “Labelbox for education,” https://labelbox.com/education/, 2024, accessed 15 Sep 2025
2024
-
[51]
Plutchik,Emotion: A Psychoevolutionary Synthesis
R. Plutchik,Emotion: A Psychoevolutionary Synthesis. New York: Harper & Row, 1980
1980
-
[52]
Interrater Reliability: The Kappa Statistic,
M. L. McHugh, “Interrater Reliability: The Kappa Statistic,”Biochemia Medica, vol. 22, no. 3, pp. 276–282, 2012
2012
-
[53]
Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models,
M. Maaz, H. Rasheed, S. Khan, and F. S. Khan, “Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models,” inAnnual Meeting of the Association for Computational Linguistics, 2024
2024
-
[54]
DINOv2: Learning Robust Visual Features without Supervision,
M. Oquab, T. Darcet, T. Moutakanniet al., “DINOv2: Learning Robust Visual Features without Supervision,” 2023, accessed 15 Sep 2025
2023
-
[55]
Wav2Vec 2.0: A Framework for Self- Supervised Learning of Speech Representations,
A. Baevski, Y . Zhouet al., “Wav2Vec 2.0: A Framework for Self- Supervised Learning of Speech Representations,”Advances in Neural Information Processing Systems, vol. 33, pp. 12 449–12 460, 2020
2020
-
[56]
Unsupervised Cross-lingual Representation Learning at Scale
A. Conneau, K. Khandelwal, N. Goyalet al., “Unsupervised Cross-lingual Representation Learning at Scale,”arXiv preprint arXiv:1911.02116, 2019, accessed 15 Sep 2025
work page internal anchor Pith review arXiv 1911
-
[57]
Explainable Human-Centered Traits From Head Motion and Facial Expression Dynamics,
S. Madan, M. Gahalawat, T. Guha, R. Goecke, and R. Subramanian, “Explainable Human-Centered Traits From Head Motion and Facial Expression Dynamics,”PloS one, vol. 20, no. 1, p. e0313883, 2025
2025
-
[58]
Multiview Attention Fusion for Explainable Body Language Behavior Recognition,
S. Madan, R. Jain, R. Subramanian, and A. Dhall, “Multiview Attention Fusion for Explainable Body Language Behavior Recognition,”IEEE Transactions on Affective Computing, 2025
2025
-
[59]
Video-gpt via next clip diffusion,
S. Zhuang, Z. Huang, Y . Zhang, F. Wang, C. Fu, B. Yang, C. Sun, C. Li, and Y . Wang, “Video-gpt via next clip diffusion,”arXiv preprint arXiv:2505.12489, 2025
-
[60]
Llava-next: A strong zero-shot video understanding model,
Y . Zhanget al., “Llava-next: A strong zero-shot video understanding model,” April 2024. [Online]. Available: https://llava-vl.github.io/blog /2024-04-30-llava-next-video/
2024
-
[61]
YouTube Terms of Service,
“YouTube Terms of Service,” https://www.youtube.com/static?templat e=terms, accessed 15 Sep 2025
2025
-
[62]
YouTube API Terms of Service,
“YouTube API Terms of Service,” https://developers.google.com/yout ube/terms/api-services-terms-of-service, accessed 15 Sep 2025
2025
-
[63]
“YouTube Privacy Guidelines,” https://support.google.com/youtube/ans wer/2797468, 2024, accessed 15 Sep 2025
-
[64]
Creative Commons Attribution 4.0 International License,
“Creative Commons Attribution 4.0 International License,” https://crea tivecommons.org/licenses/by/4.0/, accessed 15 Sep 2025. BIOGRAPHYSECTION Deepak Kumarreceived his B.Tech. and M.Tech. degrees in Computer Science and Engineering in 2012 and 2016, respectively, and his Ph.D. from the Indian Institute of Technology Roorkee, In- dia, in 2025. His researc...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.