Recognition: unknown
Defragmenting Language Models: An Interpretability-based Approach for Vocabulary Expansion
Pith reviewed 2026-05-10 08:12 UTC · model grok-4.3
The pith
Interpretability-based methods for vocabulary expansion offer a superior performance-token efficiency trade-off for non-Latin script languages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
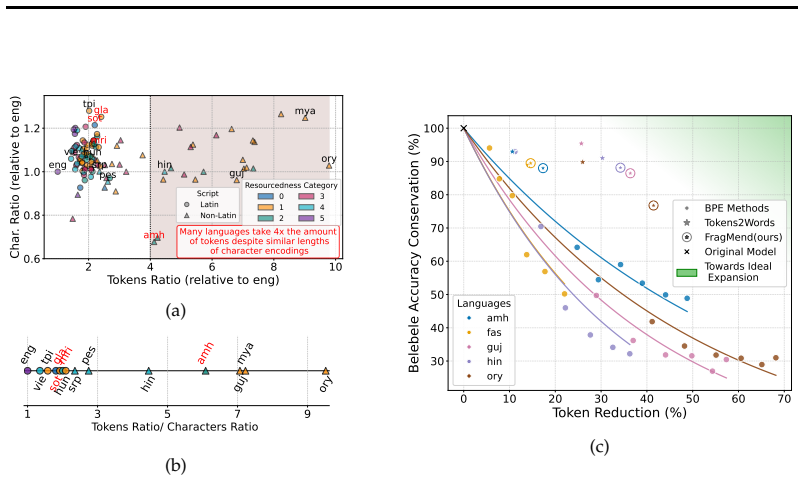
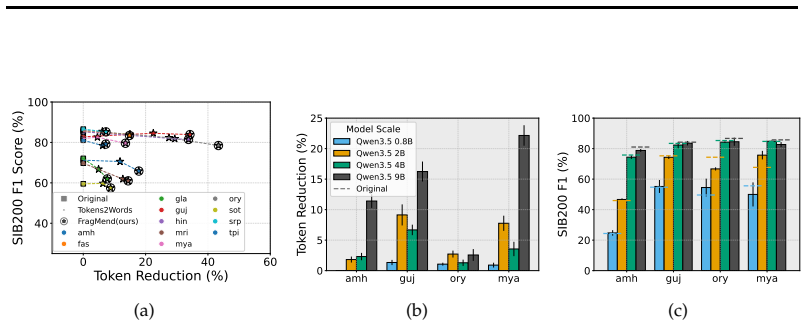
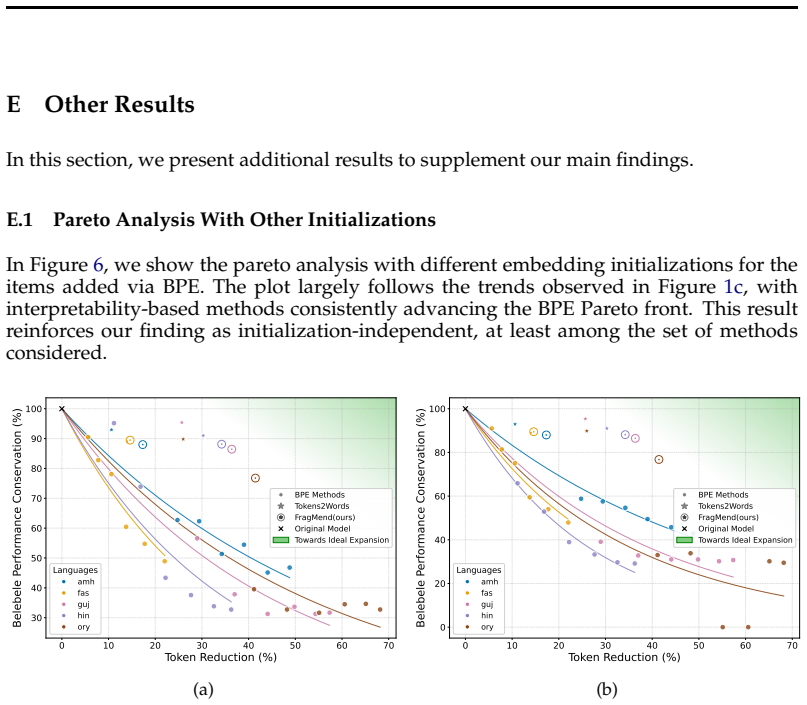
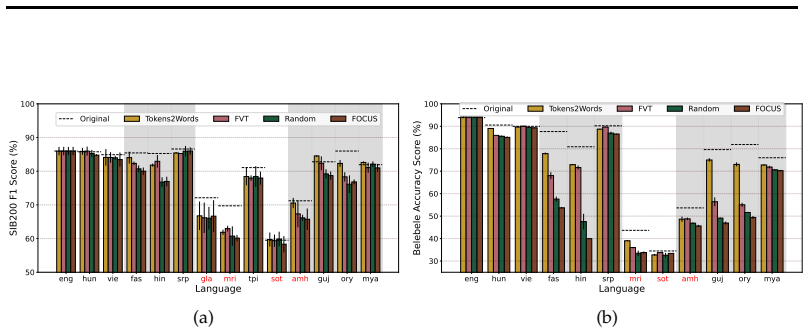
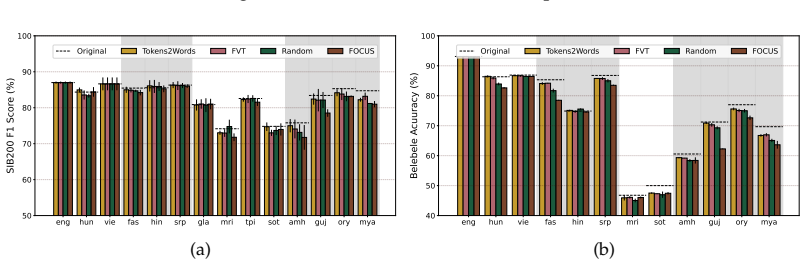
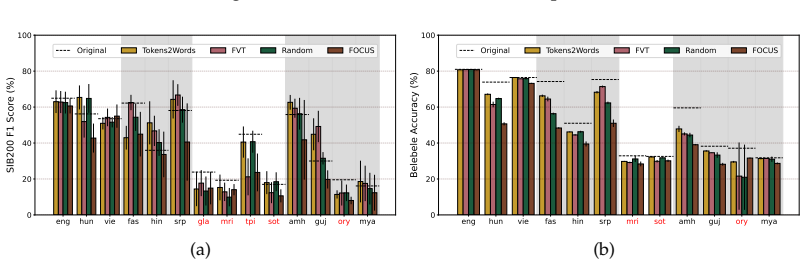
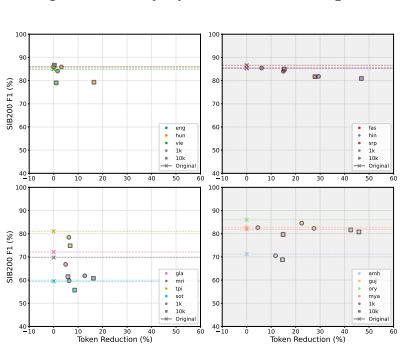
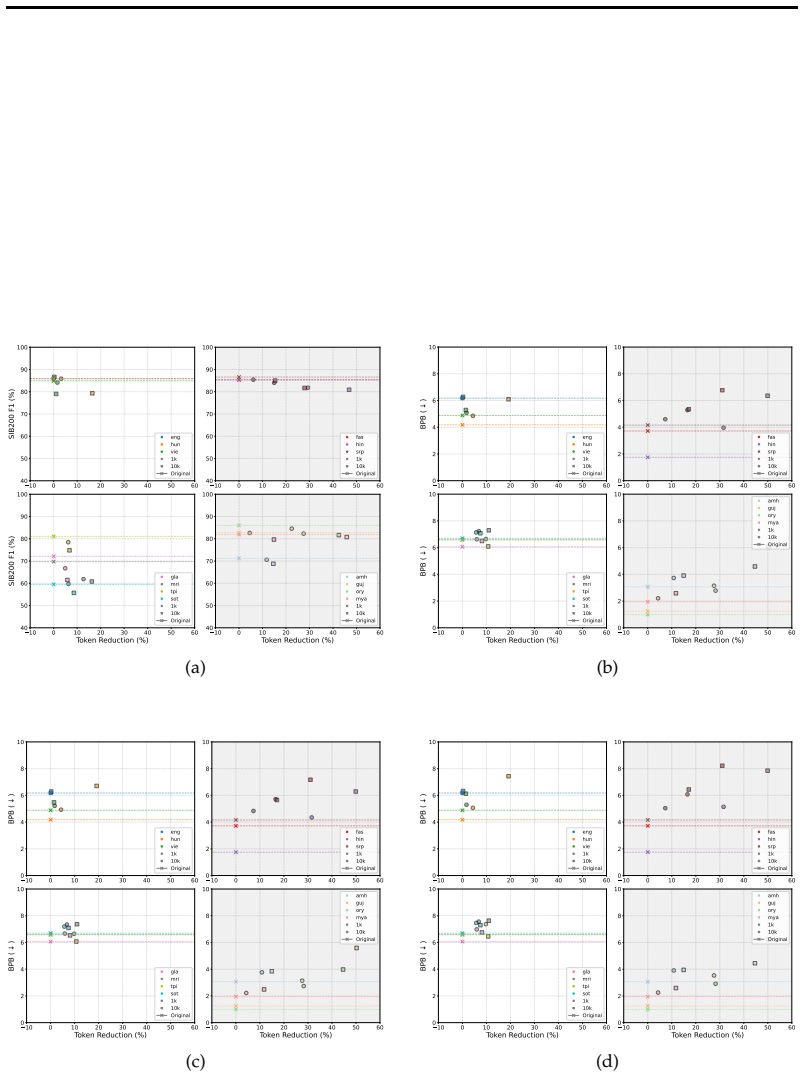
Models exhibit subword detokenization, progressively combining fragmented tokens into larger units through their layers. This pattern informs both the selection of new vocabulary items and the initialization of their embeddings, leading to better token efficiency than frequency-based baselines, with gains of around 20 points on non-Latin languages. The proposed FragMend method leverages this to further optimize the expansion process.
What carries the argument
Subword detokenization, the phenomenon where language models merge fragmented subword tokens into larger subwords across successive layers, which guides the initialization of new embeddings.
If this is right
- Interpretability-based item selection provides a better performance-token efficiency trade-off than frequency-based methods.
- Interpretability-based embedding initialization yields large performance gains for non-Latin script languages.
- The FragMend method further improves the efficiency ceiling of such expansions.
- These approaches address token over-fragmentation in modern open-weight LLMs.
Where Pith is reading between the lines
- Applying similar interpretability analysis could help in expanding vocabularies for other underrepresented languages or domains.
- Reducing token counts this way might lower the overall computational cost of deploying multilingual models.
- Future work could test if these initialization strategies transfer across different model architectures without retraining.
Load-bearing premise
The subword detokenization pattern is stable and general enough across models to guide embedding initialization without introducing new fragmentation or instability.
What would settle it
Observing that FragMend-initialized models show no improvement or worse token efficiency on a test set of non-Latin languages compared to frequency-based initialization would falsify the central claim.
Figures















read the original abstract
All languages are equal; when it comes to tokenization, some are more equal than others. Tokens are the hidden currency that dictate the cost and latency of access to contemporary LLMs. However, many languages written in non-Latin scripts observe a poor exchange rate: LLMs take several multiples of tokens to encode the same information in many languages as they do for English. Our analysis reveals that this issue, known as 'token over-fragmentation', persists in modern open-weight LLMs. The standard remedy is vocabulary expansion that adds target language items missing from the model's vocabulary. In this work, we comprehensively study and advance interpretability-based vocabulary expansion, a new research direction. We focus on two core decisions in the vocabulary expansion process: What items should we add? and How should we initialize their corresponding input and output embeddings? First, we question the conventional use of frequency-based methods to choose candidate vocabulary items to add (a decision long treated as settled), and show that interpretability-based methods offer a superior performance-token efficiency trade-off. Next, we strengthen the case for interpretability-based embedding initialization by showing large gains (~20 pts) over baseline initialization methods for several languages written in non-Latin scripts. We identify the phenomenon of "subword detokenization" where models progressively merge fragmented subword tokens into larger subwords across layers. Grounded in our analysis of this phenomenon, we propose FragMend to further push the efficiency ceiling of interpretability-based expansion. We validate the effectiveness of FragMend through comparison against strong baselines and we present extensive analysis of its design choices.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that token over-fragmentation in non-Latin script languages persists in modern LLMs and can be addressed via interpretability-based vocabulary expansion. It shows that interpretability signals outperform frequency-based methods for item selection in the performance-token trade-off, identifies the 'subword detokenization' phenomenon (progressive merging of subwords across layers), proposes FragMend for embedding initialization grounded in this analysis, and reports ~20pt gains over baselines for several non-Latin languages along with design-choice analysis.
Significance. If the empirical claims hold, the work offers a concrete advance in multilingual LLM efficiency by shifting from surface-frequency heuristics to model-internal signals for both item selection and initialization. The identification of subword detokenization as a reusable phenomenon and the FragMend proposal are potentially high-impact for reducing token costs in underrepresented languages. The manuscript includes direct comparisons to strong baselines and extensive design analysis, which strengthen its contribution.
major comments (3)
- The central claim that interpretability-based item selection and FragMend initialization yield a superior performance-token efficiency trade-off rests on the generality of subword detokenization, yet the analysis provides no quantitative bounds on its prevalence, layer-wise consistency, variance across checkpoints, or sensitivity to tokenizer choice; without these, it is unclear whether the observed pattern is stable enough to guide initialization without reintroducing fragmentation or instability.
- The reported ~20pt gains for non-Latin scripts are presented without error bars, statistical significance tests, or detailed dataset splits and language coverage; this omission directly affects verifiability of the superiority claim over baseline initialization methods.
- In the FragMend validation, the assumption that merging-based initialization avoids new fragmentation is not tested via ablations on cross-layer stability or post-expansion training dynamics, leaving the efficiency-ceiling improvement vulnerable to the weakest assumption identified in the work.
minor comments (2)
- The abstract refers to 'strong baselines' and 'extensive analysis of its design choices' without naming the baselines or summarizing the key ablation outcomes, which reduces immediate clarity for readers.
- Notation for the performance-token efficiency trade-off metric is introduced without an explicit equation or definition in the early sections, requiring readers to infer it from later experimental descriptions.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below, agreeing where revisions are needed to strengthen the empirical claims and providing clarifications on the existing analysis.
read point-by-point responses
-
Referee: The central claim that interpretability-based item selection and FragMend initialization yield a superior performance-token efficiency trade-off rests on the generality of subword detokenization, yet the analysis provides no quantitative bounds on its prevalence, layer-wise consistency, variance across checkpoints, or sensitivity to tokenizer choice; without these, it is unclear whether the observed pattern is stable enough to guide initialization without reintroducing fragmentation or instability.
Authors: We agree that additional quantitative characterization would strengthen the foundation for FragMend. The manuscript already demonstrates the phenomenon through layer-wise merging patterns and cross-model examples, but we will expand the analysis in revision to include explicit prevalence metrics (e.g., percentage of subwords showing progressive detokenization), layer-wise consistency scores, variance across multiple checkpoints, and sensitivity tests to alternative tokenizers. These additions will directly address the stability concerns. revision: yes
-
Referee: The reported ~20pt gains for non-Latin scripts are presented without error bars, statistical significance tests, or detailed dataset splits and language coverage; this omission directly affects verifiability of the superiority claim over baseline initialization methods.
Authors: We acknowledge that the current presentation lacks the statistical details needed for full verifiability. The gains are measured on standard multilingual benchmarks with consistent language sets, but in the revised manuscript we will report error bars from multiple runs, conduct statistical significance tests (e.g., paired t-tests), and provide explicit details on dataset splits, exact language coverage, and evaluation protocols to allow direct replication and comparison. revision: yes
-
Referee: In the FragMend validation, the assumption that merging-based initialization avoids new fragmentation is not tested via ablations on cross-layer stability or post-expansion training dynamics, leaving the efficiency-ceiling improvement vulnerable to the weakest assumption identified in the work.
Authors: We recognize the value of targeted ablations for this assumption. While the manuscript validates FragMend through direct performance comparisons and design-choice sweeps against strong baselines, we will add new experiments in revision that track cross-layer token stability post-initialization and monitor fragmentation metrics during continued training. These ablations will test whether the merging-based approach preserves or improves stability over time. revision: yes
Circularity Check
No significant circularity; empirical comparisons stand independently
full rationale
The paper's core contributions are empirical: comparative evaluations of item selection and embedding initialization methods, plus observation of layer-wise subword merging patterns used to motivate FragMend. No load-bearing equations, fitted parameters, or self-citations reduce the reported ~20pt gains or efficiency claims to quantities defined by the method itself. The subword detokenization phenomenon is presented as an analysis result drawn from model internals, not a self-referential definition or ansatz smuggled via prior work. The derivation chain remains self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
invented entities (1)
-
subword detokenization
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Fast Vocabulary Transfer for Language Model Compression
ISSN 0898-9788. 12 Leonidas Gee, Andrea Zugarini, Leonardo Rigutini, and Paolo Torroni. Fast Vocabu- lary Transfer for Language Model Compression. In Yunyao Li and Angeliki Lazari- dou (eds.),Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing: Industry Track, pp. 409–416, Abu Dhabi, UAE, December 2022. Associa- tion for...
-
[2]
Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates
URLhttps://openreview.net/forum?id=328vch6tRs. Seungduk Kim, Seungtaek Choi, and Myeongho Jeong. Efficient and Effective Vocabulary Expansion Towards Multilingual Large Language Models, 2024. URL https://arxiv. org/abs/2402.14714. 13 Taku Kudo. Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates. In Iryna G...
-
[3]
Association for Computational Linguistics. doi: 10.18653/v1/D18-2012. URL https://aclanthology.org/D18-2012/. Vedang Lad, Wes Gurnee, and Max Tegmark. The Remarkable Robustness of LLMs: Stages of Inference? InICML 2024 Workshop on Mechanistic Interpretability, 2024. URL https: //openreview.net/forum?id=R5unwb9KPc. Chong Li, Jiajun Zhang, and Chengqing Zon...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/d18-2012 2012
-
[4]
Association for Computational Linguistics. doi: 10.18653/v1/2024.findings-naacl.68. URLhttps://aclanthology.org/2024.findings-naacl.68/. Samuel Marks, Can Rager, Eric J Michaud, Yonatan Belinkov, David Bau, and Aaron Mueller. Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Lan- guage Models. InThe Thirteenth International C...
-
[5]
Association for Computational Linguistics. doi: 10.18653/v1/2022.naacl-main.293. URLhttps://aclanthology.org/2022.naacl-main.293/. Benjamin Minixhofer, Edoardo M Ponti, and Ivan Vuli ´c. Zero-shot Tokenizer Transfer. Advances in Neural Information Processing Systems, 37:46791–46818, 2024. 14 Nandini Mundra, Aditya Nanda Kishore Khandavally, Raj Dabre, Rat...
-
[6]
URLhttps://aclanthology.org/2021.acl-long.243/. Haruki Sakajo, Yusuke Ide, Justin Vasselli, Yusuke Sakai, Yingtao Tian, Hidetaka Kamigaito, and Taro Watanabe. Dictionaries to the Rescue: Cross-Lingual Vocabulary Transfer for Low-Resource Languages Using Bilingual Dictionaries. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar ...
-
[7]
Association for Computational Linguistics. doi: 10.18653/v1/2020.findings-emnlp
-
[8]
URLhttps://aclanthology.org/2020.findings-emnlp.240/. Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, and Colin Raffel. mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer. In Kristina Toutanova, Anna Rumshisky, Luke Zettlemoyer, Dilek Hakkani- Tur, Iz Beltagy, Steven Bethard, Ryan Cotterel...
-
[9]
In language l
study a multi-stage tuning strategy for expanded vocabularies in Korean. Yamaguchi et al. (2026) presents a detailed comparison and analysis of heuristics-based initialization and tuning methods. Hypernetwork-basedinitialization trains networks to directly predict the embeddings of a new vocabulary item, instead of relying on similarity heuristics. Such a...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.