Recognition: 2 theorem links
· Lean TheoremSpot-and-Scoot: Peeking Into Spot Instance Availability
Pith reviewed 2026-05-10 18:36 UTC · model grok-4.3
The pith
Spot-and-Scoot collects spot instance availability signals at near-zero cost by submitting requests and canceling them before instances start running.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Spot-and-Scoot gathers binary availability signals through canceled spot requests across many instance types and regions. Analysis of real interruption events shows that instances of the same type in the same zone tend to fail together within three minutes, which supports treating availability as a binary state. Three features extracted from the signals are combined into models that describe current availability and predict it at future times. A separate simulation using standard workloads indicates that acting on these predictions reduces lost computation relative to running without guidance.
What carries the argument
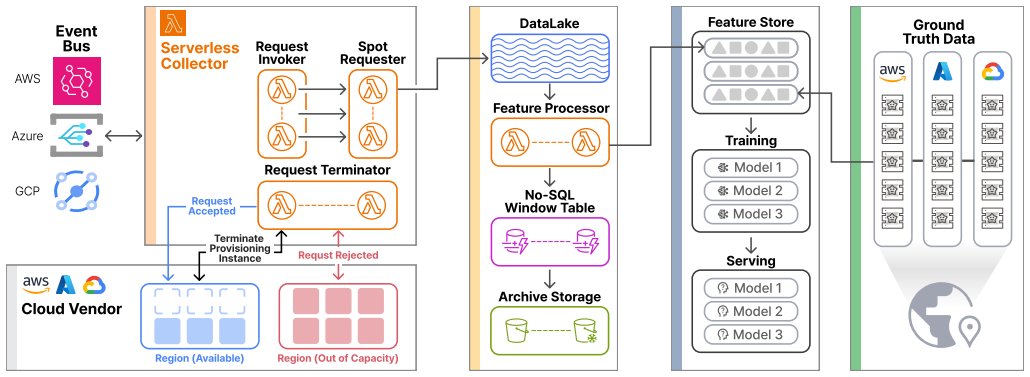
The Spot-and-Scoot (SnS) probing technique that submits spot requests and cancels them upon acceptance to obtain binary availability signals without incurring instance runtime costs.
Load-bearing premise
The assumption that the outcome of a canceled spot request accurately reflects the capacity that a running instance would experience on the same type and zone.
What would settle it
A direct comparison in which SnS signals report availability but actual long-running instances on the matching types and zones are interrupted at high rates, or the reverse pattern.
Figures







read the original abstract
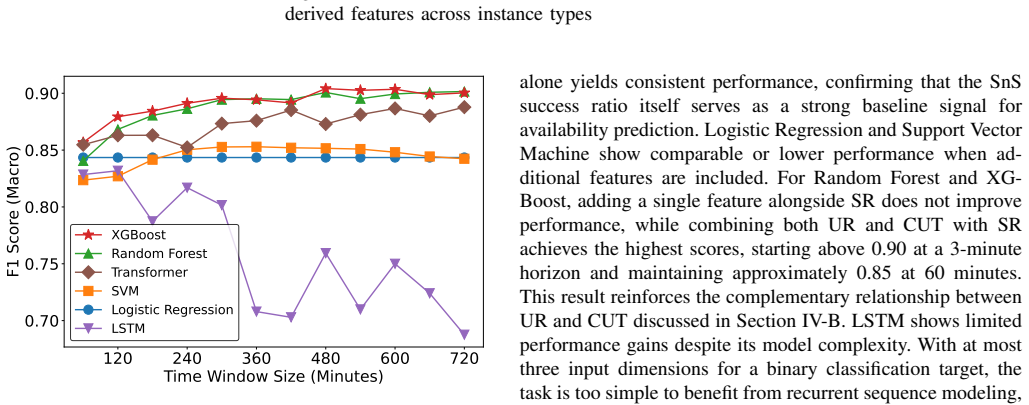
Spot instances offer significant cost savings of up to 90% over on-demand prices, making them an attractive resource for large-scale computing workloads. However, understanding their availability dynamics is essential for building systems that tolerate interruptions, and observing this availability directly requires keeping instances running, which incurs costs that scale with the number of monitored instance types and their per-instance price. We propose Spot-and-Scoot (SnS), a cost-efficient method that collects spot instance availability signals by leveraging the cloud provider's provisioning lifecycle. Since the outcome of a spot request is determined before the instance enters the running state, SnS submits requests and cancels them upon provisioning acceptance, collecting binary availability signals at near-zero instance cost. Submitting multiple concurrent requests per measurement point further yields a quantitative estimate of available capacity. We validate SnS through simultaneous collection of probing signals and actual running instance traces across 68 instance types and 15 regions on both AWS and Azure, totaling 336,033 spot requests. Analysis of 2,635 real-world interruption events reveals that co-interruptions within the same instance type and availability zone occur within three minutes in over 92% of cases, motivating a binary availability formulation. Based on this formulation, we derive three complementary features from SnS signals and demonstrate that their combination achieves an F1-macro score of up to 0.90 for current availability modeling and maintains 0.85 at a 60-minute prediction horizon. A trace-driven simulation using TPC-DS workloads further demonstrates the potential of SnS-based prediction to reduce lost computation compared to an unguided baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Spot-and-Scoot (SnS), a cost-efficient probing technique for spot instance availability that submits requests and cancels them upon provisioning acceptance to collect binary signals without incurring running costs. It validates this approach by simultaneous collection with running instance traces across 68 instance types, 15 regions, and 336,033 requests on AWS and Azure. Analysis of 2,635 interruption events shows that 92% of co-interruptions occur within 3 minutes, justifying a binary availability model per type and availability zone. Three features derived from SnS signals are used to model current availability with up to 0.90 F1-macro and predict at 60-minute horizon with 0.85 F1, and a TPC-DS trace-driven simulation shows reduced lost computation compared to baseline.
Significance. If the results hold, this provides a practical, scalable way to monitor and predict spot instance availability at low cost, which is significant for cloud users relying on spot instances for cost savings. The large-scale empirical validation across many types and regions, combined with real interruption data and workload simulation, offers concrete evidence of utility and could enable more robust interruption-tolerant systems.
major comments (3)
- [Validation / Experiments] The equivalence between SnS probe signals (submit-then-cancel) and actual running-instance capacity is load-bearing for all downstream claims; the simultaneous collection across 68 types is cited as validation, but quantitative agreement metrics (e.g., per-type precision/recall or discrepancy rates between probe outcomes and trace availability) must be reported explicitly to rule out systematic bias from the probing method.
- [Interruption Analysis] The binary availability formulation rests on the observation that 92% of 2,635 co-interruption events occur within 3 minutes; while this supports the model in the collected traces, the paper must address generalizability (e.g., sensitivity to request duration, account history, or provider allocation changes) with either additional analysis or a concrete test, as this premise directly enables the feature derivation and F1 results.
- [Availability Modeling / Prediction] The three complementary features derived from SnS signals achieve the reported F1-macro scores of 0.90 (current) and 0.85 (60 min); their exact definitions, computation from the quantitative capacity estimates obtained via concurrent requests, and the training procedure (algorithm, hyperparameters, cross-validation) need fuller specification in the modeling section for reproducibility and to confirm the scores are not sensitive to implementation details.
minor comments (2)
- [Abstract] The abstract states that multiple concurrent requests yield a quantitative capacity estimate, but the precise mapping from number of acceptances to the capacity value used in features should be clarified for readers.
- [Simulation] In the TPC-DS simulation, specify the exact unguided baseline policy and the definition of 'lost computation' (e.g., work completed before interruption) to allow direct comparison with other schedulers.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive suggestions. We address each of the major comments in detail below, providing clarifications and committing to specific revisions that will enhance the manuscript's rigor and reproducibility.
read point-by-point responses
-
Referee: The equivalence between SnS probe signals (submit-then-cancel) and actual running-instance capacity is load-bearing for all downstream claims; the simultaneous collection across 68 types is cited as validation, but quantitative agreement metrics (e.g., per-type precision/recall or discrepancy rates between probe outcomes and trace availability) must be reported explicitly to rule out systematic bias from the probing method.
Authors: We acknowledge that explicit quantitative metrics would strengthen the validation of the equivalence between SnS probes and running instances. Although the manuscript describes the simultaneous collection across 68 types and 336,033 requests, we did not include per-type agreement statistics. In the revision, we will add a new table and accompanying text in the validation section reporting quantitative metrics such as per-type and per-region precision, recall, F1 scores, and discrepancy rates between probe signals and trace availability. This will be computed directly from the existing dataset to rule out systematic bias. revision: yes
-
Referee: The binary availability formulation rests on the observation that 92% of 2,635 co-interruption events occur within 3 minutes; while this supports the model in the collected traces, the paper must address generalizability (e.g., sensitivity to request duration, account history, or provider allocation changes) with either additional analysis or a concrete test, as this premise directly enables the feature derivation and F1 results.
Authors: We agree that generalizability of the binary model is an important consideration. Our current analysis is based on 2,635 events from diverse instance types and regions, but we will revise the interruption analysis section to include additional discussion on potential sensitivities. Specifically, we will present a sensitivity analysis by recomputing the co-interruption statistics for different time windows (e.g., 1, 3, and 5 minutes) and discuss how factors like request duration might influence the 92% figure. We will also add a limitations paragraph noting that while our multi-provider, multi-region data provides broad coverage, account history and future allocation changes are beyond the scope of this study and represent opportunities for future work. revision: partial
-
Referee: The three complementary features derived from SnS signals achieve the reported F1-macro scores of 0.90 (current) and 0.85 (60 min); their exact definitions, computation from the quantitative capacity estimates obtained via concurrent requests, and the training procedure (algorithm, hyperparameters, cross-validation) need fuller specification in the modeling section for reproducibility and to confirm the scores are not sensitive to implementation details.
Authors: We concur that fuller specification of the modeling approach is required for reproducibility. We will substantially expand the modeling section to provide: exact definitions of the three features with formulas showing how they are derived from the quantitative capacity estimates (obtained via concurrent requests); the machine learning algorithm employed along with all hyperparameters and their selection process; and details of the training and evaluation procedure, including the cross-validation strategy (e.g., temporal splits to avoid data leakage). Additionally, we will include a sensitivity analysis demonstrating that the reported F1-macro scores are robust to reasonable variations in these parameters. revision: yes
Circularity Check
No significant circularity; claims rest on independent empirical validation and measured model performance
full rationale
The derivation collects SnS probe signals and simultaneous running-instance traces (336k requests across 68 types/15 regions) to empirically validate probe-to-running equivalence. Co-interruption statistics (92% within 3 min from 2635 events) motivate but do not define the binary formulation. Three features are extracted from the signals; an ML model is trained and evaluated to produce the reported F1-macro scores (0.90 current, 0.85 at 60 min) on the collected data. The TPC-DS trace-driven simulation applies the model to external workloads and measures lost computation against an unguided baseline. None of these steps reduce by construction to fitted parameters or self-referential definitions; the performance numbers are measured outcomes, not tautological outputs of the inputs.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SnS submits requests and cancels them upon provisioning acceptance, collecting binary availability signals at near-zero instance cost... three complementary features... F1-macro score of up to 0.90
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Analysis of 2,635 real-world interruption events reveals that co-interruptions... within three minutes in over 92% of cases, motivating a binary availability formulation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Usage patterns and the economics of the public cloud,
C. Kilcioglu, J. M. Rao, A. Kannan, and R. P. McAfee, “Usage patterns and the economics of the public cloud,” inProceedings of the 26th International Conference on World Wide Web, ser. WWW ’17. Republic and Canton of Geneva, CHE: International World Wide Web Conferences Steering Committee, 2017, p. 83–91. [Online]. Available: https://doi.org/10.1145/30389...
-
[2]
From cloud computing to sky computing,
I. Stoica and S. Shenker, “From cloud computing to sky computing,” inProceedings of the Workshop on Hot Topics in Operating Systems, ser. HotOS ’21. New York, NY , USA: Association for Computing Machinery, 2021, p. 26–32. [Online]. Available: https://doi.org/10.1145/3458336.3465301
-
[3]
SkyPilot: An intercloud broker for sky computing,
Z. Yang, Z. Wu, M. Luo, W.-L. Chiang, R. Bhardwaj, W. Kwon, S. Zhuang, F. S. Luan, G. Mittal, S. Shenker, and I. Stoica, “SkyPilot: An intercloud broker for sky computing,” in20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23). Boston, MA: USENIX Association, Apr. 2023, pp. 437–455. [Online]. Available: https://www.usenix.org/co...
2023
-
[4]
Can’t be late: Optimizing spot instance savings under deadlines,
Z. Wu, W.-L. Chiang, Z. Mao, Z. Yang, E. Friedman, S. Shenker, and I. Stoica, “Can’t be late: Optimizing spot instance savings under deadlines,” in21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24). Santa Clara, CA: USENIX Association, Apr. 2024, pp. 185–203. [Online]. Available: https://www.usenix.org/conference/nsdi24/present...
2024
-
[5]
Parcae: Proactive, Liveput-Optimized DNN training on preemptible instances,
J. Duan, Z. Song, X. Miao, X. Xi, D. Lin, H. Xu, M. Zhang, and Z. Jia, “Parcae: Proactive, Liveput-Optimized DNN training on preemptible instances,” in21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24). Santa Clara, CA: USENIX Association, Apr. 2024, pp. 1121–1139. [Online]. Available: https://www.usenix.org/conference/nsdi24/p...
2024
-
[6]
Making cloud spot instance interruption events visible,
K. Kim and K. Lee, “Making cloud spot instance interruption events visible,” inProceedings of the ACM on Web Conference 2024, ser. WWW ’24. New York, NY , USA: Association for Computing Machinery, 2024, p. 2998–3009. [Online]. Available: https://doi.org/10.1145/3589334.3645548
-
[7]
Autobot: Resilient and cost-effective scheduling of a bag of tasks on spot vms,
P. Varshney and Y . Simmhan, “Autobot: Resilient and cost-effective scheduling of a bag of tasks on spot vms,”IEEE Transactions on Parallel & Distributed Systems, vol. 30, no. 07, pp. 1512–1527, jul 2019
2019
-
[8]
Skyserve: Serving ai models across regions and clouds with spot instances,
Z. Mao, T. Xia, Z. Wu, W.-L. Chiang, T. Griggs, R. Bhardwaj, Z. Yang, S. Shenker, and I. Stoica, “Skyserve: Serving ai models across regions and clouds with spot instances,” inProceedings of the Twentieth European Conference on Computer Systems, ser. EuroSys ’25. New York, NY , USA: Association for Computing Machinery, 2025, p. 159–175. [Online]. Availabl...
-
[9]
Deconstructing amazon ec2 spot instance pricing,
O. Agmon Ben-Yehuda, M. Ben-Yehuda, A. Schuster, and D. Tsafrir, “Deconstructing amazon ec2 spot instance pricing,”ACM Trans. Econ. Comput., vol. 1, no. 3, sep 2013. [Online]. Available: https://doi.org/10.1145/2509413.2509416
-
[10]
The price is (not) right: Reflections on pricing for transient cloud servers,
D. Irwin, P. Shenoy, P. Ambati, P. Sharma, S. Shastri, and A. Ali- Eldin, “The price is (not) right: Reflections on pricing for transient cloud servers,” in2019 28th International Conference on Computer Communication and Networks (ICCCN), 2019, pp. 1–9
2019
-
[11]
Deepspotcloud: Leveraging cross-region gpu spot instances for deep learning,
K. Lee and M. Son, “Deepspotcloud: Leveraging cross-region gpu spot instances for deep learning,” in2017 IEEE 10th International Conference on Cloud Computing (CLOUD), 2017, pp. 98–105
2017
-
[12]
Bamboo: Making preemptible instances resilient for affordable training of large DNNs,
J. Thorpe, P. Zhao, J. Eyolfson, Y . Qiao, Z. Jia, M. Zhang, R. Netravali, and G. H. Xu, “Bamboo: Making preemptible instances resilient for affordable training of large DNNs,” in20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23). Boston, MA: USENIX Association, Apr. 2023, pp. 497–513. [Online]. Available: https://www.usenix.or...
2023
-
[13]
X. Miao, C. Shi, J. Duan, X. Xi, D. Lin, B. Cui, and Z. Jia, “Spotserve: Serving generative large language models on preemptible instances,” inProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, ser. ASPLOS ’24. New York, NY , USA: Association for Computing Machinery, 202...
-
[14]
Z. Li, T. Xia, Z. Mao, Z. Zhou, E. J. Jackson, J. Kerney, Z. Wu, P. Mishra, Y . Xu, Y . Qiao, S. Shenker, and I. Stoica, “Skynomad: On using multi-region spot instances to minimize ai batch job cost,” 2026. [Online]. Available: https://arxiv.org/abs/2601.06520
-
[15]
Spotlake: Diverse spot instance dataset archive service,
S. Lee, J. Hwang, and K. Lee, “Spotlake: Diverse spot instance dataset archive service,” in2022 IEEE International Symposium on Workload Characterization (IISWC). Los Alamitos, CA, USA: IEEE Computer Society, nov 2022, pp. 242–255. [Online]. Available: https://doi.ieeecomputersociety.org/10.1109/IISWC55918.2022.00029
-
[16]
Performance and behavior characterization of amazon ec2 spot instances,
T.-P. Pham, S. Ristov, and T. Fahringer, “Performance and behavior characterization of amazon ec2 spot instances,” in2018 IEEE 11th International Conference on Cloud Computing (CLOUD), 2018, pp. 73– 81
2018
-
[17]
Spot instance interruption notices,
Amazon Web Services, “Spot instance interruption notices,” https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/spot-instance- termination-notices.html, 2026, accessed: 2026-03-22
2026
-
[18]
Use azure spot virtual machines,
Microsoft, “Use azure spot virtual machines,” https://learn.microsoft.com/en-us/azure/virtual-machines/spot-vms, 2026, accessed: 2026-03-22
2026
-
[19]
Spot vms,
Google, “Spot vms,” https://docs.cloud.google.com/compute/docs/instances/spot, 2026, accessed: 2026-03-22
2026
-
[20]
Deepvm: Integrating spot and on-demand vms for cost-efficient deep learning clusters in the cloud,
Y . Kim, K. Kim, Y . Cho, J. Kim, A. Khan, K.-D. Kang, B.-S. An, M.-H. Cha, H.-Y . Kim, and Y . Kim, “Deepvm: Integrating spot and on-demand vms for cost-efficient deep learning clusters in the cloud,” in2024 IEEE 24th International Symposium on Cluster, Cloud and Internet Computing (CCGrid), 2024, pp. 227–235
2024
-
[21]
Snape: Reliable and low-cost computing with mixture of spot and on-demand vms,
F. Yang, L. Wang, Z. Xu, J. Zhang, L. Li, B. Qiao, C. Couturier, C. Bansal, S. Ram, S. Qin, Z. Ma, I. n. Goiri, E. Cortez, T. Yang, V . R ¨uhle, S. Rajmohan, Q. Lin, and D. Zhang, “Snape: Reliable and low-cost computing with mixture of spot and on-demand vms,” inProceedings of the 28th ACM International Conference on Architectural Support for Programming ...
-
[22]
T. Chen and C. Guestrin, “Xgboost: A scalable tree boosting system,” inProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, ser. KDD ’16. New York, NY , USA: Association for Computing Machinery, 2016, p. 785–794. [Online]. Available: https://doi.org/10.1145/2939672.2939785
-
[23]
Long short-term memory,
S. Hochreiter and J. Schmidhuber, “Long short-term memory,”Neural Computation, vol. 9, no. 8, pp. 1735–1780, 1997
1997
-
[24]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. u. Kaiser, and I. Polosukhin, “Attention is all you need,” inAdvances in Neural Information Processing Systems, I. Guyon, U. V . Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, Eds., vol. 30. Curran Associates, Inc., 2017. [Online]. Available: https://pr...
2017
-
[25]
The making of tpc-ds,
R. O. Nambiar and M. Poess, “The making of tpc-ds,” inProceedings of the 32nd International Conference on Very Large Data Bases, ser. VLDB ’06. VLDB Endowment, 2006, p. 1049–1058
2006
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.