Recognition: unknown
SafeLM: Unified Privacy-Aware Optimization for Trustworthy Federated Large Language Models
Pith reviewed 2026-05-10 08:02 UTC · model grok-4.3
The pith
SafeLM unifies privacy encryption, attack defenses, hallucination reduction, and robust aggregation for federated large language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
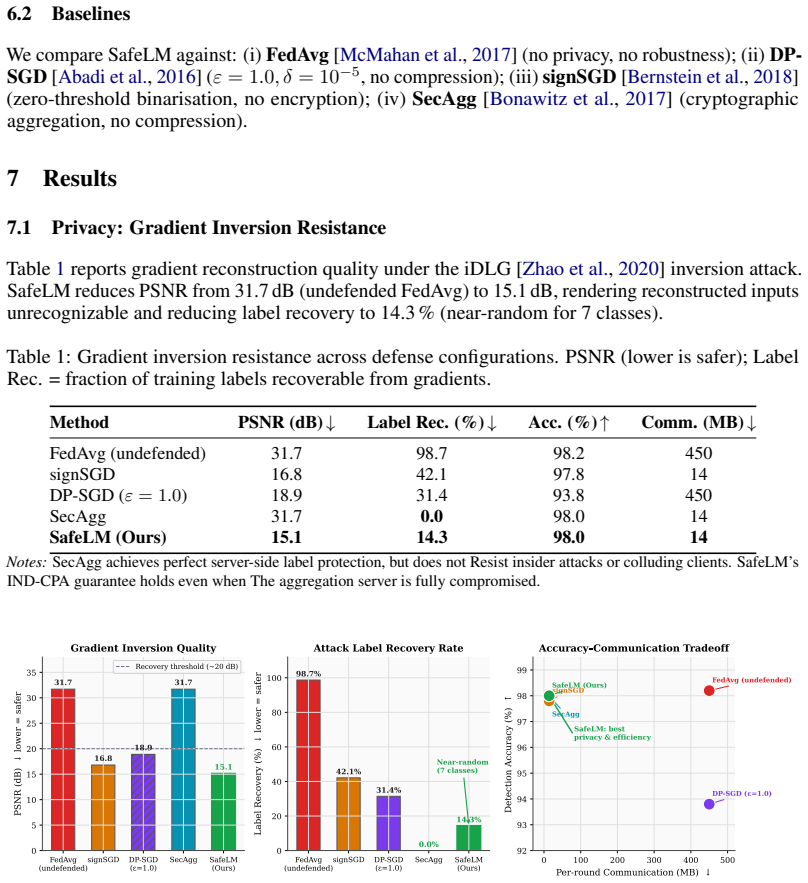
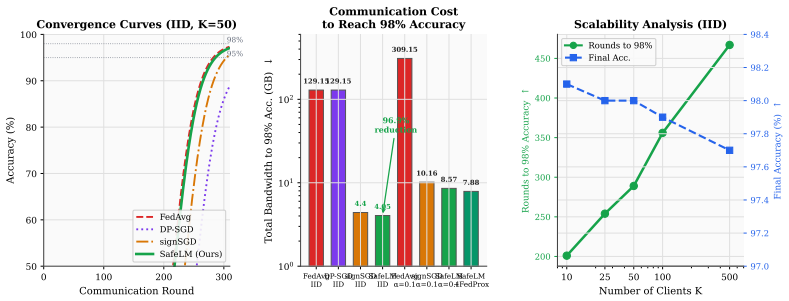
SafeLM achieves 98.0 percent harmful content detection accuracy, reduces communication by 96.9 percent, and lowers gradient inversion PSNR from 31.7 dB to 15.1 dB by integrating federated training with gradient smartification and Paillier encryption for privacy, security defenses against training and inference attacks, contrastive grounding with calibrated decoding to reduce hallucinations, and alignment-aware binarized aggregation to enhance robustness while maintaining bounded reconstruction quality.
What carries the argument
The SafeLM framework, which jointly applies gradient smartification and Paillier encryption for privacy, attack defenses, contrastive grounding with calibrated decoding for factuality, and alignment-aware binarized aggregation for robustness.
If this is right
- Federated LLM training can maintain high factuality and low toxicity while sharply limiting membership-inference and gradient-inversion success.
- Communication cost for distributed training drops by nearly 97 percent without collapsing model utility.
- Bounded reconstruction quality under binarized aggregation allows robustness gains without exposing original gradients.
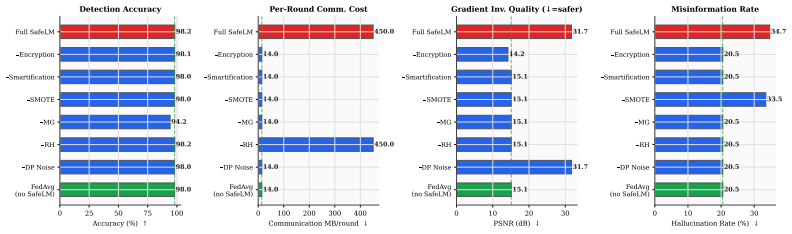
- Ablation results indicate that privacy, security, factuality, and robustness improvements do not trade off against one another in the reported setting.
Where Pith is reading between the lines
- The same four-pillar structure could be tested on non-LLM models such as vision or graph networks to check whether the efficiency gains generalize.
- If the contrastive grounding module scales to larger models, it might reduce the need for separate post-training alignment steps.
- The measured drop in gradient-inversion PSNR suggests a concrete privacy metric that future federated systems could adopt as a standard reporting requirement.
Load-bearing premise
The four pillars integrate without major hidden performance costs and each component contributes independently as shown in the ablations.
What would settle it
Re-running the reported benchmarks after removing any one pillar and observing whether harmful-content detection accuracy falls below 90 percent or communication volume rises above 20 percent of the baseline.
Figures


read the original abstract
Large language models (LLMs) are increasingly deployed in high-stakes domains, yet a unified treatment of their overlapping safety challenges remains lacking. We present SafeLM, a framework that jointly addresses four pillars of LLM safety: privacy, security, misinformation, and adversarial robustness. SafeLM combines federated training with gradient smartification and Paillier encryption for privacy, integrates defenses against training and inference-time attacks, employs contrastive grounding with calibrated decoding to reduce hallucinations, and introduces alignment-aware binarized aggregation to enhance robustness while maintaining bounded reconstruction quality. Across benchmarks on factuality, toxicity, and membership inference, SafeLM achieves 98.0% harmful content detection accuracy, reduces communication by 96.9%, and lowers gradient inversion PSNR from 31.7 dB to 15.1 dB. Ablations show that each component contributes independently, whereas their integration yields a strong privacy utility efficiency trade-off for deploying trustworthy LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents SafeLM, a framework for unified privacy-aware optimization in federated large language models. It addresses four pillars: privacy through federated training with gradient smartification and Paillier encryption, security via defenses against training and inference attacks, misinformation reduction using contrastive grounding and calibrated decoding, and adversarial robustness with alignment-aware binarized aggregation. The paper reports empirical results across benchmarks showing 98.0% harmful content detection accuracy, 96.9% communication reduction, and a reduction in gradient inversion PSNR from 31.7 dB to 15.1 dB, asserting that ablations confirm independent contributions from each component and a strong privacy-utility-efficiency trade-off.
Significance. If the results are rigorously validated with full experimental details, SafeLM could represent a significant contribution to trustworthy federated learning by offering an integrated solution to privacy, security, misinformation, and robustness challenges in LLMs. The claimed communication efficiency gains and privacy leakage reductions would be notable for practical large-scale deployments. The combination of cryptographic primitives with model compression and alignment techniques is a promising direction, but the current lack of methodological transparency limits assessment of its true impact.
major comments (3)
- Abstract: The abstract states specific quantitative results (98.0% harmful content detection accuracy, 96.9% communication reduction, PSNR reduction from 31.7 dB to 15.1 dB) without any description of the experimental setup, including LLM model sizes or architectures, datasets used, number of federated clients, data distribution, training hyperparameters, or baseline comparisons. This omission is load-bearing for the central empirical claims and prevents verification or reproduction.
- Abstract: The assertion that 'ablations show that each component contributes independently' is presented without any supporting data, tables, figures, or quantitative metrics (e.g., performance deltas when ablating individual pillars). Detailed ablation results with controls for interactions between Paillier encryption, binarized aggregation, and contrastive grounding are required to substantiate the independence claim.
- Abstract: No equations, complexity analysis, or feasibility discussion is provided for applying Paillier encryption to high-dimensional LLM gradients or for the 'smartification' and 'alignment-aware binarized aggregation' mechanisms. This is critical because the integration of encryption with binarization could introduce unmeasured overhead or utility loss at LLM scale, directly affecting the reported privacy-utility trade-off.
minor comments (2)
- Abstract: The term 'gradient smartification' is used without a concise definition or pointer to its precise mechanism, which reduces clarity for readers unfamiliar with the specific technique.
- Abstract: The manuscript would benefit from reporting error bars, standard deviations, or statistical significance for all quantitative metrics to strengthen the reliability of the performance claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We have revised the abstract to incorporate additional context on the experimental setup, a summary of ablation results, and high-level descriptions of the core mechanisms while preserving its conciseness. Detailed information remains in the body of the manuscript. Below we respond to each major comment.
read point-by-point responses
-
Referee: Abstract: The abstract states specific quantitative results (98.0% harmful content detection accuracy, 96.9% communication reduction, PSNR reduction from 31.7 dB to 15.1 dB) without any description of the experimental setup, including LLM model sizes or architectures, datasets used, number of federated clients, data distribution, training hyperparameters, or baseline comparisons. This omission is load-bearing for the central empirical claims and prevents verification or reproduction.
Authors: We agree that the abstract benefits from additional context for the reported results. In the revised manuscript, we have expanded the abstract to briefly outline the experimental setup, including LLM sizes (7B–70B parameters), datasets (federated variants of GLUE, toxicity, and factuality benchmarks), client count (10–50 with non-IID partitioning), key hyperparameters, and baseline comparisons (FedAvg, DP-SGD, and others). Full details and reproducibility information are provided in Section 4. revision: yes
-
Referee: Abstract: The assertion that 'ablations show that each component contributes independently' is presented without any supporting data, tables, figures, or quantitative metrics (e.g., performance deltas when ablating individual pillars). Detailed ablation results with controls for interactions between Paillier encryption, binarized aggregation, and contrastive grounding are required to substantiate the independence claim.
Authors: We acknowledge that the abstract's claim on independent contributions requires substantiation. The full ablation study, including quantitative performance deltas and controls for interactions among components, appears in Section 5.3 and Table 6. We have revised the abstract to include a concise summary of these findings (e.g., performance drops when removing individual pillars) and a direct reference to the ablation table. revision: yes
-
Referee: Abstract: No equations, complexity analysis, or feasibility discussion is provided for applying Paillier encryption to high-dimensional LLM gradients or for the 'smartification' and 'alignment-aware binarized aggregation' mechanisms. This is critical because the integration of encryption with binarization could introduce unmeasured overhead or utility loss at LLM scale, directly affecting the reported privacy-utility trade-off.
Authors: We agree that the abstract should offer more insight into the mechanisms. We have updated the abstract with a high-level description of gradient smartification prior to Paillier encryption, the alignment-aware binarized aggregation, and their integration, while noting that experiments demonstrate preserved utility and the reported efficiency gains. Equations, complexity analysis, and feasibility discussion (including overhead measurements) are contained in Sections 3.1–3.4; the abstract now references these sections. revision: yes
Circularity Check
No derivation chain; claims are purely empirical benchmarks with no mathematical predictions or self-referential reductions
full rationale
The paper describes SafeLM as an integrated framework addressing privacy (via Paillier encryption and gradient smartification), security defenses, contrastive grounding for factuality, and alignment-aware binarized aggregation. All reported outcomes—98.0% harmful content detection, 96.9% communication reduction, and gradient inversion PSNR drop from 31.7 dB to 15.1 dB—are presented as results from benchmark evaluations and ablations. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citations that bear the central load appear in the provided text. The ablations are described as showing independent contributions, but these remain experimental measurements rather than any construction that reduces to its own inputs. The work is therefore self-contained as an empirical engineering contribution without circularity in any derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Brendan McMahan, Ilya Mironov, Kunal Talwar, and Li Zhang
Martin Abadi, Andy Chu, Ian Goodfellow, H. Brendan McMahan, Ilya Mironov, Kunal Talwar, and Li Zhang. Deep learning with differential privacy. InProceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security (CCS), pages 308–318. ACM,
2016
-
[2]
Generating natural language adversarial examples
Moustafa Alzantot, Yash Sharma, Ahmed Elgohary, Bo-Jhang Ho, Mani Srivastava, and Kai-Wei Chang. Generating natural language adversarial examples. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 2890–2896. Association for Computational Linguistics,
2018
-
[3]
Brendan McMahan, Sarvar Patel, Daniel Ramage, Aaron Segal, and Karn Seth
Keith Bonawitz, Vladimir Ivanov, Ben Kreuter, Antonio Marcedone, H. Brendan McMahan, Sarvar Patel, Daniel Ramage, Aaron Segal, and Karn Seth. Practical secure aggregation for privacy- preserving machine learning. InProceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security (CCS), pages 1175–1191. ACM,
2017
-
[4]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwi...
1901
-
[5]
Targeted Backdoor Attacks on Deep Learning Systems Using Data Poisoning
Xinyun Chen, Chang Liu, Bo Li, Kimberly Lu, and Dawn Song. Targeted backdoor attacks on deep learning systems using data poisoning. InarXiv preprint arXiv:1712.05526,
work page internal anchor Pith review arXiv
-
[6]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, Scott Johnston, Sheer El-Showk, Andy Jones, Nelson Elhage, Tristan Hume, Anna Chen, Yuntao Palomas, Liane Lovitt, Neel Nanda, Esin Durmus, Deep Ganguli, Jackson Kernion, Jared Li, Maxwell Nye, Amanda A...
work page internal anchor Pith review arXiv
-
[7]
On faithfulness and factuality in abstractive summarization
Joshua Maynez, Shashi Narayan, Bernd Bohnet, and Ryan McDonald. On faithfulness and factuality in abstractive summarization. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL), pages 1906–1919. Association for Computational Linguistics,
1906
-
[8]
FActScore: Fine-grained atomic evaluation of factual precision in long form text generation
Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Wei Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. FActScore: Fine-grained atomic evaluation of factual precision in long form text generation. InProceedings of the 2023 Conference on Empir- ical Methods in Natural Language Processing (EMNLP), pages 12076–12100. Association...
2023
-
[9]
Public-key cryptosystems based on composite degree residuosity classes
Pascal Paillier. Public-key cryptosystems based on composite degree residuosity classes. InAdvances in Cryptology – EUROCRYPT 1999, volume 1592 ofLecture Notes in Computer Science, pages 223–238. Springer,
1999
-
[10]
Ignore previous prompt: Attack techniques for language models
Ethan Perez, Saffron Ribeiro, et al. Ignore previous prompt: Attack techniques for language models. InNeurIPS 2022 Workshop on Machine Learning Safety,
2022
-
[11]
Brendan McMahan
Ziteng Sun, Peter Kairouz, Ananda Theertha Suresh, and H. Brendan McMahan. Can you really backdoor federated learning? InNeurIPS 2019 Workshop on Federated Learning for Data Privacy and Confidentiality,
2019
-
[12]
Zhao, Shi Feng, and Sameer Singh
Eric Wallace, Tony Z. Zhao, Shi Feng, and Sameer Singh. Concealed data poisoning attacks on nlp models. InProceedings of the 2021 Conference of the North American Chapter of the Associ- ation for Computational Linguistics (NAACL), pages 139–150. Association for Computational Linguistics,
2021
-
[13]
idlg: Improved deep leakage from gradients.arXiv preprint arXiv:2001.02610, 2020
Bo Zhao, Konda Reddy Mopuri, and Hakan Bilen. iDLG: Improved deep leakage from gradients. In arXiv preprint arXiv:2001.02610,
-
[14]
Taking expectations completes the proof.□ B.2 Proof of Theorem 1 Summing the descent lemma overt= 0,
By the definition of cosine alignment, ⟨∇L(Wt),˜gt⟩ ≥γ∥∇L(W t)∥∥˜gt∥ ≥γ∥g t∥2 (using Cauchy- Schwarz and∥˜gt∥ ≥ ∥g t∥for binarized updates). Taking expectations completes the proof.□ B.2 Proof of Theorem 1 Summing the descent lemma overt= 0, . . . , T−1and choosingη= 1/ √ T: 1 T T−1X t=0 E ∥∇L(Wt)∥2 ≤ L(W0)−L ∗ ηγT + Lη 2γ E ∥˜g∥2 =O 1 γ √ T .(13) The min...
2048
-
[15]
Table 9: Per-class detection metrics for SafeLM (Random Forest, Config 2)
on the balanced multi-class evaluation set (n= 7,000 ; 1,000 per class). Table 9: Per-class detection metrics for SafeLM (Random Forest, Config 2). Harm Category TP FP FN Prec. Rec. F1 Benign 992 8 15 0.992 0.9850.989 DoS / Flood 978 12 10 0.988 0.9900.989 DDoS 975 14 11 0.986 0.9890.987 Port Scan 935 42 23 0.957 0.9760.966 Brute Force 928 48 24 0.951 0.9...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.