Recognition: unknown
FedOBP: Federated Optimal Brain Personalization through Cloud-Edge Element-wise Decoupling
Pith reviewed 2026-05-10 08:29 UTC · model grok-4.3
The pith
FedOBP introduces a quantile-thresholded importance score based on a federated first-order Taylor approximation to select a small set of parameters for personalization, claiming better performance than prior PFL methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Extensive experiments demonstrate that FedOBP outperforms state-of-the-art methods across diverse datasets and heterogeneity scenarios, while requiring personalization of only a very small number of personalized parameters.
Load-bearing premise
The federated approximation of the first-order derivative in the Taylor expansion accurately ranks parameters by their sensitivity to local loss landscapes, and the quantile threshold reliably separates globally useful from locally useful parameters without post-hoc tuning.
Figures






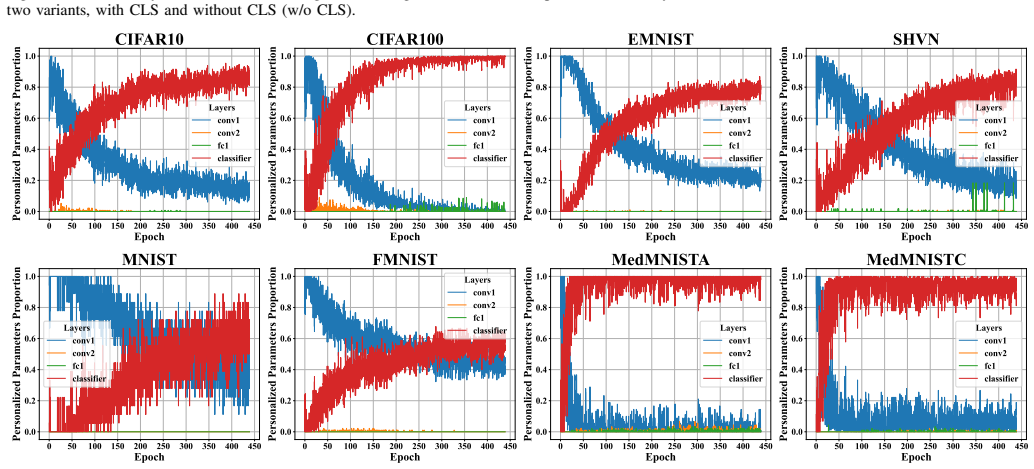

read the original abstract
Federated Learning (FL) faces challenges from client data heterogeneity and resource-constrained mobile devices, which can degrade model accuracy. Personalized Federated Learning (PFL) addresses this issue by adapting shared global knowledge to local data distributions. A promising approach in PFL is model decoupling, which separates the model into global and personalized parameters, raising the key question of which parameters should be personalized to balance global knowledge sharing and local adaptation. In this paper, we propose a Federated Optimal Brain Personalization (FedOBP) algorithm with a quantile-based thresholding mechanism and introduce an element-wise importance score. This score extends Optimal Brain Damage (OBD) pruning theory by incorporating a federated approximation of the first-order derivative in the Taylor expansion to evaluate the importance of each parameter for personalization. Moreover, we move the metric computation originally performed on clients to the server side, to alleviate the burden on resource-constrained mobile devices. To the best of our knowledge, this is the first work to bridge classical saliency-based pruning theory with federated parameter decoupling, providing a rigorous theoretical justification for selecting personalized parameters based on their sensitivity to local loss landscapes. Extensive experiments demonstrate that FedOBP outperforms state-of-the-art methods across diverse datasets and heterogeneity scenarios, while requiring personalization of only a very small number of personalized parameters.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FedOBP, a personalized federated learning algorithm that decouples model parameters into global and personalized sets using a quantile-based threshold on an element-wise importance score. This score extends Optimal Brain Damage by replacing the second-order term with a server-side federated approximation of the first-order derivative from the loss Taylor expansion, moving metric computation off clients to reduce edge-device burden. The central claim is that this provides a theoretically justified way to personalize only a very small number of parameters while outperforming state-of-the-art PFL methods across datasets and heterogeneity levels.
Significance. If the first-order approximation reliably ranks parameters by local loss sensitivity, the work would offer a novel and efficient bridge between classical saliency-based pruning and federated parameter decoupling, with practical benefits for resource-constrained clients. The server-side computation shift is a clear engineering strength that could generalize to other PFL methods.
major comments (2)
- [importance score definition and Taylor expansion] The element-wise importance score (defined via the federated first-order Taylor approximation) is load-bearing for the decoupling decision and the claim of outperformance with few personalized parameters. Classical OBD saliency uses the second-order Hessian term; the paper's substitution of only the first-order gradient term risks ranking by gradient magnitude rather than curvature or true local sensitivity. No derivation or external validation is provided showing that this approximation preserves ranking quality under heterogeneity, which directly undermines the 'rigorous theoretical justification' asserted in the abstract.
- [quantile-based thresholding mechanism] The quantile threshold is a free tunable parameter whose selection determines which parameters are personalized. The reported gains with 'only a very small number' of personalized parameters may depend on post-hoc choice of this threshold; without sensitivity analysis or cross-validation across heterogeneity scenarios, the experimental outperformance claims rest on potentially circular tuning.
minor comments (1)
- [abstract and experimental claims] The abstract states 'extensive experiments' but provides no details on baselines, number of runs, error bars, or ablation controls; the full experimental section should include these to allow verification of robustness.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on the theoretical grounding of the importance score and the experimental robustness of the quantile threshold in FedOBP. We address each major comment point by point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [importance score definition and Taylor expansion] The element-wise importance score (defined via the federated first-order Taylor approximation) is load-bearing for the decoupling decision and the claim of outperformance with few personalized parameters. Classical OBD saliency uses the second-order Hessian term; the paper's substitution of only the first-order gradient term risks ranking by gradient magnitude rather than curvature or true local sensitivity. No derivation or external validation is provided showing that this approximation preserves ranking quality under heterogeneity, which directly undermines the 'rigorous theoretical justification' asserted in the abstract.
Authors: We acknowledge that classical OBD employs the second-order Hessian diagonal for saliency, whereas FedOBP uses a server-side federated first-order approximation derived from the Taylor expansion of the local loss. This substitution is explicitly motivated by the need to shift computation away from resource-constrained clients, as full Hessian evaluation is prohibitive in federated settings. The first-order term still captures directional sensitivity to local loss changes, and the federated aggregation provides a stable estimate across clients. While the current manuscript does not contain an exhaustive derivation proving that the ranking is identical to full OBD under arbitrary heterogeneity, the approximation is justified when higher-order terms are negligible near local minima. We will revise the theoretical section to include a clearer derivation of the approximation error bounds and add new experiments that (i) compare parameter rankings produced by our score against those from a centralized OBD baseline on non-federated proxies and (ii) ablate ranking stability across varying Dirichlet heterogeneity parameters. These additions will strengthen the justification without changing the core algorithm. revision: partial
-
Referee: [quantile-based thresholding mechanism] The quantile threshold is a free tunable parameter whose selection determines which parameters are personalized. The reported gains with 'only a very small number' of personalized parameters may depend on post-hoc choice of this threshold; without sensitivity analysis or cross-validation across heterogeneity scenarios, the experimental outperformance claims rest on potentially circular tuning.
Authors: The quantile threshold is indeed a hyperparameter that controls the fraction of parameters marked for personalization. In the reported experiments we selected quantiles yielding a small personalization ratio (typically 1-5% of parameters) while ensuring competitive accuracy; these choices were fixed prior to final testing and applied uniformly across datasets. To directly address the concern of post-hoc tuning, we will add a comprehensive sensitivity study in the revised manuscript. This will include performance curves for quantile values ranging from 0.90 to 0.99 on all evaluated datasets, together with results under multiple heterogeneity regimes (Dirichlet concentration parameters 0.1, 0.5, and 1.0). The new analysis will demonstrate that FedOBP remains superior to baselines over a broad interval of thresholds, thereby removing any appearance of circular selection. revision: yes
Axiom & Free-Parameter Ledger
free parameters (1)
- quantile threshold
axioms (1)
- domain assumption The first-order Taylor expansion term provides a reliable importance ranking for parameters under federated data heterogeneity.
invented entities (1)
-
element-wise importance score
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Communication-efficient learning of deep networks from decentralized data,
B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication-efficient learning of deep networks from decentralized data,” inArtificial Intelligence and Statistics. PMLR, 2017, pp. 1273– 1282. 13
2017
-
[2]
Scaffold: Stochastic controlled aver- aging for federated learning,
S. P. Karimireddy, S. Kale, M. Mohri, S. Reddi, S. Stich, and A. T. Suresh, “Scaffold: Stochastic controlled aver- aging for federated learning,” inInternational conference on machine learning. PMLR, 2020, pp. 5132–5143
2020
-
[3]
Feddc: Federated learning with non-iid data via local drift decoupling and correction,
L. Gao, H. Fu, L. Li, Y . Chen, M. Xu, and C.-Z. Xu, “Feddc: Federated learning with non-iid data via local drift decoupling and correction,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2022, pp. 10 112–10 121
2022
-
[4]
Federated learning method based on contrastive representation knowledge distillation,
G. Zhou and J. Zheng, “Federated learning method based on contrastive representation knowledge distillation,” in 2025 5th International Conference on Computer Science, Electronic Information Engineering and Intelligent Con- trol Technology (CEI), 2025, pp. 102–105
2025
-
[5]
Heterogeneous federated learning driven by multi- knowledge distillation,
B. Xu, L. Cheng, Q. Wen, Z. Zou, X. Hu, Z. Dong, and J. Qi, “Heterogeneous federated learning driven by multi- knowledge distillation,”IEEE Transactions on Mobile Computing, vol. 24, no. 12, pp. 13 048–13 061, 2025
2025
-
[6]
Metafed: Federated learning among federations with cyclic knowl- edge distillation for personalized healthcare,
Y . Chen, W. Lu, X. Qin, J. Wang, and X. Xie, “Metafed: Federated learning among federations with cyclic knowl- edge distillation for personalized healthcare,”IEEE Transactions on Neural Networks and Learning Systems, 2023
2023
-
[7]
Fedgkd: Towards heterogeneous federated learning via global knowledge distillation,
D. Yao, W. Pan, Y . Dai, Y . Wan, X. Ding, C. Yu, H. Jin, Z. Xu, and L. Sun, “Fedgkd: Towards heterogeneous federated learning via global knowledge distillation,” IEEE Transactions on Computers, 2023
2023
-
[8]
Fedcache: A knowledge cache-driven federated learning architecture for person- alized edge intelligence,
Z. Wu, S. Sun, Y . Wang, M. Liu, K. Xu, W. Wang, X. Jiang, B. Gao, and J. Lu, “Fedcache: A knowledge cache-driven federated learning architecture for person- alized edge intelligence,”IEEE Transactions on Mobile Computing, vol. 23, no. 10, pp. 9368–9382, 2024
2024
-
[9]
Tackling spatial-temporal heterogeneous fed- erated learning with orthogonal regularization,
C. Wu, H. Wang, X. Zhang, H. Chen, J. Bu, and J. Liu, “Tackling spatial-temporal heterogeneous fed- erated learning with orthogonal regularization,”IEEE Transactions on Mobile Computing, pp. 1–17, 2026
2026
-
[10]
Personalized federated learning via gradient-fusion and gradient-decoupling for heteroge- neous data,
Z. He, Y . Li, and Z. Cai, “Personalized federated learning via gradient-fusion and gradient-decoupling for heteroge- neous data,”IEEE Transactions on Mobile Computing, vol. 25, no. 3, pp. 2956–2972, 2026
2026
-
[11]
Ditto: Fair and robust federated learning through personalization,
T. Li, S. Hu, A. Beirami, and V . Smith, “Ditto: Fair and robust federated learning through personalization,” in International conference on machine learning. PMLR, 2021, pp. 6357–6368
2021
-
[12]
Personalized federated learning with first or- der model optimization,
M. Zhang, K. Sapra, S. Fidler, S. Yeung, and J. M. Alvarez, “Personalized federated learning with first or- der model optimization,” inInternational Conference on Learning Representations, 2021
2021
-
[13]
On bridging generic and personalized federated learning for image classification,
H.-Y . Chen and W.-L. Chao, “On bridging generic and personalized federated learning for image classification,” inInternational Conference on Learning Representa- tions, 2022
2022
-
[14]
Reads: A personalized federated learning framework with fine- grained layer aggregation and decentralized clustering,
H. Fu, F. Tian, G. Deng, L. Liang, and X. Zhang, “Reads: A personalized federated learning framework with fine- grained layer aggregation and decentralized clustering,” IEEE Transactions on Mobile Computing, vol. 24, no. 8, pp. 7709–7725, 2025
2025
-
[15]
Classter: Mobile shift-robust personalized federated learning via class-wise clustering,
X. Li, S. Liu, Z. Zhou, Y . Xu, B. Guo, and Z. Yu, “Classter: Mobile shift-robust personalized federated learning via class-wise clustering,”IEEE Transactions on Mobile Computing, vol. 24, no. 3, pp. 2014–2028, 2025
2014
-
[16]
Personalized federated learning on non-iid data via group-based meta- learning,
L. Yang, J. Huang, W. Lin, and J. Cao, “Personalized federated learning on non-iid data via group-based meta- learning,”ACM Transactions on Knowledge Discovery from Data, vol. 17, no. 4, pp. 1–20, 2023
2023
-
[17]
Cpper-fl: Clustered parallel training for efficient personalized federated learning,
R. Zhang, F. Liu, J. Liu, M. Chen, Q. Tang, T. Huang, and F. R. Yu, “Cpper-fl: Clustered parallel training for efficient personalized federated learning,”IEEE Trans- actions on Mobile Computing, 2024
2024
-
[18]
Federated Learning with Personalization Layers
M. G. Arivazhagan, V . Aggarwal, A. K. Singh, and S. Choudhary, “Federated learning with personalization layers,”arXiv preprint arXiv:1912.00818, 2019
work page internal anchor Pith review arXiv 1912
-
[19]
Adaptive personalized fed- erated learning.arXiv preprint arXiv:2003.13461,
Y . Deng, M. M. Kamani, and M. Mahdavi, “Adap- tive personalized federated learning,”arXiv preprint arXiv:2003.13461, 2020
-
[20]
Think locally, act globally: Federated learning with local and global representations,
P. P. Liang, T. Liu, L. Ziyin, N. B. Allen, R. P. Auerbach, D. Brent, R. Salakhutdinov, and L.-P. Morency, “Think locally, act globally: Federated learning with local and global representations,”arXiv preprint arXiv:2001.01523, 2020
-
[21]
Exploiting shared representations for personalized fed- erated learning,
L. Collins, H. Hassani, A. Mokhtari, and S. Shakkottai, “Exploiting shared representations for personalized fed- erated learning,” inInternational Conference on Machine Learning. PMLR, 2021, pp. 2089–2099
2021
-
[22]
Fedbabu: Toward en- hanced representation for federated image classification,
J. Oh, S. Kim, and S.-Y . Yun, “Fedbabu: Toward en- hanced representation for federated image classification,” inInternational Conference on Learning Representa- tions, 2022
2022
-
[23]
Personalized federated learning with feature alignment and classifier collab- oration,
J. Xu, X. Tong, and S.-L. Huang, “Personalized federated learning with feature alignment and classifier collab- oration,” inThe Eleventh International Conference on Learning Representations, 2023
2023
-
[24]
doi:10.48550/arXiv.2305.15706 , abstract =
J. Tan, Y . Zhou, G. Liu, J. H. Wang, and S. Yu, “pfedsim: Similarity-aware model aggregation towards personalized federated learning,”arXiv preprint arXiv:2305.15706, 2023
-
[25]
Towards opti- mal customized architecture for heterogeneous federated learning with contrastive cloud-edge model decoupling,
C. Xingyan, D. Tian, W. Mu, G. Tiancheng, Z. Yu, K. Gang, X. Changqiao, and W. D. Oliver, “Towards opti- mal customized architecture for heterogeneous federated learning with contrastive cloud-edge model decoupling,” IEEE Transactions on Computers, 2024
2024
-
[26]
Personalized federated learn- ing via feature distribution adaptation,
C. Mclaughlin and L. Su, “Personalized federated learn- ing via feature distribution adaptation,” inThe Thirty- eighth Annual Conference on Neural Information Pro- cessing Systems, 2024
2024
-
[27]
Dynamic personalized federated learning with adaptive differential privacy,
X. Yang, W. Huang, and M. Ye, “Dynamic personalized federated learning with adaptive differential privacy,” Advances in Neural Information Processing Systems, vol. 36, pp. 72 181–72 192, 2023
2023
-
[28]
Accelerat- ing federated learning via parameter selection and pre- synchronization in mobile edge-cloud networks,
H. Zhou, M. Li, P. Sun, B. Guo, and Z. Yu, “Accelerat- ing federated learning via parameter selection and pre- synchronization in mobile edge-cloud networks,”IEEE Transactions on Mobile Computing, vol. 23, no. 11, pp. 10 313–10 328, 2024
2024
-
[29]
Fedselect: Personalized federated learning 14 with customized selection of parameters for fine-tuning,
R. Tamirisa, C. Xie, W. Bao, A. Zhou, R. Arel, and A. Shamsian, “Fedselect: Personalized federated learning 14 with customized selection of parameters for fine-tuning,” inProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, 2024, pp. 23 985– 23 994
2024
-
[30]
Optimal brain damage,
Y . LeCun, J. Denker, and S. Solla, “Optimal brain damage,”Advances in Neural Information Processing Systems, vol. 2, 1989
1989
-
[31]
Federated learning over connected modes,
D. Grinwald, P. Wiesner, and S. Nakajima, “Federated learning over connected modes,” inThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[32]
Federated representation learning in the under-parameterized regime,
R. Liu, C. Shen, and J. Yang, “Federated representation learning in the under-parameterized regime,” inForty- first International Conference on Machine Learning, 2024
2024
-
[33]
Seqfededt: Ac- celerating sequential federated learning on non-iid data via element-wise decoupled training,
T. Du, X. Chen, M. Wang, Y . Liu, S. Yao, G. Kou, F. Zhuang, C. Xu, and G.-M. Muntean, “Seqfededt: Ac- celerating sequential federated learning on non-iid data via element-wise decoupled training,”IEEE Transactions on Mobile Computing, pp. 1–16, 2025
2025
-
[34]
Second order derivatives for network pruning: Optimal brain surgeon,
B. Hassibi and D. Stork, “Second order derivatives for network pruning: Optimal brain surgeon,”Advances in Neural Information Processing Systems, vol. 5, 1992
1992
-
[35]
Llm-pruner: On the structural pruning of large language models,
X. Ma, G. Fang, and X. Wang, “Llm-pruner: On the structural pruning of large language models,”Advances in Neural Information Processing Systems, vol. 36, pp. 21 702–21 720, 2023
2023
-
[36]
Loraprune: Pruning meets low-rank parameter-efficient fine-tuning,
M. Zhang, H. Chen, C. Shen, Z. Yang, L. Ou, X. Yu, and B. Zhuang, “Loraprune: Pruning meets low-rank parameter-efficient fine-tuning,” 2023
2023
-
[37]
Distilling the knowledge in a neural network,
G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,”STAT, vol. 1050, p. 9, 2015
2015
-
[38]
Importance estimation for neural network pruning,
P. Molchanov, A. Mallya, S. Tyree, I. Frosio, and J. Kautz, “Importance estimation for neural network pruning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 11 264–11 272
2019
-
[39]
Adaptive federated optimization,
S. J. Reddi, Z. Charles, M. Zaheer, Z. Garrett, K. Rush, J. Kone ˇcn`y, S. Kumar, and H. B. McMahan, “Adaptive federated optimization,” inInternational Conference on Learning Representations, 2021
2021
-
[40]
Fedala: Adaptive local aggregation for personalized federated learning,
J. Zhang, Y . Hua, H. Wang, T. Song, Z. Xue, R. Ma, and H. Guan, “Fedala: Adaptive local aggregation for personalized federated learning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 9, 2023, pp. 11 237–11 244. Xingyan Chenreceived the Ph.D. degree in com- puter technology from Beijing University of Posts and Telecommunic...
2023
-
[41]
He has published in journals and confer- ences including IEEE TRANSACTIONS ONMOBILE COMPUTINGand IEEE INFOCOM
He is currently an Associate Professor with the School of Intelligent Engineering and Automation, BUPT. He has published in journals and confer- ences including IEEE TRANSACTIONS ONMOBILE COMPUTINGand IEEE INFOCOM. His research interests include federated learning, multi-agent re- inforcement learning, and stochastic optimization. Tian Duis currently purs...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.