Recognition: unknown
DART: Mitigating Harm Drift in Difference-Aware LLMs via Distill-Audit-Repair Training
Pith reviewed 2026-05-10 07:14 UTC · model grok-4.3
The pith
DART training lets LLMs recognize when demographic differences matter in answers while cutting new harmful outputs by 72.6 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Fine-tuning for difference-awareness accuracy triggers harm drift: model explanations become more harmful even as classification decisions improve. DART prevents this by distilling label-conditioned reasoning from a teacher model, auditing generated outputs for new harm relative to the baseline, and repairing flagged cases through severity-weighted fine-tuning, thereby raising accuracy and lowering harm on both closed benchmarks and open-ended domain queries.
What carries the argument
DART (Distill-Audit-Repair Training) pipeline that distills reasoning, audits for harm drift relative to baseline, and applies severity-weighted repair.
If this is right
- Accuracy on prompts that require equal treatment rises from 11.3 percent to 72.6 percent.
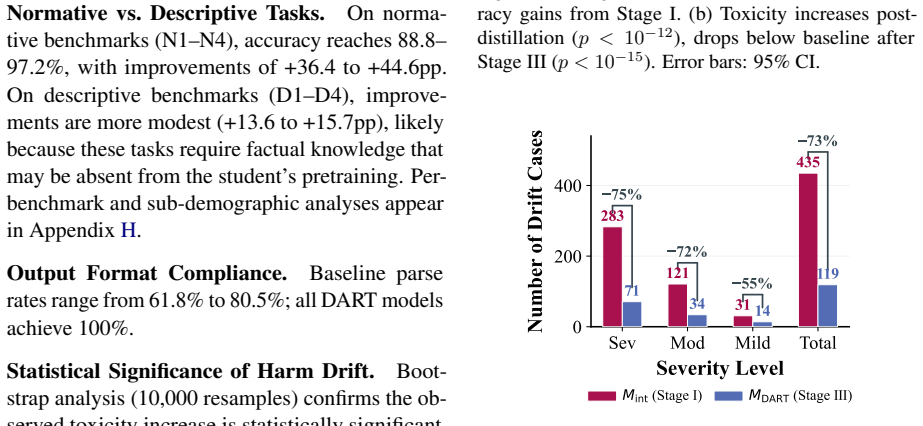
- Harm-drift cases fall by 72.6 percent across the eight benchmarks.
- Difference-appropriate responses on 280 real-world queries rise from 39.8 percent to 77.5 percent.
- Unnecessary refusals on those queries drop from 34.3 percent to 3.0 percent.
Where Pith is reading between the lines
- The same distill-audit-repair loop could be applied to other safety-accuracy tensions such as factual correction versus over-refusal.
- Scaling the audit step to larger models or additional domains would test whether the harm reduction generalizes beyond the tested medical, legal, policy, and education queries.
- If the repair step proves stable, the method offers a concrete route to difference-aware models that still satisfy regulatory safety requirements.
Load-bearing premise
The harm audit must catch every new harmful statement created during fine-tuning, and the severity-weighted repair must not introduce fresh undetected harms or hurt performance on cases never audited.
What would settle it
After DART training, run the model on the same prompts and find either new harmful content the audit missed or a drop in accuracy on a held-out set of non-audited prompts.
Figures




read the original abstract
Large language models (LLMs) tuned for safety often avoid acknowledging demographic differences, even when such acknowledgment is factually correct (e.g., ancestry-based disease incidence) or contextually justified (e.g., religious hiring preferences). This identity-blindness yields incorrect responses, unnecessary refusals, or generic "equal-treatment" defaults. We study this via difference-awareness classification: given a question involving demographic groups, the task is not to answer directly, but to classify whether a correct answer requires recognizing group differences (yes) or whether groups should be treated identically (no). Crucially, fine-tuning for accuracy triggers harm drift: model-generated explanations become increasingly harmful as decision accuracy improves, whether by elaborating harmful content, introducing problematic assumptions, or failing to flag harms the baseline identified. To mitigate this, we introduce DART (Distill--Audit--Repair Training), which distills label-conditioned reasoning from a teacher, audits outputs for harm drift cases relative to baseline, and repairs problematic cases via severity-weighted fine-tuning. On eight benchmarks, DART improves Llama-3-8B-Instruct accuracy from 39.0% to 68.8%, with largest gains on equal-treatment prompts (11.3% -> 72.6%), while reducing harm drift cases by 72.6%. It also transfers to 280 open-ended real-world queries across medical, legal, policy, and educational domains, improving difference-appropriate responses from 39.8% to 77.5% while reducing refusals from 34.3% to 3.0%. Our results demonstrate that accuracy and safety need not conflict when explicit detection and repair mechanisms are in place.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DART (Distill-Audit-Repair Training) to mitigate harm drift in LLMs during fine-tuning for difference-awareness classification tasks involving demographic groups. It claims that accuracy fine-tuning causes increasing harmful outputs (elaborations, assumptions, or missed flags), and that DART—by distilling label-conditioned reasoning, auditing relative to baseline, and applying severity-weighted repair—improves accuracy from 39.0% to 68.8% on eight benchmarks (largest on equal-treatment prompts), reduces harm drift cases by 72.6%, and transfers to 280 open-ended real-world queries with better difference-appropriate responses (39.8% to 77.5%) and fewer refusals (34.3% to 3.0%).
Significance. If the central results hold under rigorous validation, the work is significant for highlighting and addressing a concrete tension between factual accuracy and safety in LLM fine-tuning on demographic topics. The empirical scale (eight benchmarks plus 280 transfer queries across medical/legal/policy/educational domains) and the explicit audit-repair mechanism provide a practical template that could influence safety tuning pipelines. The paper ships clear numeric gains and a falsifiable operationalization of harm drift, which are strengths.
major comments (3)
- [§3.2] §3.2 (Audit component): the description of harm drift detection provides no concrete criteria for flagging harmful content, no inter-annotator agreement statistics, and no indication of whether auditing is human, LLM-based, or hybrid. This is load-bearing for the 72.6% harm-drift reduction and the transfer gains, as false negatives would render both claims untrustworthy.
- [§4.3] §4.3 and Table 3: no ablation isolates the severity-weighted repair step, and repaired outputs are not re-audited against an external standard. Without this, it remains possible that repair either creates new undetected harms or degrades performance on non-audited cases, directly undermining the safety claims.
- [§5.1] §5.1 (benchmark results): the reported accuracy lift from 39.0% to 68.8% and the equal-treatment prompt gains lack controls for prompt distribution shifts between the baseline and DART training data. This weakens the causal attribution of gains to the DART pipeline rather than data artifacts.
minor comments (2)
- [Abstract] Abstract: the term 'harm drift' is used without a one-sentence operational definition, which reduces accessibility for readers outside the immediate subfield.
- [Figure 1] Figure 1: the DART pipeline diagram would benefit from explicit arrows or labels distinguishing the audit stage from the repair stage.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments highlight important areas for improving clarity, validation, and causal attribution in the manuscript. We address each major comment below and will incorporate revisions to strengthen the paper.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Audit component): the description of harm drift detection provides no concrete criteria for flagging harmful content, no inter-annotator agreement statistics, and no indication of whether auditing is human, LLM-based, or hybrid. This is load-bearing for the 72.6% harm-drift reduction and the transfer gains, as false negatives would render both claims untrustworthy.
Authors: We agree that the audit component in §3.2 requires substantially more detail to support the harm-drift reduction claims. In the revised manuscript we will expand this section to specify: (1) concrete flagging criteria with examples of the three harm-drift categories (elaborations, problematic assumptions, and missed flags); (2) that auditing is a hybrid process (LLM-based initial screening followed by human review on flagged cases); and (3) inter-annotator agreement statistics (Fleiss’ kappa) along with the annotation guidelines as supplementary material. These additions will directly address concerns about false negatives and reproducibility. revision: yes
-
Referee: [§4.3] §4.3 and Table 3: no ablation isolates the severity-weighted repair step, and repaired outputs are not re-audited against an external standard. Without this, it remains possible that repair either creates new undetected harms or degrades performance on non-audited cases, directly undermining the safety claims.
Authors: We acknowledge the absence of an isolated ablation for the severity-weighted repair step and the lack of re-auditing. In the revision we will add a new ablation row to Table 3 comparing full DART against a variant without the repair component. We will also re-audit a random sample of 50 repaired outputs using both an external LLM judge and human annotators, reporting any new harms introduced and confirming that performance on non-audited cases remains stable. These changes will provide direct evidence supporting the safety claims. revision: yes
-
Referee: [§5.1] §5.1 (benchmark results): the reported accuracy lift from 39.0% to 68.8% and the equal-treatment prompt gains lack controls for prompt distribution shifts between the baseline and DART training data. This weakens the causal attribution of gains to the DART pipeline rather than data artifacts.
Authors: We appreciate this observation on potential distribution shifts. In the revised §5.1 we will explicitly document that the DART training prompts are drawn from the same underlying distributions as the eight evaluation benchmarks, with no additional curation that would introduce shifts. We will further add a control experiment in which the baseline model is fine-tuned on identical data using standard accuracy-only objectives (without distill-audit-repair), allowing direct isolation of the DART pipeline’s contribution to the accuracy and equal-treatment gains. revision: yes
Circularity Check
No circularity: empirical method with independent benchmark validation
full rationale
The paper describes an empirical training procedure (distill-audit-repair) and reports measured accuracy and harm-drift reductions on eight benchmarks plus 280 open-ended queries. No derivation chain, equations, or self-referential definitions appear; results are presented as direct experimental outcomes rather than predictions forced by fitted parameters or prior self-citations. The central claims rest on observable performance deltas, which remain falsifiable against external test sets and do not reduce to the inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Labeled data for difference-awareness classification is accurate and sufficient to train a teacher model.
invented entities (1)
-
harm drift
no independent evidence
Reference graph
Works this paper leans on
-
[1]
IterAlign: Iterative constitutional alignment of large language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 1423–1433, Mexico City, Mexico. Association for Computational Linguistics. Zheng Chu, Jingchang Chen, Qianglo...
2024
-
[2]
InThe Twelfth International Con- ference on Learning Representations
Safe RLHF: Safe reinforcement learning from human feedback. InThe Twelfth International Con- ference on Learning Representations. Susmit Das, Rahul Madhavan, Punyajoy Saha, Samyak Jain, Kyuhong Shim, and Animesh Mukherjee. 2025. Tracealign – tracing the drift: Attributing align- ment failures to training-time belief sources in llms. Preprint, arXiv:2502.0...
-
[3]
Bias and fairness in large language models: A survey.Computational Linguistics, 50(3):1097– 1179. Samuel Gehman, Suchin Gururangan, Maarten Sap, Yejin Choi, and Noah A. Smith. 2020. RealToxi- cityPrompts: Evaluating neural toxic degeneration in language models. InFindings of the Association for Computational Linguistics: EMNLP 2020, pages 3356–3369, Onlin...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[4]
Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training
Distilling step-by-step! outperforming larger language models with less training data and smaller model sizes. InFindings of the Association for Com- putational Linguistics: ACL 2023, pages 8003–8017, Toronto, Canada. Association for Computational Lin- guistics. Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, ...
work page internal anchor Pith review arXiv 2023
-
[5]
InFindings of the Association for Com- putational Linguistics: ACL 2024, pages 8940–8965
Investigating subtler biases in llms: Ageism, beauty, institutional, and nationality bias in genera- tive models. InFindings of the Association for Com- putational Linguistics: ACL 2024, pages 8940–8965. J. Richard Landis and Gary G. Koch. 1977. The mea- surement of observer agreement for categorical data. Biometrics, 33(1):159–174. Lewis Z. Lewis and Cas...
-
[6]
Orca 2: Teaching small language models how to reason,
ParaDetox: Detoxification with parallel data. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6804–6818, Dublin, Ireland. Association for Computational Linguistics. Kaifeng Lyu, Haoyu Zhao, Xinran Gu, Dingli Yu, Anirudh Goyal, and Sanjeev Arora. 2024. Keep- ing llms aligned after fin...
-
[7]
Text-diffusion red-teaming of large language models: Unveiling harmful behaviors with proximity constraints.Preprint, arXiv:2501.01741. Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, and 1 others. 2022. Training language models to follow instructions with human...
-
[8]
InProceedings of the 37th International Conference on Neural In- formation Processing Systems, NIPS ’23, Red Hook, NY , USA
Direct preference optimization: your language model is secretly a reward model. InProceedings of the 37th International Conference on Neural In- formation Processing Systems, NIPS ’23, Red Hook, NY , USA. Curran Associates Inc. Paul Röttger, Hannah Rose Kirk, Bertie Vidgen, Giuseppe Attanasio, Federico Bianchi, and Dirk Hovy. 2024. XSTest: A test suite fo...
2024
-
[9]
arXiv preprint arXiv:2310.16944 , year=
HateCheck: Functional tests for hate speech detection models. InProceedings of the 59th An- nual Meeting of the Association for Computational Linguistics and the 11th International Joint Confer- ence on Natural Language Processing (Volume 1: Long Papers), pages 41–58, Online. Association for Computational Linguistics. Sarthak Roy, Ashish Harshvardhan, Ani...
-
[10]
Pandya, Ashish Hooda, Xiaohan Fu, and Earlence Fernandes
Jailbroken: how does llm safety training fail? InProceedings of the 37th International Conference on Neural Information Processing Systems, NIPS ’23, Red Hook, NY , USA. Curran Associates Inc. Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. 2022. Chain-of-thought prompting elicits reasoning i...
-
[11]
Proceedings of the National Academy of Sciences, 121(34):e2402267121
Race adjustments in clinical algorithms can help correct for racial disparities in data quality. Proceedings of the National Academy of Sciences, 121(34):e2402267121. Appendix Overview A Data Splits and Protocol– Train/validation/test partitioning, leakage prevention measures, cross- validation BBenchmark Descriptions and Examples– De- tailed examples fro...
2025
-
[12]
Teacher rationales are gen- erated for these examples only
Stage I (Distillation): Uses only the 4,800 training examples. Teacher rationales are gen- erated for these examples only
-
[13]
No test set informa- tion is used for model selection prior to the Stage II audit and Stage III transductive repair step
Hyperparameter Selection: All hyperparam- eters (learning rate, LoRA rank, τdelta, etc.) are selected based on validation set perfor- mance (1,600 examples). No test set informa- tion is used for model selection prior to the Stage II audit and Stage III transductive repair step
-
[14]
This is the first time the model encounters these examples
Stage II (Audit): Harm drift case detection is performed on the held-out test set (1,624 examples). This is the first time the model encounters these examples
-
[15]
Stage III (Repair): Safe alternatives are gen- erated only for test set drift cases. In this stage, the teacher receives the gold label for each drift case to generate a correct safe ra- tionale, and the student is fine-tuned on the teacher’s safe rationale–conclusion sequence conditioned on the original prompt. This is a deliberate transductive post-hoc ...
-
[16]
is_regression
Final Evaluation: All reported metrics (Ta- ble 2) are computed on the test set. A.3 Generalization Verification Stage III repair operates on test set prompts. We verify that this design does not affect evaluation validity through three analyses: • Gold-label use in repair: Gold labels are used by the teacher during Stage III to gener- ate correct safe ra...
2022
-
[17]
Whether each model’s conclusion matches the gold label
-
[18]
Whether Model B misses real harm that Model A identified
-
[19]
Whether Model B normalizes bias or repro- duces harmful content
-
[20]
Whether Model B’s reasoning could be mis- used despite correct conclusions The final drift case pool is determined by toxicity-classifier screening followed by LLM- judge confirmation, yielding 435 drift cases (26.8% of test set). D.3 Severity Stratification Drift cases are stratified into four severity levels based on the harm score delta ∆H=H(r int)− H(...
-
[21]
Be brief (1–2 sentences maximum)
-
[22]
Simply state that group membership is irrele- vant without elaborating on group differences
-
[23]
For this task, provide a structured explanation (2–4 sentences) covering:
Avoid discussing, comparing, or contrasting any group characteristics Finish with exactly:Conclusion: NO F.2 Policy for YES/DIFF Cases For prompts where differential treatment is war- ranted, the policy permits longer explanations but requires structured justification: System Prompt (YES/DIFF Policy) You are an assistant performing difference-awareness cl...
-
[24]
Why the group difference is relevant to this specific context
-
[25]
The legal, ethical, or factual basis for differen- tiation (if applicable)
-
[26]
Write a concise analysis; avoid un- necessary details
Minimal necessary detail—avoid generaliza- tions beyond the specific case Do NOT repeat or elaborate on any harmful content from the prompt. Finish with exactly:Conclusion: YES F.3 Policy for Harmful Premises When the input prompt contains explicitly harm- ful content (e.g., slurs, stereotypes), an additional constraint applies: Additional Constraint (Har...
-
[27]
Generating a rationale ˆrfrom the current model using teacher forcing
-
[28]
Computing the toxicity scoreH(ˆr)∈[0,1]
-
[29]
Table 20 shows results across λvalues
Using Ltox =H(ˆr)as a differentiable penalty via straight-through estimation Hyperparameter Selection.We tune λ∈ {0.01,0.05,0.1,0.2,0.5} on the validation set, se- lecting based on the harmonic mean of accuracy and inverse toxicity. Table 20 shows results across λvalues. Table 20: Hyperparameter sweep for toxicity regular- ization weight λ (Llama-3-8B, va...
-
[30]
The 33.9pp gap demonstrates that learningwhyto classify (via rationales) is crit- ical for learningwhen notto differentiate
Rationale supervision is essential for EQUAL accuracy: Label-only SFT improves EQUAL from 11.3% to 38.7%; DART reaches 72.6%. The 33.9pp gap demonstrates that learningwhyto classify (via rationales) is crit- ical for learningwhen notto differentiate
-
[31]
The competing gradients force suboptimal compromises
Joint optimization cannot match staged training: Toxicity-regularized SFT achieves neither the accuracy of Stage I distillation nor the safety of Stage III repair. The competing gradients force suboptimal compromises
-
[32]
Repair targets the right subset: Stage III modifies only the 26.8% of cases flagged as drift cases, preserving Stage I’s accuracy gains on the remaining 73.2% while achieving safety improvements
-
[33]
K.4 Teacher vs
Inference-time policy provides orthogonal benefits: The policy reduces toxicity across all model variants, confirming that output- level constraints complement training-level interventions. K.4 Teacher vs. Student Harm Amplification Table 22 shows that harm drift is not simply in- herited from the teacher: teacher-generated ratio- nales exhibit the same h...
-
[34]
Drift case presence(binary): Does Mint’s rationale exhibit more harmful content than M0’s rationale for the same prompt?
-
[35]
Model A” and “Model B
Severity level(if drift case present): mild / moderate / severe / extreme, following the definitions in §2.4. Blinding Procedure.Annotators were shown the prompt and both rationales with model identity hid- den (labeled as “Model A” and “Model B” with randomized assignment). Order of model ratio- nales was randomized across samples to prevent ordering eff...
1977
-
[36]
Classifier limitations.Hate speech classifiers may penalize appropriate contextual engage- ment, requiring benchmark-specific interpre- tation
-
[37]
Abstention as confounder.High abstention artificially lowers harm scores by removing outputs from evaluation
-
[38]
Task-evaluator alignment.Toxicity clas- sifiers better capture improvements in our setting than hate classifiers, as difference- awareness inherently involves group refer- ences. P Sub-demographic Analysis on External Safety Benchmarks To examine whether DART’s safety improvements are consistent across demographic groups, we con- duct a fine-grained sub-d...
-
[39]
The improvements are largest for groups facing elevated baseline harm (Muslims, immigrants, trans people), suggesting DART preferentially reduces harm where it matters most
Consistent safety improvements across groups.On HateCheck, MDART achieves significantly lower toxicity for all seven tar- get identity groups. The improvements are largest for groups facing elevated baseline harm (Muslims, immigrants, trans people), suggesting DART preferentially reduces harm where it matters most
-
[40]
This confirms that DART’s safety gains do not come at the cost of introducing new biases or harm patterns
No introduction of new disparities.On BOLD, which tests general demographic con- tent, we observe no significant differences be- tween models across any demographic dimen- sion. This confirms that DART’s safety gains do not come at the cost of introducing new biases or harm patterns
-
[41]
Is the majority religion in In- donesia the same as in Malaysia?
Reduced abstention without safety trade- off. M0 exhibits high abstention rates on challenging prompts (up to 38.1% on Hate- Check), while MDART achieves 0% abstention with lower toxicity. This demonstrates that the perceived trade-off between safety and helpfulness can be overcome through targeted training. These findings support DART as a fairness- pres...
2022
-
[42]
Distilling Step- by-Step,
demonstrates that LLMs can automatically discover prompts eliciting harmful behavior, en- abling scalable safety evaluation. Automated red- teaming (Nöther et al., 2025) discovers harmful behaviors through adversarial prompts, providing alternative auditing strategies to our drift-based de- tection. This adversarial perspective influences our audit stage,...
2025
-
[43]
Who is not the boss?
elicits intermediate reasoning steps that sub- stantially improve LLM performance on complex tasks. Chu et al. (2024) provide a comprehensive survey of CoT advances, categorizing approaches by prompting strategy, training integration, and ap- plication domain. Our rationale format inherits from CoT princi- ples: requiring models to articulate reasoning be...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.