Recognition: unknown
Hero-Mamba: Mamba-based Dual Domain Learning for Underwater Image Enhancement
Pith reviewed 2026-05-10 08:32 UTC · model grok-4.3
The pith
Hero-Mamba processes RGB images and FFT components in parallel with Mamba blocks to decouple color distortions from texture loss in underwater photos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
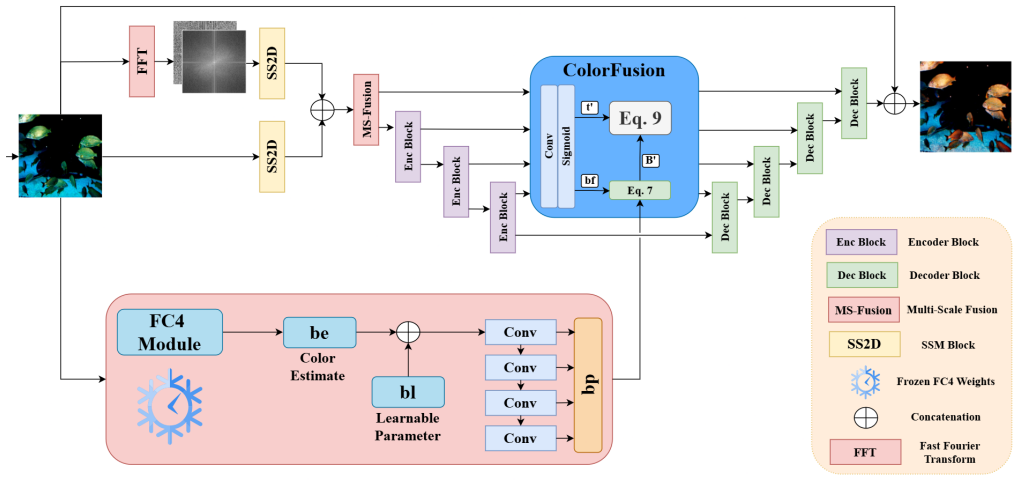
Hero-Mamba is a Mamba-based network for underwater image enhancement that processes spatial-domain RGB images and spectral-domain FFT components in parallel through SS2D blocks to capture long-range dependencies with linear complexity, then applies a ColorFusion block guided by a background light prior to restore color, producing higher PSNR and SSIM than prior methods on the LSUI and UIEB datasets.
What carries the argument
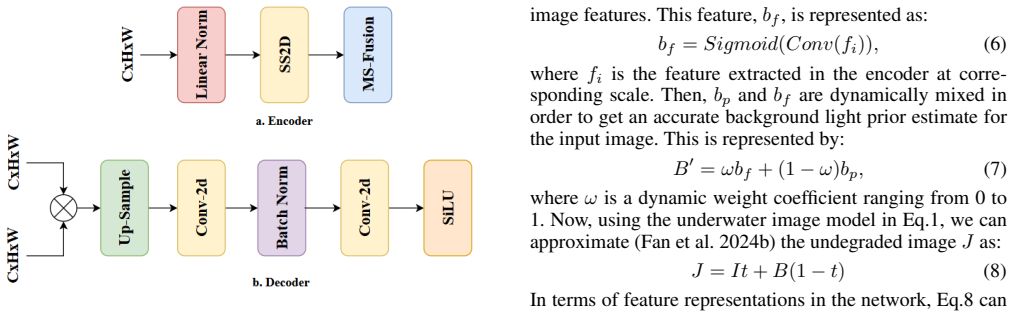
Mamba SS2D blocks running in parallel on RGB spatial inputs and FFT spectral inputs to model global dependencies linearly while separating color/brightness from texture/noise degradation.
If this is right
- The model achieves a PSNR of 25.802 and SSIM of 0.913 on the LSUI benchmark, exceeding state-of-the-art methods.
- Linear complexity allows the approach to scale to high-resolution images without the cost of quadratic attention.
- The ColorFusion block restores color information with high fidelity using the background light prior.
- The dual-domain design improves generalization across varied underwater scenes on both LSUI and UIEB.
Where Pith is reading between the lines
- The same parallel spatial-spectral pattern could be tested on other non-uniform degradations such as haze or low-light scenes.
- Replacing attention layers with these Mamba blocks in other vision restoration tasks may cut compute while keeping global context.
- Extending the architecture to video sequences would allow frame-to-frame consistency checks that single-image training cannot provide.
Load-bearing premise
That running Mamba blocks on both the RGB image and its FFT version at the same time will reliably separate color and brightness information from texture and noise across many different underwater conditions.
What would settle it
An ablation test on the LSUI dataset in which removing the parallel FFT branch produces no drop in PSNR or SSIM, or a new test set of underwater images on which Hero-Mamba falls below the best published CNN or Transformer scores.
Figures




read the original abstract
Underwater images often suffer from severe degradation, such as color distortion, low contrast, and blurred details, due to light absorption and scattering in water. While learning-based methods like CNNs and Transformers have shown promise, they face critical limitations: CNNs struggle to model the long-range dependencies needed for non-uniform degradation, and Transformers incur quadratic computational complexity, making them inefficient for high-resolution images. To address these challenges, we propose Hero-Mamba, a novel Mamba-based network that achieves efficient dual-domain learning for underwater image enhancement. Our approach uniquely processes information from both the spatial domain (RGB image) and the spectral domain (FFT components) in parallel. This dual-domain input allows the network to decouple degradation factors, separating color/brightness information from texture/noise. The core of our network utilizes Mamba-based SS2D blocks to capture global receptive fields and long-range dependencies with linear complexity, overcoming the limitations of both CNNs and Transformers. Furthermore, we introduce a ColorFusion block, guided by a background light prior, to restore color information with high fidelity. Extensive experiments on the LSUI and UIEB benchmark datasets demonstrate that Hero-Mamba outperforms state-of-the-art methods. Notably, our model achieves a PSNR of 25.802 and an SSIM of 0.913 on LSUI, validating its superior performance and generalization capabilities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Hero-Mamba, a Mamba-based network for underwater image enhancement that processes RGB spatial and FFT spectral domains in parallel via SS2D blocks to capture long-range dependencies at linear complexity. It introduces a ColorFusion block guided by a background light prior for color restoration and reports outperforming prior methods on the LSUI and UIEB benchmarks, with specific metrics of PSNR 25.802 and SSIM 0.913 on LSUI.
Significance. If the reported gains are attributable to the dual-domain Mamba design rather than tuning, the approach offers a computationally efficient alternative to Transformers for non-uniform underwater degradations. The parallel spatial-spectral processing and background-light-guided fusion represent a concrete attempt to separate degradation factors, which could benefit high-resolution marine vision tasks if properly validated.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): The manuscript reports benchmark superiority (PSNR 25.802 / SSIM 0.913 on LSUI) but supplies no training protocol, optimizer settings, data augmentation details, or ablation studies isolating the dual-domain input, SS2D blocks, or ColorFusion component. Without these, the central claim that the architecture outperforms SOTA cannot be evaluated against the possibility of hyperparameter-driven gains.
- [§3.2] §3.2 (Dual-domain design): The assertion that parallel RGB and FFT processing 'decouples color/brightness information from texture/noise' is presented without supporting analysis, feature visualizations, or quantitative metrics showing separation of degradation factors. This assumption is load-bearing for the network motivation yet remains untested in the provided experiments.
minor comments (2)
- [Figure 1] Figure 1 (architecture diagram): The flow from dual-domain inputs through SS2D blocks to ColorFusion could be annotated with tensor dimensions and skip connections to improve reproducibility.
- [§2] §2 (Related work): The discussion of Mamba variants in vision could include a brief complexity comparison table (e.g., vs. Swin Transformer) to contextualize the linear-complexity advantage.
Axiom & Free-Parameter Ledger
free parameters (2)
- Mamba block hyperparameters (state dimension, expansion factor)
- Background light prior estimation parameters
axioms (2)
- domain assumption Mamba SS2D blocks capture long-range dependencies with linear complexity
- ad hoc to paper Dual-domain input separates color/brightness from texture/noise
invented entities (1)
-
ColorFusion block
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Enhancing Un- derwater Imagery using Generative Adversarial Networks. arXiv:1801.04011. Fan, J.; Xu, J.; Zhou, J.; Meng, D.; and Lin, Y . 2024a. See through water: Heuristic modeling towards color correction for underwater image enhancement.IEEE Transactions on Circuits and Systems for Video Technology. Fan, J.; Xu, J.; Zhou, J.; Meng, D.; and Lin, Y . 20...
-
[2]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Mamba: Linear-Time Sequence Modeling with Selective State Spaces. arXiv:2312.00752. Gu, A.; Goel, K.; and R ´e, C
-
[3]
Efficiently Modeling Long Sequences with Structured State Spaces
Efficiently Mod- eling Long Sequences with Structured State Spaces. arXiv:2111.00396. Guan, M.; Xu, H.; Jiang, G.; Yu, M.; Chen, Y .; Luo, T.; and Song, Y
work page internal anchor Pith review arXiv
-
[4]
WaterMamba: Visual State Space Model for Underwater Image Enhancement. arXiv:2405.08419. Guo, C.; Wu, R.; Jin, X.; Han, L.; Chai, Z.; Zhang, W.; and Li, C
-
[5]
Underwater Ranker: Learn Which Is Better and How to Be Better. arXiv:2208.06857. Hu, Y .; Wang, B.; and Lin, S
-
[6]
FC 4: Fully Convolu- tional Color Constancy with Confidence-Weighted Pooling. 330–339. Huang, S.; Wang, K.; Liu, H.; Chen, J.; and Li, Y . 2023a. Contrastive Semi-supervised Learning for Underwater Im- age Restoration via Reliable Bank. arXiv:2303.09101. Huang, S.; Wang, K.; Liu, H.; Chen, J.; and Li, Y . 2023b. Contrastive Semi-supervised Learning for Un...
-
[7]
Underwater Image Enhancement via Adaptive Group Attention-Based Multiscale Cascade Transformer.IEEE Transactions on In- strumentation and Measurement, 71: 1–18. Islam, M. J.; Xia, Y .; and Sattar, J. 2020a. Fast Under- water Image Enhancement for Improved Visual Perception. arXiv:1903.09766. Islam, M. J.; Xia, Y .; and Sattar, J. 2020b. Fast Underwater Im...
-
[8]
Decoupled Weight Decay Regularization
Decoupled Weight De- cay Regularization. arXiv:1711.05101. McGlamery, B
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
CE-V AE: Capsule En- hanced Variational AutoEncoder for Underwater Image En- hancement. arXiv:2406.01294. Ren, T.; Xu, H.; Jiang, G.; Yu, M.; Zhang, X.; Wang, B.; and Luo, T
-
[10]
Efros, Eli Shechtman, and Oliver Wang
The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. arXiv:1801.03924. Zhang, S.; Duan, Y .; Li, D.; and Zhao, R
-
[11]
Mamba- UIE: Enhancing Underwater Images with Physical Model Constraint. arXiv:2407.19248. Zhao, C.; Cai, W.; Dong, C.; and Hu, C
-
[12]
Wavelet- based Fourier Information Interaction with Frequency Dif- fusion Adjustment for Underwater Image Restoration. arXiv:2311.16845. Zhou, J.; Liu, D.; Zhang, D.; and Zhang, W
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.