Recognition: unknown
OC-Distill: Ontology-aware Contrastive Learning with Cross-Modal Distillation for ICU Risk Prediction
Pith reviewed 2026-05-10 06:19 UTC · model grok-4.3
The pith
A two-stage training method that uses diagnosis hierarchies for contrastive learning and distills from notes improves vital-signs-only ICU risk prediction and label efficiency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that pretraining an encoder with an ontology-aware contrastive objective based on the ICD hierarchy, followed by fine-tuning via cross-modal knowledge distillation from clinical notes, yields representations that achieve state-of-the-art performance and improved label efficiency on multiple ICU prediction tasks when only vital signs are available at inference.
What carries the argument
The ontology-aware contrastive objective that quantifies patient similarity using the ICD diagnosis hierarchy, paired with the cross-modal knowledge distillation step that transfers information from notes into the vital-signs encoder.
If this is right
- Representations better reflect clinically related patient groups rather than treating all other cases as uniform negatives.
- Higher performance on tasks such as predicting severe deterioration and remaining length of stay.
- Reduced requirement for labeled examples during the fine-tuning stage.
- Leading results among models restricted to vital signs during actual deployment.
Where Pith is reading between the lines
- The same two-stage pattern could apply to other clinical prediction settings where hierarchical medical codes are available for training but only cheaper signals are present at runtime.
- Alternative hierarchical ontologies or similarity graphs might substitute for the ICD structure if they capture different aspects of clinical relatedness.
- Distillation from rich modalities into lean ones offers a route to keep training-time information without raising inference costs.
Load-bearing premise
The ICD diagnosis hierarchy supplies a clinically meaningful similarity metric between patients that improves downstream risk prediction, and knowledge from notes can be distilled into a vital-signs encoder without introducing harmful biases.
What would settle it
If removing either the ICD-based similarity term or the distillation step produces no gain in prediction accuracy or label efficiency on held-out ICU tasks that use only vital signs at test time.
Figures




read the original abstract
Early prediction of severe clinical deterioration and remaining length of stay can enable timely intervention and better resource allocation in high-acuity settings such as the ICU. This has driven the development of machine learning models that leverage continuous streams of vital signs and other physiological signals for real-time risk prediction. Despite their promise, existing methods have important limitations. Contrastive pretraining treats all patients as equally strong negatives, failing to capture clinically meaningful similarity between patients with related diagnoses. Meanwhile, downstream fine-tuning typically ignores complementary modalities such as clinical notes, which provide rich contextual information unavailable in physiological signals alone. To address these challenges, we propose OC-Distill, a two-stage framework that leverages multimodal supervision during training while requiring only vital signs at inference. In the first stage, we introduce an ontology-aware contrastive objective that exploits the ICD hierarchy to quantify patient similarity and learn clinically grounded representations. In the second stage, we fine-tune the pretrained encoder via cross-modal knowledge distillation, transferring complementary information from clinical notes into the model. Across multiple ICU prediction tasks on MIMIC, OC-Distill demonstrates improved label efficiency and achieves state-of-the-art performance among methods that use only vital signs at inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes OC-Distill, a two-stage framework for ICU risk prediction on MIMIC data. Stage 1 performs ontology-aware contrastive pretraining on vital signs, defining patient similarity via the ICD diagnosis hierarchy to create positives and negatives. Stage 2 fine-tunes via cross-modal distillation from clinical notes into the vital-signs encoder. The central claim is that this yields improved label efficiency and state-of-the-art performance on downstream tasks (e.g., clinical deterioration, length-of-stay prediction) among methods restricted to vital signs at inference time.
Significance. If the gains prove robust, the work would demonstrate a practical way to exploit multimodal supervision (notes + ontology) during training while preserving a lightweight unimodal inference model, which is valuable for real-time ICU deployment. The ontology-aware contrastive stage is a distinctive technical choice that could generalize to other hierarchical medical ontologies, provided the similarity metric aligns with physiological signals.
major comments (3)
- [§3.2] §3.2 (Ontology-aware contrastive objective): The positive-pair construction via shared ICD ancestors is load-bearing for the claim that the pretraining stage produces clinically grounded representations. The manuscript must demonstrate that this hierarchy correlates with vital-sign trajectory similarity or downstream risk labels (e.g., via a correlation analysis or a controlled ablation replacing ICD similarity with random or embedding-based pairing); otherwise the reported improvements may be attributable to the distillation stage alone rather than the ontology component.
- [§4] §4 (Experiments and results): The SOTA and label-efficiency claims require explicit reporting of all baselines, exact metrics (AUROC, AUPRC, etc.), standard deviations over multiple random seeds, and statistical significance tests. Without these, it is impossible to verify that the gains exceed variance or post-hoc hyperparameter choices.
- [§4.3] §4.3 (Ablation studies): Ablations that isolate the ontology-aware contrastive loss from a standard (non-ontology) contrastive baseline, and that isolate the distillation stage, are needed to attribute performance improvements to the proposed components rather than dataset artifacts or the multimodal training regime in general.
minor comments (2)
- [Abstract] Abstract: The specific ICU prediction tasks (mortality, LOS, etc.) and evaluation metrics should be named explicitly rather than referred to generically as 'multiple ICU prediction tasks'.
- [§3] Notation: Ensure consistent use of symbols for the contrastive loss temperature, distillation temperature, and ICD depth thresholds across equations and text.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We have revised the manuscript to incorporate additional analyses, ablations, and statistical reporting as requested. Below we address each major comment point by point.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Ontology-aware contrastive objective): The positive-pair construction via shared ICD ancestors is load-bearing for the claim that the pretraining stage produces clinically grounded representations. The manuscript must demonstrate that this hierarchy correlates with vital-sign trajectory similarity or downstream risk labels (e.g., via a correlation analysis or a controlled ablation replacing ICD similarity with random or embedding-based pairing); otherwise the reported improvements may be attributable to the distillation stage alone rather than the ontology component.
Authors: We agree that validating the clinical relevance of the ICD-based pairing is important to substantiate the ontology component's contribution. In the revised manuscript, we have added a correlation analysis in Section 3.2 (and Appendix) demonstrating that patient pairs sharing ICD ancestors exhibit significantly higher similarity in vital-sign trajectories, as measured by dynamic time warping distances on normalized time series. We have also included controlled ablations replacing ICD similarity with random pairing and with embedding-based similarity derived from a pre-trained clinical model. These ablations show degraded downstream performance relative to the ontology-aware approach, indicating that the gains are not attributable solely to the distillation stage. revision: yes
-
Referee: [§4] §4 (Experiments and results): The SOTA and label-efficiency claims require explicit reporting of all baselines, exact metrics (AUROC, AUPRC, etc.), standard deviations over multiple random seeds, and statistical significance tests. Without these, it is impossible to verify that the gains exceed variance or post-hoc hyperparameter choices.
Authors: We acknowledge the need for complete and rigorous reporting to support the SOTA and label-efficiency claims. The revised Section 4 now includes a comprehensive table listing all baselines with exact AUROC, AUPRC, and other metrics. Standard deviations are reported over five random seeds, and we have added paired t-test p-values to establish statistical significance of the improvements over the strongest baselines. revision: yes
-
Referee: [§4.3] §4.3 (Ablation studies): Ablations that isolate the ontology-aware contrastive loss from a standard (non-ontology) contrastive baseline, and that isolate the distillation stage, are needed to attribute performance improvements to the proposed components rather than dataset artifacts or the multimodal training regime in general.
Authors: We agree that isolating the individual contributions of the ontology-aware contrastive objective and the distillation stage is necessary. We have expanded the ablation studies in Section 4.3 to include (1) a standard (non-ontology) contrastive baseline that treats all unpaired patients uniformly as negatives and (2) a variant without the cross-modal distillation stage. Both ablations are evaluated using the same metrics, tasks, and multiple random seeds as the main results, confirming that each proposed component contributes to the observed performance gains. revision: yes
Circularity Check
No circularity: empirical claims rest on external ontology and standard distillation, not self-referential derivations
full rationale
The paper presents a two-stage empirical framework: ontology-aware contrastive pretraining that uses the external ICD hierarchy to define patient similarity, followed by cross-modal distillation from clinical notes into a vital-signs encoder. No equations, closed-form derivations, or fitted parameters are described that reduce any reported prediction or representation to the model's own inputs by construction. Performance gains on MIMIC tasks are measured outcomes on held-out data, not algebraic identities. The ICD hierarchy and notes function as independent external inputs rather than quantities defined in terms of the learned embeddings. This leaves the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Publicly Available Clinical BERT Embeddings
Emily Alsentzer, John R Murphy, Willie Boag, Wei-Hung Weng, Di Jin, Tristan Naumann, and Matthew McDermott. Publicly available clinical bert embeddings.arXiv preprint arXiv:1904.03323,
work page Pith review arXiv 1904
-
[2]
Harshavardhan Battula, Jiacheng Liu, and Jaideep Srivastava. Enhancing in-hospital mortality prediction using multi-representational learning with llm-generated expert summaries.arXiv preprint arXiv:2411.16818,
-
[3]
A Simple Framework for Contrastive Learning of Visual Representations
URLhttps://arxiv.org/abs/2002.05709. Alberto Coustasse. Upcoding medicare: is healthcare fraud and abuse increasing?Perspectives in health information management, 18(4):1f,
work page internal anchor Pith review arXiv 2002
-
[4]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
URLhttps://arxiv.org/abs/ 1810.04805. Sirui Ding, Jiancheng Ye, Xia Hu, and Na Zou. Distilling the knowledge from large-language model for health event prediction.Scientific Reports, 14(1):30675,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Ashish Jaiswal, Ashwin Ramesh Babu, Mohammad Zaki Zadeh, Debapriya Banerjee, and Fillia Makedon
URLhttps://arxiv.org/ abs/2506.13104. Ashish Jaiswal, Ashwin Ramesh Babu, Mohammad Zaki Zadeh, Debapriya Banerjee, and Fillia Makedon. A survey on contrastive self-supervised learning,
-
[6]
URLhttps://arxiv.org/ abs/2011.00362. Alistair EW Johnson, Tom J Pollard, Lu Shen, Li-wei H Lehman, Mengling Feng, Mohammad Ghassemi, Benjamin Moody, Peter Szolovits, Leo Anthony Celi, and Roger G Mark. Mimic-iii, a freely accessible critical care database.Scientific data, 3(1):1–9,
-
[7]
Baraa Al Jorf and Farah Shamout. Medpatch: Confidence-guided multi-stage fusion for multimodal clinical data.arXiv preprint arXiv:2508.09182,
-
[8]
Sara Ketabi and Dhanesh Ramachandram. Bridging electronic health records and clinical texts: Contrastive learning for enhanced clinical tasks.arXiv preprint arXiv:2505.17643,
-
[9]
Ziyu Liu, Azadeh Alavi, Minyi Li, and Xiang Zhang
URLhttps://arxiv.org/abs/ 2502.19625. Ziyu Liu, Azadeh Alavi, Minyi Li, and Xiang Zhang. Self-supervised contrastive learning for medical time series: A systematic review.Sensors, 23(9):4221,
-
[10]
A multimodal transformer: Fusing clinical notes with structured ehr data for in- terpretable in-hospital mortality prediction
Weimin Lyu, Xinyu Dong, Rachel Wong, Songzhu Zheng, Kayley Abell-Hart, Fusheng Wang, and Chao Chen. A multimodal transformer: Fusing clinical notes with structured ehr data for in- terpretable in-hospital mortality prediction. InAMIA Annual Symposium Proceedings, volume 2022, page 719,
2022
-
[11]
YongKyung Oh and Alex Bui. Multi-view contrastive learning for robust domain adaptation in medical time series analysis.arXiv preprint arXiv:2506.22393,
-
[12]
Elaine Silverman and Jonathan Skinner
URLhttps://arxiv.org/ abs/2003.11059. Elaine Silverman and Jonathan Skinner. Medicare upcoding and hospital ownership.Journal of health economics, 23(2):369–389,
- [13]
-
[14]
URLhttps://arxiv.org/ abs/1706.03762. Shirly Wang, Matthew BA McDermott, Geeticka Chauhan, Marzyeh Ghassemi, Michael C Hughes, and Tristan Naumann. Mimic-extract: A data extraction, preprocessing, and representation pipeline for mimic-iii. InProceedings of the ACM conference on health, inference, and learning, pages 222–235,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
The immunopathology of sepsis and potential therapeutic targets
URLhttps://arxiv. org/abs/2203.14469. Addison Weatherhead, Robert Greer, Michael-Alice Moga, Mjaye Mazwi, Danny Eytan, Anna Gold- enberg, and Sana Tonekaboni. Learning unsupervised representations for icu timeseries. InCon- ference on Health, Inference, and Learning, pages 152–168. PMLR,
-
[16]
3d cgan based cross- modality mr image synthesis for brain tumor segmentation
Biting Yu, Luping Zhou, Lei Wang, Jurgen Fripp, and Pierrick Bourgeat. 3d cgan based cross- modality mr image synthesis for brain tumor segmentation. In2018 IEEE 15th international symposium on biomedical imaging (ISBI 2018), pages 626–630. IEEE,
2018
-
[17]
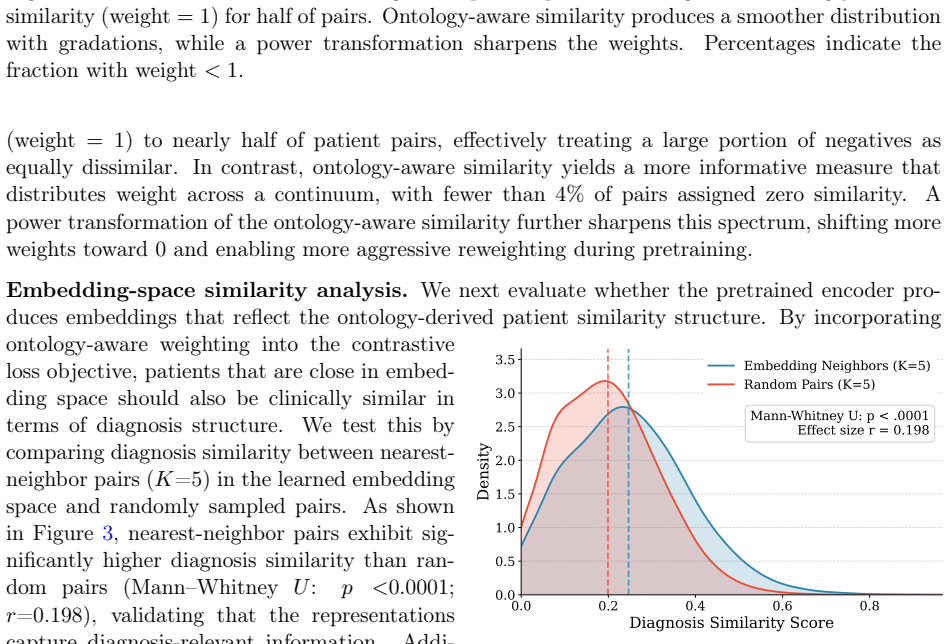
As shown in Table 11, the conclusion is stable across all choices of K: nearest-neighbor pairs consistently exhibit higher diagnosis similarity than randomly sampled pairs, and all differences remain statistically significant. KKNN Mean Random Mean Effect SizerMann–Whitneyp 1 0.251 0.200 0.214<0.0001 3 0.248 0.200 0.205<0.0001 5 0.246 0.199 0.198<0.0001 T...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.