Recognition: unknown
When Earth Foundation Models Meet Diffusion: An Application to Land Surface Temperature Super-Resolution
Pith reviewed 2026-05-10 06:59 UTC · model grok-4.3
The pith
Pretrained Earth foundation models can guide diffusion models to reconstruct fine-scale land surface temperatures from 32-times degraded satellite observations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that the EFDiff framework, which encodes high-resolution multispectral reflectance using the Prithvi-EO-2.0 model and injects the resulting embeddings into a diffusion denoising network via cross-attention, enables effective super-resolution of land surface temperature under a 32x scale gap. This conditioning guides the generative process to recover fine-scale structures that are otherwise underdetermined by the degraded thermal observations. Two variants, EFDiff-ε and EFDiff-x0, provide complementary strengths in perceptual quality and pixel fidelity. Experiments on a benchmark of 242,416 co-registered patches show that EFDiff outperforms baselines and that the cross-attent
What carries the argument
Cross-attention injection of geospatial embeddings from the Prithvi-EO-2.0 Earth foundation model into a diffusion model's denoising network to condition generation of high-resolution land surface temperature from degraded inputs.
If this is right
- Super-resolution performance improves consistently across a diverse global dataset when using foundation model guidance.
- Cross-attention conditioning extracts more useful information from the embeddings than simple concatenation of input channels.
- The approach generalizes beyond LST to other remote sensing reconstruction tasks where pretrained representations are available.
- Variants allow selection based on whether perceptual realism or exact pixel values are prioritized.
Where Pith is reading between the lines
- Pretrained models trained on multispectral data may implicitly learn temperature-related spatial patterns that transfer to thermal super-resolution.
- This conditioning strategy could reduce the need for paired high-low resolution training data in future remote sensing applications.
- Extending the framework to other foundation models or modalities might reveal which pretraining objectives best support generative downscaling.
- Testing on real-world operational data streams would show practical utility for environmental monitoring.
Load-bearing premise
Embeddings from the Prithvi-EO-2.0 model encode enough fine-scale geospatial structure to accurately guide land surface temperature reconstruction even when the input thermal data is degraded by a factor of 32.
What would settle it
If EFDiff does not outperform baselines on a new set of co-registered Landsat patches at 32x degradation or if channel concatenation performs better than cross-attention, the advantage of the proposed conditioning would be called into question.
Figures






read the original abstract
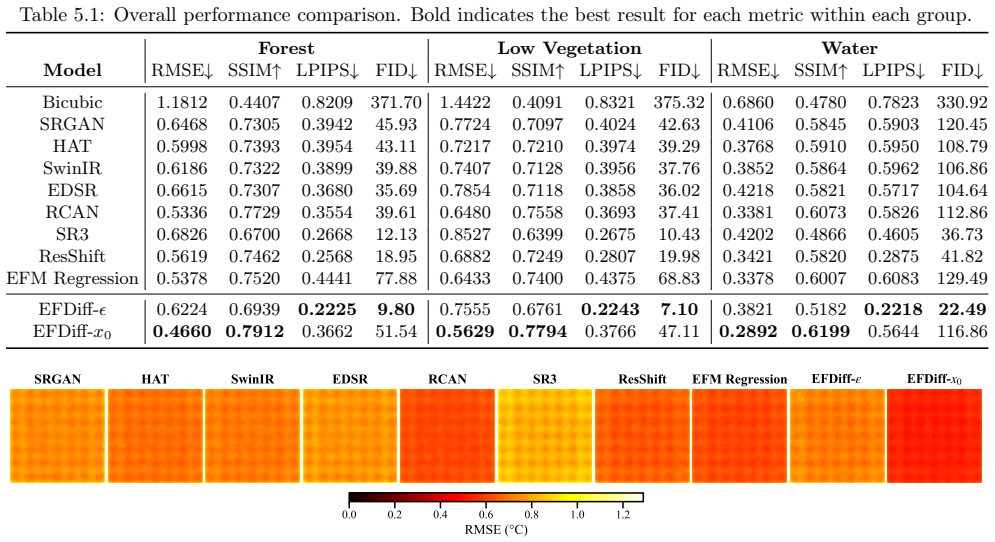
Land surface temperature (LST) super-resolution is important for environmental monitoring. However, it remains challenging as coarse thermal observations severely underdetermine fine-scale structure. In this paper, we propose Earth Foundation Model-guided Diffusion (EFDiff), a novel framework for super-resolution under extreme spatial degradation. EFDiff uses the Prithvi-EO-2.0 Earth foundation model to encode high-resolution multispectral reflectance into geospatial embeddings, which are injected into the denoising network via cross-attention to guide fine-scale reconstruction from highly degraded observations. We study two variants, EFDiff-$\epsilon$ and EFDiff-$x_0$, which offer complementary trade-offs between perceptual realism and pixel-level fidelity. We evaluate EFDiff under an extreme $32\times$ scale gap using a globally diverse benchmark comprising 242,416 co-registered Landsat thermal-reflectance patches. Results show that EFDiff consistently outperforms baseline methods and that cross-attention conditioning by EFM is more effective than HLS channel concatenation. Although we present EFDiff in the context of LST super-resolution, the framework is broadly applicable to remote sensing problems in which pretrained geospatial representations can guide generative reconstruction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Earth Foundation Model-guided Diffusion (EFDiff), a diffusion framework for LST super-resolution under 32× degradation. It extracts geospatial embeddings from the pretrained Prithvi-EO-2.0 model applied to high-resolution multispectral reflectance and injects them into the denoising network via cross-attention. Two variants (EFDiff-ε and EFDiff-x0) are presented for perceptual vs. fidelity trade-offs, evaluated on a benchmark of 242,416 global Landsat patches, with claims of consistent outperformance over baselines and superiority of cross-attention conditioning over HLS concatenation.
Significance. If the results hold, the work would demonstrate a practical way to leverage large-scale pretrained Earth foundation models for guiding generative reconstruction in remote sensing, addressing the severe under-determination of fine-scale thermal structure from coarse observations. The scale of the benchmark and the framework's stated generality to other modalities are notable strengths that could influence downstream applications in environmental monitoring.
major comments (2)
- Abstract: the claim that 'EFDiff consistently outperforms baseline methods' and that 'cross-attention conditioning by EFM is more effective than HLS channel concatenation' is asserted without any quantitative metrics, tables, or error statistics, preventing assessment of effect size or statistical significance.
- Abstract / Results: the central claim that cross-attention from Prithvi-EO-2.0 embeddings enables accurate 32× reconstruction rests on the untested assumption that these embeddings preserve high-frequency spatial structure. Under 32× degradation the thermal input supplies essentially no spatial cues, yet no ablation, frequency analysis, or resolution-specific experiment is described to show that the ViT embeddings transfer fine-scale geospatial detail rather than coarse semantics.
minor comments (1)
- Abstract: the symbols ε and x0 in the variant names EFDiff-ε and EFDiff-x0 are not defined; a one-sentence clarification of their diffusion-process meaning would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important opportunities to strengthen the presentation of results and the mechanistic justification for our approach. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: Abstract: the claim that 'EFDiff consistently outperforms baseline methods' and that 'cross-attention conditioning by EFM is more effective than HLS channel concatenation' is asserted without any quantitative metrics, tables, or error statistics, preventing assessment of effect size or statistical significance.
Authors: We agree that the abstract would benefit from explicit quantitative support. In the revised manuscript we will update the abstract to report key aggregate metrics from the 242,416-patch global benchmark (e.g., mean PSNR, SSIM, and LPIPS improvements of EFDiff over the strongest baselines, together with the corresponding gains of cross-attention over HLS concatenation). These numbers will be drawn directly from the results tables already present in the paper and will be accompanied by a brief statement of statistical significance where appropriate. revision: yes
-
Referee: Abstract / Results: the central claim that cross-attention from Prithvi-EO-2.0 embeddings enables accurate 32× reconstruction rests on the untested assumption that these embeddings preserve high-frequency spatial structure. Under 32× degradation the thermal input supplies essentially no spatial cues, yet no ablation, frequency analysis, or resolution-specific experiment is described to show that the ViT embeddings transfer fine-scale geospatial detail rather than coarse semantics.
Authors: This is a fair and substantive critique of the current evidence for the conditioning mechanism. While Prithvi-EO-2.0 is pretrained on high-resolution multispectral imagery, the manuscript does not yet contain explicit ablations or frequency-domain diagnostics. In the revision we will add (i) an ablation that replaces the high-resolution-derived embeddings with embeddings computed from spatially degraded inputs, (ii) power-spectrum and wavelet-based frequency analyses comparing reconstructions with and without the cross-attention pathway, and (iii) a resolution-sweep experiment at intermediate scale factors (4×, 8×, 16×) to isolate the contribution of fine-scale geospatial detail. These additions will directly test whether the embeddings supply high-frequency structure beyond coarse semantics. revision: yes
Circularity Check
No significant circularity; relies on external pretrained model
full rationale
The paper proposes EFDiff by encoding high-resolution multispectral reflectance with the external pretrained Prithvi-EO-2.0 model and injecting the resulting embeddings into a diffusion denoiser via cross-attention. This conditioning step and the subsequent empirical evaluation on 242,416 co-registered Landsat patches against baselines do not reduce to self-definition, fitted inputs renamed as predictions, or load-bearing self-citations. The framework is self-contained against external benchmarks with no equations or claims that equate outputs to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
[1]N. Agam, W. P. Kustas, M. C. Anderson, F. Li, and C. M. Neale,A vegetation index based technique for spatial sharpening of thermal im- agery, Remote sensing of Environment, 107 (2007), pp. 545–558. [2]Y. Blau and T. Michaeli,The perception- distortion tradeoff, in Proceedings of the IEEE con- ferenceoncomputervisionandpatternrecognition, 2018, pp. 6228...
-
[2]
[5]J. Chen, L. Jia, J. Zhang, Y. Feng, X. Zhao, and R. Tao,Super-resolution for land surface temperature retrieval images via cross-scale diffu- sion model using reference images, Remote Sens- ing, 16 (2024), p
2024
-
[3]
[6]X. Chen, X. W ang, J. Zhou, Y. Qiao, and C. Dong,Activating more pixels in image super-resolution transformer, in Proceedings of the IEEE/CVFconferenceoncomputervisionandpat- tern recognition, 2023, pp. 22367–22377. [7]M. Cla verie, J. Ju, J. G. Masek, J. L. Dun- gan, E. F. Vermote, J.-C. Roger, S. V. Skakun, and C. Justice,The harmonized land- sat and...
2023
-
[4]
Open-source AI model and interface for Earth
[8]Clay Foundation,Clay foundation model, 2024, https://github.com/Clay-foundation/model. Open-source AI model and interface for Earth. [9]Y. Cong, S. Khanna, C. Meng, P. Liu, E. Rozi, Y. He, M. Burke, D. Lobell, and S. Ermon,Satmae: Pre-training transformers for temporal and multi-spectral satellite imagery, Ad- vances in Neural Information Processing Sy...
2024
-
[5]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
[13]A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, et al.,An image is worth 16x16 words: Transformers for image recognition at scale, arXiv preprint arXiv:2010.11929, (2020). [14]Earth Resources Obser v ation and Sci- ence (EROS) Center,Landsat 8-9 opera- tional land imager...
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[6]
[21]G. C. Hulley, F. M. Göttsche, G. Rivera, S. J. Hook, R. J. Freepartner, M. A. Mar- tin, K. Ca wse-Nicholson, and W. R. John- son,Validation and quality assessment of the ecostress level-2 land surface temperature and emis- sivity product, IEEE Transactions on Geoscience and Remote Sensing, 60 (2021), pp. 1–23. [22]C. Hutengs and M. Vohland,Downscaling...
2021
-
[7]
[24]A. Lacoste, N. Lehmann, P. Rodriguez, E. Sher win, H. Kerner, B. Lütjens, J. Ir vin, D. Dao, H. Alemohammad, A. Drouin, et al., Geo-bench: Toward foundation models for earth monitoring, Advances in Neural Information Pro- cessing Systems, 36 (2023), pp. 51080–51093. [25]C. Ledig, L. Theis, F. Huszár, J. Caballero, A. Cunningham, A. Acosta, A. Aitken, ...
-
[8]
W ang, Z
[40]J. W ang, Z. Fu, B. Tang, and J. Xu, Information-guided diffusion model for downscal- ing land surface temperature from sdgsat-1 re- mote sensing images, Remote Sensing, 17 (2025), p
2025
-
[9]
[41]Z. W ang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli,Image quality assess- ment: from error visibility to structural similarity, IEEE transactions on image processing, 13 (2004), pp. 600–612. [42]Z. Xiong, Y. W ang, F. Zhang, A. J. Stew- art, J. Hanna, D. Borth, I. Papoutsis, B. Le Saux, G. Camps-V alls, and X. X. Zhu, Neural plasticity-inspired ...
-
[10]
[43]N. Xu, Z. Yin, M. Gao, J. Li, L. Song, and P. Wu,Downscaling cldas land surface tempera- ture using modis data and a multi-attention multi- residual super-resolution network, IEEE Transac- tions on Geoscience and Remote Sensing, (2025). [44]Z. Yue, J. W ang, and C. C. Loy,Resshift: Efficient diffusion model for image super-resolution by residual shift...
-
[11]
Tiles from Antarctica and central Green- land are removed due to limited relevance and sparse valid thermal coverage
and the RESOLVE 2017 ecoregion dataset [12]. Tiles from Antarctica and central Green- land are removed due to limited relevance and sparse valid thermal coverage. The remaining 3,094 MGRS tiles are then split geographically into 2,943 training tiles and 151 test tiles. For each selected tile, we re- trieve up to 48 observations from 2014 to 2026, sub- jec...
2017
-
[12]
Because extreme32×super-resolution is highly ill- posed, we report both classes of metrics to capture the perception–distortion trade-off [2]
and FID [19], which assess whether generated thermal fields exhibit realistic local texture and match the overall distribution of real sam- ples. Because extreme32×super-resolution is highly ill- posed, we report both classes of metrics to capture the perception–distortion trade-off [2]. To further expose performance differences across terrain types, all ...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.