Recognition: 2 theorem links
· Lean TheoremFuzzy Encoding-Decoding to Improve Spiking Q-Learning Performance in Autonomous Driving
Pith reviewed 2026-05-10 18:49 UTC · model grok-4.3
The pith
Fuzzy encoder-decoder improves spiking Q-network performance in autonomous driving by generating better spike representations from visual inputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
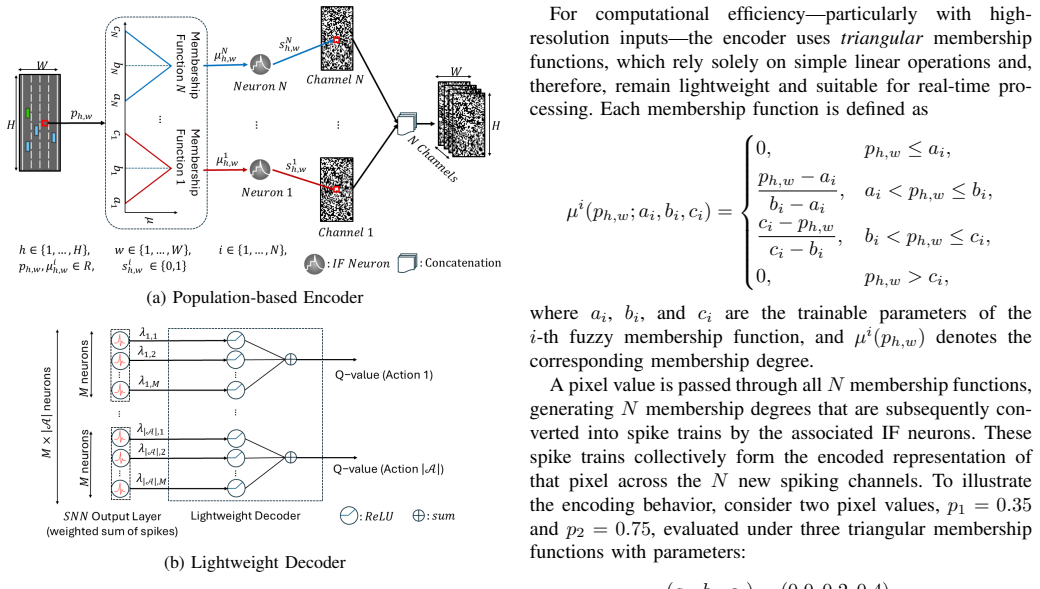
The fuzzy encoding-decoding architecture uses trainable fuzzy membership functions to create expressive population-based spike representations from dense visual inputs and employs a lightweight neural decoder to reconstruct continuous Q-values from the spiking outputs of the network, resulting in improved decision-making accuracy for multi-modal Q-learning in autonomous driving tasks on the HighwayEnv benchmark.
What carries the argument
Trainable fuzzy membership functions that map inputs to population spike codes, paired with a neural decoder that converts spiking activity back to continuous Q-value estimates.
If this is right
- Decision-making accuracy in highway autonomous driving scenarios increases substantially.
- The performance difference between spiking and non-spiking multi-modal Q-networks narrows significantly.
- Spiking neural networks become more suitable for efficient real-time autonomous driving applications.
Where Pith is reading between the lines
- This fuzzy approach might allow shorter spike train durations while maintaining performance in visual RL tasks.
- Extending the architecture to other high-dimensional sensory RL domains could be tested next.
Load-bearing premise
Trainable fuzzy membership functions will generate sufficiently expressive population spike codes on visual inputs without introducing overfitting or training instability not captured by the HighwayEnv benchmark.
What would settle it
If experiments on the HighwayEnv benchmark fail to show substantial improvement in decision-making accuracy or fail to close the performance gap between the spiking and non-spiking multi-modal Q-networks, the claim would be falsified.
Figures


read the original abstract
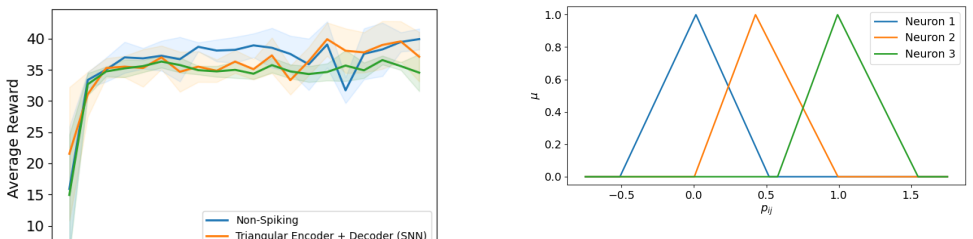
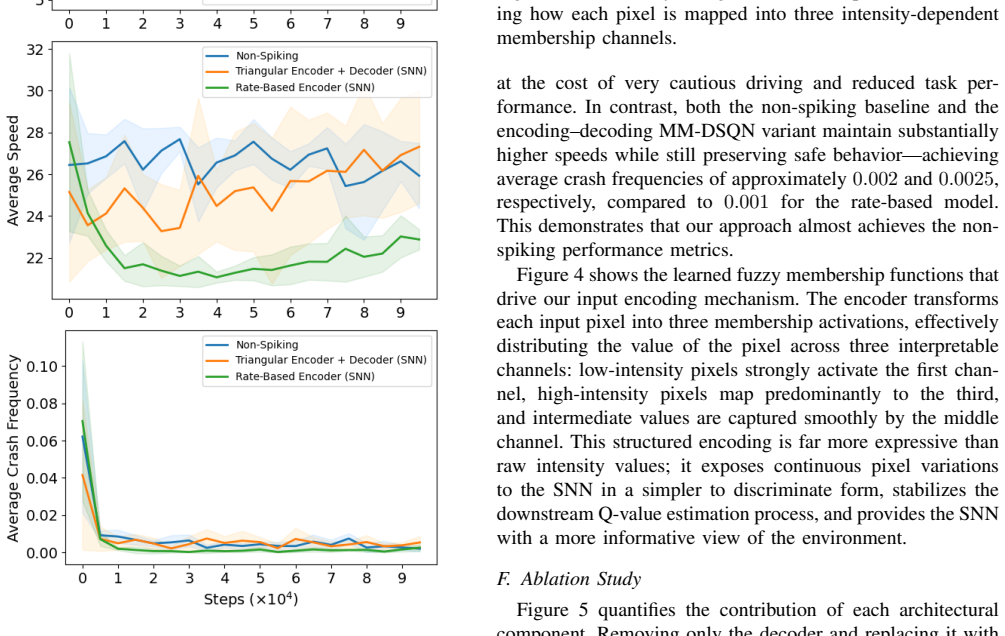
This paper develops an end-to-end fuzzy encoder-decoder architecture for enhancing vision-based multi-modal deep spiking Q-networks in autonomous driving. The method addresses two core limitations of spiking reinforcement learning: information loss stemming from the conversion of dense visual inputs into sparse spike trains, and the limited representational capacity of spike-based value functions, which often yields weakly discriminative Q-value estimates. The encoder introduces trainable fuzzy membership functions to generate expressive, population-based spike representations, and the decoder uses a lightweight neural decoder to reconstruct continuous Q-values from spiking outputs. Experiments on the HighwayEnv benchmark show that the proposed architecture substantially improves decision-making accuracy and closes the performance gap between spiking and non-spiking multi-modal Q-networks. The results highlight the potential of this framework for efficient and real-time autonomous driving with spiking neural networks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an end-to-end fuzzy encoder-decoder architecture for vision-based multi-modal deep spiking Q-networks in autonomous driving. Trainable fuzzy membership functions are used in the encoder to generate expressive population spike codes from dense visual inputs, mitigating information loss during spike conversion, while a lightweight neural decoder reconstructs continuous Q-values from the spiking outputs. Experiments on the HighwayEnv benchmark are claimed to demonstrate substantial gains in decision-making accuracy and to close the performance gap relative to non-spiking multi-modal Q-networks.
Significance. If the reported gains are reproducible and generalize beyond the chosen benchmark, the approach could meaningfully advance energy-efficient spiking reinforcement learning for real-time control by improving the representational power of spike-based value functions without sacrificing the efficiency advantages of SNNs.
major comments (1)
- [Experiments (HighwayEnv evaluation)] The central empirical claim rests on HighwayEnv experiments showing that trainable fuzzy membership functions produce sufficiently expressive spike codes to close the spiking/non-spiking gap. However, HighwayEnv typically supplies low-dimensional kinematic states or rudimentary image patches rather than high-dimensional camera imagery; this mismatch directly undermines the abstract's emphasis on 'dense visual inputs' and leaves open whether the fuzzy encoder avoids information loss or training instability on richer visual data.
minor comments (1)
- [Abstract] The abstract states performance improvements but supplies no numerical deltas, baseline values, statistical tests, or ablation results; these quantitative details should be added to allow immediate assessment of the magnitude of the claimed gains.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address the concern regarding the HighwayEnv experiments and the description of visual inputs below.
read point-by-point responses
-
Referee: The central empirical claim rests on HighwayEnv experiments showing that trainable fuzzy membership functions produce sufficiently expressive spike codes to close the spiking/non-spiking gap. However, HighwayEnv typically supplies low-dimensional kinematic states or rudimentary image patches rather than high-dimensional camera imagery; this mismatch directly undermines the abstract's emphasis on 'dense visual inputs' and leaves open whether the fuzzy encoder avoids information loss or training instability on richer visual data.
Authors: We appreciate this observation and acknowledge that the standard HighwayEnv benchmark primarily uses either low-dimensional state vectors or simplified image observations (e.g., top-down views or low-resolution patches) rather than photorealistic high-dimensional camera imagery. In our experiments, we employed the image observation mode provided by HighwayEnv, which delivers dense pixel-level visual inputs to the network, allowing us to evaluate the fuzzy encoder-decoder on vision-based inputs within this controlled simulation environment. This setup demonstrates the benefits for spike-based processing of visual data. However, we agree that the terminology 'dense visual inputs' in the abstract could be misleading without qualification. We will revise the abstract, introduction, and experimental section to explicitly state that we use 'pixel-based image observations from the HighwayEnv simulator' and add a limitations paragraph discussing the scope of the visual complexity tested. This will clarify the claims without requiring additional experiments at this stage. revision: partial
Circularity Check
No circularity: empirical architecture with external benchmark validation
full rationale
The paper presents a trainable fuzzy encoder-decoder for spiking Q-networks, evaluated empirically on the HighwayEnv benchmark. No derivation chain, equations, or predictions reduce to fitted parameters or self-citations by construction. The central claims rest on experimental results comparing spiking vs. non-spiking performance, which are externally falsifiable and independent of the method's internal definitions. This is the standard case of a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Population coding via fuzzy membership functions can recover sufficient information from dense visual inputs for Q-value estimation
- standard math Q-learning converges to useful policies when value estimates are sufficiently discriminative
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The encoder introduces trainable fuzzy membership functions to generate expressive, population-based spike representations, and the decoder uses a lightweight neural decoder to reconstruct continuous Q-values from spiking outputs.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Experiments on the HighwayEnv benchmark show that the proposed architecture substantially improves decision-making accuracy and closes the performance gap between spiking and non-spiking multi-modal Q-networks.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Human-level control through deep reinforcement learning,
V . Mnih et al., “Human-level control through deep reinforcement learning,”Nature, vol. 518, no. 7540, pp. 529–533, 2015
2015
-
[2]
Target-driven visual navigation in indoor scenes using deep reinforcement learning,
Y . Zhu et al., “Target-driven visual navigation in indoor scenes using deep reinforcement learning,” inIEEE Conf. Robotics & Automation, 2017, pp. 3357–3364
2017
-
[3]
Automated deep reinforcement learning environment for hardware of a modular legged robot,
S. Ha et al., “Automated deep reinforcement learning environment for hardware of a modular legged robot,” inInt’l Conf. Ubiquitous Robots, 2018, pp. 348–354
2018
-
[4]
A sim-to-real pipeline for deep rein- forcement learning for autonomous robot navigation in cluttered rough terrain,
H. Hu et al., “A sim-to-real pipeline for deep rein- forcement learning for autonomous robot navigation in cluttered rough terrain,”IEEE Robotics & Automation Letters, vol. 6, no. 4, pp. 6569–6576, 2021
2021
-
[5]
Tactical decision-making for au- tonomous driving using dueling double deep q net- work with double attention,
S. Zhang et al., “Tactical decision-making for au- tonomous driving using dueling double deep q net- work with double attention,”IEEE Access, vol. 9, pp. 151 983–151 992, 2021
2021
-
[6]
Bevformer: Learning bird’s-eye-view rep- resentation from lidar-camera via spatiotemporal trans- formers,
Z. Li et al., “Bevformer: Learning bird’s-eye-view rep- resentation from lidar-camera via spatiotemporal trans- formers,”IEEE Trans. Pattern Analysis & Machine Intelligence, vol. 47, no. 3, pp. 2020–2036, 2024
2020
-
[7]
Pointpillars: Fast encoders for object detection from point clouds,
A. H. Lang et al., “Pointpillars: Fast encoders for object detection from point clouds,” inProc. IEEE/CVF Conf. Computer Vision & Pattern Recognition, 2019, pp. 12 697–12 705
2019
-
[8]
Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d,
J. Philion et al., “Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d,” inEuropean Conf. Computer Vision, Springer, 2020, pp. 194–210
2020
-
[9]
J. Hu et al., “High-performance temporal reversible spiking neural networks withO(L)training memory andO(1)inference cost,”arXiv preprint arXiv:2405.16466, 2024
-
[10]
Deep reinforcement learning with population-coded spiking neural network for continuous control,
G. Tang et al., “Deep reinforcement learning with population-coded spiking neural network for continuous control,” inConf. Robot Learning, 2021, pp. 2016– 2029
2021
-
[11]
Improving performance of spike- based deep q-learning using ternary neurons,
A. Ghoreishee et al., “Improving performance of spike- based deep q-learning using ternary neurons,”arXiv preprint arXiv:2506.03392, 2025
-
[12]
New spiking architecture for multi-modal decision-making in autonomous vehicles,
A. Ghoreishee et al., “New spiking architecture for multi-modal decision-making in autonomous vehicles,” arXiv preprint arXiv:2512.01882, 2025
-
[13]
Human-level control through directly trained deep spiking q-networks,
G. Liu et al., “Human-level control through directly trained deep spiking q-networks,”IEEE Trans. Cyber- netics, vol. 53, no. 11, pp. 7187–7198, 2022
2022
-
[14]
Leurent,An environment for autonomous driving decision-making, https://github.com/eleurent/highway- env, 2018
E. Leurent,An environment for autonomous driving decision-making, https://github.com/eleurent/highway- env, 2018
2018
-
[15]
Playing Atari with Deep Reinforcement Learning
V . Mnih, “Playing atari with deep reinforcement learn- ing,”arXiv preprint arXiv:1312.5602, 2013
work page internal anchor Pith review arXiv 2013
-
[16]
Deep reinforcement learning with double q-learning,
H. Van Hasselt et al., “Deep reinforcement learning with double q-learning,” inProc. AAAI conf. Artificial Intelligence, vol. 30, 2016
2016
-
[17]
Dueling network architectures for deep reinforcement learning,
Z. Wang et al., “Dueling network architectures for deep reinforcement learning,” inInt’l Conf. Machine Learning, 2016, pp. 1995–2003
2016
-
[18]
Deep q network (dqn), double dqn, and dueling dqn: A step towards general artificial intelligence,
M. Sewak et al., “Deep q network (dqn), double dqn, and dueling dqn: A step towards general artificial intelligence,”Deep Reinforcement Learning: Frontiers Artificial Intelligence, pp. 95–108, 2019
2019
-
[19]
Improved robustness of reinforcement learning policies upon conversion to spiking neuronal network platforms applied to atari breakout game,
D. Patel et al., “Improved robustness of reinforcement learning policies upon conversion to spiking neuronal network platforms applied to atari breakout game,” Neural Networks, vol. 120, pp. 108–115, 2019
2019
-
[20]
Strategy and benchmark for convert- ing deep q-networks to event-driven spiking neural networks,
W. Tan et al., “Strategy and benchmark for convert- ing deep q-networks to event-driven spiking neural networks,” inProc. AAAI conf. Artificial Intelligence, vol. 35, 2021, pp. 9816–9824
2021
-
[21]
Solving the spike feature information vanishing problem in spiking deep q network with potential based normalization,
Y . Sun et al., “Solving the spike feature information vanishing problem in spiking deep q network with potential based normalization,”Frontiers Neuroscience, vol. 16, p. 953 368, 2022
2022
-
[22]
Population-coded spiking neural networks for high-dimensional robotic control,
K. Jaisankar et al., “Population-coded spiking neural networks for high-dimensional robotic control,”arXiv preprint arXiv:2510.10516, 2025
-
[23]
Multi-modal mutual information (mummi) training for robust self-supervised deep re- inforcement learning,
K. Chen et al., “Multi-modal mutual information (mummi) training for robust self-supervised deep re- inforcement learning,” inIEEE conf. Robotics & Au- tomation, 2021, pp. 4274–4280
2021
-
[24]
Combining reconstruction and con- trastive methods for multimodal representations in rl,
P. Becker et al., “Combining reconstruction and con- trastive methods for multimodal representations in rl,” arXiv preprint arXiv:2302.05342, 2023
-
[25]
Look closer: Bridging egocentric and third-person views with transformers for robotic manipulation,
R. Jangir et al., “Look closer: Bridging egocentric and third-person views with transformers for robotic manipulation,”IEEE Robotics & Automation Letters, vol. 7, no. 2, pp. 3046–3053, 2022
2022
-
[26]
Multimodal reinforcement learning with dynamic graph representations for autonomous driving decision-making,
T. Su et al., “Multimodal reinforcement learning with dynamic graph representations for autonomous driving decision-making,” inIEEE Conf. Info. Science & Tech. (ICIST), 2024, pp. 866–874
2024
-
[27]
A multimodal deep reinforcement learning approach for iot-driven adaptive scheduling and robust- ness optimization in global logistics networks,
Y . Lu, “A multimodal deep reinforcement learning approach for iot-driven adaptive scheduling and robust- ness optimization in global logistics networks,”Nature Scientific Reports, vol. 15, no. 1, p. 25 195, 2025
2025
-
[28]
Spikformer: When spiking neural network meets transformer.arXiv preprint arXiv:2209.15425,
Z. Zhou et al., “Spikformer: When spiking neural network meets transformer,”arXiv preprint arXiv:2209.15425, 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.