Recognition: unknown
Repurposing 3D Generative Model for Autoregressive Layout Generation
Pith reviewed 2026-05-10 08:05 UTC · model grok-4.3
The pith
LaviGen repurposes 3D generative models to generate 3D layouts autoregressively in native space while enforcing geometric and physical constraints among objects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
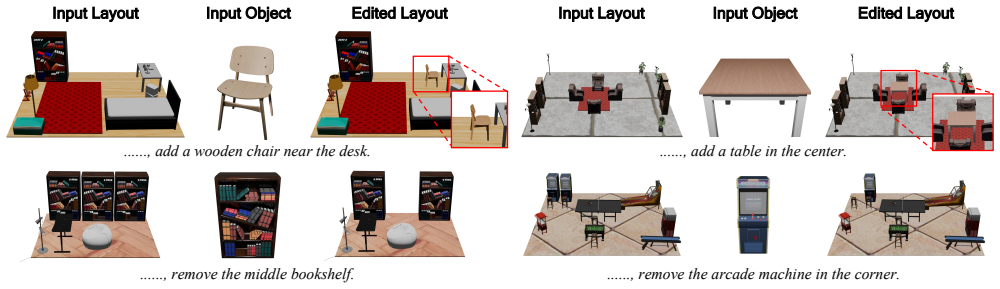
LaviGen formulates layout generation as an autoregressive process operating directly in native 3D space that explicitly models geometric relations and physical constraints among objects. It achieves this by repurposing a 3D generative model through an adapted diffusion component that integrates scene-level, object-level, and instruction-level information, together with a dual-guidance self-rollout distillation mechanism that improves efficiency and spatial accuracy.
What carries the argument
The adapted 3D diffusion model with dual-guidance self-rollout distillation, which fuses scene, object, and instruction signals to drive the autoregressive placement sequence.
If this is right
- Layouts are produced directly in 3D coordinates, yielding higher coherence than methods that first generate text descriptions.
- Physical plausibility improves because constraints are modeled inside the generation loop rather than applied afterward.
- Inference becomes substantially faster, supporting larger numbers of objects within practical time limits.
- The approach reduces reliance on separate post-processing validation steps or external simulators.
Where Pith is reading between the lines
- The same repurposing pattern could be tested on dynamic scenes that include object motion or interaction over time.
- If the distillation step generalizes, similar efficiency gains might appear when adapting other 3D generative backbones beyond diffusion models.
- Applications that need rapid scene construction, such as virtual environment authoring or robotic planning, could adopt the autoregressive 3D loop as a drop-in replacement for text-mediated pipelines.
Load-bearing premise
The adapted diffusion model and its distillation process are assumed to encode and enforce geometric relations and physical constraints sufficiently well without any explicit physics engine or extra validation data.
What would settle it
A head-to-head run on the LayoutVLM benchmark in which LaviGen fails to exceed prior methods by at least 19 percent in physical plausibility score or by at least 65 percent in computation speed.
Figures









read the original abstract
We introduce LaviGen, a framework that repurposes 3D generative models for 3D layout generation. Unlike previous methods that infer object layouts from textual descriptions, LaviGen operates directly in the native 3D space, formulating layout generation as an autoregressive process that explicitly models geometric relations and physical constraints among objects, producing coherent and physically plausible 3D scenes. To further enhance this process, we propose an adapted 3D diffusion model that integrates scene, object, and instruction information and employs a dual-guidance self-rollout distillation mechanism to improve efficiency and spatial accuracy. Extensive experiments on the LayoutVLM benchmark show LaviGen achieves superior 3D layout generation performance, with 19% higher physical plausibility than the state of the art and 65% faster computation. Our code is publicly available at https://github.com/fenghora/LaviGen.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LaviGen, a framework that repurposes 3D generative models for autoregressive 3D layout generation directly in native 3D space. It formulates layout generation as an autoregressive process that explicitly models geometric relations and physical constraints among objects. The core technical contributions are an adapted 3D diffusion model integrating scene/object/instruction conditioning and a dual-guidance self-rollout distillation mechanism for improved efficiency and spatial accuracy. Experiments on the LayoutVLM benchmark report 19% higher physical plausibility and 65% faster computation than prior state-of-the-art methods, with code released publicly.
Significance. If the performance claims and implicit constraint enforcement hold under scrutiny, the work offers a promising direction for efficient, physics-aware 3D scene synthesis without external simulators. Public code release strengthens reproducibility. However, the absence of error bars, ablations, and metric derivations in the reported results limits the assessed significance at present.
major comments (3)
- [Abstract] Abstract: The headline claim of 19% higher physical plausibility lacks error bars, confidence intervals, or statistical significance tests, preventing verification that the gain exceeds baseline variability.
- [Abstract] Abstract: No ablation studies or derivation are supplied for the dual-guidance self-rollout distillation, so it is impossible to isolate its contribution to the reported spatial accuracy and speed gains.
- [Abstract] Abstract: The assertion that the adapted diffusion model 'explicitly models' geometric relations and physical constraints (e.g., non-interpenetration, stability) without an external physics engine or extra validation data is unsupported by any equation, conditioning analysis, or out-of-distribution test showing how violations are prevented during autoregressive rollout.
minor comments (1)
- [Abstract] The abstract would benefit from naming the specific state-of-the-art baselines used for the 19% and 65% comparisons.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below and have revised the manuscript to incorporate additional supporting details, statistical measures, and clarifications where the original presentation was insufficient.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claim of 19% higher physical plausibility lacks error bars, confidence intervals, or statistical significance tests, preventing verification that the gain exceeds baseline variability.
Authors: We agree that the abstract should include measures of variability to support the headline claim. In the revised manuscript, we have updated the abstract to report the 19% improvement with error bars (standard deviation across 5 random seeds) and added a note that the gain is statistically significant (p < 0.05, paired t-test). The full per-scene results with variability are already detailed in Table 2 of the experiments section. revision: yes
-
Referee: [Abstract] Abstract: No ablation studies or derivation are supplied for the dual-guidance self-rollout distillation, so it is impossible to isolate its contribution to the reported spatial accuracy and speed gains.
Authors: The manuscript contains ablation studies in Section 4.3 that quantify the contribution of the dual-guidance self-rollout distillation to both spatial accuracy and inference speed. We have revised the abstract to reference these results concisely. We have also added a short derivation of the distillation objective in Section 3.2 of the revised methods to clarify its formulation. revision: yes
-
Referee: [Abstract] Abstract: The assertion that the adapted diffusion model 'explicitly models' geometric relations and physical constraints (e.g., non-interpenetration, stability) without an external physics engine or extra validation data is unsupported by any equation, conditioning analysis, or out-of-distribution test showing how violations are prevented during autoregressive rollout.
Authors: The model enforces constraints implicitly by conditioning the diffusion process on scene context, prior objects, and instructions, with training performed exclusively on valid layouts; no external simulator is used at inference. To strengthen the claim, we have added the explicit conditioning equations in Section 3.1 and included an out-of-distribution test (Section 4.4) that measures constraint violation rates during rollout. We have also softened the abstract wording from 'explicitly models' to 'models via learned conditioning' for precision. revision: partial
Circularity Check
No circularity in derivation chain; claims rest on external benchmarks
full rationale
The paper describes LaviGen as repurposing a 3D generative model into an autoregressive layout generator that explicitly models geometric relations and physical constraints via an adapted diffusion model with dual-guidance self-rollout distillation. No equations, derivations, or first-principles steps are presented that reduce the reported 19% plausibility gain or 65% speed improvement to quantities defined by fitted parameters inside the same paper or by self-referential definitions. Performance is evaluated via direct comparison on the external LayoutVLM benchmark, rendering the central claims self-contained and non-circular.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Qwen2.5-vl technical report
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhao- hai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Jun- yang Lin. Qwen2.5-vl technical repor...
2025
-
[3]
Diffusion forcing: Next-token prediction meets full-sequence diffu- sion.Advances in Neural Information Processing Systems, 37:24081–24125, 2024
Boyuan Chen, Diego Mart ´ı Mons´o, Yilun Du, Max Sim- chowitz, Russ Tedrake, and Vincent Sitzmann. Diffusion forcing: Next-token prediction meets full-sequence diffu- sion.Advances in Neural Information Processing Systems, 37:24081–24125, 2024. 3
2024
-
[4]
SkyReels-V2: Infinite-length Film Generative Model
Guibin Chen, Dixuan Lin, Jiangping Yang, Chunze Lin, Juncheng Zhu, Mingyuan Fan, Hao Zhang, Sheng Chen, Zheng Chen, Chengchen Ma, et al. Skyreels- v2: Infinite-length film generative model.arXiv preprint arXiv:2504.13074, 2025. 3
work page internal anchor Pith review arXiv 2025
-
[5]
Meshxl: Neural coordinate field for generative 3d foundation models.Advances in Neural Information Pro- cessing Systems, 37:97141–97166, 2024
Sijin Chen, Xin Chen, Anqi Pang, Xianfang Zeng, Wei Cheng, Yijun Fu, Fukun Yin, Zhibin Wang, Jingyi Yu, Gang Yu, et al. Meshxl: Neural coordinate field for generative 3d foundation models.Advances in Neural Information Pro- cessing Systems, 37:97141–97166, 2024. 3
2024
-
[6]
Meshanything: Artist- created mesh generation with autoregressive transformers,
Yiwen Chen, Tong He, Di Huang, Weicai Ye, Sijin Chen, Jiaxiang Tang, Xin Chen, Zhongang Cai, Lei Yang, Gang Yu, Guosheng Lin, and Chi Zhang. Meshanything: Artist- created mesh generation with autoregressive transformers,
-
[7]
Ultra3d: Efficient and high- fidelity 3d generation with part attention, 2025
Yiwen Chen, Zhihao Li, Yikai Wang, Hu Zhang, Qin Li, Chi Zhang, and Guosheng Lin. Ultra3d: Efficient and high- fidelity 3d generation with part attention, 2025. 3
2025
-
[8]
Abo: Dataset and benchmarks for real-world 3d ob- ject understanding
Jasmine Collins, Shubham Goel, Kenan Deng, Achlesh- war Luthra, Leon Xu, Erhan Gundogdu, Xi Zhang, Tomas F Yago Vicente, Thomas Dideriksen, Himanshu Arora, et al. Abo: Dataset and benchmarks for real-world 3d ob- ject understanding. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 21126–21136, 2022. 6
2022
-
[9]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blis- tein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodal- ity, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
arXiv preprint arXiv:2510.02283 (2025)
Justin Cui, Jie Wu, Ming Li, Tao Yang, Xiaojie Li, Rui Wang, Andrew Bai, Yuanhao Ban, and Cho-Jui Hsieh. Self- forcing++: Towards minute-scale high-quality video gener- ation.arXiv preprint arXiv:2510.02283, 2025. 3
-
[11]
Objaverse-xl: A universe of 10m+ 3d objects.Advances in Neural Information Processing Systems, 36:35799–35813,
Matt Deitke, Ruoshi Liu, Matthew Wallingford, Huong Ngo, Oscar Michel, Aditya Kusupati, Alan Fan, Chris- tian Laforte, Vikram V oleti, Samir Yitzhak Gadre, et al. Objaverse-xl: A universe of 10m+ 3d objects.Advances in Neural Information Processing Systems, 36:35799–35813,
-
[12]
Objaverse: A universe of annotated 3d objects
Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. Objaverse: A universe of annotated 3d objects. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13142–13153, 2023. 3
2023
-
[13]
Objaverse-xl: A universe of 10m+ 3d objects.Advances in Neural Information Processing Systems, 36, 2024
Matt Deitke, Ruoshi Liu, Matthew Wallingford, Huong Ngo, Oscar Michel, Aditya Kusupati, Alan Fan, Chris- tian Laforte, Vikram V oleti, Samir Yitzhak Gadre, et al. Objaverse-xl: A universe of 10m+ 3d objects.Advances in Neural Information Processing Systems, 36, 2024. 3
2024
-
[14]
Tela: Text to layer-wise 3d clothed human generation
Junting Dong, Qi Fang, Zehuan Huang, Xudong Xu, Jingbo Wang, Sida Peng, and Bo Dai. Tela: Text to layer-wise 3d clothed human generation. InEuropean Conference on Computer Vision, pages 19–36. Springer, 2025. 3
2025
-
[15]
From one to more: Contex- tual part latents for 3d generation
Shaocong Dong, Lihe Ding, Xiao Chen, Yaokun Li, Yuxin Wang, Yucheng Wang, Qi Wang, Jaehyeok Kim, Chenjian Gao, Zhanpeng Huang, et al. From one to more: Contex- tual part latents for 3d generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 8230–8240, 2025. 3
2025
-
[16]
The llama 3 herd of models.arXiv e-prints, pages arXiv–2407,
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Ab- hishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models.arXiv e-prints, pages arXiv–2407,
-
[17]
Scaling recti- fied flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M ¨uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling recti- fied flow transformers for high-resolution image synthesis. InForty-first international conference on machine learning,
-
[18]
Layoutgpt: Compositional vi- sual planning and generation with large language models
Weixi Feng, Wanrong Zhu, Tsu-jui Fu, Varun Jampani, Arjun Akula, Xuehai He, Sugato Basu, Xin Eric Wang, and William Yang Wang. Layoutgpt: Compositional vi- sual planning and generation with large language models. Advances in Neural Information Processing Systems, 36: 18225–18250, 2023. 1, 2, 3, 4, 6, 7, 8
2023
-
[19]
3d-future: 3d furniture shape with texture.International Journal of Com- puter Vision, 129(12):3313–3337, 2021
Huan Fu, Rongfei Jia, Lin Gao, Mingming Gong, Binqiang Zhao, Steve Maybank, and Dacheng Tao. 3d-future: 3d furniture shape with texture.International Journal of Com- puter Vision, 129(12):3313–3337, 2021. 6
2021
-
[20]
Me- shart: Generating articulated meshes with structure-guided transformers
Daoyi Gao, Yawar Siddiqui, Lei Li, and Angela Dai. Me- shart: Generating articulated meshes with structure-guided transformers. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 618–627, 2025. 3
2025
-
[21]
Ca2-vdm: Efficient autoregres- sive video diffusion model with causal generation and cache sharing
Kaifeng Gao, Jiaxin Shi, Hanwang Zhang, Chunping Wang, Jun Xiao, and Long Chen. Ca2-vdm: Efficient autoregres- sive video diffusion model with causal generation and cache sharing. InICML. PMLR, 2025. 3
2025
-
[22]
Long video generation with time-agnostic vqgan and time- sensitive transformer
Songwei Ge, Thomas Hayes, Harry Yang, Xi Yin, Guan Pang, David Jacobs, Jia-Bin Huang, and Devi Parikh. Long video generation with time-agnostic vqgan and time- sensitive transformer. InECCV, 2022. 3
2022
-
[23]
Long-context autoregressive video modeling with next-frame prediction
Yuchao Gu, Weijia Mao, and Mike Zheng Shou. Long- context autoregressive video modeling with next-frame pre- diction.arXiv preprint arXiv:2503.19325, 2025. 3
-
[24]
Zeqi Gu, Yin Cui, Zhaoshuo Li, Fangyin Wei, Yunhao Ge, Jinwei Gu, Ming-Yu Liu, Abe Davis, and Yifan Ding. Artiscene: Language-driven artistic 3d scene generation through image intermediary.2025 IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 2891–2901, 2025. 1, 2
2025
-
[25]
Romero, Tsung-Yi Lin, and Ming-Yu Liu
Zekun Hao, David W. Romero, Tsung-Yi Lin, and Ming-Yu Liu. Meshtron: High-fidelity, artist-like 3d mesh generation at scale, 2024. 3
2024
-
[26]
Neural lightrig: Unlocking accurate object normal and material estimation with multi-light diffusion
Zexin He, Tengfei Wang, Xin Huang, Xingang Pan, and Zi- wei Liu. Neural lightrig: Unlocking accurate object normal and material estimation with multi-light diffusion. InPro- ceedings of the Computer Vision and Pattern Recognition Conference, pages 26514–26524, 2025. 3
2025
-
[27]
Classifier-free diffusion guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. InarXiv, 2022. 1
2022
-
[28]
Denoising dif- fusion probabilistic models.Advances in neural informa- tion processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models.Advances in neural informa- tion processing systems, 33:6840–6851, 2020. 3
2020
-
[29]
Cogvideo: Large-scale pretraining for text-to- video generation via transformers
Wenyi Hong, Ming Ding, Wendi Zheng, Xinghan Liu, and Jie Tang. Cogvideo: Large-scale pretraining for text-to- video generation via transformers. InICLR, 2023. 3
2023
-
[30]
LRM: Large Reconstruction Model for Single Image to 3D
Yicong Hong, Kai Zhang, Jiuxiang Gu, Sai Bi, Yang Zhou, Difan Liu, Feng Liu, Kalyan Sunkavalli, Trung Bui, and Hao Tan. Lrm: Large reconstruction model for single image to 3d.arXiv preprint arXiv:2311.04400, 2023. 3
work page internal anchor Pith review arXiv 2023
-
[31]
arXiv preprint arXiv:2412.07720 (2024)
Jinyi Hu, Shengding Hu, Yuxuan Song, Yufei Huang, Mingxuan Wang, Hao Zhou, Zhiyuan Liu, Wei-Ying Ma, and Maosong Sun. Acdit: Interpolating autoregressive con- ditional modeling and diffusion transformer.arXiv preprint arXiv:2412.07720, 2024. 3
-
[32]
Junchao Huang, Xinting Hu, Boyao Han, Shaoshuai Shi, Zhuotao Tian, Tianyu He, and Li Jiang. Memory forcing: Spatio-temporal memory for consistent scene generation on minecraft.arXiv preprint arXiv:2510.03198, 2025. 3
-
[33]
Stereo-gs: Multi-view stereo vision model for generalizable 3d gaussian splatting reconstruc- tion
Xiufeng Huang, Ka Chun Cheung, Runmin Cong, Simon See, and Renjie Wan. Stereo-gs: Multi-view stereo vision model for generalizable 3d gaussian splatting reconstruc- tion. InProceedings of the 33rd ACM International Con- ference on Multimedia, pages 9822–9831, 2025. 3
2025
-
[34]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train- test gap in autoregressive video diffusion.arXiv preprint arXiv:2506.08009, 2025. 2, 3, 5
work page internal anchor Pith review arXiv 2025
-
[35]
Epidiff: Enhancing multi-view syn- thesis via localized epipolar-constrained diffusion
Zehuan Huang, Hao Wen, Junting Dong, Yaohui Wang, Yangguang Li, Xinyuan Chen, Yan-Pei Cao, Ding Liang, Yu Qiao, Bo Dai, et al. Epidiff: Enhancing multi-view syn- thesis via localized epipolar-constrained diffusion. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9784–9794, 2024. 3
2024
-
[36]
Midi: Multi-instance diffusion for single image to 3d scene generation
Zehuan Huang, Yuan-Chen Guo, Xingqiao An, Yunhan Yang, Yangguang Li, Zi-Xin Zou, Ding Liang, Xihui Liu, Yan-Pei Cao, and Lu Sheng. Midi: Multi-instance diffusion for single image to 3d scene generation. InProceedings of the Computer Vision and Pattern Recognition Conference,
-
[37]
Mv-adapter: Multi-view consistent image generation made easy
Zehuan Huang, Yuan-Chen Guo, Haoran Wang, Ran Yi, Lizhuang Ma, Yan-Pei Cao, and Lu Sheng. Mv-adapter: Multi-view consistent image generation made easy. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 16377–16387, 2025. 3
2025
-
[38]
Lite- reality: Graphics-ready 3d scene reconstruction from rgb-d scans, 2025
Zhening Huang, Xiaoyang Wu, Fangcheng Zhong, Heng- shuang Zhao, Matthias Nießner, and Joan Lasenby. Lite- reality: Graphics-ready 3d scene reconstruction from rgb-d scans, 2025. 1
2025
-
[39]
Octree transformer: Autoregressive 3d shape generation on hi- erarchically structured sequences
Moritz Ibing, Gregor Kobsik, and Leif Kobbelt. Octree transformer: Autoregressive 3d shape generation on hi- erarchically structured sequences. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2698–2707, 2023. 3
2023
-
[40]
Pyramidal flow matching for efficient video generative modeling
Yang Jin, Zhicheng Sun, Ningyuan Li, Kun Xu, Hao Jiang, Nan Zhuang, Quzhe Huang, Yang Song, Yadong Mu, and Zhouchen Lin. Pyramidal flow matching for efficient video generative modeling. InICLR, 2025. 3
2025
-
[41]
Habitat synthetic scenes dataset (hssd-200): An analysis of 3d scene scale and realism tradeoffs for objectgoal naviga- tion
Mukul Khanna, Yongsen Mao, Hanxiao Jiang, Sanjay Haresh, Brennan Shacklett, Dhruv Batra, Alexander Clegg, Eric Undersander, Angel X Chang, and Manolis Savva. Habitat synthetic scenes dataset (hssd-200): An analysis of 3d scene scale and realism tradeoffs for objectgoal naviga- tion. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern...
-
[42]
Auto-Encoding Variational Bayes
Diederik P Kingma. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013. 3
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[43]
Videopoet: A large language model for zero-shot video generation
Dan Kondratyuk, Lijun Yu, Xiuye Gu, Jose Lezama, Jonathan Huang, Grant Schindler, Rachel Hornung, Vigh- nesh Birodkar, Jimmy Yan, Ming-Chang Chiu, et al. Videopoet: A large language model for zero-shot video generation. InICML, 2024. 3
2024
-
[44]
Songlin Li, Despoina Paschalidou, and Leonidas Guibas. Pasta: Controllable part-aware shape genera- tion with autoregressive transformers.arXiv preprint arXiv:2407.13677, 2024. 3
-
[45]
Weiyu Li, Jiarui Liu, Rui Chen, Yixun Liang, Xuelin Chen, Ping Tan, and Xiaoxiao Long. Craftsman: High-fidelity mesh generation with 3d native generation and interactive geometry refiner.arXiv preprint arXiv:2405.14979, 2024. 3
-
[46]
Craftsman3d: High-fidelity mesh generation with 3d native diffusion and interactive geometry refiner
Weiyu Li, Jiarui Liu, Hongyu Yan, Rui Chen, Yixun Liang, Xuelin Chen, Ping Tan, and Xiaoxiao Long. Craftsman3d: High-fidelity mesh generation with 3d native diffusion and interactive geometry refiner. InProceedings of the Com- puter Vision and Pattern Recognition Conference, pages 5307–5317, 2025. 3
2025
-
[47]
Step1x- 3d: Towards high-fidelity and controllable generation of textured 3d assets, 2025
Weiyu Li, Xuanyang Zhang, Zheng Sun, Di Qi, Hao Li, Wei Cheng, Weiwei Cai, Shihao Wu, Jiarui Liu, Zihao Wang, Xiao Chen, Feipeng Tian, Jianxiong Pan, Zeming Li, Gang Yu, Xiangyu Zhang, Daxin Jiang, and Ping Tan. Step1x- 3d: Towards high-fidelity and controllable generation of textured 3d assets, 2025. 3
2025
-
[49]
Triposg: High-fidelity 3d shape synthesis using large-scale rectified flow models.IEEE Transactions on Pattern Analysis and Machine Intelligence,
Yangguang Li, Zi-Xin Zou, Zexiang Liu, Dehu Wang, Yuan Liang, Zhipeng Yu, Xingchao Liu, Yuan-Chen Guo, Ding Liang, Wanli Ouyang, et al. Triposg: High-fidelity 3d shape synthesis using large-scale rectified flow models.IEEE Transactions on Pattern Analysis and Machine Intelligence,
-
[50]
Instructscene: Instruction- driven 3d indoor scene synthesis with semantic graph prior
Chenguo Lin and Yadong Mu. Instructscene: Instruction- driven 3d indoor scene synthesis with semantic graph prior. InInternational Conference on Learning Representations (ICLR), 2024. 1, 2
2024
-
[51]
Partcrafter: Structured 3d mesh generation via composi- tional latent diffusion transformers, 2025
Yuchen Lin, Chenguo Lin, Panwang Pan, Honglei Yan, Yiqiang Feng, Yadong Mu, and Katerina Fragkiadaki. Partcrafter: Structured 3d mesh generation via composi- tional latent diffusion transformers, 2025. 3
2025
-
[52]
arXiv preprint arXiv:2505.02836 (2025)
Lu Ling, Chen-Hsuan Lin, Tsung-Yi Lin, Yifan Ding, Yu Zeng, Yichen Sheng, Yunhao Ge, Ming-Yu Liu, Aniket Bera, and Zhaoshuo Li. Scenethesis: Combining language and visual priors for 3d scene generation.arXiv preprint arXiv:2505.02836, 2025. 1, 2, 3
-
[53]
Part123: part-aware 3d reconstruction from a single-view image
Anran Liu, Cheng Lin, Yuan Liu, Xiaoxiao Long, Zhiyang Dou, Hao-Xiang Guo, Ping Luo, and Wenping Wang. Part123: part-aware 3d reconstruction from a single-view image. InACM SIGGRAPH 2024 Conference Papers, pages 1–12, 2024. 3
2024
-
[54]
Rolling forcing: Autoregressive long video diffusion in real time, 2025
Kunhao Liu, Wenbo Hu, Jiale Xu, Ying Shan, and Shijian Lu. Rolling forcing: Autoregressive long video diffusion in real time, 2025. 3
2025
-
[55]
One-2-3-45++: Fast single image to 3d objects with consistent multi-view generation and 3d diffusion
Minghua Liu, Ruoxi Shi, Linghao Chen, Zhuoyang Zhang, Chao Xu, Xinyue Wei, Hansheng Chen, Chong Zeng, Ji- ayuan Gu, and Hao Su. One-2-3-45++: Fast single image to 3d objects with consistent multi-view generation and 3d diffusion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10072– 10083, 2024. 3
2024
-
[56]
One-2-3-45: Any sin- gle image to 3d mesh in 45 seconds without per-shape opti- mization.Advances in Neural Information Processing Sys- tems, 36, 2024
Minghua Liu, Chao Xu, Haian Jin, Linghao Chen, Mukund Varma T, Zexiang Xu, and Hao Su. One-2-3-45: Any sin- gle image to 3d mesh in 45 seconds without per-shape opti- mization.Advances in Neural Information Processing Sys- tems, 36, 2024. 3
2024
-
[57]
arXiv preprint arXiv:2505.20129 (2025)
Xinhang Liu, Yu-Wing Tai, and Chi-Keung Tang. Agen- tic 3d scene generation with spatially contextualized vlms. arXiv preprint arXiv:2505.20129, 2025. 1
-
[58]
Yuan Liu, Cheng Lin, Zijiao Zeng, Xiaoxiao Long, Lingjie Liu, Taku Komura, and Wenping Wang. Syncdreamer: Generating multiview-consistent images from a single-view image.arXiv preprint arXiv:2309.03453, 2023. 3
-
[59]
Wonder3d: Single image to 3d using cross-domain diffusion
Xiaoxiao Long, Yuan-Chen Guo, Cheng Lin, Yuan Liu, Zhiyang Dou, Lingjie Liu, Yuexin Ma, Song-Hai Zhang, Marc Habermann, Christian Theobalt, et al. Wonder3d: Single image to 3d using cross-domain diffusion. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9970–9980, 2024. 3
2024
-
[60]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InarXiv, 2019. 1
2019
-
[61]
Uni-3dar: Unified 3d generation and understanding via autoregression on compressed spatial tokens.Arxiv, 2025
Shuqi Lu, Haowei Lin, Lin Yao, Zhifeng Gao, Xiaohong Ji, Weinan E, Linfeng Zhang, and Guolin Ke. Uni-3dar: Unified 3d generation and understanding via autoregression on compressed spatial tokens.Arxiv, 2025. 3
2025
-
[62]
Spatiallm: Training large language models for structured indoor mod- eling
Yongsen Mao, Junhao Zhong, Chuan Fang, Jia Zheng, Rui Tang, Hao Zhu, Ping Tan, and Zihan Zhou. Spatiallm: Training large language models for structured indoor mod- eling. InAdvances in Neural Information Processing Sys- tems, 2025. 1, 2, 3
2025
-
[63]
Lt3sd: Latent trees for 3d scene diffusion
Quan Meng, Lei Li, Matthias Nießner, and Angela Dai. Lt3sd: Latent trees for 3d scene diffusion. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 650–660, 2025. 3
2025
-
[64]
Sce- negen: Single-image 3d scene generation in one feedfor- ward pass
Yanxu Meng, Haoning Wu, Ya Zhang, and Weidi Xie. Sce- negen: Single-image 3d scene generation in one feedfor- ward pass. InarXiv, 2025. 1, 2
2025
-
[65]
Polygen: An autoregressive generative model of 3d meshes
Charlie Nash, Yaroslav Ganin, SM Ali Eslami, and Peter Battaglia. Polygen: An autoregressive generative model of 3d meshes. InInternational conference on machine learn- ing, pages 7220–7229. PMLR, 2020. 3
2020
-
[66]
Atiss: Autoregressive transformers for indoor scene synthesis
Despoina Paschalidou, Amlan Kar, Maria Shugrina, Karsten Kreis, Andreas Geiger, and Sanja Fidler. Atiss: Autoregressive transformers for indoor scene synthesis. Advances in neural information processing systems, 34: 12013–12026, 2021. 1, 2, 3, 4
2021
-
[67]
Scalable diffusion mod- els with transformers
William Peebles and Saining Xie. Scalable diffusion mod- els with transformers. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision, pages 4195– 4205, 2023. 3
2023
-
[68]
Deocc-1-to- 3: 3d de-occlusion from a single image via self-supervised multi-view diffusion
Yansong Qu, Shaohui Dai, Xinyang Li, Yuze Wang, You Shen, Shengchuan Zhang, and Liujuan Cao. Deocc-1-to- 3: 3d de-occlusion from a single image via self-supervised multi-view diffusion. InProceedings of the AAAI Confer- ence on Artificial Intelligence, pages 8677–8685, 2026. 3
2026
-
[69]
L3dg: Latent 3d gaussian diffusion
Barbara Roessle, Norman M ¨uller, Lorenzo Porzi, Samuel Rota Bul `o, Peter Kontschieder, Angela Dai, and Matthias Nießner. L3dg: Latent 3d gaussian diffusion. InSIG- GRAPH Asia 2024 Conference Papers, pages 1–11, 2024. 3
2024
-
[70]
Magi-1: Autoregressive video generation at scale,
Sand-AI. Magi-1: Autoregressive video generation at scale,
-
[71]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020. 3
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[72]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568: 127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568: 127063, 2024. 4
2024
-
[73]
Layoutvlm: Differentiable optimization of 3d lay- out via vision-language models
Fan-Yun Sun, Weiyu Liu, Siyi Gu, Dylan Lim, Goutam Bhat, Federico Tombari, Manling Li, Nick Haber, and Jia- jun Wu. Layoutvlm: Differentiable optimization of 3d lay- out via vision-language models. InProceedings of the Com- puter Vision and Pattern Recognition Conference, pages 29469–29478, 2025. 2, 3, 4, 6, 7, 8
2025
-
[74]
Lgm: Large multi- view gaussian model for high-resolution 3d content cre- ation
Jiaxiang Tang, Zhaoxi Chen, Xiaokang Chen, Tengfei Wang, Gang Zeng, and Ziwei Liu. Lgm: Large multi- view gaussian model for high-resolution 3d content cre- ation. InEuropean Conference on Computer Vision, pages 1–18. Springer, 2025. 3
2025
-
[75]
Efficient part-level 3d object generation via dual volume packing, 2025
Jiaxiang Tang, Ruijie Lu, Zhaoshuo Li, Zekun Hao, Xuan Li, Fangyin Wei, Shuran Song, Gang Zeng, Ming-Yu Liu, and Tsung-Yi Lin. Efficient part-level 3d object generation via dual volume packing, 2025. 3
2025
-
[76]
Xiang Tang, Ruotong Li, and Xiaopeng Fan. Towards ge- ometric and textural consistency 3d scene generation via single image-guided model generation and layout optimiza- tion.arXiv preprint arXiv:2507.14841, 2025. 1
-
[77]
Gpt-4o system card
OpenAI teams. Gpt-4o system card. InarXiv, 2024. 2, 6
2024
-
[78]
Sv3d: Novel multi-view synthesis and 3d generation from a single image using la- tent video diffusion
Vikram V oleti, Chun-Han Yao, Mark Boss, Adam Letts, David Pankratz, Dmitry Tochilkin, Christian Laforte, Robin Rombach, and Varun Jampani. Sv3d: Novel multi-view synthesis and 3d generation from a single image using la- tent video diffusion. InEuropean Conference on Computer Vision, pages 439–457. Springer, 2025. 3
2025
-
[79]
Llama-mesh: Unifying 3d mesh generation with language models, 2024
Zhengyi Wang, Jonathan Lorraine, Yikai Wang, Hang Su, Jun Zhu, Sanja Fidler, and Xiaohui Zeng. Llama-mesh: Unifying 3d mesh generation with language models, 2024
2024
-
[80]
Crm: Single image to 3d textured mesh with convo- lutional reconstruction model
Zhengyi Wang, Yikai Wang, Yifei Chen, Chendong Xiang, Shuo Chen, Dajiang Yu, Chongxuan Li, Hang Su, and Jun Zhu. Crm: Single image to 3d textured mesh with convo- lutional reconstruction model. InEuropean conference on computer vision, pages 57–74. Springer, 2024. 3
2024
-
[81]
Octgpt: Octree-based mul- tiscale autoregressive models for 3d shape generation
Si-Tong Wei, Rui-Huan Wang, Chuan-Zhi Zhou, Baoquan Chen, and Peng-Shuai Wang. Octgpt: Octree-based mul- tiscale autoregressive models for 3d shape generation. In Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Confer- ence Papers, pages 1–11, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.