Recognition: unknown
In Search of Lost DNA Sequence Pretraining
Pith reviewed 2026-05-10 08:49 UTC · model grok-4.3
The pith
DNA pretraining suffers from inappropriate evaluation datasets, flawed neighbor-masking, and neglected vocabulary design; the authors supply guidelines and a reproducible testbed to fix them.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
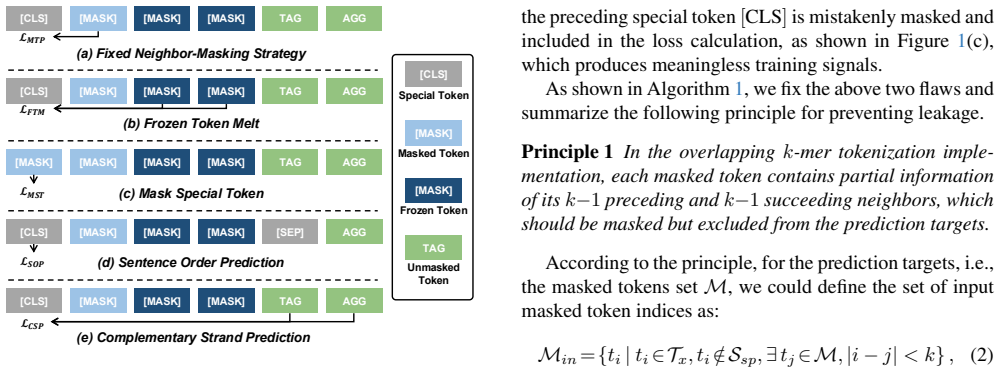
We reveal three critical yet heretofore overlooked problems in DNA pretraining: inappropriate downstream datasets, inherent flaws in the neighbor-masking strategy, and the lack of detailed discussion on vocabulary. ... we introduce a standardized testbed that enables reproducible and rigorous benchmarking of DNA pretraining methods.
Load-bearing premise
That the three identified problems are the primary overlooked issues and that the proposed guidelines plus testbed will produce meaningfully better genomic models, as validated by the authors' experiments.
Figures






read the original abstract
DNA sequence encoding is fundamental to gene function prediction, protein synthesis, and diverse downstream biological tasks. Despite the substantial progress achieved by large-scale DNA sequence pretraining, existing studies have overwhelmingly emphasized pretraining scale and custom downstream evaluation datasets, while neglecting some essential components of the pretraining paradigm. In this paper, we reveal three critical yet heretofore overlooked problems in DNA pretraining: inappropriate downstream datasets, inherent flaws in the neighbor-masking strategy, and the lack of detailed discussion on vocabulary. Therefore, we undertake comprehensive investigations and propose principled guidelines, including selection criteria for evaluation datasets, guiding task design, and in-depth vocabulary analysis. Extensive experiments validate the significance of our identified problems and support the rationale behind our recommendations. Finally, we introduce a standardized testbed that enables reproducible and rigorous benchmarking of DNA pretraining methods to advance the development of genomic foundation models.
Editorial analysis
A structured set of objections, weighed in public.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
An atlas of active enhancers across human cell types and tissues.Nature, 507(7493):455–461, 2014
Robin Andersson, Claudia Gebhard, Irene Miguel-Escalada, Ilka Hoof, Jette Bornholdt, Mette Boyd, Yun Chen, Xiaobei Zhao, Christian Schmidl, Takahiro Suzuki, et al. An atlas of active enhancers across human cell types and tissues.Nature, 507(7493):455–461, 2014. 3
2014
-
[2]
Barcodebert: Transformers for biodiversity analysis.arXiv preprint arXiv:2311.02401, 2023
Pablo Millan Arias, Niousha Sadjadi, Monireh Safari, ZeM- ing Gong, Austin T Wang, Scott C Lowe, Joakim Bruslund Haurum, Iuliia Zarubiieva, Dirk Steinke, Lila Kari, et al. Barcodebert: Transformers for biodiversity analysis.arXiv preprint arXiv:2311.02401, 2023. 2, 3
-
[3]
Genome modeling and design across all domains of life with evo 2.BioRxiv, pages 2025–02, 2025
Garyk Brixi, Matthew G Durrant, Jerome Ku, Michael Poli, Greg Brockman, Daniel Chang, Gabriel A Gonza- lez, Samuel H King, David B Li, Aditi T Merchant, et al. Genome modeling and design across all domains of life with evo 2.BioRxiv, pages 2025–02, 2025. 1, 3
2025
-
[4]
An integrated encyclo- pedia of dna elements in the human genome.Nature, 489 (7414):57, 2012
ENCODE Project Consortium et al. An integrated encyclo- pedia of dna elements in the human genome.Nature, 489 (7414):57, 2012. 1, 3
2012
-
[5]
Nucleotide trans- former: building and evaluating robust foundation models for human genomics.Nature Methods, 22(2):287–297, 2025
Hugo Dalla-Torre, Liam Gonzalez, Javier Mendoza-Revilla, Nicolas Lopez Carranza, Adam Henryk Grzywaczewski, Francesco Oteri, Christian Dallago, Evan Trop, Bernardo P de Almeida, Hassan Sirelkhatim, et al. Nucleotide trans- former: building and evaluating robust foundation models for human genomics.Nature Methods, 22(2):287–297, 2025. 1, 3, 5, 6, 13, 14
2025
-
[6]
Bert: Pre-training of deep bidirectional trans- formers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional trans- formers for language understanding. InProceedings of the 2019 conference of the North American chapter of the asso- ciation for computational linguistics: human language tech- nologies, volume 1 (long and short papers), pages 4171– 4186, 2019. 3, 4
2019
-
[7]
An introduction to roc analysis.Pattern recog- nition letters, 27(8):861–874, 2006
Tom Fawcett. An introduction to roc analysis.Pattern recog- nition letters, 27(8):861–874, 2006. 6
2006
-
[8]
Jaspar 2020: update of the open-access database of transcrip- tion factor binding profiles.Nucleic acids research, 48(D1): D87–D92, 2020
Oriol Fornes, Jaime A Castro-Mondragon, Aziz Khan, Robin Van der Lee, Xi Zhang, Phillip A Richmond, Bhavi P Modi, Solenne Correard, Marius Gheorghe, Damir Baranaˇsi´c, et al. Jaspar 2020: update of the open-access database of transcrip- tion factor binding profiles.Nucleic acids research, 48(D1): D87–D92, 2020. 3
2020
-
[9]
Gencode 2021.Nucleic acids research, 49(D1):D916–D923, 2021
Adam Frankish, Mark Diekhans, Irwin Jungreis, Julien La- garde, Jane E Loveland, Jonathan M Mudge, Cristina Sisu, James C Wright, Joel Armstrong, If Barnes, et al. Gencode 2021.Nucleic acids research, 49(D1):D916–D923, 2021. 3
2021
-
[10]
Cpg is- lands in vertebrate genomes.Journal of molecular biology, 196(2):261–282, 1987
Margaret Gardiner-Garden and Marianne Frommer. Cpg is- lands in vertebrate genomes.Journal of molecular biology, 196(2):261–282, 1987. 2
1987
-
[11]
Human genome assembly grch38.p14 (gcf 000001405.40).https://www.ncbi
Genome Reference Consortium. Human genome assembly grch38.p14 (gcf 000001405.40).https://www.ncbi. nlm.nih.gov/assembly/GCF_000001405.40/,
-
[12]
Accessed: 2025-07-29. 6, 14
2025
-
[13]
Comparing two k-category assignments by a k-category correlation coefficient.Computational biology and chemistry, 28(5-6):367–374, 2004
Jan Gorodkin. Comparing two k-category assignments by a k-category correlation coefficient.Computational biology and chemistry, 28(5-6):367–374, 2004. 6
2004
-
[14]
Genomic benchmarks: a collection of datasets for genomic sequence classification
Katar ´ına Greˇsov´a, Vlastimil Martinek, David ˇCech´ak, Petr ˇSimeˇcek, and Panagiotis Alexiou. Genomic benchmarks: a collection of datasets for genomic sequence classification. BMC Genomic Data, 24(1):25, 2023. 3, 6, 13
2023
-
[15]
Springer, 2009
Trevor Hastie, Robert Tibshirani, Jerome H Friedman, and Jerome H Friedman.The elements of statistical learning: data mining, inference, and prediction. Springer, 2009. 6, 7, 14, 15
2009
-
[16]
Prentice Hall PTR, 1998
Simon Haykin.Neural networks: a comprehensive founda- tion. Prentice Hall PTR, 1998. 6, 14
1998
-
[17]
Delving deep into rectifiers: Surpassing human-level perfor- mance on imagenet classification
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Delving deep into rectifiers: Surpassing human-level perfor- mance on imagenet classification. InProceedings of the IEEE international conference on computer vision, pages 1026–1034, 2015. 6, 14
2015
-
[18]
Dnabert: pre-trained bidirectional encoder representa- tions from transformers model for dna-language in genome
Yanrong Ji, Zhihan Zhou, Han Liu, and Ramana V Davu- luri. Dnabert: pre-trained bidirectional encoder representa- tions from transformers model for dna-language in genome. Bioinformatics, 37(15):2112–2120, 2021. 1, 2, 3, 4, 6, 11
2021
-
[19]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Chromatin modifications and their func- tion.Cell, 128(4):693–705, 2007
Tony Kouzarides. Chromatin modifications and their func- tion.Cell, 128(4):693–705, 2007. 3
2007
-
[21]
Jerome Ku, Eric Nguyen, David W Romero, Garyk Brixi, Brandon Yang, Anton V orontsov, Ali Taghibakhshi, Amy X Lu, Dave P Burke, Greg Brockman, et al. Systems and al- gorithms for convolutional multi-hybrid language models at scale.arXiv preprint arXiv:2503.01868, 2025. 3
-
[22]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 14
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[23]
MIT press, 1999
Christopher Manning and Hinrich Schutze.Foundations of statistical natural language processing. MIT press, 1999. 2
1999
-
[24]
Frederikke Isa Marin, Felix Teufel, Marc Horlacher, Dennis Madsen, Dennis Pultz, Ole Winther, and Wouter Boomsma. Bend: Benchmarking dna language models on biologically meaningful tasks.arXiv preprint arXiv:2311.12570, 2023. 1, 3, 6, 12, 13, 14
-
[25]
Hye- nadna: Long-range genomic sequence modeling at single nu- cleotide resolution.Advances in neural information process- ing systems, 36:43177–43201, 2023
Eric Nguyen, Michael Poli, Marjan Faizi, Armin Thomas, Michael Wornow, Callum Birch-Sykes, Stefano Massaroli, 9 Aman Patel, Clayton Rabideau, Yoshua Bengio, et al. Hye- nadna: Long-range genomic sequence modeling at single nu- cleotide resolution.Advances in neural information process- ing systems, 36:43177–43201, 2023. 1, 3, 6, 14
2023
-
[26]
Sequence mod- eling and design from molecular to genome scale with evo
Eric Nguyen, Michael Poli, Matthew G Durrant, Brian Kang, Dhruva Katrekar, David B Li, Liam J Bartie, Armin W Thomas, Samuel H King, Garyk Brixi, et al. Sequence mod- eling and design from molecular to genome scale with evo. Science, 386(6723):eado9336, 2024. 1, 3
2024
-
[27]
Ch ip-atlas: a data-mining suite powered by full integration of public ch ip-seq data.EMBO reports, 19(12):e46255, 2018
Shinya Oki, Tazro Ohta, Go Shioi, Hideki Hatanaka, Osamu Ogasawara, Yoshihiro Okuda, Hideya Kawaji, Ryo Nakaki, Jun Sese, and Chikara Meno. Ch ip-atlas: a data-mining suite powered by full integration of public ch ip-seq data.EMBO reports, 19(12):e46255, 2018. 3
2018
-
[28]
Model decides how to tokenize: Adaptive dna sequence tok- enization with mxdna.Advances in Neural Information Pro- cessing Systems, 37:66080–66107, 2024
Lifeng Qiao, Peng Ye, Yuchen Ren, Weiqiang Bai, Chaoqi Liang, Xinzhu Ma, Nanqing Dong, and Wanli Ouyang. Model decides how to tokenize: Adaptive dna sequence tok- enization with mxdna.Advances in Neural Information Pro- cessing Systems, 37:66080–66107, 2024. 6, 14
2024
-
[29]
Improving language understanding by gen- erative pre-training
Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, et al. Improving language understanding by gen- erative pre-training. 2018. 3
2018
-
[30]
U- net: Convolutional networks for biomedical image segmen- tation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U- net: Convolutional networks for biomedical image segmen- tation. InInternational Conference on Medical image com- puting and computer-assisted intervention, pages 234–241. Springer, 2015. 6, 14
2015
-
[31]
Neural Machine Translation of Rare Words with Subword Units
Rico Sennrich, Barry Haddow, and Alexandra Birch. Neural machine translation of rare words with subword units.arXiv preprint arXiv:1508.07909, 2015. 2, 5
work page internal anchor Pith review arXiv 2015
-
[32]
A mathematical theory of communi- cation.The Bell system technical journal, 27(3):379–423,
Claude E Shannon. A mathematical theory of communi- cation.The Bell system technical journal, 27(3):379–423,
-
[33]
An analysis of variance test for normality.Biometrika, 52(3):591–611, 1965
S Shaphiro and MBJB Wilk. An analysis of variance test for normality.Biometrika, 52(3):591–611, 1965. 5, 7
1965
-
[34]
K-mer content, correlation, and po- sition analysis of genome dna sequences for the identifica- tion of function and evolutionary features.Genes, 8(4):122,
Aaron Sievers, Katharina Bosiek, Marc Bisch, Chris Dreessen, Jascha Riedel, Patrick Froß, Michael Hausmann, and Georg Hildenbrand. K-mer content, correlation, and po- sition analysis of genome dna sequences for the identifica- tion of function and evolutionary features.Genes, 8(4):122,
-
[35]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063,
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063,
-
[36]
The information bottleneck method
Naftali Tishby, Fernando C Pereira, and William Bialek. The information bottleneck method.arXiv preprint physics/0004057, 2000. 11
work page Pith review arXiv 2000
-
[37]
Generator: a long-context generative genomic foundation model
Wei Wu, Qiuyi Li, Mingyang Li, Kun Fu, Fuli Feng, Jieping Ye, Hui Xiong, and Zheng Wang. Generator: a long-context generative genomic foundation model.arXiv preprint arXiv:2502.07272, 2025. 3
-
[38]
Daoan Zhang, Weitong Zhang, Yu Zhao, Jianguo Zhang, Bing He, Chenchen Qin, and Jianhua Yao. Dnagpt: A gen- eralized pre-trained tool for versatile dna sequence analysis tasks.arXiv preprint arXiv:2307.05628, 2023. 3
-
[39]
Predicting effects of noncoding variants with deep learning–based sequence model.Nature methods, 12(10):931–934, 2015
Jian Zhou and Olga G Troyanskaya. Predicting effects of noncoding variants with deep learning–based sequence model.Nature methods, 12(10):931–934, 2015. 1
2015
-
[40]
Zhihan Zhou, Yanrong Ji, Weijian Li, Pratik Dutta, Ra- mana Davuluri, and Han Liu. Dnabert-2: Efficient founda- tion model and benchmark for multi-species genome.arXiv preprint arXiv:2306.15006, 2023. 3, 5, 6 10 The supplementary material provides additional details to complement the main paper.More details for method, we further prove the information lea...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.