Recognition: unknown
IYKYK (But AI Doesn't): Automated Content Moderation Does Not Capture Communities' Heterogeneous Attitudes Towards Reclaimed Language
Pith reviewed 2026-05-10 08:16 UTC · model grok-4.3
The pith
Automated hate speech detectors align poorly with how members of LGBTQIA+, Black, and women communities judge reclaimed slur usage.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
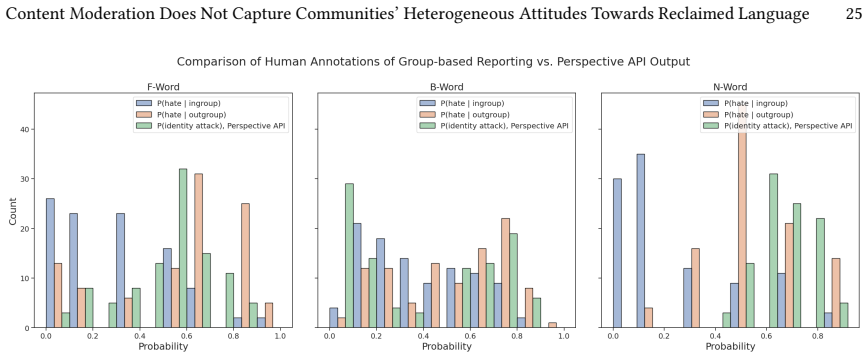
Through an annotated corpus of online slur usages collected from community members, the authors demonstrate low inter-annotator agreement across all groups and questions, coupled with weak correspondence to Perspective API scores. Features such as whether the slur was used derogatorily or targeted at the speaker influence annotator decisions, but overall, the lack of clear identity and intent signals leads to varied interpretations even among in-group members.
What carries the argument
The annotated corpus of slur-containing texts, paired with annotator judgments on hate speech flagging and contextual features, compared against automated assessments from Perspective API.
If this is right
- Annotators report texts as hate speech more often when slur usage is derogatory or targeted at oneself.
- Low inter-annotator agreement persists across communities, showing disagreement even within groups.
- Automated assessments fail to distinguish reclaimed uses, potentially suppressing marginalized voices.
- Personal history and lived experience contribute to differences in interpretation.
Where Pith is reading between the lines
- Moderation systems may need to incorporate community-specific training data or user-reported context to better handle reclaimed language.
- Future tools could allow users to signal reclaimed intent, reducing over-flagging of in-group speech.
- Policy for platforms should account for the heterogeneity rather than assuming uniform community standards.
Load-bearing premise
That the attitudes of the recruited social media users accurately represent the stable views of their broader communities despite variations in personal experience.
What would settle it
A study with a larger sample of annotators from the same communities showing high agreement on the same set of texts would indicate that the observed disagreement is not representative.
Figures



read the original abstract
Reclaimed slur usage is a common and meaningful practice online for many marginalized communities. It serves as a source of solidarity, identity, and shared experience. However, contemporary automated and AI-based moderation tools for online content largely fail to distinguish between reclaimed and hateful uses of slurs, resulting in the suppression of marginalized voices. In this work, we use quantitative and qualitative methods to examine the attitudes of social media users in LGBTQIA+, Black, and women communities around reclaimed slurs targeting our focus groups including the f-word, n-word, and b-word. With social media users from these communities, we collect and analyze an annotated online slur usage corpus. The corpus includes annotators' perceptions of whether an online text containing a slur should be flagged as hate speech, as well as contextual features of the slur usage. Across all communities and annotation questions, we observe low inter-annotator agreement, indicating substantial disagreement among in-group annotators. This is compounded by the fact that, absent clear contextual signals of identity and intent, even in-group members may disagree on how to interpret reclaimed slur usage online. Semi-structured interviews with annotators suggest that differences in lived experience and personal history contribute to this variation as well. We find poor alignment between annotator judgments and automated hate speech assessments produced by Perspective API. We further observe that certain features of a text such as whether the slur usage was derogatory and if the slur was targeted at oneself are more associated with whether annotators report the text as hate speech. Together, these findings highlight the inherent subjectivity and contextual nature of how marginalized communities interpret slurs online.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that automated hate speech detection tools like Perspective API fail to capture heterogeneous attitudes toward reclaimed slur usage (f-word, n-word, b-word) in LGBTQIA+, Black, and women communities. It supports this via a newly collected annotated corpus from in-group social media users, reporting low inter-annotator agreement across communities and questions, poor alignment between annotator judgments and API scores, associations between features like derogatory tone or self-targeting and hate speech perceptions, and interview insights linking variation to differences in lived experience.
Significance. If the empirical findings hold after addressing methodological gaps, the work would be significant for NLP and content moderation research. It supplies direct evidence that community attitudes toward reclaimed language are context-dependent and non-monolithic, with implications for why current automated systems over-flag or under-flag such content. The mixed-methods approach (annotations plus interviews) and focus on specific slurs and communities add concrete data to ongoing debates about inclusive moderation design.
major comments (3)
- [Annotation Collection / Methods] Annotation Collection / Methods: The paper recruits social media users via self-identification with the target communities but provides no sample sizes, demographic stratification (age, region, usage frequency), verification of in-group status, or comparison to population benchmarks. This is load-bearing for the central claim, as the reported low IAA and API misalignment could be artifacts of unrepresentative sampling rather than inherent community heterogeneity (see skeptic note on recruitment).
- [Results] Results: The abstract and main text assert 'low inter-annotator agreement' and 'substantial disagreement' without reporting quantitative metrics (e.g., Krippendorff's alpha, Fleiss' kappa), per-question or per-community values, or statistical tests. This leaves the robustness of the heterogeneity conclusion unclear and prevents readers from assessing whether agreement is truly low or merely moderate.
- [API Comparison / Results] API Comparison / Results: The claim of 'poor alignment' between annotator judgments and Perspective API is central but lacks specifics on the alignment metric (correlation, thresholded accuracy, etc.), the exact API output used, or any baseline comparisons. Without these, it is hard to judge the magnitude or generalizability of the misalignment finding.
minor comments (2)
- [Abstract] Abstract: Lacks any numerical details on sample size, agreement scores, or effect sizes, which would allow immediate evaluation of the strength of the reported findings.
- [Discussion] Discussion: The feature associations (derogatory use, self-targeting) are noted but could be strengthened by reporting odds ratios or regression coefficients to quantify their predictive power.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which has helped us identify areas for improvement in clarity and reporting. We address each major comment below, indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Annotation Collection / Methods] The paper recruits social media users via self-identification with the target communities but provides no sample sizes, demographic stratification (age, region, usage frequency), verification of in-group status, or comparison to population benchmarks. This is load-bearing for the central claim, as the reported low IAA and API misalignment could be artifacts of unrepresentative sampling rather than inherent community heterogeneity.
Authors: We agree that providing more details on recruitment will strengthen transparency. In the revised manuscript, we will add sample sizes for annotators per community, available demographic information (age ranges and regions), and explicit description of the self-identification process. We will also add a limitations discussion on the lack of population benchmarks. However, the observed heterogeneity is supported by within-sample variation and interview data on lived experience, which indicate it is not solely an artifact of sampling. revision: partial
-
Referee: [Results] The abstract and main text assert 'low inter-annotator agreement' and 'substantial disagreement' without reporting quantitative metrics (e.g., Krippendorff's alpha, Fleiss' kappa), per-question or per-community values, or statistical tests.
Authors: We apologize for not highlighting the metrics in the abstract and summary. The results section reports Krippendorff's alpha per community and question (indicating poor agreement). We will revise the abstract and results to explicitly include these values, per-question breakdowns, and relevant statistical tests to allow readers to assess the robustness of the heterogeneity finding. revision: yes
-
Referee: [API Comparison / Results] The claim of 'poor alignment' between annotator judgments and Perspective API is central but lacks specifics on the alignment metric (correlation, thresholded accuracy, etc.), the exact API output used, or any baseline comparisons.
Authors: We agree more precise reporting is needed. In the revision, we will specify the alignment metrics (e.g., correlation with annotator judgments and accuracy at standard thresholds), confirm use of the toxicity score, and add baseline comparisons (e.g., against majority vote or random) to better contextualize the misalignment magnitude. revision: yes
Circularity Check
No circularity: empirical study relies on newly collected annotations and external API comparison
full rationale
The paper presents an observational analysis of annotator judgments on slur usage collected from recruited social media users, reports inter-annotator agreement statistics, and directly compares those judgments to Perspective API outputs. No equations, fitted parameters, or predictions are defined in terms of the target results. No self-citation chain is invoked to justify the core claims about heterogeneity or misalignment; the findings rest on the primary data collection and standard agreement metrics. The sampling assumption (representativeness of recruited users) is a potential external-validity concern but does not create internal circularity in the reported derivation or results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Annotators drawn from the target communities provide valid and informative perspectives on reclaimed slur usage
Reference graph
Works this paper leans on
-
[1]
Hala Al Kuwatly, Maximilian Wich, and Georg Groh. 2020. Identifying and Measuring Annotator Bias Based on Annotators’ Demographic Characteristics. InProceedings of the Fourth Workshop on Online Abuse and Harms, Seyi Akiwowo, Bertie Vidgen, Vinodkumar Prabhakaran, and Zeerak Waseem (Eds.). Association for Computational Linguistics, Online, 184–190. doi:10....
-
[2]
2023.We Asked People Who Used to Make Homophobic Comments What Their Turning Point Was
David Allegretti. 2023.We Asked People Who Used to Make Homophobic Comments What Their Turning Point Was. Vice. https://www.vice.com/en/ article/we-asked-people-who-used-to-make-homophobic-comments-what-their-turning-point-was/
2023
-
[3]
Luvell Anderson and Ernie Lepore. 2013. Slurring Words.Noûs47, 1 (2013), 25–48. doi:10.1111/j.1468-0068.2010.00820.x
-
[4]
Luvell Anderson and Ernie Lepore. 2013. What Did You Call Me? Slurs as Prohibited Words.Analytic Philosophy54, 3 (2013), 350–363. doi:10.1111/ phib.12023
2013
-
[5]
Carolina Are, Catherine Talbot, and Pam Briggs. 2025. Social media affordances of LGBTQIA+ expression and community formation.Convergence 31, 4 (2025), 1401–1422. arXiv:https://doi.org/10.1177/13548565241296628 doi:10.1177/13548565241296628
-
[6]
2007.Nigger vs
Jabari Asim. 2007.Nigger vs. Nigga. Houghton Mifflin Harcourt, Boston, MA, USA, 212–257
2007
-
[7]
Giuseppe Attanasio, Debora Nozza, Dirk Hovy, and Elena Baralis. 2022. Entropy-based Attention Regularization Frees Unintended Bias Mitigation from Lists. InFindings of the Association for Computational Linguistics: ACL 2022, Smaranda Muresan, Preslav Nakov, and Aline Villavicencio (Eds.). Association for Computational Linguistics, Dublin, Ireland, 1105–11...
-
[8]
Joris Baan, Wilker Aziz, Barbara Plank, and Raquel Fernandez. 2022. Stop Measuring Calibration When Humans Disagree. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang (Eds.). Association for Computational Linguistics, Abu Dhabi, United Arab Emirates, 1892–1915. doi:10....
- [9]
-
[10]
Valerio Basile, Michael Fell, Tommaso Fornaciari, Dirk Hovy, Silviu Paun, Barbara Plank, Massimo Poesio, and Alexandra Uma. 2021. We Need to Consider Disagreement in Evaluation. InProceedings of the 1st Workshop on Benchmarking: Past, Present and Future, Kenneth Church, Mark Liberman, and Valia Kordoni (Eds.). Association for Computational Linguistics, On...
-
[11]
Claudia Bianchi. 2014. Slurs and appropriation: An echoic account.Journal of Pragmatics66 (2014), 35–44. doi:10.1016/j.pragma.2014.02.009
-
[12]
Laura Biester, Vanita Sharma, Ashkan Kazemi, Naihao Deng, Steven Wilson, and Rada Mihalcea. 2022. Analyzing the Effects of Annotator Gender across NLP Tasks. InProceedings of the 1st Workshop on Perspectivist Approaches to NLP LREC2022, Gavin Abercrombie, Valerio Basile, Sara Tonelli, Verena Rieser, and Alexandra Uma (Eds.). European Language Resources As...
2022
-
[13]
BITCHSTIX. 2026. BITCHSTIX: A Balm for Every Body. https://bitchstix.com/
2026
-
[14]
Black in AI. 2017. Black in AI. https://www.blackinai.org/
2017
-
[15]
As long as we stick together everything is going to be OK
Laura Bradley. 2023.“As long as we stick together everything is going to be OK”: An Examination of Aotearoa’s Far-Right Subculture on 4chan.Master’s thesis. Victoria University of Wellington. doi:10.26686/wgtn.24871797
-
[16]
John P. Brammer. 2019.A Decade of LGBTQ Pop Culture Visibility but Stalled Political Progress. NBC News. https://www.nbcnews.com/think/ opinion/decade-lgbtq-pop-culture-visibility-stalled-political-progress-ncna1108786
2019
-
[17]
Kendra Calhoun and Alexia Fawcett. 2023. “They Edited Out her Nip Nops”: Linguistic Innovation as Textual Censorship Avoidance on TikTok. LanguageInternet21 (Dec. 2023), 1–30. doi:10.14434/li.v21.37371
-
[18]
Santiago Castro. 2017. Fast Krippendorff: Fast computation of Krippendorff’s alpha agreement measure. https://github.com/pln-fing-udelar/fast- krippendorff
2017
-
[19]
Bianca Cepollaro. 2021. The moral status of the reclamation of slurs.Organon F28, 3 (2021), 672–688
2021
-
[20]
Bianca Cepollaro and Dan López de Sa. 2022. Who Reclaims Slurs?Pacific Philosophical Quarterly103, 3 (2022), 606–619. doi:10.1111/papq.12403
-
[21]
Amanda Cercas Curry, Gavin Abercrombie, and Zeerak Talat. 2024. Subjective Isms? On the Danger of Conflating Hate and Offence in Abusive Language Detection. InProceedings of the 8th Workshop on Online Abuse and Harms (WOAH 2024), Yi-Ling Chung, Zeerak Talat, Debora Nozza, Flor Miriam Plaza-del Arco, Paul Röttger, Aida Mostafazadeh Davani, and Agostina Cal...
-
[22]
Christina Chance and Kai-Wei Chang. 2025. Re-imagining Virtual Communities: Ethical Guidelines for Studying Black Twitter.Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society8, 1 (Oct. 2025), 541–553. doi:10.1609/aies.v8i1.36569
-
[23]
Thomas Davidson, Debasmita Bhattacharya, and Ingmar Weber. 2019. Racial Bias in Hate Speech and Abusive Language Detection Datasets. In Proceedings of the Third Workshop on Abusive Language Online, Sarah T. Roberts, Joel Tetreault, Vinodkumar Prabhakaran, and Zeerak Waseem (Eds.). Association for Computational Linguistics, Florence, Italy, 25–35. doi:10.1...
-
[24]
Naihao Deng, Xinliang Zhang, Siyang Liu, Winston Wu, Lu Wang, and Rada Mihalcea. 2023. You Are What You Annotate: Towards Better Models through Annotator Representations. InFindings of the Association for Computational Linguistics: EMNLP 2023, Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). Association for Computational Linguistics, Singapore, 12475–124...
- [25]
-
[26]
Lucas Dixon, John Li, Jeffrey Sorensen, Nithum Thain, and Lucy Vasserman. 2018. Measuring and Mitigating Unintended Bias in Text Classification. InProceedings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society(New Orleans, LA, USA)(AIES ’18). Association for Computing Machinery, New York, NY, USA, 67–73. doi:10.1145/3278721.3278729
-
[27]
Rebecca Dorn, Lee Kezar, Fred Morstatter, and Kristina Lerman. 2024. Harmful Speech Detection by Language Models Exhibits Gender-Queer Dialect Bias. InProceedings of the 4th ACM Conference on Equity and Access in Algorithms, Mechanisms, and Optimization(San Luis Potosi, Mexico) (EAAMO ’24). Association for Computing Machinery, New York, NY, USA, Article 6...
-
[28]
Lia Draetta, Chiara Ferrando, Marco Cuccarini, Liam James, and Viviana Patti. 2024. ReCLAIM Project: Exploring Italian Slurs Reappropriation with Large Language Models. InProceedings of the 10th Italian Conference on Computational Linguistics (CLiC-it 2024), Felice Dell’Orletta, Alessandro Lenci, Simonetta Montemagni, and Rachele Sprugnoli (Eds.). CEUR Wo...
2024
-
[29]
Shangbin Feng, Taylor Sorensen, Yuhan Liu, Jillian Fisher, Chan Young Park, Yejin Choi, and Yulia Tsvetkov. 2024. Modular Pluralism: Pluralistic Alignment via Multi-LLM Collaboration. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (Eds.). Association for Computati...
-
[30]
Eve Fleisig, Rediet Abebe, and Dan Klein. 2023. When the Majority is Wrong: Modeling Annotator Disagreement for Subjective Tasks. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). Association for Computational Linguistics, Singapore, 6715–6726. doi:10.18653/v1/2023.e...
-
[31]
Eve Fleisig, Su Lin Blodgett, Dan Klein, and Zeerak Talat. 2024. The Perspectivist Paradigm Shift: Assumptions and Challenges of Capturing Human Labels. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), Kevin Duh, Helena Gomez, and Steve...
-
[32]
Sarah Florini. 2014. Tweets, Tweeps, and Signifyin’: Communication and Cultural Performance on “Black Twitter”.Television & New Media15, 3 (2014), 223–237. arXiv:https://doi.org/10.1177/1527476413480247 doi:10.1177/1527476413480247
-
[33]
Chiara Francesconi, Cristina Bosco, Fabio Poletto, and Manuela Sanguinetti. 2019. Error Analysis in a Hate Speech Detection Task: The Case of HaSpeeDe-TW at EVALITA 2018. InProceedings of the Sixth Italian Conference on Computational Linguistics (CLiC-it 2019), Raffaella Bernardi, Roberto Navigli, and Giovanni Semeraro (Eds.). CEUR Workshop Proceedings, B...
2019
-
[34]
Adam D Galinsky, Kurt Hugenberg, Carla Groom, and Galen V Bodenhausen. 2003. The reappropriation of stigmatizing labels: Implications for soical identity. InIdentity Issues in Groups. Emerald Group Publishing Limited, Leeds, UK. doi:10.1016/S1534-0856(02)05009-0
-
[35]
2026.NJ cops who collected millions in salary while suspended for using the N-word can finally be fired: judge rules
Shane Galvin. 2026.NJ cops who collected millions in salary while suspended for using the N-word can finally be fired: judge rules. New York Post. https: //nypost.com/2026/01/03/us-news/nj-cops-who-collected-millions-in-salary-while-suspended-for-using-the-n-word-can-be-fired-judge-rules/
2026
-
[36]
2021.Intel’s Dystopian Anti-Harassment AI Lets Users Opt In for ‘Some’ Racism
Matthew Gault. 2021.Intel’s Dystopian Anti-Harassment AI Lets Users Opt In for ‘Some’ Racism. Vice. https://www.vice.com/en/article/intels- dystopian-anti-harassment-ai-lets-users-opt-in-for-some-racism Accessed: 2026-01-09
2021
- [37]
-
[38]
Kivlichan, Rachel Rosen, and Lucy Vasserman
Nitesh Goyal, Ian D. Kivlichan, Rachel Rosen, and Lucy Vasserman. 2022. Is Your Toxicity My Toxicity? Exploring the Impact of Rater Identity on Toxicity Annotation.Proc. ACM Hum.-Comput. Interact.6, CSCW2, Article 363 (nov 2022), 28 pages. doi:10.1145/3555088
-
[39]
Melody Y. Guan, Manas Joglekar, Eric Wallace, Saachi Jain, Boaz Barak, Alec Helyar, Rachel Dias, Andrea Vallone, Hongyu Ren, Jason Wei, Hyung Won Chung, Sam Toyer, Johannes Heidecke, Alex Beutel, and Amelia Glaese. 2025. Deliberative Alignment: Reasoning Enables Safer Language Models. arXiv:2412.16339 [cs.CL] https://arxiv.org/abs/2412.16339
-
[40]
Necdet Gürkan, Mohammed Almarzouq, and Pon Rahul Murugaraj. 2023. Personalized Content Moderation and Emergent Outcomes. InProceedings of the International Conference on Information Systems (ICIS). Association for Information Systems, Hyderabad, India, 8 pages. https://aisel.aisnet. org/icis2023/paperthon/paperthon/3
2023
-
[41]
Hala Guta and Magdalena Karolak. 2015. Veiling and blogging: Social media as sites of identity negotiation and expression among Saudi women. Journal of International Women’s Studies16, 2 (2015), 115–127
2015
-
[42]
Haimson, Daniel Delmonaco, Peipei Nie, and Andrea Wegner
Oliver L. Haimson, Daniel Delmonaco, Peipei Nie, and Andrea Wegner. 2021. Disproportionate Removals and Differing Content Moderation Experiences for Conservative, Transgender, and Black Social Media Users: Marginalization and Moderation Gray Areas.Proc. ACM Hum.-Comput. Interact.5, CSCW2, Article 466 (oct 2021), 35 pages. doi:10.1145/3479610
-
[43]
Laura Hanu and Unitary team. 2020. Detoxify. Github. https://github.com/unitaryai/detoxify
2020
-
[44]
Honestly, I Think TikTok has a Vendetta Against Black Creators
Camille Harris, Amber Gayle Johnson, Sadie Palmer, Diyi Yang, and Amy Bruckman. 2023. "Honestly, I Think TikTok has a Vendetta Against Black Creators": Understanding Black Content Creator Experiences on TikTok.Proc. ACM Hum.-Comput. Interact.7, CSCW2, Article 320 (oct 2023), 31 pages. doi:10.1145/3610169
-
[45]
Thomas Hartvigsen, Saadia Gabriel, Hamid Palangi, Maarten Sap, Dipankar Ray, and Ece Kamar. 2022. ToxiGen: A Large-Scale Machine-Generated Dataset for Adversarial and Implicit Hate Speech Detection. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Smaranda Muresan, Preslav Nakov, and Aline ...
-
[46]
Caroline Hatchett. 2024. I Ate My Way Through America’s Bitch-Themed Restaurants and I Have Feelings. https://www.cosmopolitan.com/lifestyle/ a60257625/i-ate-my-way-through-americas-bitch-themed-restaurants-and-i-have-feelings/. Cosmopolitan, published May 22, 2024. Content Moderation Does Not Capture Communities’ Heterogeneous Attitudes Towards Reclaimed...
2024
-
[47]
Monique Hennink and Bonnie N. Kaiser. 2022. Sample sizes for saturation in qualitative research: A systematic review of empirical tests.Social Science & Medicine292 (2022), 114523. doi:10.1016/j.socscimed.2021.114523
- [48]
-
[49]
Jennifer Hornsby. 2001. Meaning and Uselessness: How to Think about Derogatory Words.Midwest Studies In Philosophy25, 1 (2001), 128–141. arXiv:https://onlinelibrary.wiley.com/doi/pdf/10.1111/1475-4975.00042 doi:10.1111/1475-4975.00042
- [50]
-
[51]
Robin Jeshion. 2020. Pride and Prejudiced.Grazer Philosophische Studien97, 1 (2020), 106–137. doi:10.1163/18756735-09701007
-
[52]
Shagun Jhaver, Sucheta Ghoshal, Amy Bruckman, and Eric Gilbert. 2018. Online Harassment and Content Moderation: The Case of Blocklists.ACM Trans. Comput.-Hum. Interact.25, 2, Article 12 (March 2018), 33 pages. doi:10.1145/3185593
-
[53]
Shagun Jhaver, Alice Qian Zhang, Quan Ze Chen, Nikhila Natarajan, Ruotong Wang, and Amy X. Zhang. 2023. Personalizing Content Moderation on Social Media: User Perspectives on Moderation Choices, Interface Design, and Labor.Proc. ACM Hum.-Comput. Interact.7, CSCW2, Article 289 (Oct. 2023), 33 pages. doi:10.1145/3610080
-
[54]
Shagun Jhaver and Amy X. Zhang. 2025. Do Users Want Platform Moderation or Individual Control? Examining the Role of Third-Person Effects and Free Speech Support in Shaping Moderation Preferences.New Media & Society27, 5 (2025), 2930–2950. arXiv:https://doi.org/10.1177/14614448231217993 doi:10.1177/14614448231217993
-
[55]
Shivani Kapania, Alex S Taylor, and Ding Wang. 2023. A hunt for the Snark: Annotator Diversity in Data Practices. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems(Hamburg, Germany)(CHI ’23). Association for Computing Machinery, New York, NY, USA, Article 133, 15 pages. doi:10.1145/3544548.3580645
-
[56]
Alt-Right
Mary M. Kosse. 2025.Semiotics of Online "Alt-Right" Discourse. Ph. D. Dissertation. University of Colorado at Boulder. https://scholar.colorado.edu/ concern/graduate_thesis_or_dissertations/r781wh84t
2025
-
[57]
Jana Kurrek, Haji Mohammad Saleem, and Derek Ruths. 2020. Towards a Comprehensive Taxonomy and Large-Scale Annotated Corpus for Online Slur Usage. InProceedings of the Fourth Workshop on Online Abuse and Harms, Seyi Akiwowo, Bertie Vidgen, Vinodkumar Prabhakaran, and Zeerak Waseem (Eds.). Association for Computational Linguistics, Online, 138–149. doi:10....
-
[58]
Francesca Lameiro, Lavinia Dunagan, Dallas Card, Eric Gilbert, and Oliver Haimson. 2025. TIDEs: A Transgender and Nonbinary Community-Labeled Dataset and Model for Transphobia Identification in Digital Environments. InProceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency (FAccT ’25). Association for Computing Machinery, New ...
-
[59]
Savannah Larimore, Ian Kennedy, Breon Haskett, and Alina Arseniev-Koehler. 2021. Reconsidering Annotator Disagreement about Racist Language: Noise or Signal?. InProceedings of the Ninth International Workshop on Natural Language Processing for Social Media, Lun-Wei Ku and Cheng-Te Li (Eds.). Association for Computational Linguistics, Online, 81–90. doi:10...
-
[60]
Nayeon Lee, Chani Jung, Junho Myung, Jiho Jin, Jose Camacho-Collados, Juho Kim, and Alice Oh. 2024. Exploring Cross-Cultural Differences in English Hate Speech Annotations: From Dataset Construction to Analysis. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies ...
-
[61]
There’s Always a Way to Get Around the Guidelines
Valerie Lookingbill and Kimanh Le. 2024. “There’s Always a Way to Get Around the Guidelines”: Nonsuicidal Self-Injury and Content Moderation on TikTok.Social Media + Society10, 2 (2024), 20563051241254371. doi:10.1177/20563051241254371
-
[62]
Chu Fei Luo, Samuel Dahan, and Xiaodan Zhu. 2025. Towards Low-Resource Alignment to Diverse Perspectives with Sparse Feedback. InFindings of the Association for Computational Linguistics: EMNLP 2025, Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng (Eds.). Association for Computational Linguistics, Suzhou, China, 20330–20339....
-
[63]
Alice E. Marwick and danah boyd. 2011. I tweet honestly, I tweet passionately: Twitter users, context collapse, and the imagined audience.New Media & Society13, 1 (2011), 114–133. doi:10.1177/1461444810365313
-
[64]
Giacomo Marzi, Marco Balzano, and Davide Marchiori. 2024. K-Alpha Calculator–Krippendorff’s Alpha Calculator: A user-friendly tool for computing Krippendorff’s Alpha inter-rater reliability coefficient.MethodsX12 (2024), 102545. doi:10.1016/j.mex.2023.102545
-
[65]
Merriam-Webster. 2026. derogatory. https://www.merriam-webster.com/dictionary/derogatory. Accessed: March 24, 2026
2026
-
[66]
Emanuele Moscato, Tiancheng Hu, Matthias Orlikowski, Paul Röttger, and Debora Nozza. 2025. Personalization up to a Point: Why Personalized Content Moderation Needs Boundaries, and How We Can Enforce Them. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose,...
-
[67]
Luigi Pavone. 2024. Slur reclamation, irony, and resilience.Lodz Papers in Pragmatics20, 2 (2024), 349–363. doi:10.1515/lpp-2024-0029
-
[68]
Jiaxin Pei and David Jurgens. 2023. When Do Annotator Demographics Matter? Measuring the Influence of Annotator Demographics with the POPQUORN Dataset. InProceedings of the 17th Linguistic Annotation Workshop (LA W-XVII), Jakob Prange and Annemarie Friedrich (Eds.). Association for Computational Linguistics, Toronto, Canada, 252–265. doi:10.18653/v1/2023.law-1.25
-
[69]
Barbara Plank. 2022. The “Problem” of Human Label Variation: On Ground Truth in Data, Modeling and Evaluation. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang (Eds.). Association for Computational Linguistics, Abu Dhabi, United Arab Emirates, 10671–10682. doi:10.1865...
-
[70]
Mihaela Popa-Wyatt. 2020. Reclamation: Taking Back Control of Words.Grazer Philosophische Studien97, 1 (2020), 159–176. doi:10.1163/18756735- 09701009 20 Chance et al
-
[71]
Grace Proebsting, Oghenefejiro Isaacs Anigboro, Charlie M. Crawford, Danaé Metaxa, and Sorelle A. Friedler. 2025. Identity-related Speech Suppression in Generative AI Content Moderation. InProceedings of the 5th ACM Conference on Equity and Access in Algorithms, Mechanisms, and Optimization (EAAMO ’25). Association for Computing Machinery, New York, NY, U...
-
[72]
Organizers Of Queerinai, Anaelia Ovalle, Arjun Subramonian, Ashwin Singh, Claas Voelcker, Danica J. Sutherland, Davide Locatelli, Eva Breznik, Filip Klubicka, Hang Yuan, Hetvi J, Huan Zhang, Jaidev Shriram, Kruno Lehman, Luca Soldaini, Maarten Sap, Marc Peter Deisenroth, Maria Leonor Pacheco, Maria Ryskina, Martin Mundt, Milind Agarwal, Nyx Mclean, Pan Xu...
-
[73]
Joni Salminen, Hind Almerekhi, Milica Milenković, Soon-gyo Jung, Jisun An, Haewoon Kwak, and Bernard Jansen. 2018. Anatomy of Online Hate: Developing a Taxonomy and Machine Learning Models for Identifying and Classifying Hate in Online News Media.Proceedings of the International AAAI Conference on Web and Social Media12, 1 (Jun. 2018), 330–339. doi:10.160...
-
[74]
Joni Salminen, Fabio Veronesi, Hind Almerekhi, Soon-Gvo Jung, and Bernard J. Jansen. 2018. Online Hate Interpretation Varies by Country, But More by Individual: A Statistical Analysis Using Crowdsourced Ratings. In2018 Fifth International Conference on Social Networks Analysis, Management and Security (SNAMS). Institute of Electrical and Electronics Engin...
-
[75]
Sebastin Santy, Jenny Liang, Ronan Le Bras, Katharina Reinecke, and Maarten Sap. 2023. NLPositionality: Characterizing Design Biases of Datasets and Models. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki (Eds.). Association for Computati...
-
[76]
Maarten Sap, Dallas Card, Saadia Gabriel, Yejin Choi, and Noah A. Smith. 2019. The Risk of Racial Bias in Hate Speech Detection. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Anna Korhonen, David Traum, and Lluís Màrquez (Eds.). Association for Computational Linguistics, Florence, Italy, 1668–1678. doi:10.18653...
-
[77]
Maarten Sap, Swabha Swayamdipta, Laura Vianna, Xuhui Zhou, Yejin Choi, and Noah A. Smith. 2022. Annotators with Attitudes: How Annotator Beliefs And Identities Bias Toxic Language Detection. InProceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Marine Carpuat, Mari...
-
[78]
Julia Schuster. 2013. Invisible feminists? Social media and young women’s political participation.Political Science65, 1 (2013), 8–24. arXiv:https://doi.org/10.1177/0032318713486474 doi:10.1177/0032318713486474
-
[79]
Farhana Shahid and Aditya Vashistha. 2023. Decolonizing Content Moderation: Does Uniform Global Community Standard Resemble Utopian Equality or Western Power Hegemony?. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems(Hamburg, Germany) (CHI ’23). Association for Computing Machinery, New York, NY, USA, Article 391, 18 pages. d...
-
[80]
Taylor Sorensen, Jared Moore, Jillian Fisher, Mitchell L Gordon, Niloofar Mireshghallah, Christopher Michael Rytting, Andre Ye, Liwei Jiang, Ximing Lu, Nouha Dziri, Tim Althoff, and Yejin Choi. 2024. Position: A Roadmap to Pluralistic Alignment. InProceedings of the 41st International Conference on Machine Learning (Proceedings of Machine Learning Researc...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.