Recognition: unknown
Debate as Reward: A Multi-Agent Reward System for Scientific Ideation via RL Post-Training
Pith reviewed 2026-05-10 07:52 UTC · model grok-4.3
The pith
A multi-agent debate system supplies robust binary rewards for RL-based scientific idea generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
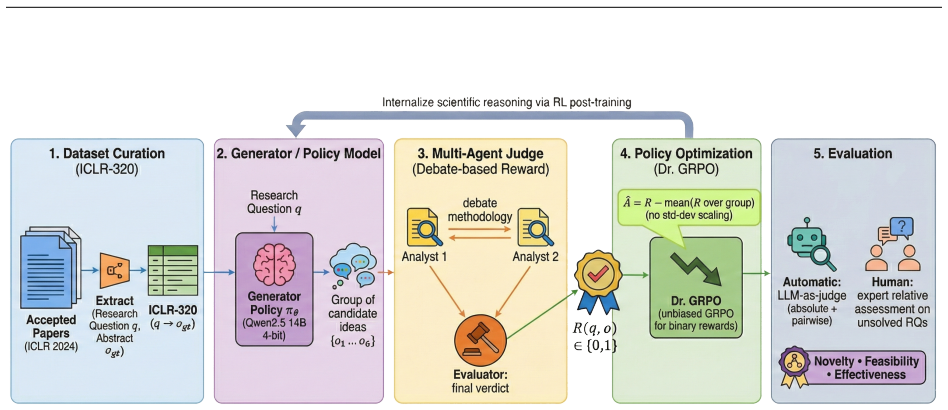
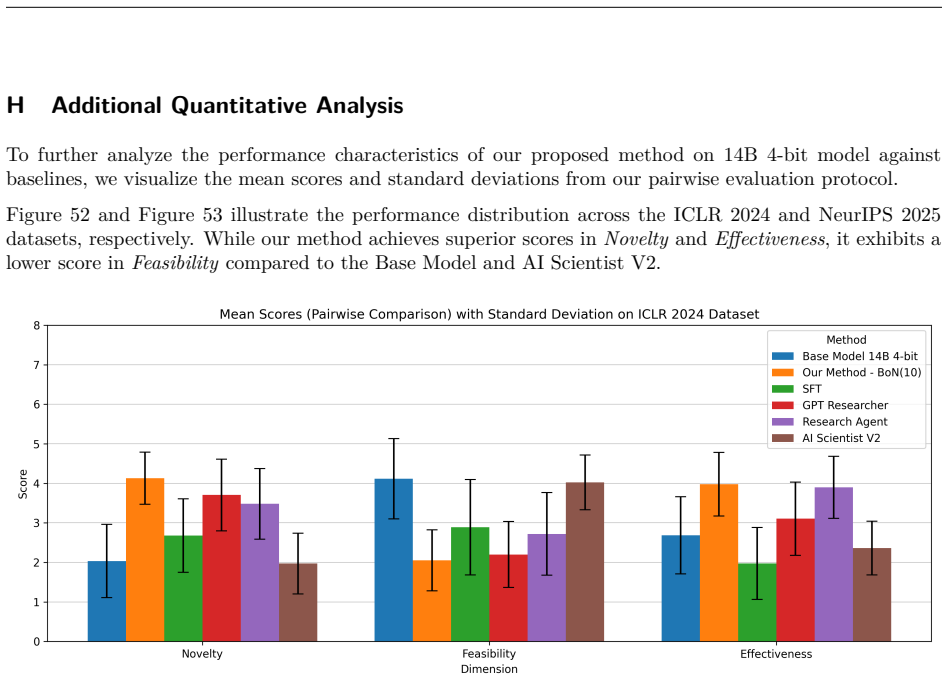
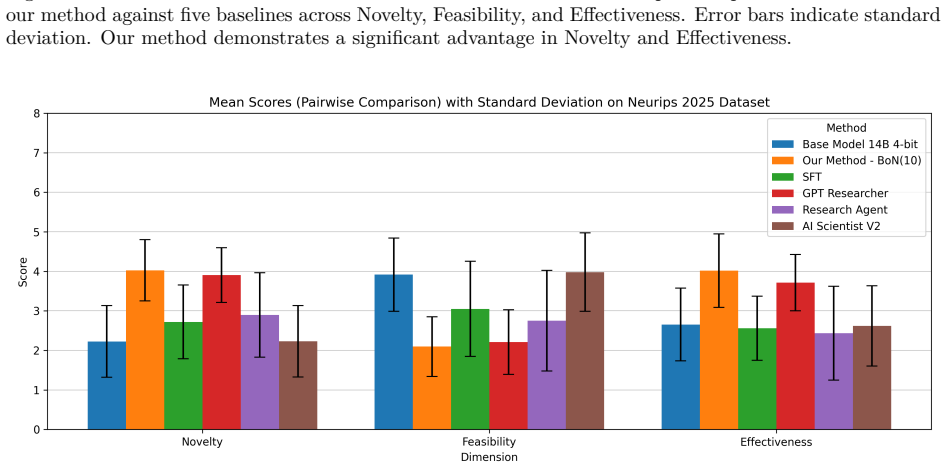
The paper establishes that a multi-agent reward function based on debate can act as an effective judge for scientific ideas in an RL setting, decoupling methodological validation from implementation details and delivering strict binary rewards that resist reward hacking. Optimized with an unbiased Group Relative Policy Optimization on the ICLR-320 dataset, this leads to LLMs that generate ideas outperforming state-of-the-art baselines according to expert evaluations on novelty, feasibility, and effectiveness.
What carries the argument
The multi-agent reward function, which structures debate among agents to validate ideas and assign binary rewards while remaining independent of specific implementation details.
If this is right
- Effective RL optimization becomes possible for open-ended tasks with sparse binary rewards.
- Generated scientific ideas show measurable improvements in quality metrics.
- Length bias in policy optimization is mitigated through the unbiased variant.
- The approach scales training for ideation without complex prompting or inefficient architectures.
Where Pith is reading between the lines
- Similar debate-based rewards could apply to other domains like code generation or creative writing.
- The framework might reduce the need for extensive human oversight in evaluating AI-generated content.
- Testing on datasets from other fields could reveal broader applicability of the method.
Load-bearing premise
That the multi-agent debate process yields binary rewards robust to exploitation by the model and that expert human judgments reliably indicate true scientific innovation.
What would settle it
If a follow-up experiment shows that the trained model produces ideas that experts rate no better than baseline models, or if the reward function can be gamed to give high scores to low-quality ideas.
Figures

















































read the original abstract
Large Language Models (LLMs) have demonstrated potential in automating scientific ideation, yet current approaches relying on iterative prompting or complex multi-agent architectures often suffer from hallucination or computational inefficiency. A critical bottleneck in applying Reinforcement Learning (RL) to this open-ended domain is reward hacking -- where models exploit imperfect evaluation proxies to maximize scores without producing genuine scientific innovation. To address these limitations, we propose an RL framework explicitly tailored for high-quality scientific idea generation. We propose the first multi-agent reward function designed to serve as a judge, decoupling methodological validation from implementation details while providing strict binary rewards that are robust to reward hacking. To effectively optimize against this sparse signal, we utilize an unbiased variant of Group Relative Policy Optimization to mitigate artificial length bias. We grounded our training in ICLR-320, a curated dataset of problem-solution pairs extracted from ICLR 2024 proceedings. Experiments demonstrate that our framework significantly outperforms state-of-the-art baselines across expert-evaluated metrics of novelty, feasibility, and effectiveness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an RL post-training framework for LLM-based scientific ideation that uses a multi-agent debate system to generate strict binary rewards, decoupling methodological validation from implementation details and claiming robustness to reward hacking. It employs an unbiased variant of Group Relative Policy Optimization to optimize against this sparse signal, trains on a curated ICLR-320 dataset of problem-solution pairs from ICLR 2024, and reports significant outperformance over state-of-the-art baselines on expert-evaluated metrics of novelty, feasibility, and effectiveness.
Significance. If the empirical claims hold after proper validation, the work could advance RL applications to open-ended scientific tasks by offering a more reliable alternative to iterative prompting or complex multi-agent setups prone to hallucination. The emphasis on binary rewards from debate and unbiased optimization addresses a recognized bottleneck in reward design for creative generation.
major comments (4)
- Abstract: The headline claim of significant outperformance on novelty, feasibility, and effectiveness is presented without any mention of statistical tests, number of expert raters, baseline implementations, or dataset construction details, rendering it impossible to evaluate whether the metrics support the central assertion.
- Abstract and reward-function description: The multi-agent reward is stated to deliver 'strict binary rewards that are robust to reward hacking,' yet no formal argument, adversarial attack experiments, or ablation removing the multi-agent component is referenced, which is load-bearing for attributing gains to the proposed framework rather than to the RL setup itself.
- Experiments section: Expert human ratings are treated as ground truth for scientific quality, but the manuscript provides no information on blinding, inter-rater reliability statistics, or controls for presentation bias, leaving open the possibility that observed deltas reflect evaluator artifacts rather than genuine ideation improvements.
- Optimization section: The 'unbiased variant of Group Relative Policy Optimization' is introduced to mitigate length bias with the sparse binary signal, but no equations, derivation of unbiasedness, or comparison to standard GRPO are supplied, making it unclear whether the optimization is correctly specified for the reward structure.
minor comments (2)
- Abstract: Acronyms RL and GRPO appear without initial expansion; the dataset name 'ICLR-320' is introduced without a brief description of its construction or scale.
- Overall: Several claims about decoupling validation from implementation would benefit from a concrete example or pseudocode in the method section to improve clarity for readers.
Simulated Author's Rebuttal
We thank the referee for their constructive comments and recommendations. We address each of the major comments in detail below, indicating the revisions we plan to make to the manuscript.
read point-by-point responses
-
Referee: Abstract: The headline claim of significant outperformance on novelty, feasibility, and effectiveness is presented without any mention of statistical tests, number of expert raters, baseline implementations, or dataset construction details, rendering it impossible to evaluate whether the metrics support the central assertion.
Authors: We agree that including these details in the abstract would improve transparency. In the revised manuscript, we will update the abstract to reference the statistical tests conducted, the number of expert raters involved in the evaluation, and key information about the baseline implementations and the construction of the ICLR-320 dataset. These elements are described in the Experiments section, and we will ensure the abstract provides sufficient context for the claims. revision: yes
-
Referee: Abstract and reward-function description: The multi-agent reward is stated to deliver 'strict binary rewards that are robust to reward hacking,' yet no formal argument, adversarial attack experiments, or ablation removing the multi-agent component is referenced, which is load-bearing for attributing gains to the proposed framework rather than to the RL setup itself.
Authors: The robustness claim stems from the requirement for multi-agent consensus in generating binary rewards, which we believe makes reward hacking more challenging than with single-agent or scalar reward systems. However, we acknowledge the lack of formal arguments or specific experiments supporting this. We will revise the reward-function description to include a more detailed rationale and add an ablation study comparing the full multi-agent reward system to a single-agent baseline to better attribute the performance gains. revision: partial
-
Referee: Experiments section: Expert human ratings are treated as ground truth for scientific quality, but the manuscript provides no information on blinding, inter-rater reliability statistics, or controls for presentation bias, leaving open the possibility that observed deltas reflect evaluator artifacts rather than genuine ideation improvements.
Authors: We recognize the critical need for rigorous human evaluation protocols. The current version of the manuscript does not detail these aspects. In the revision, we will add information on the blinding procedures used, report inter-rater reliability statistics such as agreement rates or kappa coefficients, and describe controls implemented to mitigate presentation bias, such as standardized formatting of ideas presented to raters. revision: yes
-
Referee: Optimization section: The 'unbiased variant of Group Relative Policy Optimization' is introduced to mitigate length bias with the sparse binary signal, but no equations, derivation of unbiasedness, or comparison to standard GRPO are supplied, making it unclear whether the optimization is correctly specified for the reward structure.
Authors: We agree that the optimization method requires a more formal presentation. We will expand the Optimization section in the revised manuscript to include the relevant equations for the unbiased GRPO variant, provide a derivation of its unbiasedness property in the context of sparse binary rewards, and include a direct comparison to the standard GRPO algorithm to clarify its specification and advantages for this task. revision: yes
Circularity Check
No circularity: empirical outperformance claims rely on external dataset and baselines
full rationale
The paper describes an RL post-training framework with a proposed multi-agent reward function, trained on the external ICLR-320 dataset extracted from ICLR 2024 proceedings, and evaluated via expert human ratings against state-of-the-art baselines. No equations, derivations, or self-citations are referenced in the abstract or provided text that would reduce any claimed result (such as novelty/feasibility/effectiveness scores) to a fitted parameter or prior input by construction. The central results are presented as empirical comparisons to independent benchmarks rather than tautological redefinitions or self-referential predictions. This matches the default expectation for non-circular empirical work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A multi-agent debate process can produce strict binary rewards for scientific ideas that are robust against reward hacking.
Forward citations
Cited by 1 Pith paper
-
Reinforcement Learning for LLM-based Multi-Agent Systems through Orchestration Traces
This survey organizes RL for LLM multi-agent systems into reward families, credit units, and five orchestration sub-decisions, notes the absence of explicit stopping-decision training in its paper pool, and releases a...
Reference graph
Works this paper leans on
-
[1]
URLhttps://doi.org/10.48550/arXiv.2503.19257. Long Li, Weiwen Xu, Jiayan Guo, Ruochen Zhao, Xingxuan Li, Yuqian Yuan, Boqiang Zhang, Yuming Jiang, Yifei Xin, Ronghao Dang, Yu Rong, Deli Zhao, Tian Feng, and Lidong Bing. Chain of ideas: Revolutionizing research via novel idea development with LLM agents. In Christos Christodoulopou- los, Tanmoy Chakraborty...
-
[2]
Understanding R1-Zero-Like Training: A Critical Perspective
URLhttps://doi.org/10.48550/arXiv.2503.20783. 11 Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. The AI scientist: Towards fully automated open-ended scientific discovery.arXiv preprint arXiv:2408.06292, 2024. URL https://doi.org/10.48550/arXiv.2408.06292. Maxime Robeyns and Laurence Aitchison. Improving llm-generated cod...
-
[3]
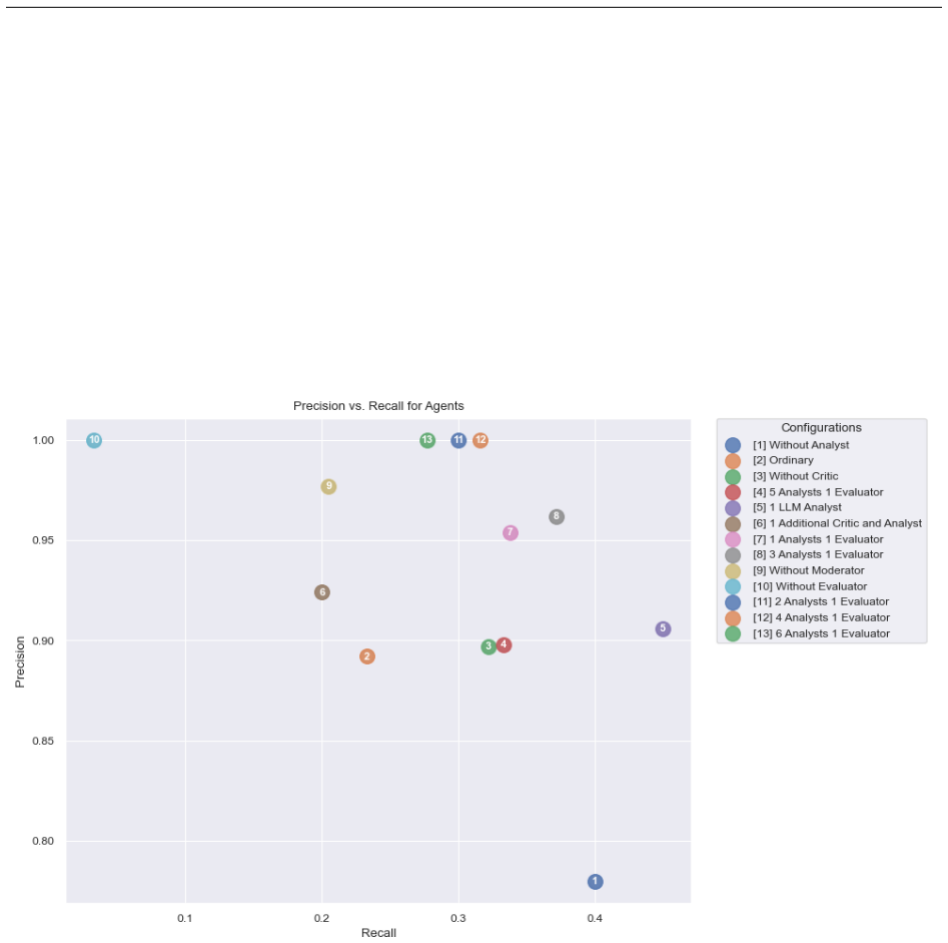
Configuration [11] (2 Analysts + 1 Evaluator) represents the optimal trade-off chosen for the main pipeline, achieving perfect precision (1.0) with robust recall (0.300)
nearly eliminates recall. Configuration [11] (2 Analysts + 1 Evaluator) represents the optimal trade-off chosen for the main pipeline, achieving perfect precision (1.0) with robust recall (0.300). 17 F Prompts System Prompt: Survey Classifier You are an expert research assistant. Your task is to determine if a research paper is a SUR- VEY/REVIEW paper, a ...
-
[4]
paper_type
If the paper mainly reviews, surveys, or summarizes existing work then it is a SURVEY ("paper_type": "survey")
-
[5]
paper_type
If the paper introduces a new method, model, algorithm, framework, or experimental setup then it is a NEW IDEA ("paper_type": "new_idea")
-
[6]
paper_type
If the paper does not introduce a new method but instead focuses on evaluating, testing, bench- marking, or stress-testing existing methods on certain tasks or datasets, then it is an EVALUATION paper ("paper_type": "evaluation"). Output format:
-
[7]
First write your reasoning step by step
-
[8]
paper_type
Then give the final answer in strict JSON format, for example: {"paper_type": "survey"} {"paper_type": "new_idea"} {"paper_type": "evaluation"} Don’t forget to tell your reasoning. Figure 4: The system prompt used to classify whether a paper contains new ideas or is a survey or evaluation paper. User Prompt: Survey Classifier Here is the title of the pape...
-
[9]
Core Problem: [Synthesize the main challenge]
-
[10]
Gap/Opportunity: [State the specific gap inferred from the question]
-
[11]
‘json). JSON SCHEMA: {
Bridge: [Explain how your idea connects the gap to a solution] </reasoning> <answer> [Your specific and actionable research idea, focusing on the proposed method] </answer> Figure 8: The full system prompt used for the Idea Generation Policy. 20 User Prompt: Idea Generation Policy Research Question: {research_question} Based on the instructions, please sy...
-
[12]
If any participant attempts this, issue a clear warning
The discussion mustnotcompare the Abstract and the Generated Idea based on data pipelines or evaluation setups. If any participant attempts this, issue a clear warning
-
[13]
Ensure they compare concrete components — algorithms, frameworks — and that they do not compare the datasets and evaluation process
-
[14]
If the Generated Idea contains placeholder text or fails to propose a substantial or meaningful solution to the stated Research Question, immediately halt the discussion and notify all partici- pants
-
[15]
You act as a moderator — your job is to guide and manage the conversation ensuring it stays focused and methodologically sound
You arenota participant in the discussion. You act as a moderator — your job is to guide and manage the conversation ensuring it stays focused and methodologically sound. Figure 14: The system prompt used for theModerator Agent, tasked with guiding the discussion and enforcing methodological alignment. User Prompt: The Moderator Agent {history} Round{roun...
-
[16]
– If your current assessment differs from your prior view explicitly explain why your opinion evolved
Carefullyreviewthepreviousdiscussionsandyourownearlieropinionstoensurecontinuityandconsistency in reasoning. – If your current assessment differs from your prior view explicitly explain why your opinion evolved
-
[17]
Identify the core methodological elements and novel contributions in the Abstract — such as models, algorithms, architectures, and assumptions
-
[18]
Compare each core methodological or conceptual element of the Abstract against the Generated Idea
-
[19]
Highlight any misalignment or omission, such as when a critical component from the Abstract is absent, replaced, or contradicted in the Generated Idea
-
[20]
Pay extra attention to specific innovations or contributions rather than general context, background, or motivation
-
[21]
– Provide analytical reasoning when commenting, always grounded in methodological evidence
Engage with other persons by commenting on their observations: – You may agree, partially agree, or respectfully disagree. – Provide analytical reasoning when commenting, always grounded in methodological evidence. – If another person’s reasoning is unclear, inconsistent or off-topic, politely request clarification. Your Output Should Include: •A clear li...
-
[22]
– Ensure consistency with your earlier assessments, or clearly explain any evolution in your stance
Review prior discussions and your own previous opinions before providing a new one. – Ensure consistency with your earlier assessments, or clearly explain any evolution in your stance
-
[23]
– Do not consider datasets, data pipelines, evaluation setups, or metrics for comparison
IdentifytheAbstract’scoremethodologicalassumptionsandapproach—includingtheoreticalfoundations, modeling frameworks, or algorithmic strategies. – Do not consider datasets, data pipelines, evaluation setups, or metrics for comparison
-
[24]
– Explicitly point out contradictions or incompatible assumptions
Compare these elements with the Generated Idea: – Highlight any missing, altered, or replaced methodological aspects. – Explicitly point out contradictions or incompatible assumptions
-
[25]
– Provide concise, evidence-based commentary that either supports or challenges their reasoning
Engage with other agents constructively: – You may agree, partially agree, or respectfully disagree with their analysis. – Provide concise, evidence-based commentary that either supports or challenges their reasoning. – If another participant’s comment is vague or off-topic, request clarification politely. Your Output Should Include: •A list or brief summ...
-
[26]
– Briefly capture the essence of their arguments and reasoning
Begin by reviewing and summarizing the prior discussion among people (Analyst, Critic, Moder- ator, etc.). – Briefly capture the essence of their arguments and reasoning. – Consider the reasoning and arguments made by all participants (Analyst, Critic, Moderator, etc.). – Extract each participant’s individual opinion (e.g., match or not match) and reasoni...
-
[27]
– Ignore datasets, metrics, or evaluation setups as comparison factors
After summarizing, perform your own evaluation: – Focus solely onmethodologyandcore contributions. – Ignore datasets, metrics, or evaluation setups as comparison factors
-
[28]
Determine alignment: Decide whether the Abstract and the Generated Idea express essentially the same core methodological logic and contributions
-
[29]
Provide a final, concise judgment reflecting both the discussion summary and your reasoning
-
[30]
‘json {
Justify your conclusion: Provide a brief, evidence-based explanation that reflects the entire dis- cussion history. Output Format:After writing the summarization and your reasoning, return your answer strictly in the following JSON format: <summarization> Your summarization </summarization> <reasoning> Your reasoning </reasoning> “‘json { "reason": "short...
-
[31]
•Extract each participant’s stance (match or not match) and key reasoning
First summarize the discussion among participants and write it down. •Extract each participant’s stance (match or not match) and key reasoning. •State whether they generally agree or disagree
-
[32]
reason":
Then, make your own evaluation strictly based onmethodologyandcore contributionsand write your reasoning. •Ignore dataset, metrics, and evaluation setups. •If the Generated Idea captures themain ideaandcentral logicof the Abstract, even with small or secondary differences, mark it as a match. •Mark it as not a match if it diverges from or contradicts the ...
-
[34]
Provide thorough reasoning explaining how the methods compare on each criterion before indicating which method is superior
Two proposed methods (Method A and Method B) to address that question Your role is to compare these methods based on three criteria:Novelty,Feasibility, andEffectiveness. Provide thorough reasoning explaining how the methods compare on each criterion before indicating which method is superior. Evaluation Criteria
-
[35]
•Task:Compare which method demonstrates greater originality, introduces more innovative concepts, or combines ideas in more unprecedented ways
Novelty •Definition:The degree to which the proposed method introduces new concepts, approaches, or perspec- tives that differ from existing work in the field. •Task:Compare which method demonstrates greater originality, introduces more innovative concepts, or combines ideas in more unprecedented ways
-
[36]
•Task:Comparewhichmethodismorepracticaltoimplement, requiresfewerresources, facesfewertechnical barriers, or has a more realistic timeline
Feasibility •Definition:The practical viability of implementing the proposed method given current technological capabilities, resource requirements, time constraints, and technical complexity. •Task:Comparewhichmethodismorepracticaltoimplement, requiresfewerresources, facesfewertechnical barriers, or has a more realistic timeline
-
[37]
A"- Method A is clearly better •
Effectiveness •Definition:The expected capability of the method to adequately address the research question and produce meaningful, reliable results that advance scientific understanding. •Task:Compare which method better addresses the research question, is more likely to produce robust results, or has stronger scientific methodology. Comparison Values Fo...
-
[38]
A scientific research question
-
[39]
Provide thorough reasoning for each criterion before assigning scores
A proposed method or idea to address that question Your role is to critically assess the proposed method based on three criteria:Novelty,Feasibility, and Effectiveness. Provide thorough reasoning for each criterion before assigning scores. Evaluation Criteria
-
[40]
•5 (Highly Novel):Introduces groundbreaking concepts or paradigm-shifting approaches not previously explored
Novelty (1-5) •Definition:The degree to which the proposed method introduces new concepts, approaches, or perspectives that differ from existing work in the field. •5 (Highly Novel):Introduces groundbreaking concepts or paradigm-shifting approaches not previously explored. •4 (Novel):Presents fresh perspectives or modifications that significantly advance ...
-
[41]
•5 (Highly Feasible):Can be readily implemented with existing resources and technology
Feasibility (1-5) •Definition:The practical viability of implementing the proposed method given current technological capabilities and resources. •5 (Highly Feasible):Can be readily implemented with existing resources and technology. •4 (Feasible):Implementation is practical with reasonable effort. •3 (Moderately Feasible):Presents notable implementation ...
-
[42]
novelty": <1-5>,
Effectiveness (1-5) •Definition:The expected capability of the method to adequately address the research question. •5 (Highly Effective):Directly and comprehensively addresses all aspects of the research question. •4 (Effective):Addresses the core research question well. •3 (Moderately Effective):Partially addresses the research question. •2 (Minimally Ef...
-
[43]
Train an LLM to simulate neural activity patterns inspired by the holonomic brain theory, focusing on distributed memory and interference patterns
-
[44]
Incorporate concreteness scores for input and output text segments, ensuring the model penalizes responses that deviate from human-like semantic coherence
-
[45]
Use Representational Similarity Analysis (RSA) to compare the model’s semantic representations with those of humans, as established in Related Paper #6
-
[46]
Implement a scoring mechanism that detects deviations in neural activity patterns simulated by the LLM compared to those observed in human brains, guided by Related Papers #7 and #9
-
[47]
Develop a threshold-based system that flags potential hallucinations when the deviation exceeds predefined thresholds
-
[48]
Use this flagged data to iteratively refine the model’s training, enhancing its ability to mitigate hallucina- tions over time
-
[49]
Evaluate the effectiveness of our method using qualitative and quantitative assessments, including human judgment and benchmark datasets
-
[50]
What supporting evidence leads to this conclusion?
Ensure the method’s generalizability by testing it across various types of LLMs and application domains. Figure 32: Research idea generated for sample 1 by the Research Agent. Example 1: Generated Idea from SFT A framework that monitors the evolution of intermediate representations throughout model generations by computing the KL divergence between distri...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.