Recognition: unknown
Revisiting a Pain in the Neck: A Semantic Reasoning Benchmark for Language Models
Pith reviewed 2026-05-10 08:50 UTC · model grok-4.3
The pith
SemanticQA is a unified benchmark that reveals substantial performance gaps in language models on semantic reasoning tasks involving multiword expressions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Through SemanticQA, we assess LMs of diverse architectures and scales in extraction, classification, and interpretation tasks, as well as sequential task compositions. We reveal substantial performance variation, particularly on tasks requiring semantic reasoning.
Load-bearing premise
That reorganizing existing multiword expression resources into unified tasks accurately measures semantic reasoning without introducing selection or annotation biases from the source datasets.
Figures





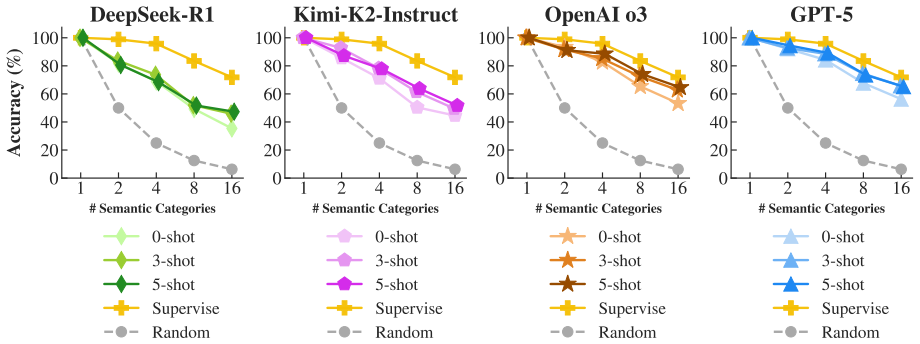










read the original abstract
We present SemanticQA, an evaluation suite designed to assess language models (LMs) in semantic phrase processing tasks. The benchmark consolidates existing multiword expression (MwE) resources and reorganizes them into a unified testbed. It covers both general lexical phenomena, such as lexical collocations, and three fine-grained categories: idiomatic expressions, noun compounds, and verbal constructions. Through SemanticQA, we assess LMs of diverse architectures and scales in extraction, classification, and interpretation tasks, as well as sequential task compositions. We reveal substantial performance variation, particularly on tasks requiring semantic reasoning, highlighting differences in reasoning efficacy and semantic understanding of LMs, providing insights for pushing LMs with stronger comprehension on non-trivial semantic phrases. The evaluation harness and data of SemanticQA are available at https://github.com/jacklanda/SemanticQA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SemanticQA, a benchmark that consolidates and reorganizes existing multiword expression (MWE) resources into a unified suite of tasks covering extraction, classification, interpretation, and sequential task compositions. It evaluates language models of varying architectures and scales on these tasks, claiming to reveal substantial performance variation—particularly on those requiring semantic reasoning—and provides public access to the evaluation harness and data.
Significance. If the benchmark construction successfully isolates semantic reasoning differences without inheriting source-dataset artifacts, SemanticQA could offer a valuable standardized testbed for diagnosing LM limitations on non-compositional phrases and guiding improvements in semantic comprehension. The public release of code and data supports reproducibility and is a clear strength.
major comments (2)
- [Benchmark construction] Benchmark construction (likely §3): The reorganization of prior MWE corpora (idioms, noun compounds, verbal constructions, collocations) into unified extraction/classification/interpretation tasks provides no description of new validation steps, adversarial controls, inter-annotator agreement checks, or bias audits on the reorganized splits. This leaves open the possibility that observed performance variation reflects source-specific annotation guidelines, frequency imbalances, or domain skews rather than differences in semantic reasoning efficacy.
- [Results and evaluation] Results and evaluation sections: The abstract asserts 'substantial performance variation' and 'differences in reasoning efficacy' but supplies no quantitative metrics, error analysis, per-task breakdowns, or statistical significance tests. Without these details, it is impossible to assess whether the variation is large enough, consistent across models, or genuinely attributable to semantic reasoning rather than task formulation artifacts.
minor comments (2)
- [Data availability] The GitHub repository link is provided, but the paper should explicitly document the exact train/dev/test splits, licensing of source resources, and any preprocessing steps applied during reorganization.
- [Task definitions] Notation for task compositions (e.g., sequential pipelines) could be clarified with a small diagram or pseudocode to improve readability for readers unfamiliar with MWE literature.
Circularity Check
No circularity: empirical benchmark relies on external resources without internal derivations or self-referential fitting
full rationale
The paper constructs SemanticQA by consolidating and reorganizing existing multiword expression resources into unified tasks for extraction, classification, interpretation, and composition. No equations, fitted parameters, predictions, or uniqueness theorems appear in the provided text or abstract. All load-bearing elements rest on external corpora and observed LM performance differences rather than any reduction to the paper's own inputs by construction. This is a standard empirical benchmark setup with no self-citation chains or ansatz smuggling that would trigger circularity under the defined criteria.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existing multiword expression resources can be reorganized into a unified testbed that preserves their original semantic properties.
Reference graph
Works this paper leans on
-
[1]
Lisa Alazraki, Lihu Chen, Ana Brassard, Joe Stacey, Hossein A. Rahmani, and Marek Rei. 2025. https://arxiv.org/abs/2508.19988 Agentcoma: A compositional benchmark mixing commonsense and mathematical reasoning in real-world scenarios . Preprint, arXiv:2508.19988
-
[2]
Shengnan An, Xunliang Cai, Xuezhi Cao, Xiaoyu Li, Yehao Lin, Junlin Liu, Xinxuan Lv, Dan Ma, Xuanlin Wang, Ziwen Wang, and Shuang Zhou. 2025. https://arxiv.org/abs/2510.26768 Amo-bench: Large language models still struggle in high school math competitions . Preprint, arXiv:2510.26768
-
[3]
Anthropic. 2024. https://www-cdn.anthropic.com/de8ba9b01c9ab7cbabf5c33b80b7bbc618857627/Model_Card_Claude_3.pdf The claude 3 model family: Opus, sonnet, haiku . In Anthropic Blog
2024
-
[4]
Anthropic. 2025. Anthropic. https://www.anthropic.com/news/claude-sonnet-4-5. September 30, 2025
2025
-
[5]
Yuki Arase and Jun ' ichi Tsujii. 2020. https://doi.org/10.18653/v1/2020.emnlp-main.125 Compositional phrase alignment and beyond . In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1611--1623, Online. Association for Computational Linguistics
-
[6]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie J. Cai, Michael Terry, Quoc V. Le, and Charles Sutton. 2021. https://api.semanticscholar.org/CorpusID:237142385 Program synthesis with large language models . ArXiv, abs/2108.07732
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
Mislav Balunović, Jasper Dekoninck, Ivo Petrov, Nikola Jovanović, and Martin Vechev. 2025. https://matharena.ai/ Matharena: Evaluating llms on uncontaminated math competitions
2025
-
[8]
Ekaba Bisong. 2019. Google colaboratory. Building machine learning and deep learning models on google cloud platform: a comprehensive guide for beginners, pages 59--64
2019
-
[9]
Lars Buijtelaar and Sandro Pezzelle. 2023. https://doi.org/10.18653/v1/2023.eacl-main.163 A psycholinguistic analysis of BERT ' s representations of compounds . In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 2230--2241, Dubrovnik, Croatia. Association for Computational Linguistics
-
[10]
Tuhin Chakrabarty, Yejin Choi, and Vered Shwartz. 2022 a . https://doi.org/10.1162/tacl_a_00478 It ' s not rocket science: Interpreting figurative language in narratives . Transactions of the Association for Computational Linguistics, 10:589--606
-
[11]
Tuhin Chakrabarty, Yejin Choi, and Vered Shwartz. 2022 b . It’s not rocket science: Interpreting figurative language in narratives. Transactions of the Association for Computational Linguistics, 10:589--606
2022
-
[12]
I-Hsuan Chen, Yunfei Long, Qin Lu, and Chu-Ren Huang. 2017. https://doi.org/10.18653/v1/K17-1006 Leveraging eventive information for better metaphor detection and classification . In Proceedings of the 21st Conference on Computational Natural Language Learning ( C o NLL 2017) , pages 36--46, Vancouver, Canada. Association for Computational Linguistics
-
[13]
Albert Coil and Vered Shwartz. 2023. https://doi.org/10.18653/v1/2023.findings-acl.169 From chocolate bunny to chocolate crocodile: Do language models understand noun compounds? In Findings of the Association for Computational Linguistics: ACL 2023, pages 2698--2710, Toronto, Canada. Association for Computational Linguistics
-
[14]
Mathieu Constant, G \"u l s en Eryi g it, Johanna Monti, Lonneke Van Der Plas, Carlos Ramisch, Michael Rosner, and Amalia Todirascu. 2017 a . Multiword expression processing: A survey. Computational Linguistics, 43(4):837--892
2017
-
[15]
Mathieu Constant, G \"u l s en Eryi g it, Johanna Monti, Lonneke van der Plas, Carlos Ramisch, Michael Rosner, and Amalia Todirascu. 2017 b . https://doi.org/10.1162/COLI_a_00302 S urvey: Multiword expression processing: A S urvey . Computational Linguistics, 43(4):837--892
-
[16]
DeepSeek. 2025. https://doi.org/10.1038/s41586-025-09422-z Deepseek-r1 incentivizes reasoning in llms through reinforcement learning . Nature, 645:633--638
-
[17]
Michael Denkowski and Alon Lavie. 2014. https://doi.org/10.3115/v1/W14-3348 Meteor universal: Language specific translation evaluation for any target language . In Proceedings of the Ninth Workshop on Statistical Machine Translation, pages 376--380, Baltimore, Maryland, USA. Association for Computational Linguistics
-
[18]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171--4186
2019
-
[19]
Luis Espinosa-Anke, Joan Codina-Filba, and Leo Wanner. 2021. https://doi.org/10.18653/v1/2021.eacl-main.120 Evaluating language models for the retrieval and categorization of lexical collocations . In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pages 1406--1417, Online. Associat...
-
[20]
Luis Espinosa-Anke, Steven Schockaert, and Leo Wanner. 2019. https://doi.org/10.18653/v1/P19-1576 Collocation classification with unsupervised relation vectors . In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 5765--5772, Florence, Italy. Association for Computational Linguistics
-
[21]
Luis Espinosa-Anke, Alexander Shvets, Alireza Mohammadshahi, James Henderson, and Leo Wanner. 2022. https://doi.org/10.18653/v1/2022.starsem-1.8 Multilingual extraction and categorization of lexical collocations with graph-aware transformers . In Proceedings of the 11th Joint Conference on Lexical and Computational Semantics, pages 89--100, Seattle, Washi...
-
[22]
Afsaneh Fazly, Paul Cook, and Suzanne Stevenson. 2009. Unsupervised type and token identification of idiomatic expressions. Computational Linguistics, 35(1):61--103
2009
-
[23]
Beatriz Fisas, Luis Espinosa-Anke, Joan Codina-Filb \'a , and Leo Wanner. 2020. https://aclanthology.org/2020.mwe-1.1 C oll F r E n: Rich bilingual E nglish -- F rench collocation resource . In Proceedings of the Joint Workshop on Multiword Expressions and Electronic Lexicons, pages 1--12, online. Association for Computational Linguistics
2020
-
[24]
Thierry Fontenelle. 1997. Turning a bilingual dictionary into a lexical-semantic database. De Gruyter
1997
-
[25]
Marcos Garcia, Tiago Kramer Vieira, Carolina Scarton, Marco Idiart, and Aline Villavicencio. 2021. https://doi.org/10.18653/v1/2021.acl-long.212 Assessing the representations of idiomaticity in vector models with a noun compound dataset labeled at type and token levels . In Proceedings of the 59th Annual Meeting of the Association for Computational Lingui...
-
[26]
Alexander Gelbukh and 1 others. 2012. Semantic analysis of verbal collocations with lexical functions, volume 414. Springer
2012
-
[27]
Gemma . 2025. https://goo.gle/Gemma3Report Gemma 3
2025
-
[28]
Google. 2025. Google. https://blog.google/technology/google-deepmind/gemini-model-thinking-updates-march-2025. Mar 25, 2025
2025
-
[29]
Tayyar Madabushi Harish, Gow-Smith Edward, Scarton Carolina, and Villavicencio Aline. 2021. https://doi.org/10.18653/v1/2021.findings-emnlp.294 AS titch I n L anguage M odels: Dataset and methods for the exploration of idiomaticity in pre-trained language models . In Findings of the Association for Computational Linguistics: EMNLP 2021, pages 3464--3477, ...
-
[30]
Adi Haviv, Ido Cohen, Jacob Gidron, Roei Schuster, Yoav Goldberg, and Mor Geva. 2023. https://doi.org/10.18653/v1/2023.eacl-main.19 Understanding transformer memorization recall through idioms . In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 248--264, Dubrovnik, Croatia. Association fo...
-
[31]
Iris Hendrickx, Zornitsa Kozareva, Preslav Nakov, Diarmuid \'O S \'e aghdha, Stan Szpakowicz, and Tony Veale. 2013. https://aclanthology.org/S13-2025 S em E val-2013 task 4: Free paraphrases of noun compounds . In Second Joint Conference on Lexical and Computational Semantics (* SEM ), Volume 2: Proceedings of the Seventh International Workshop on Semanti...
2013
-
[32]
Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. 2019. The curious case of neural text degeneration. In International Conference on Learning Representations
2019
-
[33]
Xuming Hu, Junzhe Chen, Xiaochuan Li, Yufei Guo, Lijie Wen, Philip Yu, and Zhijiang Guo. 2024. https://proceedings.iclr.cc/paper_files/paper/2024/file/7b7d7985f62284060d65f532ed2ea5fa-Paper-Conference.pdf Towards understanding factual knowledge of large language models . In International Conference on Representation Learning, volume 2024, pages 28680--28715
2024
-
[34]
Sirui Huang, Yanggan Gu, Zhonghao Li, Xuming Hu, Li Qing, and Guandong Xu. 2025. https://doi.org/10.18653/v1/2025.findings-acl.391 S truct F act: Reasoning factual knowledge from structured data with large language models . In Findings of the Association for Computational Linguistics: ACL 2025, pages 7521--7552, Vienna, Austria. Association for Computatio...
-
[35]
Kimi . 2025. https://arxiv.org/abs/2507.20534 Kimi k2: Open agentic intelligence . Preprint, arXiv:2507.20534
work page internal anchor Pith review arXiv 2025
-
[36]
Filip Klubi c ka, Vasudevan Nedumpozhimana, and John Kelleher. 2023. https://doi.org/10.18653/v1/2023.mwe-1.8 Idioms, probing and dangerous things: Towards structural probing for idiomaticity in vector space . In Proceedings of the 19th Workshop on Multiword Expressions (MWE 2023), pages 45--57, Dubrovnik, Croatia. Association for Computational Linguistics
-
[37]
Olga Kolesnikova. 2020. Automatic detection of lexical functions in context. Computaci \'o n y sistemas , 24(3):1337--1352
2020
-
[38]
Keshav Kolluru, Gabriel Stanovsky, and Mausam . 2022. https://doi.org/10.18653/v1/2022.emnlp-main.711 `` covid vaccine is against covid but O xford vaccine is made at O xford! '' semantic interpretation of proper noun compounds . In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 10407--10420, Abu Dhabi, Unite...
-
[39]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient memory management for large language model serving with pagedattention. In Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles
2023
-
[40]
Jia Li, Ge Li, Xuanming Zhang, Yunfei Zhao, Yihong Dong, Zhi Jin, Binhua Li, Fei Huang, and Yongbin Li. 2024. https://doi.org/10.52202/079017-1837 Evocodebench: An evolving code generation benchmark with domain-specific evaluations . In Advances in Neural Information Processing Systems, volume 37, pages 57619--57641. Curran Associates, Inc
-
[41]
Jiaqi Li, Xinyi Dong, Yang Liu, Zhizhuo Yang, Quansen Wang, Xiaobo Wang, Song-Chun Zhu, Zixia Jia, and Zilong Zheng. 2025. https://doi.org/10.18653/v1/2025.findings-acl.871 R eflect E vo: Improving meta introspection of small LLM s by learning self-reflection . In Findings of the Association for Computational Linguistics: ACL 2025, pages 16948--16966, Vie...
-
[42]
Chin-Yew Lin. 2004. https://aclanthology.org/W04-1013 ROUGE : A package for automatic evaluation of summaries . In Text Summarization Branches Out, pages 74--81, Barcelona, Spain. Association for Computational Linguistics
2004
-
[43]
Hongwei Liu, Zilong Zheng, Yuxuan Qiao, Haodong Duan, Zhiwei Fei, Fengzhe Zhou, Wenwei Zhang, Songyang Zhang, Dahua Lin, and Kai Chen. 2024. https://arxiv.org/abs/2405.12209 Mathbench: Evaluating the theory and application proficiency of llms with a hierarchical mathematics benchmark . Preprint, arXiv:2405.12209
-
[44]
Yang Liu, Jiaqi Li, and Zilong Zheng. 2026 a . https://openreview.net/forum?id=MQV4TJyqnb Rulereasoner: Reinforced rule-based reasoning via domain-aware dynamic sampling . In The Fourteenth International Conference on Learning Representations
2026
-
[45]
Yang Liu, Jiaye Yang, Weikang Li, Jiahui Liang, Yang Li, and Lingyong Yan. 2026 b . https://doi.org/10.18653/v1/2026.eacl-long.1 LM -lexicon: Improving definition modeling via harmonizing semantic experts . In Proceedings of the 19th Conference of the E uropean Chapter of the A ssociation for C omputational L inguistics (Volume 1: Long Papers) , pages 1--...
-
[46]
Thang Luong, Dawsen Hwang, Hoang H Nguyen, Golnaz Ghiasi, Yuri Chervonyi, Insuk Seo, Junsu Kim, Garrett Bingham, Jonathan Lee, Swaroop Mishra, Alex Zhai, Huiyi Hu, Henryk Michalewski, Jimin Kim, Jeonghyun Ahn, Junhwi Bae, Xingyou Song, Trieu Hoang Trinh, Quoc V Le, and Junehyuk Jung. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.1794 Towards robust ma...
-
[47]
Mel' c uk
Igor A. Mel' c uk. 1998. Collocations and lexical functions. Phraseology. Theory, analysis, and applications, pages 23--53
1998
-
[48]
Mel' c uk
Igor A. Mel' c uk. 2023. General phraseology: Theory and practice. John Benjamins
2023
-
[49]
Filip Mileti \'c and Sabine Schulte im Walde. 2024. https://doi.org/10.1162/tacl_a_00657 Semantics of multiword expressions in transformer-based models: A survey . Transactions of the Association for Computational Linguistics, 12:593--612
-
[50]
Sag, and Thomas Wasow
Geoffrey Nunberg, Ivan A. Sag, and Thomas Wasow. 1994. http://www.jstor.org/stable/416483 Idioms . Language, 70(3):491--538
1994
-
[51]
OpenAI. 2023. https://arxiv.org/abs/2303.08774 Gpt-4 technical report . https://arxiv.org/pdf/2303.08774.pdf. Preprint, arXiv:2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[52]
OpenAI. 2025 a . Openai. https://openai.com/index/introducing-gpt-5. Accessed: August 7, 2025
2025
-
[53]
OpenAI. 2025 b . Openai. https://openai.com/index/introducing-o3-and-o4-mini. April 16, 2025
2025
-
[54]
Caroline Pasquer, Agata Savary, Carlos Ramisch, and Jean-Yves Antoine. 2020. https://doi.org/10.18653/v1/2020.coling-main.296 Verbal multiword expression identification: Do we need a sledgehammer to crack a nut? In Proceedings of the 28th International Conference on Computational Linguistics, pages 3333--3345, Barcelona, Spain (Online). International Comm...
-
[55]
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, and 1 others. 2019. Pytorch: An imperative style, high-performance deep learning library. Advances in neural information processing systems, 32
2019
-
[56]
Thang Pham, Seunghyun Yoon, Trung Bui, and Anh Nguyen. 2023. https://doi.org/10.18653/v1/2023.eacl-main.1 P i C : A phrase-in-context dataset for phrase understanding and semantic search . In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 1--26, Dubrovnik, Croatia. Association for Computa...
-
[57]
Qwen . 2025. https://arxiv.org/abs/2505.09388 Qwen3 technical report . Preprint, arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, and 1 others. 2019. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9
2019
-
[59]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. The Journal of Machine Learning Research, 21(1):5485--5551
2020
-
[60]
Parikshit Ram, Tim Klinger, and Alexander G. Gray. 2024. https://doi.org/10.24963/ijcai.2024/533 What makes models compositional? a theoretical view . In Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, IJCAI '24
-
[61]
Carlos Ramisch. 2023. https://theses.hal.science/tel-04216223 Multiword expressions in computational linguistics . Habilitation \`a diriger des recherches, Aix Marseille Universit \'e (AMU)
2023
-
[62]
Carlos Ramisch, Agata Savary, Bruno Guillaume, Jakub Waszczuk, Marie Candito, Ashwini Vaidya, Verginica Barbu Mititelu, Archna Bhatia, Uxoa I \ n urrieta, Voula Giouli, Tunga G \"u ng \"o r, Menghan Jiang, Timm Lichte, Chaya Liebeskind, Johanna Monti, Renata Ramisch, Sara Stymne, Abigail Walsh, and Hongzhi Xu. 2020. https://aclanthology.org/2020.mwe-1.14 ...
2020
-
[63]
Carlos Ramisch, Abigail Walsh, Thomas Blanchard, and Shiva Taslimipoor. 2023 a . A survey of mwe identification experiments: The devil is in the details. In Proceedings of the 19th Workshop on Multiword Expressions (MWE 2023), pages 106--120
2023
-
[64]
Carlos Ramisch, Abigail Walsh, Thomas Blanchard, and Shiva Taslimipoor. 2023 b . https://doi.org/10.18653/v1/2023.mwe-1.15 A survey of MWE identification experiments: The devil is in the details . In Proceedings of the 19th Workshop on Multiword Expressions (MWE 2023), pages 106--120, Dubrovnik, Croatia. Association for Computational Linguistics
-
[65]
Mar \' a A Barrios Rodr \' guez. 2003. The domain of the lexical functions fact0, causfact0 and real1. learning, page 64
2003
-
[66]
Ivan A Sag, Timothy Baldwin, Francis Bond, Ann Copestake, and Dan Flickinger. 2002 a . Multiword expressions: A pain in the neck for nlp. In Computational Linguistics and Intelligent Text Processing: Third International Conference, CICLing 2002 Mexico City, Mexico, February 17--23, 2002 Proceedings 3, pages 1--15. Springer
2002
-
[67]
Sag, Timothy Baldwin, Francis Bond, Ann Copestake, and Dan Flickinger
Ivan A. Sag, Timothy Baldwin, Francis Bond, Ann Copestake, and Dan Flickinger. 2002 b . Multiword expressions: A pain in the neck for nlp. In Computational Linguistics and Intelligent Text Processing, pages 1--15, Berlin, Heidelberg. Springer Berlin Heidelberg
2002
-
[68]
Manfred Sailer and Stella Markantonatou. 2018. Multiword expressions: Insights from a multi-lingual perspective. Language Science Press
2018
-
[69]
Paul-Edouard Sarlin, Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. 2020. Superglue: Learning feature matching with graph neural networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4938--4947
2020
-
[70]
Agata Savary, Cherifa Ben Khelil, Carlos Ramisch, Voula Giouli, Verginica Barbu Mititelu, Najet Hadj Mohamed, Cvetana Krstev, Chaya Liebeskind, Hongzhi Xu, Sara Stymne, Tunga G \"u ng \"o r, Thomas Pickard, Bruno Guillaume, Eduard Bej c ek, Archna Bhatia, Marie Candito, Polona Gantar, Uxoa I \ n urrieta, Albert Gatt, and 9 others. 2023. https://doi.org/10...
-
[71]
Agata Savary, Carlos Ramisch, Silvio Cordeiro, Federico Sangati, Veronika Vincze, Behrang QasemiZadeh, Marie Candito, Fabienne Cap, Voula Giouli, Ivelina Stoyanova, and Antoine Doucet. 2017. https://doi.org/10.18653/v1/W17-1704 The PARSEME shared task on automatic identification of verbal multiword expressions . In Proceedings of the 13th Workshop on Mult...
-
[72]
Alexander Shvets and Leo Wanner. 2022. https://doi.org/10.3390/math10203831 The relation dimension in the identification and classification of lexically restricted word co-occurrences in text corpora . Mathematics, 10(20)
-
[73]
Vered Shwartz and Ido Dagan. 2019. https://doi.org/10.1162/tacl_a_00277 Still a pain in the neck: Evaluating text representations on lexical composition . Transactions of the Association for Computational Linguistics, 7:403--419
-
[74]
Giorgos Spathas and Dimitris Michelioudakis. 2021. https://doi.org/10.1007/s11049-020-09496-6 States in the decomposition of verbal predicates . Natural Language & Linguistic Theory, 39(4):1253--1306
-
[75]
Joshua Tanner and Jacob Hoffman. 2023. https://doi.org/10.18653/v1/2023.findings-emnlp.14 MWE as WSD : Solving multiword expression identification with word sense disambiguation . In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 181--193, Singapore. Association for Computational Linguistics
-
[76]
Simone Tedeschi, Federico Martelli, and Roberto Navigli. 2022. https://doi.org/10.18653/v1/2022.findings-naacl.208 ID 10 M : Idiom identification in 10 languages . In Findings of the Association for Computational Linguistics: NAACL 2022, pages 2715--2726, Seattle, United States. Association for Computational Linguistics
-
[77]
Stephen Tratz and Eduard Hovy. 2010. https://aclanthology.org/P10-1070/ A taxonomy, dataset, and classifier for automatic noun compound interpretation . In Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics, pages 678--687, Uppsala, Sweden. Association for Computational Linguistics
2010
-
[78]
Valenzuela-Esc \'a rcega, Rebecca Sharp, and Mihai Surdeanu
Robert Vacareanu, Marco A. Valenzuela-Esc \'a rcega, Rebecca Sharp, and Mihai Surdeanu. 2020. https://doi.org/10.18653/v1/2020.coling-main.297 An unsupervised method for learning representations of multi-word expressions for semantic classification . In Proceedings of the 28th International Conference on Computational Linguistics, pages 3346--3356, Barcel...
-
[79]
Takashi Wada, Yuji Matsumoto, Timothy Baldwin, and Jey Han Lau. 2023. https://doi.org/10.18653/v1/2023.findings-acl.290 Unsupervised paraphrasing of multiword expressions . In Findings of the Association for Computational Linguistics: ACL 2023, pages 4732--4746, Toronto, Canada. Association for Computational Linguistics
-
[80]
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, and 3 others. 2020. https://doi.org/10.18653/v1/2020.emnlp-demos.6 Transformers: Sta...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.