Recognition: unknown
Beyond Feature Fusion: Contextual Bayesian PEFT for Multimodal Uncertainty Estimation
Pith reviewed 2026-05-10 08:37 UTC · model grok-4.3
The pith
CoCo-LoRA conditions Bayesian low-rank text adapters on audio context signals to estimate uncertainty without high-dimensional fusion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
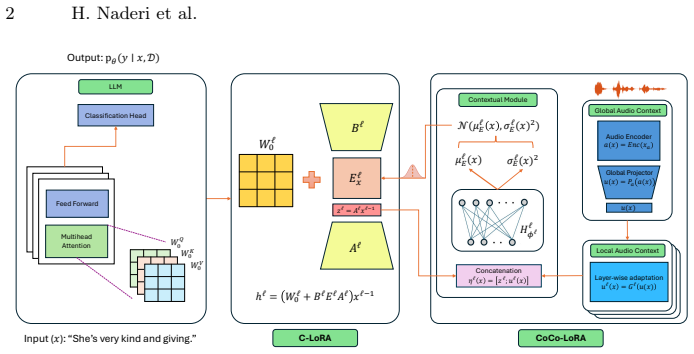
CoCo-LoRA conditions a contextual variational posterior in the low-rank space on local text-derived adapter features and an audio-derived context signal. A pooled audio embedding is projected once into a shared context space and adapted through lightweight layer-wise heads, enabling global-to-local, depth-specific modulation of the adapter uncertainty and update without high-dimensional multimodal fusion. Stochasticity remains confined to a compact latent component in the rank space.
What carries the argument
Contextual variational posterior over low-rank adapters, modulated by a projected pooled audio embedding through lightweight layer-wise heads for depth-specific uncertainty control.
If this is right
- Audio context can be used to make low-rank adapter uncertainty reflect external factors such as background noise or speaking style in speech-centered text tasks.
- The approach delivers performance comparable to feature-fusion baselines while using far fewer additional parameters.
- Uncertainty estimates become heteroscedastic and audio-sensitive without sacrificing the scalability of standard PEFT methods.
- High-coverage labels benefit most from the added context signal for reliable low-resource adaptation.
Where Pith is reading between the lines
- Context from one modality can usefully shape uncertainty modeling in another modality even when the two are not fused into a joint representation.
- The same lightweight projection-and-head design could be tested with other auxiliary signals such as video frames or metadata to control uncertainty in different prediction settings.
- Separating uncertainty modulation from feature fusion opens a route to more modular multimodal systems that scale better under tight compute budgets.
Load-bearing premise
A single pooled audio embedding projected into a shared space and adapted by lightweight layer-wise heads can supply effective global-to-local modulation of adapter uncertainty without needing high-dimensional multimodal fusion.
What would settle it
On datasets with strong acoustic variability, an ablation that removes or randomizes the audio context signal shows no gain in uncertainty calibration or task accuracy relative to text-only Bayesian LoRA baselines.
Figures
read the original abstract
We introduce CoCo-LoRA, a multimodal, uncertainty-aware parameter-efficient fine-tuning method for text prediction tasks accompanied by audio context. Existing PEFT approaches such as LoRA are efficient but typically deterministic, while recent Bayesian low-rank adapters model uncertainty in a lightweight way yet remain largely unimodal and condition uncertainty primarily on internal text features. This leaves them poorly equipped to reflect uncertainty driven by external acoustic factors such as background noise, channel variability, or speaking style, which can materially affect reliability in speech-centered applications. CoCo-LoRA addresses this gap by conditioning a contextual variational posterior in the low-rank space on both local text-derived adapter features and an audio-derived context signal. A pooled audio embedding is projected once into a shared context space and then adapted through lightweight layer-wise heads, enabling global-to-local, depth-specific modulation of the adapter uncertainty and update without high-dimensional multimodal fusion. Stochasticity is confined to a compact latent component in the rank space, preserving PEFT scalability while producing audio-sensitive, heteroscedastic uncertainty. Based on our evaluations across diverse tasks and backbone combinations, CoCo-LoRA consistently matches or outperforms text-only PEFT and conventional feature-fusion transfer baselines, particularly on high-coverage labels where reliable adaptation is critical. The results indicate that using audio as a contextual uncertainty signal, rather than as a fused feature stream, provides a robust and parameter-efficient alternative for multimodal low-resource prediction.
Editorial analysis
A structured set of objections, weighed in public.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems19(2006)
Ben-David, S., Blitzer, J., Crammer, K., Pereira, F.: Analysis of representations for domain adaptation. Advances in neural information processing systems19(2006)
2006
-
[2]
IEEE/ACM transactions on audio, speech, and language processing31, 2523–2533 (2023)
Borsos, Z., Marinier, R., Vincent, D., Kharitonov, E., Pietquin, O., Sharifi, M., Roblek, D., Teboul, O., Grangier, D., Tagliasacchi, M., et al.: Audiolm: a language modeling approach to audio generation. IEEE/ACM transactions on audio, speech, and language processing31, 2523–2533 (2023)
2023
-
[3]
Advances in neural information processing systems33, 1877–1901 (2020) CoCo-LoRA: Contextual Bayesian PEFT for Uncertainty Estimation 15
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J.D., Dhariwal, P., Nee- lakantan, A., Shyam, P., Sastry, G., Askell, A., et al.: Language models are few-shot learners. Advances in neural information processing systems33, 1877–1901 (2020) CoCo-LoRA: Contextual Bayesian PEFT for Uncertainty Estimation 15
1901
-
[4]
In: International conference on machine learning
Chen, T., Kornblith, S., Norouzi, M., Hinton, G.: A simple framework for con- trastive learning of visual representations. In: International conference on machine learning. pp. 1597–1607. PMLR (2020)
2020
-
[5]
Advances in neural information pro- cessing systems33, 22243–22255 (2020)
Chen, T., Kornblith, S., Swersky, K., Norouzi, M., Hinton, G.E.: Big self-supervised models are strong semi-supervised learners. Advances in neural information pro- cessing systems33, 22243–22255 (2020)
2020
-
[6]
International Conference on Learning Representations (2021)
Fan, X., Zhang, S., Tanwisuth, K., Qian, X., Zhou, M.: Contextual dropout: An efficient sample-dependent dropout module. International Conference on Learning Representations (2021)
2021
-
[7]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Fu, Z., Yang, H., So, A.M.C., Lam, W., Bing, L., Collier, N.: On the effective- ness of parameter-efficient fine-tuning. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 37, pp. 12799–12807 (2023)
2023
-
[8]
Iclr1(2), 3 (2022)
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: Lora: Low-rank adaptation of large language models. Iclr1(2), 3 (2022)
2022
-
[9]
Fedpara: Low-rank hadamard product for communication-efficient federated learning
Hyeon-Woo, N., Ye-Bin, M., Oh, T.H.: Fedpara: Low-rank hadamard product for communication-efficient federated learning. arXiv preprint arXiv:2108.06098 (2021)
-
[10]
International Conference on Learning Representations (ICLR) (2025)
Leng, J., Huang, C., Zhu, B., Huang, J.: Taming overconfidence in llms: Reward calibration in rlhf. International Conference on Learning Representations (ICLR) (2025)
2025
-
[11]
Liu, H., Tam, D., Muqeeth, M., Mohta, J., Huang, T., Bansal, M., Raffel, C.A.: Few-shot parameter-efficient fine-tuning is better and cheaper than in-context learning.AdvancesinNeuralInformationProcessingSystems35,1950–1965(2022)
1950
-
[12]
In: International con- ference on machine learning
Locatello, F., Poole, B., Rätsch, G., Schölkopf, B., Bachem, O., Tschannen, M.: Weakly-supervised disentanglement without compromises. In: International con- ference on machine learning. pp. 6348–6359. PMLR (2020)
2020
-
[13]
Large Language Models: A Survey
Minaee, S., Mikolov, T., Nikzad, N., Chenaghlu, M., Socher, R., Amatriain, X., Gao, J.: Large language models: A survey. arXiv preprint arXiv:2402.06196 (2024)
work page internal anchor Pith review arXiv 2024
-
[14]
In: 29th International Conference on Artificial Intelligence and Statistics (AISTATS) (2026)
Naderi, H., Haji Soleimani, B., Matwin, S.: From token imbalance to balanced routing: An elbo-regularized probabilistic framework for contrastive multimodal learning. In: 29th International Conference on Artificial Intelligence and Statistics (AISTATS) (2026)
2026
-
[15]
arXiv preprint arXiv:1909.01067 (2019)
Naderi, H., Soleimani, B.H., Matwin, S.: Multimodal deep learning for mental disorders prediction from audio speech samples. arXiv preprint arXiv:1909.01067 (2019)
-
[16]
In: 2020 international joint conference on neural networks (IJCNN)
Naderi, H., Soleimani, B.H., Matwin, S.: Generating high-fidelity images with dis- entangled adversarial vaes and structure-aware loss. In: 2020 international joint conference on neural networks (IJCNN). pp. 1–8. IEEE (2020)
2020
-
[17]
Proceedings of the Canadian Conference on Artificial Intel- ligence (may 19 2025), https://caiac.pubpub.org/pub/zpm3p8jv
Naderi, H., Soleimani, B.H., Matwin, S.: Mac: Multimodal Attentive Contrastive Learning Framework. Proceedings of the Canadian Conference on Artificial Intel- ligence (may 19 2025), https://caiac.pubpub.org/pub/zpm3p8jv
2025
-
[18]
In: Proceedings of The 12th International Workshop on Semantic Evaluation
Naderi, H., Soleimani, B.H., Mohammad, S., Kiritchenko, S., Matwin, S.: Deep- miner at semeval-2018 task 1: emotion intensity recognition using deep represen- tation learning. In: Proceedings of The 12th International Workshop on Semantic Evaluation. pp. 305–312 (2018)
2018
-
[19]
Representation Learning with Contrastive Predictive Coding
Oord, A.v.d., Li, Y., Vinyals, O.: Representation learning with contrastive predic- tive coding. arXiv preprint arXiv:1807.03748 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[20]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PMLR (2021) 16 H. Naderi et al
2021
-
[21]
OpenAI blog1(8), 9 (2019)
Radford,A.,Wu,J.,Child,R.,Luan,D.,Amodei,D.,Sutskever,I.,etal.:Language models are unsupervised multitask learners. OpenAI blog1(8), 9 (2019)
2019
-
[22]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025)
Rahmati, A.H., Jantre, S., Zhang, W., Wang, Y., Yoon, B.J., Urban, N., Qian, X.: C-loRA: Contextual low-rank adaptation for uncertainty estimation in large language models. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025)
2025
-
[23]
AudioPaLM: A large language model that can speak and listen,
Rubenstein, P.K., Asawaroengchai, C., Nguyen, D.D., Bapna, A., Borsos, Z., Quitry, F.d.C., Chen, P., Badawy, D.E., Han, W., Kharitonov, E., et al.: Au- diopalm: A large language model that can speak and listen. arXiv preprint arXiv:2306.12925 (2023)
-
[24]
Nature620(7973), E19 (2023)
Singhal, K., Azizi, S., Tu, T., Mahdavi, S.S., Wei, J., Chung, H.W., Scales, N., Tanwani, A., Cole-Lewis, H., Pfohl, S., et al.: Publisher correction: large language models encode clinical knowledge. Nature620(7973), E19 (2023)
2023
-
[25]
BMC psychiatry14(1), 344 (2014)
Uher, R., Cumby, J., MacKenzie, L.E., Morash-Conway, J., Glover, J.M., Aylott, A., Propper, L., Abidi, S., Bagnell, A., Pavlova, B., et al.: A familial risk enriched cohort as a platform for testing early interventions to prevent severe mental illness. BMC psychiatry14(1), 344 (2014)
2014
-
[26]
Advances in neural informa- tion processing systems37, 67758–67794 (2024)
Wang, Y., Shi, H., Han, L., Metaxas, D., Wang, H.: Blob: Bayesian low-rank adap- tation by backpropagation for large language models. Advances in neural informa- tion processing systems37, 67758–67794 (2024)
2024
-
[27]
International Conference on Learning Representations (ICLR) (2024)
Xiong, M., Hu, Z., Lu, X., Li, Y., Fu, J., He, J., Hooi, B.: Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms. International Conference on Learning Representations (ICLR) (2024)
2024
-
[28]
International Conference on Learning Representations (ICLR) (2024)
Yang, A.X., Robeyns, M., Wang, X., Aitchison, L.: Bayesian low-rank adaptation for large language models. International Conference on Learning Representations (ICLR) (2024)
2024
-
[29]
In: The Eleventh Inter- national Conference on Learning Representations (2023)
Zhang, Q., Chen, M., Bukharin, A., He, P., Cheng, Y., Chen, W., Zhao, T.: Adap- tive budget allocation for parameter-efficient fine-tuning. In: The Eleventh Inter- national Conference on Learning Representations (2023)
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.