Recognition: unknown
SinkRouter: Sink-Aware Routing for Efficient Long-Context Decoding in Large Language and Multimodal Models
Pith reviewed 2026-05-10 07:52 UTC · model grok-4.3
The pith
Attention sinks form stable fixed points from training that let models skip near-zero computations during long-context decoding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
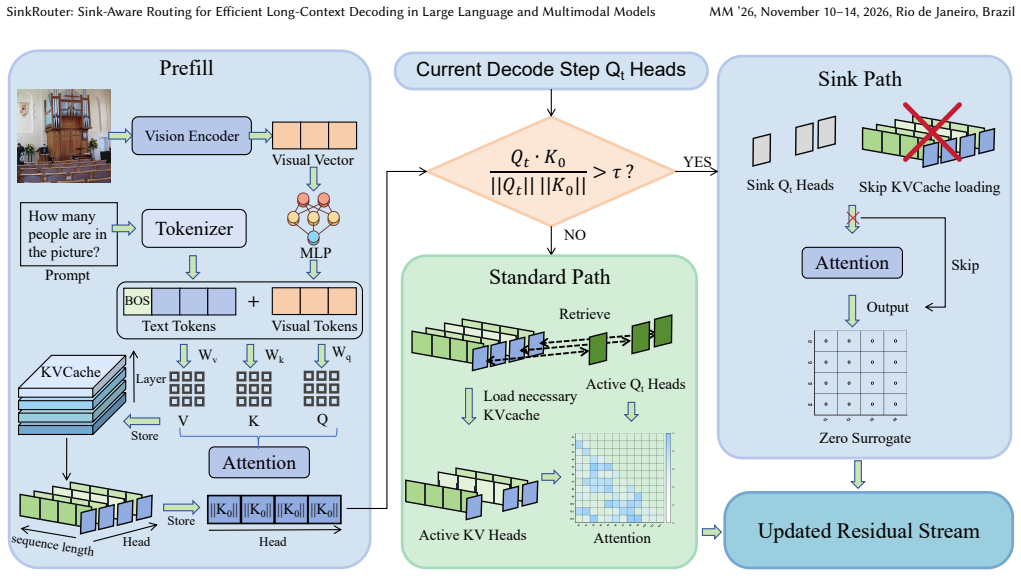
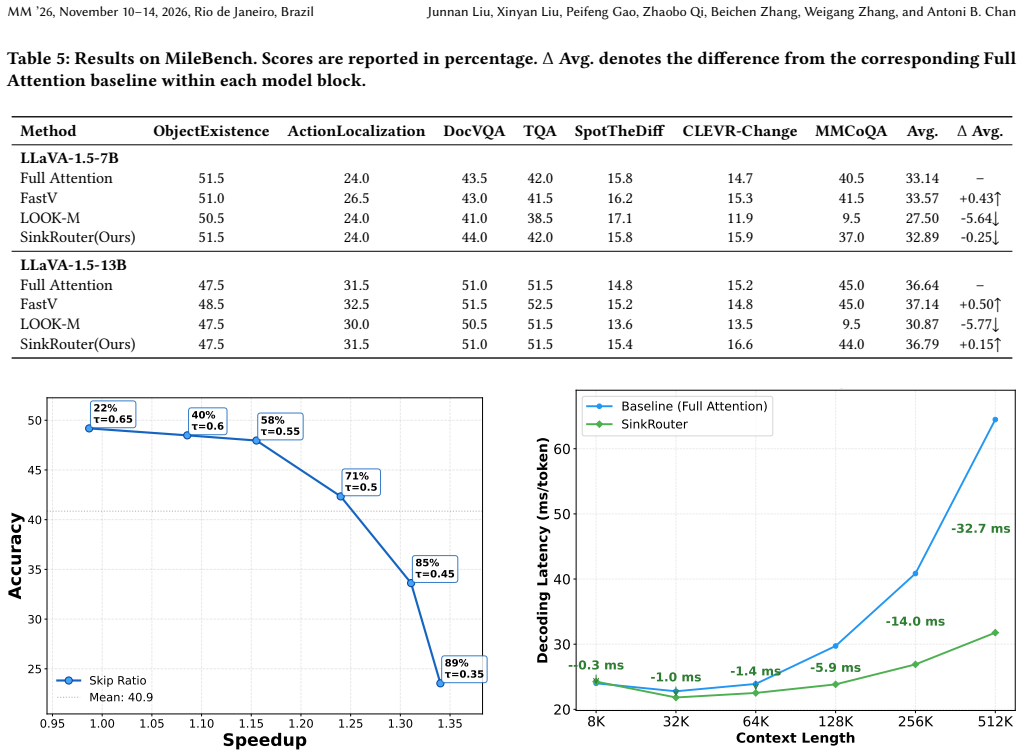
The attention sink phenomenon corresponds to a stable, reachable, and error-controllable fixed point constructed during training. SinkRouter detects the sink signal and skips computations that would otherwise produce near-zero output. This mechanism is implemented via a hardware-aware Triton kernel with block-level branching and Split-K parallelism, delivering up to 2.03x speedup on 512K contexts across models such as Llama-3.1-8B, Llama-3.1-70B, Yi-9B-200K, LLaVA-1.5-7B, and LLaVA-1.5-13B on benchmarks including LongBench, InfiniteBench, CVBench, MileBench, and MMVP.
What carries the argument
The sink signal, identified from partial attention scores, marks the fixed point and enables selective routing that bypasses near-zero output computations.
If this is right
- Decoding steps can avoid loading large portions of the KV-cache when sink signals are present, reducing memory bandwidth pressure.
- The routing method works without any additional training on both language and multimodal backbones.
- Speedups reach approximately 2x at context lengths of 512K tokens while accuracy remains competitive on standard long-context suites.
- Block-level branching and Split-K parallelism in the kernel translate the fixed-point insight into practical GPU efficiency gains.
Where Pith is reading between the lines
- The fixed-point framing of sinks could extend to analyzing attention patterns in other sequence models or to designing new attention regularizers during pretraining.
- Early sink detection might enable adaptive context management that dynamically prunes or compresses non-critical segments in streaming applications.
- If the error-controllability holds more broadly, similar routing ideas could apply to other sparse or low-magnitude operations inside transformer layers.
Load-bearing premise
The sink signal can be detected reliably from partial attention scores without full KV-cache computation, and skipping those operations never discards task-critical information across models and domains.
What would settle it
A direct measurement showing that skipping operations flagged by the sink detector causes a substantial drop in accuracy on a long-context task, or that reliable sink detection requires the complete attention computation rather than partial scores.
Figures








read the original abstract
In long-context decoding for LLMs and LMMs, attention becomes increasingly memory-bound because each decoding step must load a large amount of KV-cache data from GPU memory. Existing acceleration strategies often trade efficiency for accuracy by relying on heuristic pruning that may discard useful information. At a deeper level, they also tend to indiscriminately preserve all high-scoring tokens, treat early tokens as indispensable anchors, or rely on heuristic head routing, reflecting an insufficient mechanistic understanding of the attention sink phenomenon. In this paper, we show that the attention sink phenomenon corresponds to a stable, reachable, and error-controllable fixed point constructed during training. Based on this insight, we propose SinkRouter, a training-free selective routing framework that detects the sink signal and skips computations that would otherwise produce near-zero output. To translate this mechanism into real-world acceleration, we develop a hardware-aware Triton kernel with block-level branching and Split-K parallelism. We conduct extensive evaluations on a diverse suite of long-context benchmarks, including LongBench, InfiniteBench, CVBench, MileBench, and MMVP, using both text-only and multimodal backbones such as Llama-3.1-8B, Llama-3.1-70B, Yi-9B-200K, LLaVA-1.5-7B, and LLaVA-1.5-13B. Across these settings, SinkRouter consistently improves decoding efficiency while maintaining competitive accuracy, and reaches 2.03x speedup with a 512K context.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the attention sink phenomenon corresponds to a stable, reachable, and error-controllable fixed point constructed during training. Based on this, it introduces SinkRouter, a training-free selective routing framework that detects the sink signal and skips computations producing near-zero outputs. A hardware-aware Triton kernel with block-level branching and Split-K parallelism is developed for acceleration. Evaluations on LongBench, InfiniteBench, CVBench, MileBench, and MMVP using Llama-3.1-8B, Llama-3.1-70B, Yi-9B-200K, LLaVA-1.5-7B, and LLaVA-1.5-13B report consistent accuracy with up to 2.03x speedup at 512K context.
Significance. If the fixed-point characterization holds with verifiable error bounds, this could provide a mechanistically grounded alternative to heuristic KV-cache pruning for long-context inference, with the broad benchmark coverage across text and multimodal models strengthening the case for practical impact. The Triton kernel implementation addresses deployment realities, but the absence of formal guarantees on lossless skipping reduces the theoretical significance relative to the empirical speedups.
major comments (2)
- Abstract: The claim that the attention sink 'corresponds to a stable, reachable, and error-controllable fixed point constructed during training' is presented without derivation, training-dynamics analysis, or error bound, yet this property directly licenses the training-free detection and skipping that underpins the routing framework and 2.03x speedup.
- Abstract: No formal analysis or bound is given for the approximation error when detecting the sink from partial attention scores without full KV-cache computation, nor evidence that skipping never discards task-critical information; this is load-bearing for the reliability claim across models and domains.
Simulated Author's Rebuttal
Thank you for your thorough review and constructive feedback on our manuscript. We appreciate the emphasis on strengthening the theoretical grounding of our claims and address each major comment point by point below, proposing targeted revisions where appropriate.
read point-by-point responses
-
Referee: Abstract: The claim that the attention sink 'corresponds to a stable, reachable, and error-controllable fixed point constructed during training' is presented without derivation, training-dynamics analysis, or error bound, yet this property directly licenses the training-free detection and skipping that underpins the routing framework and 2.03x speedup.
Authors: We thank the referee for highlighting the need for clearer linkage between the abstract claim and supporting evidence. While the abstract is concise by design, the full manuscript provides the requested elements in Section 3, which includes training-dynamics analysis across multiple models and checkpoints demonstrating consistent sink emergence (stability and reachability) and in Section 4.2, which quantifies output deviation to establish error controllability. We will revise the abstract to explicitly reference these sections and add a concise summary paragraph on the empirical characterization of the fixed-point property to make the connection more direct. revision: partial
-
Referee: Abstract: No formal analysis or bound is given for the approximation error when detecting the sink from partial attention scores without full KV-cache computation, nor evidence that skipping never discards task-critical information; this is load-bearing for the reliability claim across models and domains.
Authors: We agree that formal analysis would further strengthen the reliability claims. The manuscript currently supports these aspects through extensive empirical results in Sections 5 and 6, where sink detection from partial attention scores maintains competitive accuracy (average degradation <0.5%) across text and multimodal benchmarks without discarding critical tokens, as verified by per-task breakdowns. In the revision, we will add a dedicated subsection with approximate error bounds based on attention score distributions and sensitivity analyses confirming preservation of task-critical information. This addresses the concern while preserving the training-free nature of the method. revision: partial
Circularity Check
No significant circularity; derivation relies on empirical observation and external benchmarks
full rationale
The paper states that attention sinks correspond to a stable fixed point constructed during training, then proposes SinkRouter based on this insight for detection and skipping. No equations, self-citations, or definitions are provided that reduce the fixed-point claim or the detection logic to a tautology or fitted input by construction. The evaluations on LongBench, InfiniteBench, CVBench, MileBench, MMVP and multiple models (Llama-3.1, Yi, LLaVA) serve as independent validation of accuracy preservation rather than internal redefinition. The hardware-aware Triton kernel further decouples the implementation from the mechanistic claim.
Axiom & Free-Parameter Ledger
free parameters (1)
- sink detection threshold
axioms (1)
- domain assumption Attention sink is a stable, reachable, error-controllable fixed point constructed during training
Reference graph
Works this paper leans on
-
[1]
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. 2024. LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ...
-
[2]
Payman Behnam, Yaosheng Fu, Ritchie Zhao, Po-An Tsai, Zhiding Yu, and Alexey Tumanov. 2026. RocketKV: accelerating long-context LLM inference via two- stage KV cache compression. InProceedings of the 42nd International Conference on Machine Learning(Vancouver, Canada)(ICML’25). JMLR.org, Vancouver, Canada, Article 123, 35 pages
2026
-
[3]
Yelysei Bondarenko, Markus Nagel, and Tijmen Blankevoort. 2023. Quantizable transformers: removing outliers by helping attention heads do nothing. InPro- ceedings of the 37th International Conference on Neural Information Processing Systems(New Orleans, LA, USA)(NIPS ’23). Curran Associates Inc., Red Hook, NY, USA, Article 3282, 30 pages
2023
-
[4]
Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. 2024. An Image is Worth 1/2 Tokens After Layer 2: Plug-and-Play Inference Acceleration for Large Vision-Language Models. InComputer Vision – ECCV 2024: 18th European Conference, Milan, Italy, September 29–October 4, 2024, Proceedings, Part LXXXI(Milan, Italy). Sprin...
-
[5]
Tri Dao. 2024. FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning. InThe Twelfth International Conference on Learning Repre- sentations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, Vienna, Austria, 1–14. https://openreview.net/forum?id=mZn2Xyh9Ec
2024
-
[6]
Timothée Darcet, Maxime Oquab, Julien Mairal, and Piotr Bojanowski. 2024. Vision Transformers Need Registers. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenRe- view.net, Vienna, Austria, 1–21. https://openreview.net/forum?id=2dnO3LLiJ1
2024
- [7]
-
[8]
Song Dingjie, Shunian Chen, Guiming Hardy Chen, Fei Yu, Xiang Wan, and Benyou Wang. 2024. MileBench: Benchmarking MLLMs in Long Context. In First Conference on Language Modeling. Philadelphia, PA, USA, 1–31. https: //openreview.net/forum?id=Uhwze2LEwq
2024
-
[9]
Harry Dong, Xinyu Yang, Zhenyu Zhang, Zhangyang Wang, Yuejie Chi, and Beidi Chen. 2024. Get more with LESS: synthesizing recurrence with KV cache compression for efficient LLM inference. InProceedings of the 41st International Conference on Machine Learning (ICML’24). JMLR.org, Vienna, Austria, Article 454, 16 pages
2024
- [10]
-
[11]
Suyu Ge, Yunan Zhang, Liyuan Liu, Minjia Zhang, Jiawei Han, and Jianfeng Gao
-
[12]
InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024
Model Tells You What to Discard: Adaptive KV Cache Compression for LLMs. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, Vienna, Austria, 1–14. https://openreview.net/forum?id=uNrFpDPMyo
2024
-
[13]
Xiangming Gu, Tianyu Pang, Chao Du, Qian Liu, Fengzhuo Zhang, Cunxiao Du, Ye Wang, and Min Lin. 2025. When Attention Sink Emerges in Language Models: An Empirical View. InThe Thirteenth International Conference on Learning Repre- sentations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, Singapore, 1–31. https://openreview.net/forum?id=78Nn4QJTEN
2025
- [14]
-
[15]
Abdi, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, and Lili Qiu
Huiqiang Jiang, Yucheng Li, Chengruidong Zhang, Qianhui Wu, Xufang Luo, Surin Ahn, Zhenhua Han, Amir H. Abdi, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. 2024. MInference 1.0: accelerating pre-filling for long-context LLMs via dynamic sparse attention. InProceedings of the 38th International Con- ference on Neural Information Processing Systems...
2024
-
[16]
Dongwon Jo, Jiwon Song, Yulhwa Kim, and Jae-Joon Kim. 2026. FastKV: De- coupling of Context Reduction and KV Cache Compression for Prefill-Decoding Acceleration. arXiv:2502.01068 [cs.LG] https://arxiv.org/abs/2502.01068
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
Seil Kang, Jinyeong Kim, Junhyeok Kim, and Seong Jae Hwang. 2025. See What You Are Told: Visual Attention Sink in Large Multimodal Models. InThe Thir- teenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, Singapore, 1–28. https://openreview.net/ forum?id=7uDI7w5RQA
2025
-
[18]
Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen. 2024. SnapKV: LLM Knows What You are Looking for Before Generation. arXiv:2404.14469 [cs.CL] https://arxiv.org/abs/2404.14469
work page internal anchor Pith review arXiv 2024
-
[19]
Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen. 2024. SnapKV: LLM knows what you are looking for before generation. InProceedings of the 38th International Conference on Neural Information Processing Systems(Vancouver, BC, Canada)(NIPS ’24). Curran Associates Inc., Red Hook, ...
2024
-
[20]
Zichang Liu, Aditya Desai, Fangshuo Liao, Weitao Wang, Victor Xie, Zhaozhuo Xu, Anastasios Kyrillidis, and Anshumali Shrivastava. 2023. Scissorhands: Exploit- ing the Persistence of Importance Hypothesis for LLM KV Cache Compression at Test Time. InAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Sys...
2023
-
[21]
Zichang Liu, Jue Wang, Tri Dao, Tianyi Zhou, Binhang Yuan, Zhao Song, An- shumali Shrivastava, Ce Zhang, Yuandong Tian, Christopher Re, and Beidi Chen. 2023. Deja Vu: Contextual Sparsity for Efficient LLMs at Inference Time. arXiv:2310.17157 [cs.LG] https://arxiv.org/abs/2310.17157
- [22]
-
[23]
Zihan Qiu, Zekun Wang, Bo Zheng, Zeyu Huang, Kaiyue Wen, Songlin Yang, Rui Men, Le Yu, Fei Huang, Suozhi Huang, Dayiheng Liu, Jingren Zhou, and Junyang Lin. 2025. Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free.CoRRabs/2505.06708 (2025), 1–17. arXiv:2505.06708 doi:10.48550/ARXIV.2505.06708
work page internal anchor Pith review doi:10.48550/arxiv.2505.06708 2025
-
[24]
Hanshi Sun, Li-Wen Chang, Wenlei Bao, Size Zheng, Ningxin Zheng, Xin Liu, Harry Dong, Yuejie Chi, and Beidi Chen. 2025. ShadowKV: KV Cache in Shad- ows for High-Throughput Long-Context LLM Inference. InForty-second Interna- tional Conference on Machine Learning, ICML 2025, Vancouver, BC, Canada, July 13-19, 2025 (Proceedings of Machine Learning Research),...
2025
-
[25]
Llama Team. 2024. The Llama 3 Herd of Models.CoRRabs/2407.21783 (2024), 1–92. arXiv:2407.21783 doi:10.48550/ARXIV.2407.21783
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783 2024
-
[26]
Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, and Saining Xie. 2024. Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs. arXiv:2401.06209 [cs.CV] https://arxiv.org/abs/2401.06209 MM ’26, November 10–14, 2026, Rio de Janeiro, Brazil Junnan Liu, Xinyan Liu, Peifeng Gao, Zhaobo Qi, Beichen Zhang, Weigang Zhang, and Antoni B. Chan
-
[27]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yas- mine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhos- ale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucu- rull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Zhongwei Wan, Ziang Wu, Che Liu, Jinfa Huang, Zhihong Zhu, Peng Jin, Longyue Wang, and Li Yuan. 2024. LOOK-M: Look-Once Optimization in KV Cache for Efficient Multimodal Long-Context Inference. InFindings of the Association for Computational Linguistics: EMNLP 2024, Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (Eds.). Association for Computational Li...
-
[29]
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. 2024. Efficient Streaming Language Models with Attention Sinks. InThe Twelfth In- ternational Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, Vienna, Austria, 1–21. https://openreview.net/ forum?id=NG7sS51zVF
2024
-
[30]
Suho Yoo, Youngjoon Jang, and Joon Son Chung. 2026. On the Nature of Attention Sink that Shapes Decoding Strategy in MLLMs. arXiv:2603.14337 [cs.CV] https: //arxiv.org/abs/2603.14337
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
Jingyang Yuan, Huazuo Gao, Damai Dai, Junyu Luo, Liang Zhao, Zhengyan Zhang, Zhenda Xie, Yuxing Wei, Lean Wang, Zhiping Xiao, Yuqing Wang, Chong Ruan, Ming Zhang, Wenfeng Liang, and Wangding Zeng. 2025. Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention. InACL (1). Association for Computational Linguistics, Vienna, Austria, ...
2025
-
[32]
Ted Zadouri, Hubert Strauss, and Tri Dao. 2025. Hardware-Efficient Attention for Fast Decoding. InES-FoMo III: 3rd Workshop on Efficient Systems for Foundation Models. 1–37. https://openreview.net/forum?id=8ixiZ1b8rr
2025
-
[33]
Xinrong Zhang, Yingfa Chen, Shengding Hu, Zihang Xu, Junhao Chen, Moo Hao, Xu Han, Zhen Thai, Shuo Wang, Zhiyuan Liu, and Maosong Sun. 2024. ∞Bench: Extending Long Context Evaluation Beyond 100K Tokens. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Lun-Wei Ku, Andre Martins, and Vivek Sr...
2024
-
[34]
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Ré, Clark Barrett, Zhangyang "At- las" Wang, and Beidi Chen. 2023. H2O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models. InAdvances in Neural In- formation Processing Systems, A. Oh, T. Naumann, A. Globerson...
2023
-
[35]
Nannan Zhu, Yonghao Dong, Teng Wang, Xueqian Li, Shengjun Deng, Yijia Wang, Zheng Hong, Tiantian Geng, Guo Niu, Hanyan Huang, Xiongfei Yao, and Shuaiwei Jiao. 2026. CVBench: Benchmarking Cross-Video Synergies for Complex Multimodal Reasoning. arXiv:2508.19542 [cs.CV] https://arxiv.org/abs/ 2508.19542 SinkRouter: Sink-Aware Routing for Efficient Long-Conte...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.