Recognition: unknown
POLAR: Online Learning for LoRA Adapter Caching and Routing in Edge LLM Serving
Pith reviewed 2026-05-10 08:47 UTC · model grok-4.3
The pith
POLAR formulates joint LoRA adapter caching and routing as a two-timescale contextual bandit, achieving sublinear regret bounds and outperforming non-adaptive baselines in experiments with real adapters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
POLAR+ achieves sublinear regret of order O(d sqrt(NT) + sqrt(KT)) under stochastic regularity and cacheability conditions, with the routing term matching standard contextual bandit rates up to logs, and experiments show adaptive cache control substantially outperforms non-adaptive baselines.
Load-bearing premise
The stochastic regularity and cacheability conditions on adapter utilities and contexts hold in practice, allowing the epoch-doubling and forced exploration to deliver the stated regret bounds without excessive exploration cost.
Figures

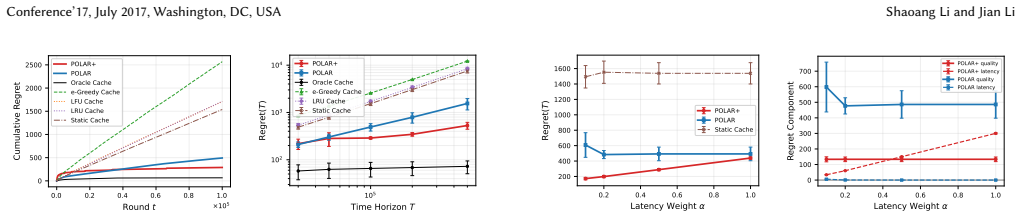

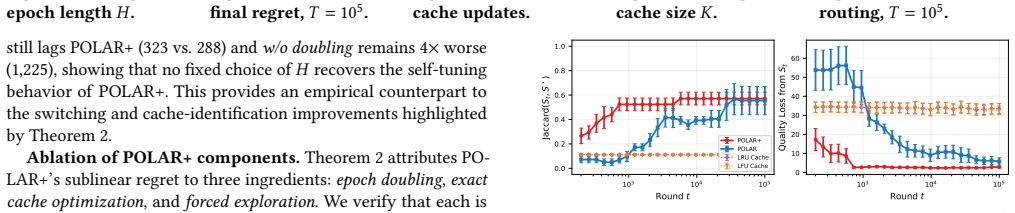
read the original abstract
Edge deployment of large language models (LLMs) increasingly relies on libraries of lightweight LoRA adapters, yet GPU/DRAM can keep only a small resident subset at a time. Serving a request through a non-resident adapter requires paging its weights from storage, incurring measurable latency. This creates a two-timescale online control problem: on a slow timescale, the system selects which adapters remain resident in fast memory, while on a fast timescale it routes each request to an adapter whose context-dependent utility is unknown a priori. The two decisions are tightly coupled: the cache determines the cost of exploration, and the router determines which adapters receive informative feedback. We formulate this joint caching-and-routing problem as a two-timescale contextual bandit and propose POLAR (Paging and Online Learning for Adapter Routing). POLAR pairs a cache-aware LinUCB router with an epoch-based cache controller. We study two variants. A fixed-epoch version provides a robust baseline with worst-case regret guarantees under arbitrary contexts. An epoch-doubling version, POLAR+, adds forced exploration and improved cache optimization to achieve $\widetilde{\mathcal{O}}(d\sqrt{NT}+\sqrt{KT})$ sublinear regret under stochastic regularity and cacheability conditions, where $N$ is the adapter count, $K$ the cache size, $d$ the context dimension, and $T$ the horizon. The routing term matches the standard contextual-bandit rate up to logarithmic factors, showing that the memory hierarchy does not fundamentally slow routing learning. Experiments using 15 real LoRA adapters for Qwen2.5-7B together with measured GPU paging latencies show that adaptive cache control substantially outperforms non-adaptive baselines and exhibits scaling trends consistent with the theory.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces POLAR for joint online caching and routing of LoRA adapters in edge LLM serving. It formulates the problem as a two-timescale contextual bandit, pairs a cache-aware LinUCB router with an epoch-based cache controller, and analyzes two variants: a fixed-epoch version with worst-case guarantees and POLAR+ with epoch-doubling that achieves sublinear regret of order ~O(d sqrt(NT) + sqrt(KT)) under stochastic regularity and cacheability conditions. Experiments with 15 real LoRA adapters on Qwen2.5-7B and measured GPU paging latencies show adaptive caching outperforming non-adaptive baselines.
Significance. If the regret analysis holds and the stochastic assumptions are realistic for LLM workloads, the work is significant for demonstrating that memory-hierarchy constraints need not degrade contextual-bandit routing rates beyond logarithmic factors. The explicit coupling of cache decisions to exploration cost and the use of measured paging latencies provide a concrete bridge between online learning theory and systems practice in multi-adapter edge serving.
major comments (2)
- [Abstract] Abstract: The sublinear regret claim for POLAR+ rests on 'stochastic regularity and cacheability conditions' that are load-bearing for the bound but are only named, not defined or justified, in the abstract. The main text must supply their precise mathematical statement (e.g., lower bounds on adapter utility gaps or context distribution regularity) together with a discussion of when they plausibly hold for real request traces; otherwise the practical scope of the O~(d sqrt(NT) + sqrt(KT)) result remains unclear.
- [Theory section (regret analysis)] The two-timescale analysis (presumably §4): while the abstract states that the routing term matches standard LinUCB rates up to logs, the interaction between the slow cache controller and the fast router must be shown not to introduce additional linear or super-logarithmic terms in the regret decomposition. A concrete walk-through of how the epoch-doubling schedule and forced exploration interact with the cache state is required to confirm the claimed separation.
minor comments (2)
- [Notation and preliminaries] Ensure that all symbols (N, K, d, T, and the precise definition of the utility function) are introduced with a single consistent notation block early in the paper rather than scattered across the abstract and later sections.
- [Experiments] The experimental claims would be strengthened by including a table or figure that reports both the observed latency overheads and the empirical regret curves side-by-side with the theoretical scaling predictions.
Circularity Check
No significant circularity; regret bounds extend standard LinUCB analysis independently.
full rationale
The paper formulates the joint caching-routing problem as a two-timescale contextual bandit and derives the POLAR+ regret bound of order O(d sqrt(NT) + sqrt(KT)) by extending the standard LinUCB analysis with epoch-doubling, forced exploration, and cache terms under explicit stochastic regularity and cacheability assumptions. The routing component matches known contextual-bandit rates up to logs, and the cache controller is analyzed separately without reducing the main result to fitted parameters or self-referential definitions. No load-bearing self-citations, ansatzes smuggled via prior work, or renamings of known results appear in the derivation chain; the analysis is self-contained against external benchmarks for contextual bandits.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Adapter utilities are stochastic with regularity conditions allowing sublinear regret for LinUCB-style algorithms
- domain assumption Cacheability conditions hold so that epoch-based updates can control paging costs without excessive regret
Reference graph
Works this paper leans on
-
[1]
Yasin Abbasi-Yadkori, Dávid Pál, and Csaba Szepesvári. 2011. Improved Algo- rithms for Linear Stochastic Bandits. InAdvances in Neural Information Processing Systems 24. 2312–2320
2011
-
[2]
Shipra Agrawal and Navin Goyal. 2013. Thompson Sampling for Contextual Bandits with Linear Payoffs. InProceedings of the 30th International Conference on Machine Learning. 127–135
2013
-
[3]
2005.Online computation and competitive analysis
Allan Borodin and Ran El-Yaniv. 2005.Online computation and competitive analysis. cambridge university press
2005
-
[4]
Lequn Chen, Zihao Ye, Yongji Wu, Danyang Zhuo, Luis Ceze, and Arvind Kr- ishnamurthy. 2024. Punica: Multi-Tenant LoRA Serving. InProceedings of the Seventh Annual Conference on Machine Learning and Systems
2024
-
[5]
Schapire
Wei Chu, Lihong Li, Lev Reyzin, and Robert E. Schapire. 2011. Contextual Bandits with Linear Payoff Functions. InProceedings of the 14th International Conference on Artificial Intelligence and Statistics (AISTATS). 208–214
2011
-
[6]
Weibo Chu, Xiaoyan Zhang, Xinming Jia, John CS Lui, and Zhiyong Wang
-
[7]
Online optimal service caching for multi-access edge computing: A con- strained multi-armed bandit optimization approach.Computer Networks246 (2024), 110395
2024
-
[8]
Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. LoRA: Low-Rank Adaptation of Large Language Models. InInternational Conference on Learning Representations
2022
-
[9]
Shaoang Li and Jian Li. 2026. Near-Optimal Online Deployment and Routing for Streaming LLMs. InThe Fourteenth International Conference on Learning Representations
2026
- [10]
- [11]
-
[12]
Lui, Wei Chen, and Carlee Joe-Wong
Xutong Liu, Baran Atalar, XiangXiang Dai, Jinhang Zuo, Siwei Wang, John C.S. Lui, Wei Chen, and Carlee Joe-Wong. 2026. Semantic Caching for Low-Cost LLM Serving: From Offline Learning to Online Adaptation. InIEEE International Conference on Computer Communications (INFOCOM)
2026
-
[13]
Yinan Ni, Xiao Yang, Yuqi Tang, Zhimin Qiu, Chen Wang, and Tingzhou Yuan
-
[14]
InProceedings of the 6th International Conference on Computer Science and Management Technology
Predictive-LoRA: A proactive and fragmentation-aware serverless inference system for LLMs. InProceedings of the 6th International Conference on Computer Science and Management Technology. 1267–1273
-
[15]
Georgios S Paschos, Apostolos Destounis, and George Iosifidis. 2020. Online convex optimization for caching networks.IEEE/ACM Transactions on Networking 28, 2 (2020), 625–638
2020
-
[16]
Manhin Poon, XiangXiang Dai, Xutong Liu, Fang Kong, John CS Lui, and Jinhang Zuo. 2026. Online multi-llm selection via contextual bandits under unstructured context evolution. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 24855–24863
2026
-
[17]
Guocong Quan, Atilla Eryilmaz, and Ness B Shroff. 2024. Minimizing edge caching service costs through regret-optimal online learning.IEEE/ACM Transactions on Networking32, 5 (2024), 4349–4364
2024
-
[18]
Zheyu Shen, Yexiao He, Ziyao Wang, Yuning Zhang, Guoheng Sun, Wanghao Ye, and Ang Li. 2025. EdgeLoRA: An Efficient Multi-Tenant LLM Serving System on Edge Devices. InProceedings of the 23rd Annual International Conference on Mobile Systems, Applications and Services. 138–153
2025
- [19]
-
[20]
Daniel D Sleator and Robert E Tarjan. 1985. Amortized efficiency of list update and paging rules.Commun. ACM28, 2 (1985), 202–208
1985
- [21]
-
[22]
Chunlin Tian, Xinpeng Qin, Kahou Tam, Li Li, Zijian Wang, Yuanzhe Zhao, Minglei Zhang, and Chengzhong Xu. 2025. CLONE: Customizing LLMs for Efficient Latency-Aware Inference at the Edge. In2025 USENIX Annual Technical Conference. 563–585
2025
-
[23]
Joel A Tropp. 2012. User-friendly tail bounds for sums of random matrices. Foundations of computational mathematics12, 4 (2012), 389–434
2012
- [24]
-
[25]
Bingyang Wu, Ruidong Zhu, Zili Zhang, Peng Sun, Xuanzhe Liu, and Xin Jin. 2024. dLoRA: Dynamically orchestrating requests and adapters for LoRALLM serving. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI). 911–927
2024
-
[26]
Minrui Xu, Dusit Niyato, and Christopher G Brinton. 2026. Serving long-context LLMs at the mobile edge: Test-time reinforcement learning-based model caching and inference offloading.IEEE Transactions on Networking(2026)
2026
-
[27]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tingyu X...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Hang Zhang, Jiuchen Shi, Yixiao Wang, Quan Chen, Yizhou Shan, and Minyi Guo
- [29]
- [30]
-
[31]
Banghua Zhu, Ying Sheng, Lianmin Zheng, Clark Barrett, Michael Jordan, and Jiantao Jiao. 2023. Towards Optimal Caching and Model Selection for Large Model Inference. InThirty-seventh Conference on Neural Information Processing Systems. 10 POLAR: Online Learning for LoRA Adapter Caching and Routing in Edge LLM Serving Conference’17, July 2017, Washington, ...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.