Recognition: unknown
Towards Reliable Testing of Machine Unlearning
Pith reviewed 2026-05-10 11:21 UTC · model grok-4.3
The pith
Standard attribution checks miss residual influence in unlearned models due to proxy pathways and cancellation effects, necessitating causal testing instead.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that reliable unlearning verification requires addressing proxy and mediated pathways through a causal perspective, where budgeted interventions estimate residual effects to produce actionable diagnostics that standard checks cannot provide.
What carries the argument
Causal fuzzing, a pathway-centric method that generates budgeted interventions to estimate residual direct and indirect effects.
Load-bearing premise
Budgeted causal interventions can be generated and run efficiently enough under realistic query limits to give reliable estimates of leakage without needing model internals or the original training data.
What would settle it
An experiment where a model is unlearned on known data but retains proxy influence, and causal fuzzing detects the leakage while attribution methods report none, with confirmation via retraining from scratch.
Figures

read the original abstract
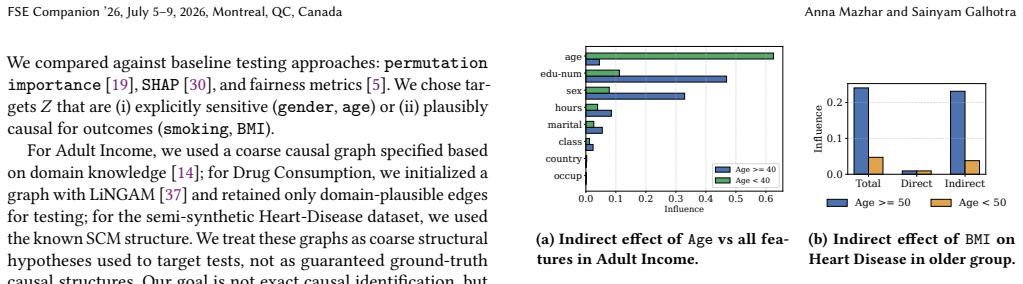
Machine learning components are now central to AI-infused software systems, from recommendations and code assistants to clinical decision support. As regulations and governance frameworks increasingly require deleting sensitive data from deployed models, machine unlearning is emerging as a practical alternative to full retraining. However, unlearning introduces a software quality-assurance challenge: under realistic deployment constraints and imperfect oracles, how can we test that a model no longer relies on targeted information? This paper frames unlearning testing as a first-class software engineering problem. We argue that practical unlearning tests must provide (i) thorough coverage over proxy and mediated influence pathways, (ii) debuggable diagnostics that localize where leakage persists, (iii) cost-effective regression-style execution under query budgets, and (iv) black-box applicability for API-deployed models. We outline a causal, pathway-centric perspective, causal fuzzing, that generates budgeted interventions to estimate residual direct and indirect effects and produce actionable "leakage reports". Proof-of-concept results illustrate that standard attribution checks can miss residual influence due to proxy pathways, cancellation effects, and subgroup masking, motivating causal testing as a promising direction for unlearning testing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper frames machine unlearning testing as a software engineering problem and argues that standard attribution checks are insufficient because they miss residual influence via proxy pathways, cancellation effects, and subgroup masking. It proposes causal fuzzing as a pathway-centric approach that generates budgeted interventions to estimate direct and indirect effects, produce debuggable leakage reports, and operate under query budgets in black-box API settings. Proof-of-concept illustrations are provided to motivate the need for this causal perspective over conventional methods.
Significance. If the causal fuzzing framework can be made concrete with explicit intervention-generation procedures and supporting empirical validation, the work could meaningfully advance reliable verification of unlearning in regulated, deployed ML systems where full retraining is impractical.
major comments (2)
- [§3] §3 (Causal Fuzzing): The description of intervention generation provides no concrete procedure or algorithm for systematically selecting or sampling interventions that cover proxy and mediated pathways in a strict black-box setting without model internals or training data. This directly undermines the claim that the method overcomes the listed failure modes of attribution checks, as coverage guarantees remain unspecified and the approach reduces to unspecified heuristic search.
- [Proof-of-Concept Results] Proof-of-Concept Results (likely §4 or §5): The results are presented qualitatively with no quantitative metrics, error bars, details on how interventions were budgeted or validated, or comparison against baselines, leaving the central motivation that causal testing is promising without rigorous evidence.
minor comments (2)
- [§3] Clarify the exact definition and computation of 'leakage reports' from the intervention outcomes, including any aggregation or statistical procedure.
- [Introduction] The abstract and introduction would benefit from a short related-work paragraph distinguishing causal fuzzing from existing influence-function and attribution literature.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the potential of the causal fuzzing perspective for reliable unlearning verification in deployed systems. We agree that greater concreteness is needed and address the major comments below, outlining revisions that will strengthen the manuscript without altering its position-paper scope.
read point-by-point responses
-
Referee: [§3] §3 (Causal Fuzzing): The description of intervention generation provides no concrete procedure or algorithm for systematically selecting or sampling interventions that cover proxy and mediated pathways in a strict black-box setting without model internals or training data. This directly undermines the claim that the method overcomes the listed failure modes of attribution checks, as coverage guarantees remain unspecified and the approach reduces to unspecified heuristic search.
Authors: We acknowledge that §3 presents causal fuzzing at a conceptual level, describing the principles of budgeted interventions for estimating direct and indirect residual effects rather than a fully specified algorithm. The manuscript frames the work as an outline of a pathway-centric perspective to motivate why standard attribution methods are insufficient, with the black-box applicability argued via query-only access. We agree that explicit procedures for intervention selection (e.g., how to sample perturbations targeting potential proxies without internals) would make the framework more actionable and address coverage concerns. In revision we will add a high-level algorithm sketch, including query-efficient sampling strategies such as sensitivity-guided perturbations and iterative refinement under budget constraints, while clarifying that full coverage guarantees are an open research question beyond this position paper. revision: yes
-
Referee: [Proof-of-Concept Results] Proof-of-Concept Results (likely §4 or §5): The results are presented qualitatively with no quantitative metrics, error bars, details on how interventions were budgeted or validated, or comparison against baselines, leaving the central motivation that causal testing is promising without rigorous evidence.
Authors: We agree that the proof-of-concept results are qualitative and illustrative, intended to demonstrate concrete scenarios in which attribution methods miss leakage due to proxies, cancellations, and subgroup masking. The manuscript does not claim these examples constitute rigorous empirical validation. To strengthen the central motivation, we will revise the results section to include quantitative metrics (e.g., leakage detection rates across scenarios), details on query budgets used for interventions, statistical measures such as error bars from repeated runs, and direct comparisons against standard attribution baselines. This will provide clearer evidence while preserving the illustrative focus. revision: yes
Circularity Check
No significant circularity; proposal is a new testing perspective without self-referential derivations.
full rationale
The manuscript frames unlearning testing as a software engineering problem and outlines causal fuzzing as a budgeted intervention approach. No equations, fitted parameters, or first-principles results are presented that reduce by construction to the paper's own inputs or prior self-citations. The central argument relies on conceptual motivation from observed limitations of attribution methods rather than any closed derivation chain, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Causal interventions on inputs can isolate direct and indirect effects of unlearned data in black-box models
Reference graph
Works this paper leans on
-
[1]
Zohreh Aghababaeyan, Manel Abdellatif, Lionel Briand, Ramesh S, and Mojtaba Bagherzadeh. 2023. Black-Box Testing of Deep Neural Networks through Test Case Diversity.IEEE Trans. Softw. Eng.(2023)
2023
-
[2]
Saleema Amershi et al. 2019. Software Engineering for Machine Learning: A Case Study. In2019 IEEE/ACM 41st International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP)
2019
-
[3]
Barr, Mark Harman, Phil McMinn, Muzammil Shahbaz, and Shin Yoo
Earl T. Barr, Mark Harman, Phil McMinn, Muzammil Shahbaz, and Shin Yoo
-
[4]
The Oracle Problem in Software Testing: A Survey.IEEE Transactions on Software Engineering(2015)
2015
-
[5]
Barry Becker and Ronny Kohavi. 1996. Adult. UCI Machine Learning Repository
1996
- [6]
-
[7]
Martin Andres Bertran, Shuai Tang, Michael Kearns, Jamie Heather Morgenstern, Aaron Roth, and Steven Wu. 2024. Reconstruction Attacks on Machine Unlearn- ing: Simple Models are Vulnerable. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems
2024
-
[8]
Choquette-Choo, Hengrui Jia, Adelin Travers, Baiwu Zhang, David Lie, and Nicolas Papernot
Lucas Bourtoule, Varun Chandrasekaran, Christopher A. Choquette-Choo, Hen- grui Jia, Adelin Travers, Baiwu Zhang, David Lie, and Nicolas Papernot. 2020. Machine Unlearning. arXiv:1912.03817
-
[9]
Nicholas Carlini, Jamie Hayes, Milad Nasr, Matthew Jagielski, Vikash Sehwag, Florian Tramèr, Borja Balle, Daphne Ippolito, and Eric Wallace. 2023. Extracting training data from diffusion models. InProceedings of the 32nd USENIX Conference on Security Symposium
2023
-
[10]
Nicholas Carlini, Florian Tramèr, Eric Wallace, Matthew Jagielski, Ariel Herbert- Voss, Katherine Lee, Adam Roberts, Tom Brown, Dawn Song, Úlfar Erlingsson, Alina Oprea, and Colin Raffel. 2021. Extracting Training Data from Large Lan- guage Models. In30th USENIX Security Symposium (USENIX Security 21)
2021
-
[11]
Jinyin Chen, Chengyu Jia, Yunjie Yan, Jie Ge, Haibin Zheng, and Yao Cheng. 2024. A Miss Is as Good as A Mile: Metamorphic Testing for Deep Learning Operators. Proc. ACM Softw. Eng.FSE (2024)
2024
-
[12]
Min Chen, Zhikun Zhang, Tianhao Wang, Michael Backes, Mathias Humbert, and Yang Zhang. 2021. When Machine Unlearning Jeopardizes Privacy. InProceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security (CCS ’21). 896–911
2021
-
[13]
Tsong Yueh Chen, Fei-Ching Kuo, Huai Liu, Pak-Lok Poon, Dave Towey, T. H. Tse, and Zhi Quan Zhou. 2018. Metamorphic Testing: A Review of Challenges and Opportunities. (2018)
2018
-
[14]
Zhang, Max Hort, Mark Harman, and Federica Sarro
Zhenpeng Chen, Jie M. Zhang, Max Hort, Mark Harman, and Federica Sarro
-
[15]
Fairness Testing: A Comprehensive Survey and Analysis of Trends.ACM Trans. Softw. Eng. Methodol.(2024)
2024
-
[16]
Silvia Chiappa. 2019. Path-specific counterfactual fairness. InProceedings of the Thirty-Third AAAI Conference on Artificial Intelligence and Thirty-First Innovative Applications of Artificial Intelligence Conference and Ninth AAAI Symposium on Educational Advances in Artificial Intelligence (AAAI’19/IAAI’19/EAAI’19)
2019
-
[17]
European Commission (AI Act Service Desk). 2024. EU Artificial Intelligence Act — Article 11: Technical documentation. https://ai-act-service-desk.ec.europa.eu/ en/ai-act/article-11
2024
-
[18]
European Commission (AI Act Service Desk). 2024. EU Artificial Intelligence Act — Article 72: Post-market monitoring by providers. https://ai-act-service- desk.ec.europa.eu/en/ai-act/article-72
2024
-
[19]
2016.General Data Protection Regulation (GDPR), Article 17
European Parliament and Council of the European Union. 2016.General Data Protection Regulation (GDPR), Article 17. Official Journal of the European Union. https://gdpr-info.eu/art-17-gdpr/
2016
-
[20]
Elaine Fehrman, Vincent Egan, and Evgeny Mirkes. 2015. Drug Consumption (Quantified). UCI Machine Learning Repository
2015
- [21]
-
[22]
Garima, Frederick Liu, Satyen Kale, and Mukund Sundararajan. 2020. Estimating training data influence by tracing gradient descent. InProceedings of the 34th International Conference on Neural Information Processing Systems (NIPS ’20)
2020
- [23]
-
[24]
Fabrice Harel-Canada, Lingxiao Wang, Muhammad Ali Gulzar, Quanquan Gu, and Miryung Kim. 2020. Is neuron coverage a meaningful measure for testing deep neural networks?(ESEC/FSE 2020). New York, NY, USA
2020
-
[25]
ISO/IEC. 2023. ISO/IEC 23894:2023 — Artificial intelligence — Guidance on risk management. https://www.iso.org/standard/77304.html
2023
- [26]
- [27]
-
[28]
Weipeng Jiang, Juan Zhai, Shiqing Ma, Xiaoyu Zhang, and Chao Shen. 2024. COSTELLO: Contrastive Testing for Embedding-Based Large Language Model as a Service Embeddings.Proceedings of the ACM on Software Engineering(2024)
2024
-
[29]
Jones, M.J
J.A. Jones, M.J. Harrold, and J. Stasko. 2002. Visualization of test information to assist fault localization. InProceedings of the 24th International Conference on Software Engineering. ICSE 2002
2002
-
[30]
Pang Wei Koh and Percy Liang. 2017. Understanding black-box predictions via influence functions. InProceedings of the 34th International Conference on Machine Learning - Volume 70 (ICML’17)
2017
-
[31]
Caroline Lemieux and Koushik Sen. 2018. FairFuzz: A Targeted Mutation Strategy for Increasing Greybox Fuzz Testing Coverage. In33rd IEEE/ACM International Conference on Automated Software Engineering (ASE)
2018
-
[32]
Lundberg and Su-In Lee
Scott M. Lundberg and Su-In Lee. 2017. A unified approach to interpreting model predictions. InProceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17). 4768–4777
2017
-
[33]
Yanzhou Mu, Juan Zhai, Chunrong Fang, Xiang Chen, Zhixiang Cao, Peiran Yang, Kexin Zhao, An Guo, and Zhenyu Chen. 2025. Improving Deep Learning Framework Testing with Model-Level Metamorphic Testing.Proc. ACM Softw. Eng.ISSTA (2025)
2025
-
[34]
Kexin Pei, Yinzhi Cao, Junfeng Yang, and Suman Jana. 2019. DeepXplore: auto- mated whitebox testing of deep learning systems.Commun. ACM(2019)
2019
-
[35]
Ahmed Salem, Apratim Bhattacharya, Michael Backes, Mario Fritz, and Yang Zhang. 2020. Updates-leak: data set inference and reconstruction attacks in online learning. InProceedings of the 29th USENIX Conference on Security Symposium (SEC’20)
2020
-
[36]
Ahmed Salem, Yang Zhang, Mathias Humbert, Pascal Berrang, Mario Fritz, and Michael Backes. 2018. ML-Leaks: Model and Data Independent Membership Inference Attacks and Defenses on Machine Learning Models. arXiv:1806.01246
work page Pith review arXiv 2018
-
[37]
Amit Sharma and Emre Kiciman. 2020. DoWhy: An End-to-End Library for Causal Inference
2020
-
[38]
Smith, and Chiyuan Zhang
Weijia Shi, Jaechan Lee, Yangsibo Huang, Sadhika Malladi, Jieyu Zhao, Ari Holtz- man, Daogao Liu, Luke Zettlemoyer, Noah A. Smith, and Chiyuan Zhang. 2025. MUSE: Machine Unlearning Six-Way Evaluation for Language Models. InThe Thirteenth International Conference on Learning Representations
2025
-
[39]
Hoyer, Aapo Hyvärinen, and Antti Kerminen
Shohei Shimizu, Patrik O. Hoyer, Aapo Hyvärinen, and Antti Kerminen. 2006. A Linear Non-Gaussian Acyclic Model for Causal Discovery.J. Mach. Learn. Res. (2006)
2006
-
[40]
Reza Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. 2017. Mem- bership Inference Attacks Against Machine Learning Models . In2017 IEEE Sym- posium on Security and Privacy (SP). 3–18
2017
-
[41]
Karen Simonyan, Andrea Vedaldi, and Andrew Zisserman. 2014. Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps. arXiv:1312.6034
work page Pith review arXiv 2014
-
[42]
Sommer, Liwei SOng, Sameer Wagh, and Prateek Mittal
David M. Sommer, Liwei SOng, Sameer Wagh, and Prateek Mittal. 2022. Athena: Probabilistic Verification of Machine Unlearning.Proceedings on Privacy Enhanc- ing Technologies
2022
-
[43]
State of California. 2018. California Consumer Privacy Act of 2018 (CCPA). California Civil Code, Division 3, Part 4, Title 1.81.5. https://leginfo.legislature.ca. gov/faces/codes_displaySection.xhtml?sectionNum=1798.105&lawCode=CIV
2018
-
[44]
Mukund Sundararajan, Ankur Taly, and Qiqi Yan. 2017. Axiomatic attribution for deep networks. InProceedings of the 34th International Conference on Machine Learning - Volume 70 (ICML’17)
2017
-
[45]
Elham Tabassi. 2023. Artificial Intelligence Risk Management Framework (AI RMF 1.0). https://tsapps.nist.gov/publication/get_pdf.cfm?pub_id=936225
2023
-
[46]
Yuchi Tian, Kexin Pei, Suman Jana, and Baishakhi Ray. 2018. DeepTest: automated testing of deep-neural-network-driven autonomous cars. InProceedings of the 40th International Conference on Software Engineering. New York, NY, USA
2018
-
[47]
Longtian Wang, Xiaofei Xie, Xiaoning Du, Meng Tian, Qing Guo, Zheng Yang, and Chao Shen. 2023. DistXplore: Distribution-Guided Testing for Evaluating and Enhancing Deep Learning Systems(ESEC/FSE 2023). Association for Computing Machinery, New York, NY, USA
2023
-
[48]
Xiaofei Xie et al. 2019. DeepHunter: a coverage-guided fuzz testing framework for deep neural networks. InProceedings of the 28th ACM SIGSOFT International Sym- posium on Software Testing and Analysis (ISSTA 2019). Association for Computing Machinery, New York, NY, USA
2019
-
[49]
Shenao Yan, Guanhong Tao, Xuwei Liu, Juan Zhai, Shiqing Ma, Lei Xu, and Xiangyu Zhang. 2020. Correlations between deep neural network model coverage criteria and model quality(ESEC/FSE 2020). Association for Computing Machinery, New York, NY, USA
2020
-
[50]
Andreas Zeller. 2002. Isolating cause-effect chains from computer programs (SIGSOFT ’02/FSE-10). Association for Computing Machinery, New York, NY, USA
2002
-
[51]
Zeller and R
A. Zeller and R. Hildebrandt. 2002. Simplifying and isolating failure-inducing input.IEEE Transactions on Software Engineering(2002)
2002
-
[52]
Zhang, Mark Harman, Lei Ma, and Yang Liu
Jie M. Zhang, Mark Harman, Lei Ma, and Yang Liu. 2022. Machine Learning Test- ing: Survey, Landscapes and Horizons.IEEE Transactions on Software Engineering (2022)
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.