Recognition: unknown
Where Do Vision-Language Models Fail? World Scale Analysis for Image Geolocalization
Pith reviewed 2026-05-10 08:28 UTC · model grok-4.3
The pith
Vision-language models show wide variation in zero-shot country prediction from ground-view images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Modern vision-language models exhibit substantial variation in performance when performing country-level geolocalization of ground-view images through zero-shot prompt-based prediction across three diverse datasets, demonstrating the potential of semantic reasoning for coarse geographic inference while revealing limitations in capturing fine-grained geographic cues.
What carries the argument
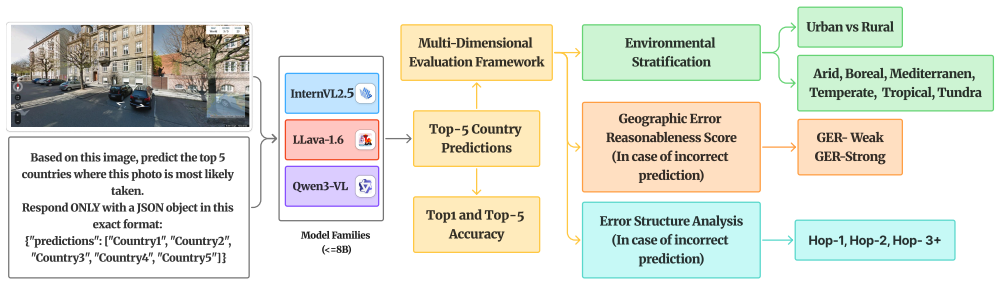
Zero-shot prompt-based country prediction on vision-language models evaluated across three geographically diverse ground-view image datasets.
If this is right
- Semantic reasoning in VLMs supports usable coarse country-level geolocalization from ground-view images.
- Current VLMs will continue to miss subtle geographic cues needed for finer distinctions.
- Performance differences across models will persist depending on architecture and training data.
- This zero-shot evaluation establishes a baseline for tracking progress in multimodal geographic reasoning.
Where Pith is reading between the lines
- Pairing VLMs with retrieval-based methods could compensate for their fine-grained weaknesses.
- Training data geographic imbalances likely contribute to the observed regional performance gaps.
- Extending the same prompt-based approach to city or landmark scale would test whether the coarse-to-fine pattern holds.
- Model choice will matter in any real-world system that uses VLMs for initial location filtering.
Load-bearing premise
The three chosen datasets and specific zero-shot prompts provide an unbiased test of VLM geographic inference without hidden selection effects or prompt sensitivity.
What would settle it
A new model achieving uniformly high accuracy across all three datasets or a different prompt producing reversed performance rankings on the same images would challenge the reported variation and limitations.
Figures

read the original abstract
Image geolocalization has traditionally been addressed through retrieval-based place recognition or geometry-based visual localization pipelines. Recent advances in Vision-Language Models (VLMs) have demonstrated strong zero-shot reasoning capabilities across multimodal tasks, yet their performance in geographic inference remains underexplored. In this work, we present a systematic evaluation of multiple state-of-the-art VLMs for country-level image geolocalization using ground-view imagery only. Instead of relying on image matching, GPS metadata, or task-specific training, we evaluate prompt-based country prediction in a zero-shot setting. The selected models are tested on three geographically diverse datasets to assess their robustness and generalization ability. Our results reveal substantial variation across models, highlighting the potential of semantic reasoning for coarse geolocalization and the limitations of current VLMs in capturing fine-grained geographic cues. This study provides the first focused comparison of modern VLMs for country-level geolocalization and establishes a foundation for future research at the intersection of multimodal reasoning and geographic understanding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a systematic zero-shot evaluation of multiple state-of-the-art Vision-Language Models for country-level image geolocalization from ground-view imagery alone. It tests the models via prompt-based country prediction on three geographically diverse datasets, avoiding retrieval, GPS metadata, or task-specific training, and reports substantial performance variation across models while highlighting semantic reasoning strengths for coarse localization and limitations for fine-grained geographic cues.
Significance. If the empirical findings prove robust, this work supplies a useful baseline comparison for assessing geographic understanding in VLMs, an area relevant to visual navigation, cultural analysis, and multimodal AI safety. The zero-shot, multi-model, multi-dataset design provides concrete evidence of current capabilities without confounding factors from fine-tuning, and the focus on failure modes offers actionable directions for improving semantic geographic reasoning.
major comments (2)
- The evaluation protocol section does not include the exact prompt templates, model versions, or decoding parameters used for country prediction. This detail is load-bearing for the central claim of 'substantial variation' because prompt sensitivity could alter the observed differences between models, directly affecting the weakest assumption that the chosen prompts provide an unbiased test.
- Results section and associated tables lack per-dataset accuracy breakdowns, confidence intervals, or error analysis (e.g., which countries are systematically confused). Without these, the claim that VLMs capture coarse but not fine-grained cues cannot be quantitatively verified and risks post-hoc interpretation of the observed outputs.
minor comments (2)
- The abstract would benefit from one or two key quantitative results (e.g., best-model accuracy range) to give readers an immediate sense of effect size.
- Figure captions and axis labels in the performance comparison plots should explicitly state the metric (top-1 country accuracy) and whether results are averaged across datasets.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will incorporate revisions to improve reproducibility and quantitative support for our claims.
read point-by-point responses
-
Referee: The evaluation protocol section does not include the exact prompt templates, model versions, or decoding parameters used for country prediction. This detail is load-bearing for the central claim of 'substantial variation' because prompt sensitivity could alter the observed differences between models, directly affecting the weakest assumption that the chosen prompts provide an unbiased test.
Authors: We agree that these implementation details are critical for reproducibility and for validating that the reported model variations are not artifacts of prompt choice. In the revised manuscript, we will add a new subsection to the evaluation protocol that lists the exact prompt templates (including any system prompts or few-shot examples if used), the precise model versions and checkpoints, and all decoding parameters such as temperature, top-p, and maximum token limits. This addition will directly address the concern and allow independent verification of the results. revision: yes
-
Referee: Results section and associated tables lack per-dataset accuracy breakdowns, confidence intervals, or error analysis (e.g., which countries are systematically confused). Without these, the claim that VLMs capture coarse but not fine-grained cues cannot be quantitatively verified and risks post-hoc interpretation of the observed outputs.
Authors: We acknowledge that the current results presentation would benefit from greater granularity to strengthen the evidence for our interpretations. We will revise the results section to include per-dataset accuracy tables, bootstrap-derived confidence intervals for all reported metrics, and an expanded error analysis subsection. This analysis will quantify common country-level confusions (e.g., neighboring countries or those sharing visual or semantic features) and explicitly link them to the distinction between coarse semantic reasoning and fine-grained geographic cues. Representative confusion examples and aggregate statistics will be provided to keep the presentation concise while improving verifiability. revision: yes
Circularity Check
No circularity: empirical evaluation only
full rationale
The paper is a zero-shot empirical study that runs existing VLMs on three public datasets with fixed prompts and reports observed country-level prediction accuracies. No equations, derivations, fitted parameters, or self-citation chains are present. All claims rest on direct model outputs rather than any reduction to author-defined quantities or prior self-referential results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The three geographically diverse datasets provide a fair test of country-level inference without selection bias.
Reference graph
Works this paper leans on
-
[1]
Netvlad: Cnn architecture for weakly supervised place recognition
Relja Arandjelovic, Petr Gronat, Akihiko Torii, Tomas Pa- jdla, and Josef Sivic. Netvlad: Cnn architecture for weakly supervised place recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5297–5307, 2016. 1, 2
2016
-
[2]
OpenStreetView-5M: The Many Roads to Global Visual Ge- olocation
Guillaume Astruc, Nicolas Dufour, Ioannis Siglidis, Con- stantin Aronssohn, Nacim Bouia, Stephanie Fu, Romain Loiseau, Van Nguyen Nguyen, Charles Raude, Elliot Vincent, Lintao Xu, Hongyu Zhou, and Loic Landrieu. OpenStreetView-5M: The Many Roads to Global Visual Ge- olocation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni...
2024
-
[3]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for understand- ing, localization, text reading, and beyond. 2023. doi: 10. 48550.arXiv preprint ARXIV .2308.12966. 1
work page internal anchor Pith review arXiv 2023
-
[4]
Deep visual geo-localization benchmark
Gabriele Berton, Riccardo Mereu, Gabriele Trivigno, Carlo Masone, Gabriela Csurka, Torsten Sattler, and Barbara Ca- puto. Deep visual geo-localization benchmark. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5396–5407, 2022. 2
2022
-
[5]
Adaptive-attentive geolocalization from few queries: A hybrid approach
Gabriele Moreno Berton, Valerio Paolicelli, Carlo Masone, and Barbara Caputo. Adaptive-attentive geolocalization from few queries: A hybrid approach. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 2918–2927, 2021. 1
2021
-
[6]
Ground-to-aerial image geo-localization with a hard exemplar reweighting triplet loss
Sudong Cai, Yulan Guo, Salman Khan, Jiwei Hu, and Gongjian Wen. Ground-to-aerial image geo-localization with a hard exemplar reweighting triplet loss. InProceedings of the IEEE/CVF international conference on computer vision, pages 8391–8400, 2019. 1
2019
-
[7]
Gaea: A geolocation aware conversational assistant, 2025
Ron Campos, Ashmal Vayani, Parth Parag Kulkarni, Rohit Gupta, Aritra Dutta, and Mubarak Shah. Gaea: A geolocation aware conversational assistant, 2025. 6
2025
-
[8]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhang- wei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling.arXiv preprint arXiv:2412.05271, 2024. 3
work page internal anchor Pith review arXiv 2024
-
[9]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24185–24198, 2024. 1
2024
-
[10]
RetinaFace: Single-Shot Multi- Level Face Localisation in the Wild
Jiankang Deng, Jia Guo, Evangelos Ververas, Irene Kotsia, and Stefanos Zafeiriou. RetinaFace: Single-Shot Multi- Level Face Localisation in the Wild. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5203–5212, 2020. 5
2020
-
[11]
Self-supervising fine-grained region similarities for large- scale image localization
Yixiao Ge, Haibo Wang, Feng Zhu, Rui Zhao, and Hongsheng Li. Self-supervising fine-grained region similarities for large- scale image localization. InEuropean conference on computer vision, pages 369–386. Springer, 2020. 1
2020
-
[12]
End-to-end learning of deep visual representations for image retrieval.International Journal of Computer Vision, 124(2):237–254, 2017
Albert Gordo, Jon Almazan, Jerome Revaud, and Diane Lar- lus. End-to-end learning of deep visual representations for image retrieval.International Journal of Computer Vision, 124(2):237–254, 2017. 2
2017
-
[13]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Aggregating local image descriptors into compact codes.IEEE transac- tions on pattern analysis and machine intelligence, 34(9): 1704–1716, 2011
Herv´e J ´egou, Florent Perronnin, Matthijs Douze, Jorge S´anchez, Patrick P´erez, and Cordelia Schmid. Aggregating local image descriptors into compact codes.IEEE transac- tions on pattern analysis and machine intelligence, 34(9): 1704–1716, 2011. 2
2011
-
[15]
Learned contextual feature reweighting for image geo- localization
Hyo Jin Kim, Enrique Dunn, and Jan-Michael Frahm. Learned contextual feature reweighting for image geo- localization. InProceedings of the IEEE conference on com- puter vision and pattern recognition, pages 2136–2145, 2017. 1
2017
-
[16]
GeoLocation – GeoGuessr Images (50K)
Rohan K. GeoLocation – GeoGuessr Images (50K). Kaggle,
-
[17]
Accessed: 2025. 4, 5
2025
-
[18]
CityGuessr: City-Level Video Geo-Localization on a Global Scale
Parth Parag Kulkarni, Gourav Kumar Nayak, and Mubarak Shah. CityGuessr: City-Level Video Geo-Localization on a Global Scale. InEuropean Conference on Computer Vision (ECCV), pages 289–306. Springer, 2024. 5
2024
-
[19]
Unleashing unlabeled data: A paradigm for cross-view geo-localization
Guopeng Li, Ming Qian, and Gui-Song Xia. Unleashing unlabeled data: A paradigm for cross-view geo-localization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16719–16729, 2024. 1
2024
-
[20]
Blip- 2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip- 2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning, pages 19730–19742. PMLR,
-
[21]
Densernet: Weakly supervised visual localization using multi-scale feature aggregation
Dongfang Liu, Yiming Cui, Liqi Yan, Christos Mousas, Bai- jian Yang, and Yingjie Chen. Densernet: Weakly supervised visual localization using multi-scale feature aggregation. In Proceedings of the AAAI conference on artificial intelligence, pages 6101–6109, 2021. 1
2021
-
[22]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023. 1, 2
2023
-
[23]
Llava-next: Improved reason- ing, ocr, and world knowledge, 2024
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llava-next: Improved reason- ing, ocr, and world knowledge, 2024. 3
2024
-
[24]
Globalgeotree: a multi-granular vision-language dataset for global tree species classification.Earth System Science Data, 18(2):1379–1403, 2026
Yang Mu, Zhitong Xiong, Yi Wang, Muhammad Shahzad, Franz Essl, Holger Kreft, Mark van Kleunen, and Xiao Xiang Zhu. Globalgeotree: a multi-granular vision-language dataset for global tree species classification.Earth System Science Data, 18(2):1379–1403, 2026. 2
2026
-
[25]
Fisher kernels on visual vocabularies for image categorization
Florent Perronnin and Christopher Dance. Fisher kernels on visual vocabularies for image categorization. In2007 IEEE conference on computer vision and pattern recognition, pages 1–8. IEEE, 2007. 2
2007
-
[26]
Large language models sensitivity to the order of options in multiple-choice questions.arXiv, 2023
Pouya Pezeshkpour and Estevam Hruschka. Large language models sensitivity to the order of options in multiple-choice questions.arXiv, 2023. 8
2023
-
[27]
Object retrieval with large vocabularies and fast spatial matching
James Philbin, Ondrej Chum, Michael Isard, Josef Sivic, and Andrew Zisserman. Object retrieval with large vocabularies and fast spatial matching. In2007 IEEE conference on com- puter vision and pattern recognition, pages 1–8. IEEE, 2007. 2
2007
-
[28]
Benchmarking image retrieval for visual localization
No´e Pion, Martin Humenberger, Gabriela Csurka, Yohann Cabon, and Torsten Sattler. Benchmarking image retrieval for visual localization. In2020 International Conference on 3D Vision (3DV), pages 483–494. IEEE, 2020. 2
2020
-
[29]
Zhaofang Qian, Hardy Chen, Zeyu Wang, Li Zhang, Zijun Wang, Xiaoke Huang, Hui Liu, Xianfeng Tang, Zeyu Zheng, Haoqin Tu, et al. Where on earth? a vision-language bench- mark for probing model geolocation skills across scales.arXiv preprint arXiv:2510.10880, 2025. 1
-
[30]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 1
2021
-
[31]
Charting new territories: Exploring the geographic and geospatial capabilities of multimodal llms
Jonathan Roberts, Timo L¨uddecke, Rehan Sheikh, Kai Han, and Samuel Albanie. Charting new territories: Exploring the geographic and geospatial capabilities of multimodal llms. arXiv preprint arXiv:2311.14656, 2024. 3
-
[32]
Semgeo: Seman- tic keywords for cross-view image geo-localization
Royston Rodrigues and Masahiro Tani. Semgeo: Seman- tic keywords for cross-view image geo-localization. In ICASSP 2023-2023 IEEE International Conference on Acous- tics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2023. 2
2023
-
[33]
Uav pose estimation using cross-view geolocalization with satellite imagery
Akshay Shetty and Grace Xingxin Gao. Uav pose estimation using cross-view geolocalization with satellite imagery. In 2019 International Conference on Robotics and Automation (ICRA), pages 1827–1833. IEEE, 2019. 1
2019
-
[34]
Order mat- ters: Exploring order sensitivity in multimodal large language models.arXiv, 2024
Zhijie Tan, Xu Chu, Weiping Li, and Tong Mo. Order mat- ters: Exploring order sensitivity in multimodal large language models.arXiv, 2024. 8
2024
-
[35]
Advancements in vision– language models for remote sensing: Datasets, capabilities, and enhancement techniques.Remote Sensing, 17(1):162,
Lijie Tao, Haokui Zhang, Haizhao Jing, Yu Liu, Dawei Yan, Guoting Wei, and Xizhe Xue. Advancements in vision– language models for remote sensing: Datasets, capabilities, and enhancement techniques.Remote Sensing, 17(1):162,
-
[36]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking mul- timodal understanding across millions of tokens of context, 2024.URL https://arxiv. org/abs/2403.05530, 2403, 2024. 2
work page internal anchor Pith review arXiv 2024
-
[37]
Qwen3 technical report, 2025
Qwen Team. Qwen3 technical report, 2025. 3
2025
-
[38]
Localizing and orienting street views using overhead imagery
Nam N V o and James Hays. Localizing and orienting street views using overhead imagery. InEuropean conference on computer vision, pages 494–509. Springer, 2016. 1
2016
-
[39]
Gama: Cross- view video geo-localization
Shruti Vyas, Chen Chen, and Mubarak Shah. Gama: Cross- view video geo-localization. InEuropean Conference on Computer Vision, pages 440–456. Springer, 2022. 2
2022
-
[40]
Chun Wang, Xiaojun Ye, Xiaoran Pan, Zihao Pan, Haofan Wang, and Yiren Song. Gre suite: Geo-localization infer- ence via fine-tuned vision-language models and enhanced reasoning chains.arXiv preprint arXiv:2505.18700, 2025. 2
-
[41]
On the location depen- dence of convolutional neural network features
Scott Workman and Nathan Jacobs. On the location depen- dence of convolutional neural network features. InProceed- ings of the IEEE conference on computer vision and pattern recognition workshops, pages 70–78, 2015. 1
2015
-
[42]
Where am i? cross- view geo-localization with natural language descriptions
Junyan Ye, Honglin Lin, Leyan Ou, Dairong Chen, Zihao Wang, Qi Zhu, Conghui He, and Weijia Li. Where am i? cross- view geo-localization with natural language descriptions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 5890–5900, 2025. 2
2025
-
[43]
Cross- view image sequence geo-localization
Xiaohan Zhang, Waqas Sultani, and Safwan Wshah. Cross- view image sequence geo-localization. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 2914–2923, 2023. 1
2023
-
[44]
Yushuo Zheng, Jiangyong Ying, Huiyu Duan, Chunyi Li, Zicheng Zhang, Jing Liu, Xiaohong Liu, and Guangtao Zhai. Geox-bench: Benchmarking cross-view geo-localization and pose estimation capabilities of large multimodal models. arXiv preprint arXiv:2511.13259, 2025. 1 Supplementary Material Where Do Vision-Language Models Fail? World Scale Analysis for Image...
-
[45]
I am showing you two images from two different locations in the world. For each image, predict the top 5 countries it is most likely from. Respond only in JSON format
Qualitative Analysis Table 7 presents qualitative examples of neighboring-country confusion produced byQwen3-VL-4B-Instructunder a blind two-turn prompting setup. Three image pairs are shown, each drawn from geographically close countries: (1) Pakistan vs. India, (2) Bangladesh vs. India, and (3) USA vs. Canada. For each pair, the model is given the same ...
-
[46]
Top-1: India✓
Canada Stone arch + arid landscape→defaulted to India. Top-1: India✓
-
[47]
Top-1: USA✗
Canada Ancient temple, stone fortification→India ranked #1. Top-1: USA✗
-
[48]
Top-1: India✗
Argentina Street sign + American-style lamppost mis- led model. Top-1: India✗
-
[49]
Top-1: USA✗
Vietnam Dense tropical forest→South/SE Asia. Top-1: USA✗
-
[50]
Top-1: USA✓
Mexico Suburban homes + fire hydrant→ de- faulted to USA. Top-1: USA✓
-
[51]
Mexico Fire hydrant + utility poles→USA ranked #1
-
[52]
It reports the frequency of each biome category under this strict consensus criterion, providing an overview of the recognized environmental classes across datasets
Biome Label Distribution Table 8 summarizes the distribution of consensus biome labels across the three datasets, considering only the samples where all three annotators-CLIP, SigLIP, and Qwen3-VL-4B-are in agreement. It reports the frequency of each biome category under this strict consensus criterion, providing an overview of the recognized environmenta...
-
[53]
a tropical rainforest or jungle scene
Biome Classification Prompts Table 9 lists the text prompts used for zero-shot biome classification. For CLIP and SigLIP, each prompt is used as a text embedding and the highest cosine similarity biome is assigned. For Qwen3-VL-4B, the six category names and descriptions are provided directly and the model is asked to select one. Table 9. Prompts used for...
-
[54]
The data highlights a dominant performance by the Qwen3-VL family, particularly the 2B and 4B variants, which achieve the highest scores in most categories
Top-5 Biome Accuracy Table 10 presents the Top-5 accuracy for nine Vision-Language Models (VLMs) across three datasets and six environmental biomes: Arid, Boreal, Mediterranean, Temperate, Tropical, and Tundra. The data highlights a dominant performance by the Qwen3-VL family, particularly the 2B and 4B variants, which achieve the highest scores in most c...
-
[55]
Top-1 accuracy improves from 40.40% to79.44%(+39.04 pp)
Preliminary LoRA Fine-Tuning To assess parameter-efficient fine-tuning, we fine-tune InternVL2.5-1B using LoRA ( r=8, α=32, all-linear modules) on a top-20 country subset of GeoGuessr-50k (12,116 train / 3,030 test images), training for 2 epochs at 5×10 −5. Top-1 accuracy improves from 40.40% to79.44%(+39.04 pp). The gain is larger for rural scenes (+45.9...
-
[56]
Full Urban/Rural and GER Tables Table 11 extends Table 4 (main paper) with per-cell standard deviations. Urban accuracy is highly stable across labellers (std < 1 pp for most cells), while rural variance reaches 5–6 pp, confirming that annotator disagreement concentrates on the rural boundary. Top-5 gaps are consistently narrower than Top-1, e.g., Qwen3-V...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.