Recognition: unknown
LongBench: Evaluating Robotic Manipulation Policies on Real-World Long-Horizon Tasks
Pith reviewed 2026-05-10 07:30 UTC · model grok-4.3
The pith
A new real-world benchmark shows long-horizon robotic policy failures arise from separate execution and contextual sources.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
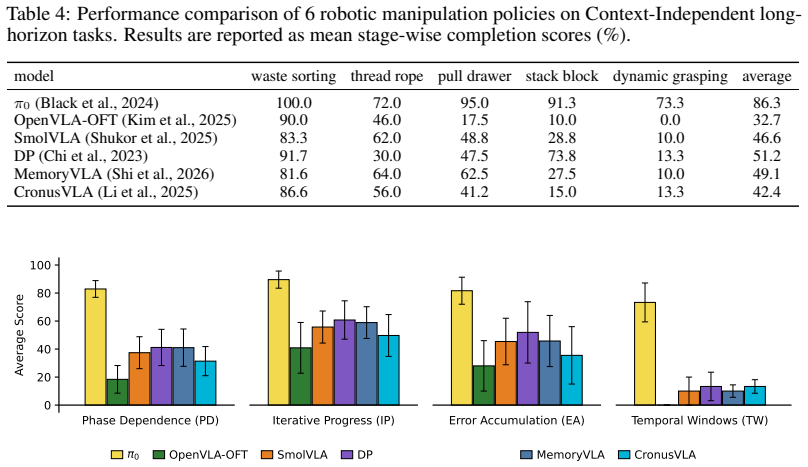
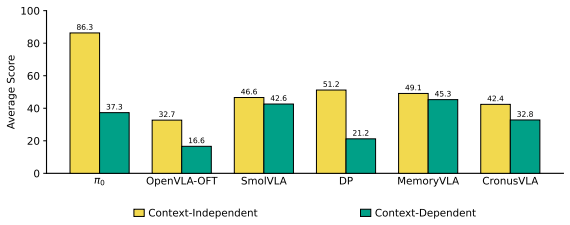
LongBench consists of over 1,000 real-world episodes covering Context-Independent (fully observable) and Context-Dependent (ambiguity-driven) regimes. By grouping tasks into capability- and ambiguity-specific subsets, it supports mechanism-aware evaluation of execution robustness, temporal consistency, and context-dependent reasoning. Tests of six state-of-the-art policies show long-horizon performance is not governed by a single factor, with fully observable settings more strongly tied to execution robustness and contextual difficulty varying across tasks without consistent gains from memory-based methods.
What carries the argument
LongBench benchmark with its Context-Independent and Context-Dependent regimes that organize real-world episodes to isolate execution robustness from contextual reasoning.
If this is right
- Improving execution robustness will raise success rates on fully observable long-horizon tasks.
- Memory-based methods will not produce uniform gains across all context-dependent tasks.
- Future benchmarks should maintain the separation of observable execution challenges from ambiguity-driven ones.
- Policy development can target robustness and contextual reasoning as distinct objectives.
Where Pith is reading between the lines
- Hybrid architectures that pair reliable execution modules with selective memory could address both regimes at once.
- Adding richer perception or external state tracking might shrink the performance gap observed in ambiguous tasks.
- Specialized training regimes for each regime could produce policies that outperform general ones on LongBench.
Load-bearing premise
The selected tasks and collected episodes represent typical real-world long-horizon manipulation challenges and the context-independent versus context-dependent split isolates execution robustness from contextual reasoning.
What would settle it
A new policy that exhibits the same performance degradation pattern in both context-independent and context-dependent tasks, or whose results on LongBench fail to predict outcomes on other real-world long-horizon manipulation scenarios.
Figures





read the original abstract
Robotic manipulation policies often degrade over extended horizons, yet existing benchmarks provide limited insight into why such failures occur. Most prior benchmarks are either simulation-based or report aggregate success, making it difficult to disentangle the distinct sources of temporal difficulty in real-world execution. We introduce LongBench, a real-world benchmark for evaluating long-horizon manipulation. LongBench consists of over 1,000 real-world episodes, covering two complementary regimes: Context-Independent (fully observable) and Context-Dependent (ambiguity-driven). By organizing tasks into capability- and ambiguity-specific subsets, LongBench enables mechanism-aware evaluation of execution robustness, temporal consistency, and context-dependent reasoning. Evaluating six state-of-the-art policies reveals that long-horizon performance is not governed by a single factor. We observe that performance in fully observable settings is more strongly associated with execution robustness, while contextual difficulty varies across tasks and is not consistently improved by memory-based methods. We hope that LongBench serves as a useful benchmark for studying long-horizon manipulation and for developing policies with stronger robustness across both execution and contextual challenges.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LongBench, a real-world benchmark for long-horizon robotic manipulation consisting of over 1,000 episodes. Tasks are organized into Context-Independent (fully observable) and Context-Dependent (ambiguity-driven) regimes to support mechanism-aware evaluation of execution robustness, temporal consistency, and contextual reasoning. Evaluation of six state-of-the-art policies leads to the observation that long-horizon performance is not governed by a single factor, with stronger association to execution robustness in fully observable settings and variable contextual difficulty not consistently improved by memory-based methods.
Significance. If the task collection is representative and the regime split isolates the intended factors, LongBench offers a useful advance over aggregate-success benchmarks by enabling targeted diagnosis of failure modes in real-world manipulation. The scale (>1,000 episodes) and real-world execution are concrete strengths that could support reproducible follow-on studies and policy development focused on robustness.
minor comments (2)
- The abstract states that tasks are organized into capability- and ambiguity-specific subsets, but does not detail the classification criteria or validation procedure; a concise methods subsection on task taxonomy would improve reproducibility.
- The reported associations between performance, execution robustness, and contextual difficulty would be strengthened by explicit statistical tests or confidence intervals rather than qualitative descriptions.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. The report correctly identifies the core contributions of LongBench in separating execution robustness from context-dependent reasoning and in providing a large-scale real-world dataset for mechanism-aware analysis. No specific major comments were listed in the provided referee report.
Circularity Check
No significant circularity
full rationale
This is an empirical benchmark paper that introduces LongBench with over 1,000 real-world episodes and evaluates six external state-of-the-art policies across context-independent and context-dependent regimes. No mathematical derivations, fitted parameters, predictions, or ansatzes appear in the provided text or abstract. The central observations (performance associations with execution robustness and lack of consistent improvement from memory methods) are direct empirical results from the benchmark data rather than quantities defined by the authors' own modeling choices. The work is self-contained against external policy evaluations and does not rely on self-citation chains or uniqueness theorems for its claims.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Tanner, J., Vuong, Q., Walling, A., Wang, H., and Zhilinsky, U. (2024).π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164
work page internal anchor Pith review arXiv 2024
-
[3]
Chi, C., Feng, S., Du, Y ., Xu, Z., Cousineau, E., Burchfiel, B., and Song, S. (2023). Diffusion policy: Visuomotor policy learning via action diffusion. InProceedings of Robotics: Science and Systems (RSS)
2023
-
[4]
Han, S., Qiu, B., Liao, Y ., Huang, S., Gao, C., Yan, S., and Liu, S. (2025). Robocerebra: A large-scale benchmark for long-horizon robotic manipulation evaluation.arXiv preprint
2025
-
[5]
Heo, M., Lee, Y ., Lee, D., and Lim, J. J. (2023). Furniturebench: Reproducible real-world benchmark for long-horizon complex manipulation.Robotics: Science and Systems (RSS)
2023
-
[6]
R., and Davison, A
James, S., Ma, Z., Arrojo, D. R., and Davison, A. J. (2020). Rlbench: The robot learning benchmark and learning environment.arXiv preprint
2020
-
[7]
H., Lu, Y ., Jaykumar P, J., Prabhakaran, B., and Xiang, Y
Khargonkar, N., Allu, S. H., Lu, Y ., Jaykumar P, J., Prabhakaran, B., and Xiang, Y . (2024). Scenereplica: Benchmarking real-world robot manipulation by creating replicable scenes.IEEE International Conference on Robotics and Automation (ICRA)
2024
-
[8]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Kim, M. J., Finn, C., and Liang, P. (2025). Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645
work page internal anchor Pith review arXiv 2025
-
[9]
Li, H., Yang, S., Chen, Y ., Chen, X., Yang, X., Tian, Y ., Wang, H., Wang, T., Lin, D., Zhao, F., and Pang, J. (2025). Cronusvla: Towards efficient and robust manipulation via multi-frame vision-language-action modeling
2025
-
[10]
Liu, B., Zhu, Y ., Gao, C., Feng, Y ., Liu, Q., Zhu, Y ., and Stone, P. (2023). Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems
2023
-
[11]
Mees, O., Hermann, L., Rosete-Beas, E., and Burgard, W. (2022). Calvin: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks.IEEE Robotics and Automation Letters. National Institute of Standards and Technology (2023). Robotic grasping and manipulation competition (rgmc): Manufacturing track
2022
-
[12]
Shi, H., Xie, B., Liu, Y ., Sun, L., Liu, F., Wang, T., Zhou, E., Fan, H., Zhang, X., and Huang, G. (2026). Memoryvla: Perceptual-cognitive memory in vision-language-action models for robotic manipulation
2026
-
[13]
Shukor, M., Aubakirova, D., Capuano, F., Kooijmans, P., Palma, S., Zouitine, A., Aractingi, M., Pascal, C., Russi, M., Marafioti, A., Alibert, S., Cord, M., Wolf, T., and Cadene, R. (2025). Smolvla: A vision-language-action model for affordable and efficient robotics.arXiv preprint arXiv:2506.01844
work page internal anchor Pith review arXiv 2025
-
[14]
Zhang, S., Xu, Z., Liu, P., Yu, X., Li, Y ., Gao, Q., Fei, Z., Yin, Z., Wu, Z., Jiang, Y .-G., and Qiu, X. (2025). Vlabench: A large-scale benchmark for language-conditioned robotics manipulation with long-horizon reasoning tasks. InProceedings of the IEEE/CVF International Conference on Computer Vision. 11
2025
-
[15]
Zheng, L., Yan, F., Liu, F., Feng, C., Kang, Z., and Ma, L. (2024). Robocas: A benchmark for robotic manipulation in complex object arrangement scenarios.arXiv preprint
2024
-
[16]
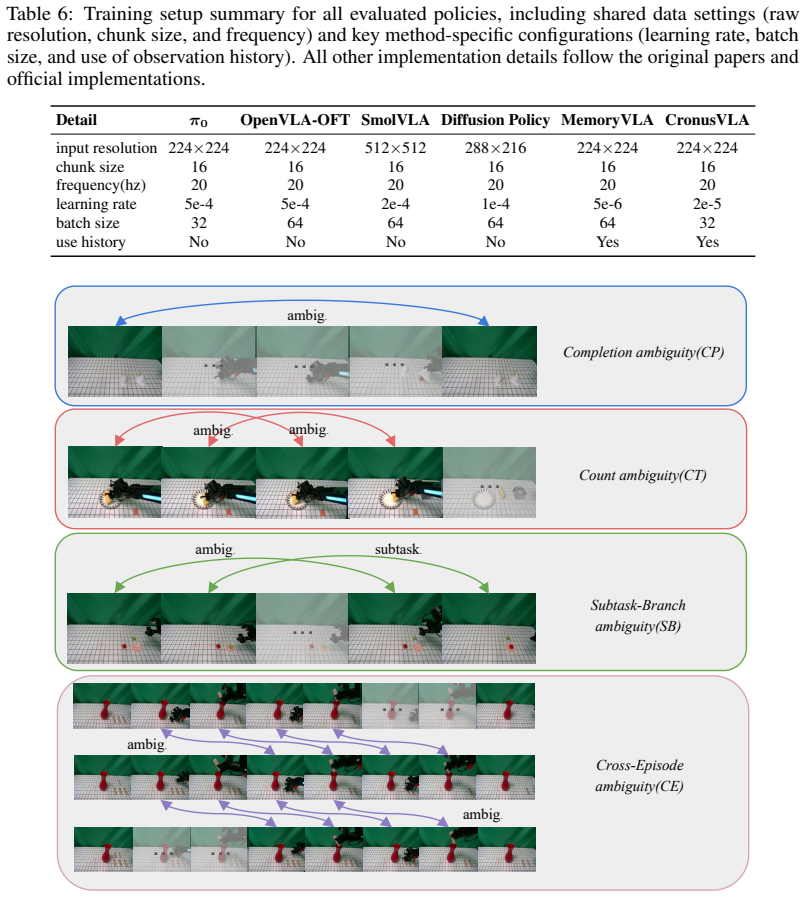
Zhou, Z., Atreya, P., Tan, Y . L., Pertsch, K., and Levine, S. (2025). Autoeval: Autonomous evaluation of generalist robot manipulation policies in the real world.arXiv preprint arXiv:2503.24278. 12 Appendix A Implementation Details For clarity, we summarize the training protocols of all evaluated policies in Table 6. All methods are trained on the same L...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.