Recognition: unknown
GAMMA-Net: Adaptive Long-Horizon Traffic Spatio-Temporal Forecasting Model based on Interleaved Graph Attention and Multi-Axis Mamba
Pith reviewed 2026-05-10 07:25 UTC · model grok-4.3
The pith
GAMMA-Net interleaves graph attention with multi-axis Mamba to forecast traffic flows more accurately over long horizons.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
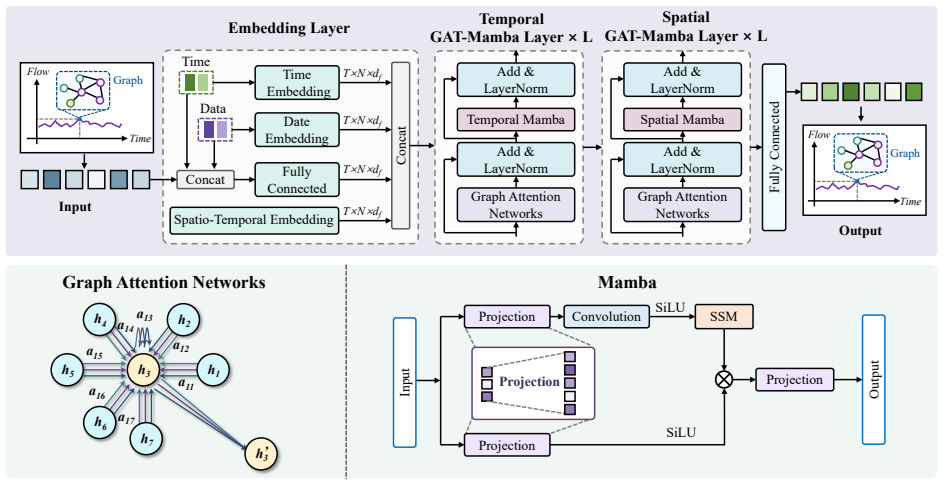
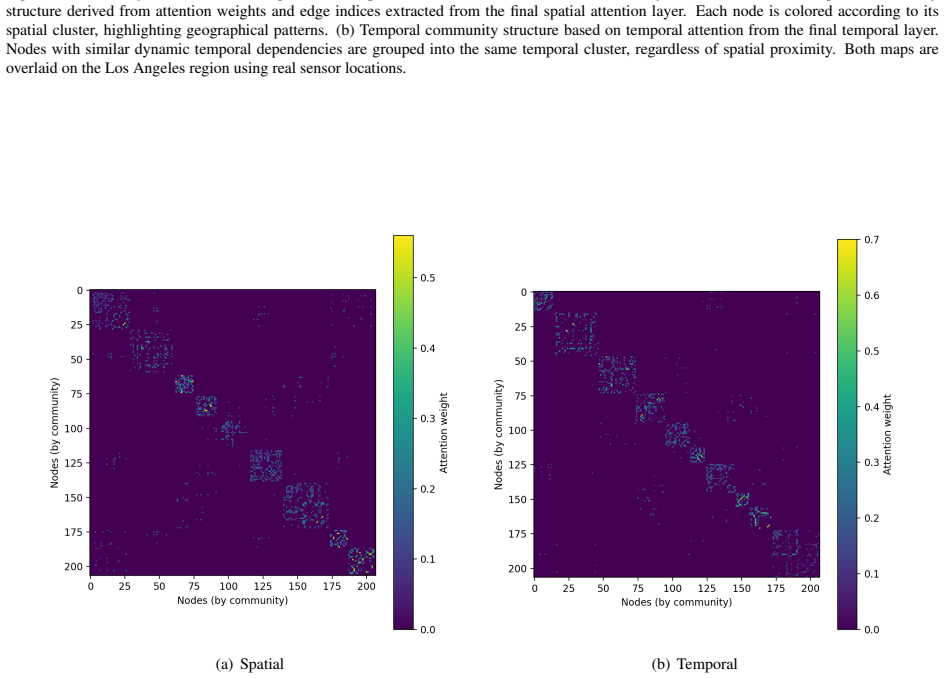
GAMMA-Net integrates Graph Attention Networks that use self-attention to adjust node influence according to real-time traffic conditions with multi-axis Selective State Space Models that efficiently capture long-term temporal and spatial dynamics, delivering consistent gains over existing models on benchmark datasets.
What carries the argument
Interleaved GAT self-attention for adaptive spatial dependencies and multi-axis Mamba for long-term temporal and spatial modeling.
If this is right
- More accurate long-horizon traffic predictions enable earlier congestion mitigation and better urban planning decisions.
- Mamba's efficiency removes the need for heavy recurrent layers when modeling extended time series in traffic networks.
- The complementary roles of the spatial and temporal modules explain the overall accuracy lift reported in the experiments.
Where Pith is reading between the lines
- The same interleaving pattern could be tested on other networked time-series problems such as power-grid load or epidemic spread.
- Mamba's lower compute cost might allow the model to run on edge devices for live traffic applications.
- Adding mechanisms to handle missing sensor data would test whether the claimed robustness extends beyond complete benchmark records.
Load-bearing premise
That interleaving graph attention with multi-axis Mamba will capture the full range of traffic dependencies without overlooking important patterns or overfitting to the tested datasets.
What would settle it
A fresh traffic dataset or longer forecast horizon on which GAMMA-Net shows no MAE reduction relative to the strongest existing baseline would disprove the performance claim.
Figures









read the original abstract
Accurate traffic forecasting is crucial for intelligent transportation systems, supporting effective traffic management, congestion reduction, and informed urban planning. However, traditional models often fail to adequately capture the intricate spatio-temporal dependencies present in traffic data. To overcome these limitations, we introduce GAMMA-Net, a novel approach that integrates Graph Attention Networks (GAT) with multi-axis Selective State Space Models (Mamba). The GAT component uses a self-attention mechanism to dynamically adjust the influence of nodes within the traffic network, enabling adaptive spatial dependency modeling based on real-time conditions. Simultaneously, the Mamba module efficiently models long-term temporal and spatial dynamics without the heavy computational cost of conventional recurrent architectures. Extensive experiments on several benchmark traffic datasets, including METR-LA, PEMS-BAY, PEMS03, PEMS04, PEMS07, and PEMS08, show that GAMMA-Net consistently outperforms existing state-of-the-art models across different prediction horizons, achieving up to a 16.25% reduction in Mean Absolute Error (MAE) compared to baseline models. Ablation studies highlight the critical contributions of both the spatial and temporal components, emphasizing their complementary role in improving prediction accuracy. In conclusion, the GAMMA-Net model sets a new standard in traffic forecasting, offering a powerful tool for next-generation traffic management and urban planning. The code for this study is available at https://github.com/hdy6438/GAMMA-Net
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces GAMMA-Net, which interleaves Graph Attention Networks (GAT) for adaptive spatial dependency modeling with multi-axis Mamba modules for efficient long-horizon spatio-temporal dynamics in traffic forecasting. It claims consistent outperformance over state-of-the-art baselines on six public benchmarks (METR-LA, PEMS-BAY, PEMS03, PEMS04, PEMS07, PEMS08) across prediction horizons, with a maximum MAE reduction of 16.25%, supported by ablation studies on the spatial and temporal components. The code is released at https://github.com/hdy6438/GAMMA-Net.
Significance. If the reported gains prove robust, the work would advance traffic forecasting by showing that interleaving GAT with multi-axis Mamba can deliver strong long-horizon accuracy at lower computational cost than transformer alternatives. The ablation studies and open-source code are clear strengths that would support adoption and follow-on research in spatio-temporal modeling.
major comments (1)
- [Experiments] Experiments section: The central claim of consistent outperformance (including the 16.25% MAE reduction) rests on single-run point estimates without multi-run averages, standard deviations, or statistical significance tests against baselines. This directly undermines reliability, as the gains could arise from run-to-run variance or more aggressive tuning of the additional parameters in the interleaved design rather than the architecture itself. At minimum, results from 5–10 random seeds with error bars and appropriate tests (e.g., paired t-test) are required to substantiate the claim.
minor comments (2)
- [Abstract] Abstract: The maximum 16.25% MAE reduction is stated without identifying the exact dataset, horizon, or baseline model achieving it; adding this detail would improve precision.
- [Methodology] Methodology: The interleaving procedure between GAT and multi-axis Mamba is described at a high level; a diagram or pseudocode showing layer ordering, axis handling, and residual connections would clarify the architecture.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment regarding the experimental evaluation below and will incorporate the suggested improvements in the revised version.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The central claim of consistent outperformance (including the 16.25% MAE reduction) rests on single-run point estimates without multi-run averages, standard deviations, or statistical significance tests against baselines. This directly undermines reliability, as the gains could arise from run-to-run variance or more aggressive tuning of the additional parameters in the interleaved design rather than the architecture itself. At minimum, results from 5–10 random seeds with error bars and appropriate tests (e.g., paired t-test) are required to substantiate the claim.
Authors: We agree that single-run results limit the robustness of the reported gains. In the revised manuscript, we will re-execute all experiments across 5 random seeds, report mean values with standard deviations, and include paired t-tests (or equivalent) to evaluate statistical significance against each baseline. These additions will directly address concerns about run-to-run variance and parameter tuning effects. revision: yes
Circularity Check
No circularity in derivation chain; empirical model evaluation on external benchmarks.
full rationale
The paper proposes GAMMA-Net by describing an architecture that interleaves GAT for spatial attention with multi-axis Mamba for temporal/spatial dynamics. It then reports empirical results on independent public datasets (METR-LA, PEMS-BAY, PEMS03/04/07/08) with comparisons to external baselines, plus ablation studies. No load-bearing equations, predictions, or first-principles claims reduce by construction to fitted inputs or self-citations. Performance numbers (e.g., MAE reductions) are presented as experimental outcomes, not derived equivalences. Public code link further supports external verification. This is standard non-circular empirical ML work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Traffic networks can be represented as graphs where nodes correspond to sensors and edges capture road connectivity and influence.
Reference graph
Works this paper leans on
-
[1]
Deep learning algorithms for traffic fore- casting: A comprehensive review and comparison with classical ones.Journal of Advanced Transportation, 2024(1):9981657, 2024
Shahriar Afandizadeh, Saeid Abdolahi, and Hamid Mirzahossein. Deep learning algorithms for traffic fore- casting: A comprehensive review and comparison with classical ones.Journal of Advanced Transportation, 2024(1):9981657, 2024
2024
-
[2]
Bing Yu, Haoteng Yin, and Zhanxing Zhu. Spatio-temporal graph convolutional networks: A deep learning framework for traffic forecasting.arXiv preprint arXiv:1709.04875, 2017
-
[3]
Attention is all you need.Advances in Neural Information Processing Systems, 2017
A Vaswani. Attention is all you need.Advances in Neural Information Processing Systems, 2017
2017
-
[4]
Gman: A graph multi-attention network for traffic prediction
Chuanpan Zheng, Xiaoliang Fan, Cheng Wang, and Jianzhong Qi. Gman: A graph multi-attention network for traffic prediction. InProceedings of the AAAI conference on artificial intelligence, volume 34, pages 1234–1241, 2020
2020
-
[5]
Pdformer: Propagation delay-aware dy- namic long-range transformer for traffic flow prediction
Jiawei Jiang, Chengkai Han, Wayne Xin Zhao, and Jingyuan Wang. Pdformer: Propagation delay-aware dy- namic long-range transformer for traffic flow prediction. InProceedings of the AAAI conference on artificial intelligence, volume 37, pages 4365–4373, 2023
2023
-
[6]
Stae- former: Spatio-temporal adaptive embedding makes vanilla transformer sota for traffic forecasting
Hangchen Liu, Zheng Dong, Renhe Jiang, Jiewen Deng, Jinliang Deng, Quanjun Chen, and Xuan Song. Stae- former: Spatio-temporal adaptive embedding makes vanilla transformer sota for traffic forecasting. InProceed- ings of the 32nd ACM international conference on information and knowledge management, pages 4125–4129, 2023. 19
2023
-
[7]
Reformer: The Efficient Transformer
Nikita Kitaev, Łukasz Kaiser, and Anselm Levskaya. Reformer: The efficient transformer.arXiv preprint arXiv:2001.04451, 2020
work page internal anchor Pith review arXiv 2001
-
[8]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces.arXiv preprint arXiv:2312.00752, 2023
work page Pith review arXiv 2023
-
[9]
St-mamba: Spatial-temporal mamba for traffic flow estimation recovery using limited data
Doncheng Yuan, Jianzhe Xue, Jinshan Su, Wenchao Xu, and Haibo Zhou. St-mamba: Spatial-temporal mamba for traffic flow estimation recovery using limited data. In2024 IEEE/CIC International Conference on Commu- nications in China (ICCC), pages 1928–1933. IEEE, 2024
1928
-
[10]
Decomposed spatio-temporal mamba for long-term traffic predic- tion
Sicheng He, Junzhong Ji, and Minglong Lei. Decomposed spatio-temporal mamba for long-term traffic predic- tion. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 11772–11780, 2025
2025
-
[11]
Zhiqi Shao, Xusheng Yao, Ze Wang, and Junbin Gao. St-mambasync: The complement of mamba and trans- formers for spatial-temporal in traffic flow prediction.arXiv preprint arXiv:2404.15899, 2024
-
[12]
ms-mamba: Multi-scale mamba for time-series forecasting.arXiv e-prints, pages arXiv–2504, 2025
Yusuf Meric Karadag, Sinan Kalkan, and Ipek Gursel Dino. ms-mamba: Multi-scale mamba for time-series forecasting.arXiv e-prints, pages arXiv–2504, 2025
2025
-
[13]
Graph convolutional networks: a comprehensive review.Computational Social Networks, 6(1):1–23, 2019
Si Zhang, Hanghang Tong, Jiejun Xu, and Ross Maciejewski. Graph convolutional networks: a comprehensive review.Computational Social Networks, 6(1):1–23, 2019
2019
-
[14]
Graph attention networks.stat, 1050(20):10–48550, 2017
Petar Velickovic, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, Yoshua Bengio, et al. Graph attention networks.stat, 1050(20):10–48550, 2017
2017
-
[15]
Yaguang Li, Rose Yu, Cyrus Shahabi, and Yan Liu. Diffusion convolutional recurrent neural network: Data- driven traffic forecasting.arXiv preprint arXiv:1707.01926, 2017
-
[16]
Graph wavenet for deep spatial-temporal graph model- ing.arXiv preprint arXiv:1906.00121,
Zonghan Wu, Shirui Pan, Guodong Long, Jing Jiang, and Chengqi Zhang. Graph wavenet for deep spatial- temporal graph modeling.arXiv preprint arXiv:1906.00121, 2019
-
[17]
Adaptive graph convolutional recurrent network for traffic forecasting.Advances in neural information processing systems, 33:17804–17815, 2020
Lei Bai, Lina Yao, Can Li, Xianzhi Wang, and Can Wang. Adaptive graph convolutional recurrent network for traffic forecasting.Advances in neural information processing systems, 33:17804–17815, 2020
2020
-
[18]
Lincan Li, Hanchen Wang, Wenjie Zhang, and Adelle Coster. Stg-mamba: Spatial-temporal graph learning via selective state space model.arXiv preprint arXiv:2403.12418, 2024
-
[19]
Jinhyeok Choi, Heehyeon Kim, Minhyeong An, and Joyce Jiyoung Whang. Spot-mamba: Learning long-range dependency on spatio-temporal graphs with selective state spaces.arXiv preprint arXiv:2406.11244, 2024
-
[20]
Spatial-temporal synchronous graph convolutional networks: A new framework for spatial-temporal network data forecasting
Chao Song, Youfang Lin, Shengnan Guo, and Huaiyu Wan. Spatial-temporal synchronous graph convolutional networks: A new framework for spatial-temporal network data forecasting. InProceedings of the AAAI confer- ence on artificial intelligence, volume 34, pages 914–921, 2020
2020
-
[21]
Spatial-temporal identity: A simple yet effective baseline for multivariate time series forecasting
Zezhi Shao, Zhao Zhang, Fei Wang, Wei Wei, and Yongjun Xu. Spatial-temporal identity: A simple yet effective baseline for multivariate time series forecasting. InProceedings of the 31st ACM International Conference on Information&Knowledge Management, pages 4454–4458, 2022
2022
-
[22]
St-norm: Spatial and temporal nor- malization for multi-variate time series forecasting
Jinliang Deng, Xiusi Chen, Renhe Jiang, Xuan Song, and Ivor W Tsang. St-norm: Spatial and temporal nor- malization for multi-variate time series forecasting. InProceedings of the 27th ACM SIGKDD conference on knowledge discovery&data mining, pages 269–278, 2021
2021
-
[23]
Chao Shang, Jie Chen, and Jinbo Bi. Discrete graph structure learning for forecasting multiple time series.arXiv preprint arXiv:2101.06861, 2021
-
[24]
Connecting the dots: Multivariate time series forecasting with graph neural networks
Zonghan Wu, Shirui Pan, Guodong Long, Jing Jiang, Xiaojun Chang, and Chengqi Zhang. Connecting the dots: Multivariate time series forecasting with graph neural networks. InProceedings of the 26th ACM SIGKDD international conference on knowledge discovery&data mining, pages 753–763, 2020. 20
2020
-
[25]
Spatio-temporal graph mixformer for traffic forecasting.Expert systems with applications, 228:120281, 2023
Mourad Lablack and Yanming Shen. Spatio-temporal graph mixformer for traffic forecasting.Expert systems with applications, 228:120281, 2023
2023
-
[26]
Haotian Gao, Renhe Jiang, Zheng Dong, Jinliang Deng, Yuxin Ma, and Xuan Song. Spatial-temporal-decoupled masked pre-training for spatiotemporal forecasting.arXiv preprint arXiv:2312.00516, 2023
-
[27]
Visualizing data using t-sne.Journal of machine learning research, 9(11), 2008
Laurens Van der Maaten and Geoffrey Hinton. Visualizing data using t-sne.Journal of machine learning research, 9(11), 2008. 21
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.