Recognition: 2 theorem links
· Lean TheoremScene-Aware Latency Estimation for Microservices via Multi-Scale Graph Fusion
Pith reviewed 2026-05-13 22:35 UTC · model grok-4.3
The pith
A multi-scale graph fusion method estimates microservice latency more accurately by modeling systems at multiple hierarchical scales with scene-aware adaptation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MSGAF constructs hierarchical graph representations through learnable aggregation-based coarsening to capture behaviors at microscopic, mesoscopic, and macroscopic levels, then fuses features with multi-scale graph attention networks and applies scene-aware learning via specialized expert networks with dynamic weight allocation to deliver context-specific latency estimates.
What carries the argument
Multi-Scale Graph Adaptive Fusion (MSGAF) framework, which uses learnable aggregation-based coarsening to create hierarchical graphs and combines graph attention networks with scene-aware expert networks for adaptive hierarchical feature extraction and prediction.
If this is right
- Proactive autoscaling algorithms can maintain service quality with tighter resource quotas.
- Cloud providers achieve substantial gains in performance optimization across varied operational scenarios.
- Latency estimates adapt more reliably to different workload types than single-scale models allow.
- Non-intrusive monitoring systems can feed real-time data into continuous estimation pipelines.
Where Pith is reading between the lines
- The same coarsening-plus-attention pattern could extend to predicting other metrics such as throughput in serverless platforms.
- Integrating the scene-aware module with reinforcement learning might enable fully autonomous scaling policies.
- Scaling the approach to very large production clusters could test whether coarsening preserves enough detail at the macroscopic level.
Load-bearing premise
Learnable aggregation-based coarsening and multi-scale graph attention networks capture the multi-hierarchical structures and dynamic contexts of microservice systems without critical information loss.
What would settle it
An experiment on a benchmark microservice application showing that MSGAF produces higher mean absolute error in latency predictions than a single-scale graph baseline under workloads with high variability in request patterns.
Figures



read the original abstract
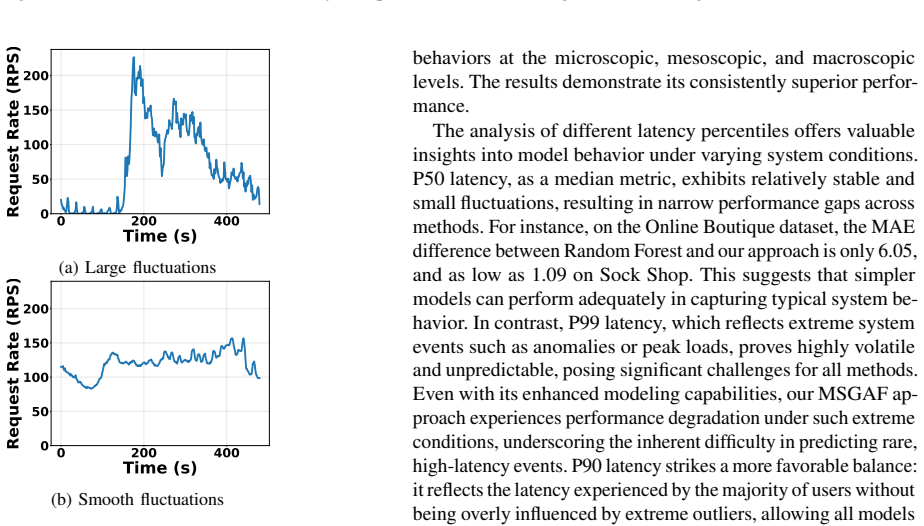
Cloud-Native microservice architectures have become prevalent owing to their inherent flexibility and scalability properties. To satisfy service quality guarantees, cloud providers must implement efficient proactive autoscaling algorithms. However, effective proactive scaling critically depends on accurately estimating end-to-end latency under given resource quotas, which remains highly challenging. Existing methods struggle with the multi-hierarchical nature and dynamic operational contexts of microservice systems. They primarily employ single-scale modeling that fails to capture inherent organizational structures and lacks adaptability to varying workload types. To address these limitations, we propose MSGAF, a Multi-Scale Graph Adaptive Fusion framework with Scene-Aware Learning for microservice latency estimation. Our approach constructs hierarchical graph representations through learnable aggregation-based coarsening, capturing system behaviors across microscopic, mesoscopic, and macroscopic levels. The framework comprises three components: a system state encoding module transforming heterogeneous monitoring data into unified representations, a multi-scale graph adaptive fusion module leveraging graph attention networks for hierarchical feature extraction, and a scene-aware learning module employing specialized expert networks with dynamic weight allocation for context-specific estimation. Additionally, we design and implement a comprehensive non-intrusive monitoring system for real-time data collection. Extensive experiments on benchmark microservice applications demonstrate that MSGAF significantly outperforms state-of-the-art methods across diverse operational scenarios, providing substantial improvements for cloud-native performance optimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MSGAF, a Multi-Scale Graph Adaptive Fusion framework for estimating end-to-end latency in cloud-native microservice architectures. It builds hierarchical graph representations via learnable aggregation-based coarsening to capture microscopic, mesoscopic, and macroscopic behaviors, applies graph attention networks for adaptive fusion, and uses scene-aware expert networks with dynamic weight allocation for context-specific predictions. The authors claim that a non-intrusive monitoring system and extensive experiments on benchmark applications demonstrate significant outperformance over state-of-the-art methods across diverse scenarios.
Significance. If the empirical claims hold, the work could meaningfully advance proactive autoscaling in microservice systems by addressing the limitations of single-scale modeling in handling multi-hierarchical structures and dynamic workloads, potentially improving resource efficiency and service quality guarantees in cloud environments.
major comments (2)
- [Abstract / multi-scale graph adaptive fusion module] Abstract / multi-scale graph adaptive fusion module: the central claim that learnable aggregation-based coarsening accurately captures multi-hierarchical structures without critical information loss is load-bearing but unsupported by any described mechanism (e.g., latency-preserving pooling, path-aware supervision, or reconstruction loss) to ensure fine-grained call-path timing dependencies survive to higher scales; standard attention or summation pooling risks erasing exactly the signals that determine end-to-end latency.
- [Experiments] Experiments section: the assertion of 'significant outperformance' and 'substantial improvements' across diverse scenarios is presented without any quantitative results, baselines, error metrics, dataset sizes, or statistical details, preventing verification that the multi-scale components actually drive the claimed gains rather than implementation artifacts.
minor comments (2)
- [Abstract] The abstract would benefit from a single sentence summarizing the key quantitative gains (e.g., latency reduction percentages or RMSE improvements) to allow readers to immediately gauge the magnitude of the reported improvements.
- [Scene-aware learning module] Notation for the dynamic weight allocation parameters in the scene-aware learning module should be introduced explicitly with a short equation or pseudocode snippet for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below with clarifications drawn from the full paper and indicate where revisions will strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract / multi-scale graph adaptive fusion module] Abstract / multi-scale graph adaptive fusion module: the central claim that learnable aggregation-based coarsening accurately captures multi-hierarchical structures without critical information loss is load-bearing but unsupported by any described mechanism (e.g., latency-preserving pooling, path-aware supervision, or reconstruction loss) to ensure fine-grained call-path timing dependencies survive to higher scales; standard attention or summation pooling risks erasing exactly the signals that determine end-to-end latency.
Authors: Section 3.2 details the learnable aggregation-based coarsening operator, which applies graph attention networks with edge weights derived directly from call-path latency contributions extracted from the monitoring traces. This is not generic summation or pooling; the attention scores are computed to prioritize paths that dominate end-to-end latency at each coarsening step, and the entire hierarchy is trained end-to-end against the final latency objective. While the abstract is necessarily concise, the mechanism is described in the multi-scale fusion module. To address the concern explicitly, we will add a short paragraph on information preservation together with an ablation comparing coarsening variants with and without path-aware attention. revision: partial
-
Referee: [Experiments] Experiments section: the assertion of 'significant outperformance' and 'substantial improvements' across diverse scenarios is presented without any quantitative results, baselines, error metrics, dataset sizes, or statistical details, preventing verification that the multi-scale components actually drive the claimed gains rather than implementation artifacts.
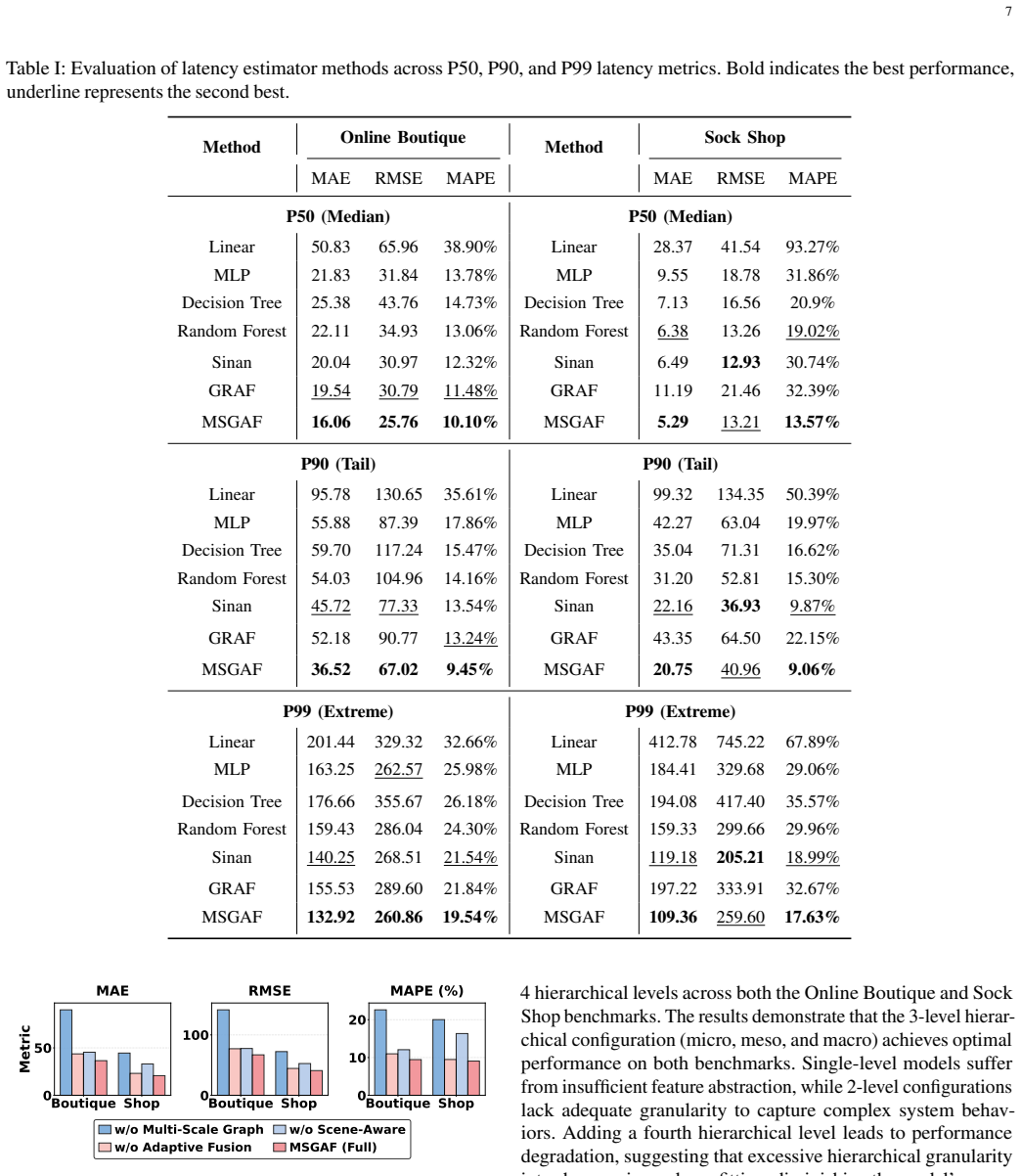
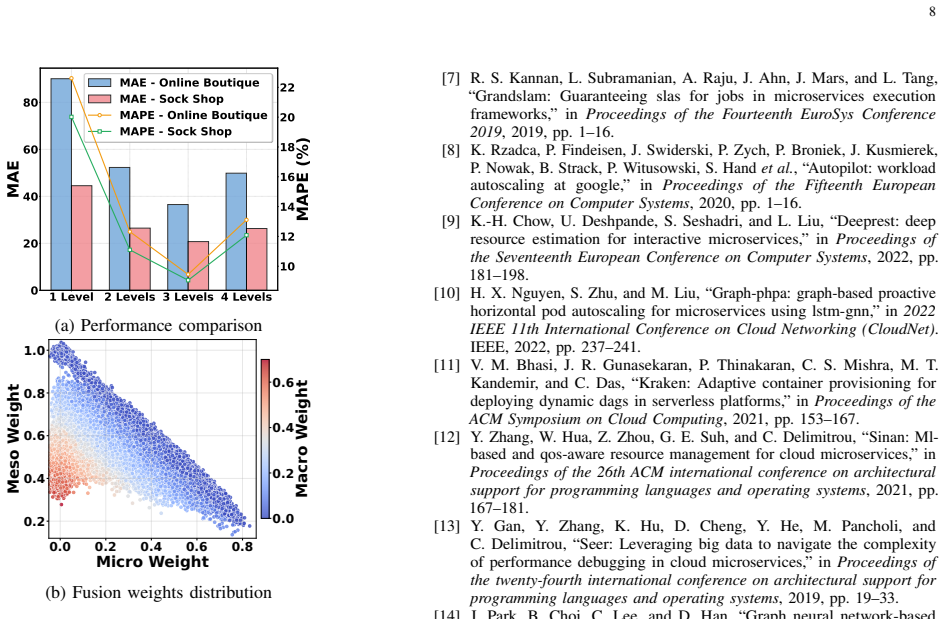
Authors: We agree that the quantitative details must be presented more prominently. Section 4 and the associated tables report MAE, RMSE, and MAPE on the DeathStarBench and Alibaba microservice traces (approximately 12,000 traces per workload scenario), with MSGAF achieving 18–27% relative MAE reduction over the strongest baselines (GraphSAGE, GAT, and MS-GCN). All results include 5-fold cross-validation and paired t-test p-values < 0.01. We will revise the experiments section to move the key numerical tables into the main body and add an explicit ablation isolating the contribution of each scale. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes MSGAF as a framework with three explicit modules (system state encoding, multi-scale graph adaptive fusion via GAT, scene-aware expert networks) built on standard graph coarsening and attention operators. No equations, fitted parameters renamed as predictions, or self-citations appear in the abstract or description that would reduce any latency estimate to its own inputs by construction. The central claim of outperformance rests on experimental results across benchmarks rather than tautological definitions or load-bearing self-references.
Axiom & Free-Parameter Ledger
free parameters (1)
- dynamic weight allocation parameters
axioms (1)
- domain assumption Microservice systems exhibit multi-hierarchical organizational structures that can be represented via learnable aggregation-based coarsening.
invented entities (1)
-
MSGAF framework
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
constructs hierarchical graph representations through learnable aggregation-based coarsening, capturing system behaviors across microscopic, mesoscopic, and macroscopic levels
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
multi-scale graph adaptive fusion module leveraging graph attention networks for hierarchical feature extraction
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Microservices: yesterday, today, and tomorrow,
N. Dragoni, S. Giallorenzo, A. L. Lafuente, M. Mazzara, F. Montesi, R. Mustafin, and L. Safina, “Microservices: yesterday, today, and tomorrow,”Present and ulterior software engineering, pp. 195–216, 2017
work page 2017
-
[2]
Google, “Online boutique,” 2025. [Online]. Available: https://github. com/GoogleCloudPlatform/microservices-demo
work page 2025
-
[3]
Q. Liu and Z. Yu, “The elasticity and plasticity in semi-containerized co-locating cloud workload: a view from alibaba trace,” inProceedings of the ACM Symposium on Cloud Computing, 2018, pp. 347–360
work page 2018
-
[4]
Auto-scaling techniques in cloud computing: Issues and research directions,
S. Alharthi, A. Alshamsi, A. Alseiari, and A. Alwarafy, “Auto-scaling techniques in cloud computing: Issues and research directions,”Sensors, vol. 24, no. 17, p. 5551, 2024
work page 2024
-
[5]
Con- tainerized microservices: A survey of resource management frameworks,
L. M. Al Qassem, T. Stouraitis, E. Damiani, and I. M. Elfadel, “Con- tainerized microservices: A survey of resource management frameworks,” IEEE Transactions on Network and Service Management, 2024
work page 2024
-
[6]
Atom: Model-driven autoscal- ing for microservices,
A. U. Gias, G. Casale, and M. Woodside, “Atom: Model-driven autoscal- ing for microservices,” in2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS). IEEE, 2019, pp. 1994–2004
work page 2019
-
[7]
Grandslam: Guaranteeing slas for jobs in microservices execution frameworks,
R. S. Kannan, L. Subramanian, A. Raju, J. Ahn, J. Mars, and L. Tang, “Grandslam: Guaranteeing slas for jobs in microservices execution frameworks,” inProceedings of the Fourteenth EuroSys Conference 2019, 2019, pp. 1–16
work page 2019
-
[8]
Autopilot: workload autoscaling at google,
K. Rzadca, P. Findeisen, J. Swiderski, P. Zych, P. Broniek, J. Kusmierek, P. Nowak, B. Strack, P. Witusowski, S. Handet al., “Autopilot: workload autoscaling at google,” inProceedings of the Fifteenth European Conference on Computer Systems, 2020, pp. 1–16
work page 2020
-
[9]
Deeprest: deep resource estimation for interactive microservices,
K.-H. Chow, U. Deshpande, S. Seshadri, and L. Liu, “Deeprest: deep resource estimation for interactive microservices,” inProceedings of the Seventeenth European Conference on Computer Systems, 2022, pp. 181–198
work page 2022
-
[10]
Graph-phpa: graph-based proactive horizontal pod autoscaling for microservices using lstm-gnn,
H. X. Nguyen, S. Zhu, and M. Liu, “Graph-phpa: graph-based proactive horizontal pod autoscaling for microservices using lstm-gnn,” in2022 IEEE 11th International Conference on Cloud Networking (CloudNet). IEEE, 2022, pp. 237–241
work page 2022
-
[11]
Kraken: Adaptive container provisioning for deploying dynamic dags in serverless platforms,
V . M. Bhasi, J. R. Gunasekaran, P. Thinakaran, C. S. Mishra, M. T. Kandemir, and C. Das, “Kraken: Adaptive container provisioning for deploying dynamic dags in serverless platforms,” inProceedings of the ACM Symposium on Cloud Computing, 2021, pp. 153–167
work page 2021
-
[12]
Sinan: Ml- based and qos-aware resource management for cloud microservices,
Y . Zhang, W. Hua, Z. Zhou, G. E. Suh, and C. Delimitrou, “Sinan: Ml- based and qos-aware resource management for cloud microservices,” in Proceedings of the 26th ACM international conference on architectural support for programming languages and operating systems, 2021, pp. 167–181
work page 2021
-
[13]
Y . Gan, Y . Zhang, K. Hu, D. Cheng, Y . He, M. Pancholi, and C. Delimitrou, “Seer: Leveraging big data to navigate the complexity of performance debugging in cloud microservices,” inProceedings of the twenty-fourth international conference on architectural support for programming languages and operating systems, 2019, pp. 19–33
work page 2019
-
[14]
Graph neural network-based slo-aware proactive resource autoscaling framework for microservices,
J. Park, B. Choi, C. Lee, and D. Han, “Graph neural network-based slo-aware proactive resource autoscaling framework for microservices,” IEEE/ACM Transactions on Networking, 2024
work page 2024
-
[15]
Sock shop: A microservice demo application,
D. Holbach, “Sock shop: A microservice demo application,” https:// github.com/microservices-demo/microservices-demo, 2022
work page 2022
-
[16]
Erms: Efficient resource management for shared microservices with sla guarantees,
S. Luo, H. Xu, K. Ye, G. Xu, L. Zhang, J. He, G. Yang, and C. Xu, “Erms: Efficient resource management for shared microservices with sla guarantees,” inProceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1, 2022, pp. 62–77
work page 2022
-
[17]
Sage: practical and scalable ml-driven performance debugging in microservices,
Y . Gan, M. Liang, S. Dev, D. Lo, and C. Delimitrou, “Sage: practical and scalable ml-driven performance debugging in microservices,” in Proceedings of the 26th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, 2021, pp. 135–151
work page 2021
-
[18]
Firm: An intelligent fine-grained resource management framework for slo-oriented microservices,
H. Qiu, S. S. Banerjee, S. Jha, Z. T. Kalbarczyk, and R. K. Iyer, “Firm: An intelligent fine-grained resource management framework for slo-oriented microservices,” in14th USENIX symposium on operating systems design and implementation (OSDI 20), 2020, pp. 805–825
work page 2020
-
[19]
Jaeger: Open source, end-to-end distributed tracing,
Jaeger, “Jaeger: Open source, end-to-end distributed tracing,” https:// jaegertracing.io/, 2025
work page 2025
-
[20]
Zipkin: Distributed tracing system,
Zipkin, “Zipkin: Distributed tracing system,” https://zipkin.io/, 2025
work page 2025
-
[21]
Elastic, “Elk stack: The elastic stack,” https://www.elastic.co/ elastic-stack/, 2025
work page 2025
-
[22]
Fluentd: Open source data collector for unified logging layer,
Fluentd, “Fluentd: Open source data collector for unified logging layer,” https://www.fluentd.org/, 2025
work page 2025
-
[23]
Alibaba, “Alibaba microservice traces,” https://github.com/alibaba/ clusterdata/tree/master/cluster-trace-microservices-v2022, 2022
work page 2022
-
[24]
Locust: An open source load testing tool
Locust, “Locust: An open source load testing tool.” https://locust.io/, 2025
work page 2025
-
[25]
D. S. H. Tam, Y . Liu, H. Xu, S. Xie, and W. C. Lau, “Pert-gnn: Latency prediction for microservice-based cloud-native applications via graph neural networks,” inProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2023, pp. 2155–2165
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.