Recognition: unknown
Chain Of Interaction Benchmark (COIN): When Reasoning meets Embodied Interaction
Pith reviewed 2026-05-10 06:46 UTC · model grok-4.3
The pith
New benchmark shows embodied AI models struggle with chained interactive tasks
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that generalist embodied agents need interactive, causally-dependent reasoning to solve long-horizon tasks by continually interacting with the environment, acquiring information, and updating plans under partial observability, yet existing methods fail at this due to significant gaps between visual understanding and motor execution, as demonstrated through the new COIN benchmark's tasks, dataset, and evaluation metrics.
What carries the argument
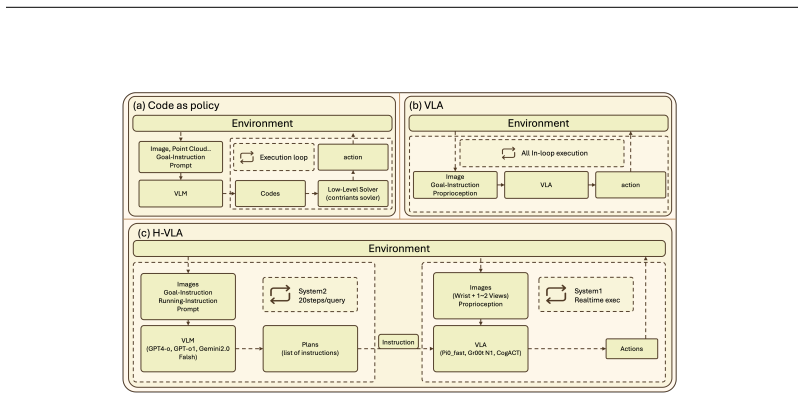
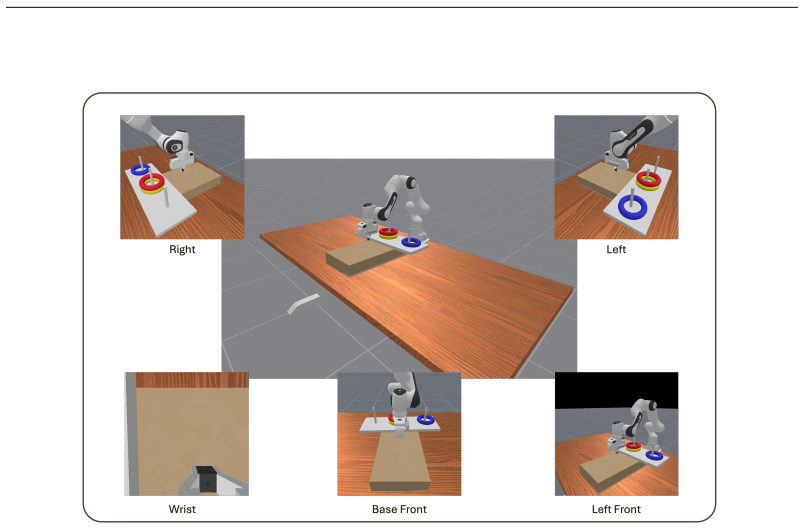
The COIN benchmark, which organizes robotic manipulation into chains of causally-dependent interactive tasks with separate primitive and composition sets, a collected demonstration dataset, and metrics focused on execution stability plus generalization robustness.
If this is right
- Current approaches including CodeAsPolicy and language-conditioned vision-language-action models show critical limitations when required to handle interactive reasoning under partial observability.
- Gaps between visual perception and motor execution prevent reliable performance on tasks that demand sequential information gathering and plan adaptation.
- Metrics centered on execution stability and generalization robustness can systematically expose these shortcomings across different model types.
- Fine-grained analysis of failures in chained interactions supplies concrete directions for improving the integration of reasoning and physical actions.
Where Pith is reading between the lines
- If the benchmark tasks scale to more varied real-world settings, closing the identified gaps could shorten the path to deploying robots in unstructured home or industrial environments.
- The primitive dataset and composition tasks offer a structured way to test whether new training regimes that explicitly model causal dependencies outperform current end-to-end methods.
- Persistent shortfalls on these tasks even with larger models would suggest that architectural additions for explicit interaction chaining are necessary rather than relying on scale alone.
Load-bearing premise
The 50 tasks and chosen metrics for execution stability and generalization robustness accurately capture the essential interactive reasoning capability required for real-life robotic scenarios.
What would settle it
A controlled test in which one of the evaluated models completes at least 80 percent of the COIN-50 tasks with stable execution sequences and successful generalization to unseen compositions would indicate that the reported gaps between visual understanding and motor execution do not hold.
Figures



read the original abstract
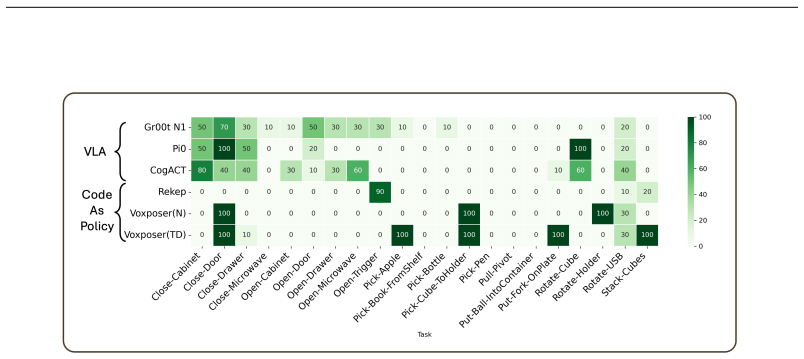
Generalist embodied agents must perform interactive, causally-dependent reasoning, continually interacting with the environment, acquiring information, and updating plans to solve long-horizon tasks before they could be adopted in real-life scenarios. For instance, retrieving an apple from a cabinet may require opening multiple doors and drawers before the apple becomes visible and reachable, demanding sequential interaction under partial observability. However, existing benchmarks fail to systematically evaluate this essential capability. We introduce COIN, a benchmark designed to assess interactive reasoning in realistic robotic manipulation through three key contributions. First, we construct COIN-50: 50 interactive tasks in daily scenarios, and create COIN-Primitive required by causally-dependent tasks, and COIN-Composition with mid-term complexity for skill learning and generalization evaluation. Second, we develop a low-cost mobile AR teleoperation system and collect the COIN-Primitive Dataset with 50 demonstrations per primitive task (1,000 in total). Third, we develop systematic evaluation metrics about execution stability and generalization robustness to evaluate CodeAsPolicy, VLA, and language-conditioned H-VLA approaches. Our comprehensive evaluation reveals critical limitations in current methods: models struggle with interactive reasoning tasks due to significant gaps between visual understanding and motor execution. We provide fine-grained analysis of these limitations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the COIN benchmark to evaluate interactive, causally-dependent reasoning in embodied robotic agents under partial observability. It presents COIN-50 (50 daily manipulation tasks), COIN-Primitive (basic skills with 1,000 demonstrations collected via low-cost AR teleoperation), and COIN-Composition (mid-complexity tasks for generalization). Systematic metrics for execution stability and generalization robustness are defined to assess CodeAsPolicy, VLA, and language-conditioned H-VLA methods. The evaluation concludes that current models exhibit critical limitations due to gaps between visual understanding and motor execution, supported by fine-grained analysis.
Significance. If the benchmark tasks and metrics validly isolate interactive reasoning from low-level control and data issues, the work could provide a useful diagnostic tool for long-horizon embodied agents and highlight actionable gaps in VLA approaches. The low-cost data collection pipeline and public dataset are practical strengths that could accelerate reproducible research in this area.
major comments (3)
- [Abstract and §5] Abstract and §5 (Evaluation): The central claim that failures stem from 'significant gaps between visual understanding and motor execution' is not supported by explicit per-failure-mode breakdowns (e.g., incorrect sequence planning vs. imprecise primitive execution) or ablations (oracle perception, perfect low-level controller). Without these, poor performance on COIN-Primitive/Composition could arise from embodiment mismatch, demonstration scarcity, or metric sensitivity rather than the claimed reasoning deficit under partial observability.
- [§3] §3 (Benchmark Construction): The 50 tasks in COIN-50 and the definitions of execution stability/generalization robustness lack reported controls for confounding factors such as task difficulty, causal dependency depth, or overlap with model pretraining data. This undermines the claim that the benchmark systematically captures 'essential interactive reasoning capability' for real-life scenarios.
- [§4] §4 (Dataset and Metrics): No statistical significance tests, inter-task variance analysis, or human baseline comparisons are described for the reported performance gaps. This makes it difficult to assess whether the observed limitations are robust or sensitive to the specific 50-demonstration-per-primitive collection protocol.
minor comments (2)
- [§3] Notation for COIN-Primitive vs. COIN-Composition should be clarified with explicit task counts and dependency graphs in a single table for reproducibility.
- [§4] The AR teleoperation system description would benefit from quantitative metrics on collection time, error rates, and calibration procedure to allow independent replication.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. We address each major comment point by point below, indicating where revisions will be made to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract and §5] Abstract and §5 (Evaluation): The central claim that failures stem from 'significant gaps between visual understanding and motor execution' is not supported by explicit per-failure-mode breakdowns (e.g., incorrect sequence planning vs. imprecise primitive execution) or ablations (oracle perception, perfect low-level controller). Without these, poor performance on COIN-Primitive/Composition could arise from embodiment mismatch, demonstration scarcity, or metric sensitivity rather than the claimed reasoning deficit under partial observability.
Authors: We appreciate this observation. Section 5 already includes a fine-grained analysis that categorizes observed failures into planning, perception, and execution categories with examples. However, we agree that the central claim would be more robustly supported by explicit ablations (such as oracle perception or a perfect low-level controller) and more detailed per-failure-mode breakdowns. We will add these elements to the revised §5 to better isolate the contribution of interactive reasoning deficits under partial observability. revision: yes
-
Referee: [§3] §3 (Benchmark Construction): The 50 tasks in COIN-50 and the definitions of execution stability/generalization robustness lack reported controls for confounding factors such as task difficulty, causal dependency depth, or overlap with model pretraining data. This undermines the claim that the benchmark systematically captures 'essential interactive reasoning capability' for real-life scenarios.
Authors: The task design in COIN-50 was intentionally structured around varying levels of causal dependency and real-world daily scenarios, with primitives selected to reflect essential interactive skills. We acknowledge that explicit quantitative controls and reporting for task difficulty, dependency depth, and pretraining overlap were not included. We will revise §3 to add these controls, including dependency depth metrics and pretraining data checks, to strengthen the claim that COIN systematically evaluates interactive reasoning. revision: yes
-
Referee: [§4] §4 (Dataset and Metrics): No statistical significance tests, inter-task variance analysis, or human baseline comparisons are described for the reported performance gaps. This makes it difficult to assess whether the observed limitations are robust or sensitive to the specific 50-demonstration-per-primitive collection protocol.
Authors: We agree that adding statistical significance testing, inter-task variance reporting, and human baseline comparisons would improve the assessment of robustness. We will incorporate these analyses (including appropriate statistical tests for the performance gaps) into the revised §4 and §5, while retaining the 50-demonstration protocol as a practical low-cost baseline. revision: yes
Circularity Check
No circularity: benchmark introduction with independent empirical evaluation
full rationale
The paper constructs COIN-50 tasks, collects a teleoperation dataset, defines execution stability and generalization robustness metrics, and evaluates external methods (CodeAsPolicy, VLA, H-VLA) on them. No equations, parameter fits, or derivations appear in the provided text. The central claim about gaps between visual understanding and motor execution is an empirical observation from the benchmark results rather than a reduction to self-defined inputs or self-citations. The methodology is self-contained as a standard benchmark release with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, and Ury Zhilinsky. Π0: A Visi...
work page internal anchor Pith review arXiv
-
[2]
Accessed: 2025-05-07. Yunhai Feng, Jiaming Han, Zhuoran Yang, Xiangyu Yue, Sergey Levine, and Jianlan Luo. Reflective planning: Vision-language models for multi-stage long-horizon robotic manipulation. URL http://arxiv.org/abs/2502.16707. Figure AI. Helix: A vision-language-action model for generalist humanoid control. https: //www.figure.ai/news/helix, February
-
[3]
Accessed: 2025-04-27. Haoran Geng, Feishi Wang, Songlin Wei, Yuyang Li, Bangjun Wang, Boshi An, Charlie Tianyue Cheng, Haozhe Lou, Peihao Li, Yen-Jen Wang, Yutong Liang, Dylan Goetting, Chaoyi Xu, Haozhe Chen, Yuxi Qian, Yiran Geng, Jiageng Mao, Weikang Wan, Mingtong Zhang, Jiangran Lyu, Siheng Zhao, Jiazhao Zhang, Jialiang Zhang, Chengyang Zhao, Haoran L...
2025
-
[4]
URL https://arxiv.org/abs/2504.18904. Ran Gong, Jiangyong Huang, Yizhou Zhao, Haoran Geng, Xiaofeng Gao, Qingyang Wu, Wensi Ai, Ziheng Zhou, Demetri Terzopoulos, Song-Chun Zhu, Baoxiong Jia, and Siyuan Huang. Arnold: A benchmark for language-grounded task learning with continuous states in realistic 3d scenes,
-
[5]
URLhttps://arxiv.org/abs/2304.04321. Sanjay Haresh, Daniel Dijkman, Apratim Bhattacharyya, and Roland Memisevic. ClevrSkills: Compositional language and visual reasoning in robotics. URL https://openreview.net/ forum?id=64sZtFSOh6#discussion. 10 Haoxu Huang, Fanqi Lin, Yingdong Hu, Shengjie Wang, and Yang Gao. CoPa: General robotic manipulation through sp...
-
[6]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
URL https://developer.apple.com/ augmented-reality/arkit/. Augmented reality framework for iOS. Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ashwin Balakrishna, Sudeep Dasari, Siddharth Karamcheti, Soroush Nasiriany, Mohan Kumar Srirama, Lawrence Yunliang Chen, Kirsty Ellis, et al. Droid: A large-scale in-the-wild robot manipulation dataset.arXiv prepri...
work page internal anchor Pith review arXiv
-
[7]
URL https://arxiv.org/abs/2304.02643. Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, et al. Segment anything model
work page internal anchor Pith review arXiv
-
[8]
URLhttps://arxiv.org/abs/2404.14192. Chengshu Li et al. Evaluating real-world robot manipulation policies in simulation
-
[10]
Evaluating Real-World Robot Manipulation Policies in Simulation
Xuanlin Li, Kyle Hsu, Jiayuan Gu, Karl Pertsch, Oier Mees, Homer Rich Walke, Chuyuan Fu, Ishikaa Lunawat, Isabel Sieh, Sean Kirmani, Sergey Levine, Jiajun Wu, Chelsea Finn, Hao Su, Quan Vuong, and Ted Xiao. Evaluating real-world robot manipulation policies in simulation, b. URL http://arxiv.org/abs/2405.05941. Percy Liang, Rishi Chen, Po-Hsun Huang, Nikhi...
work page internal anchor Pith review arXiv
-
[11]
Code as Policies: Language Model Programs for Embodied Control
URLhttps://arxiv.org/abs/2209.07753. Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. LIBERO: Benchmarking knowledge transfer for lifelong robot learning. URL http://arxiv.org/ abs/2306.03310. Google LLC. Arcore - google developers
work page internal anchor Pith review arXiv
-
[12]
URL https://developers.google.com/ ar. Augmented reality platform for Android. Oier Mees, Lukas Hermann, Erick Rosete-Beas, and Wolfram Burgard. CALVIN: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks. URL http: //arxiv.org/abs/2112.03227. NVIDIA, :, Alisson Azzolini, Hannah Brandon, Prithvijit Chattopadhyay,...
-
[13]
com/omarrayyann/mujocoar
URL https://github. com/omarrayyann/mujocoar. Sketchfab. Sketchfab - the leading platform for 3d & ar on the web.https://sketchfab.com/. Accessed: 2025-05-07. Stone Tao, Fanbo Xiang, Arth Shukla, Yuzhe Qin, Xander Hinrichsen, Xiaodi Yuan, and Lin. MANISKILL3: GPU PARALLELIZED ROBOTICS SIMULATION AND RENDERING FOR GENERALIZABLE EMBODIED AI. Gemini Robotics...
2025
-
[14]
Gemini Robotics: Bringing AI into the Physical World
URLhttps://arxiv.org/abs/2503.20020. Fanbo Xiang, Yuzhe Qin, Kaichun Mo, Yikuan Xia, Hao Zhu, Fangchen Liu, Minghua Liu, Hanxiao Jiang, Yifu Yuan, He Wang, et al. Sapien: A simulated part-based interactive environment. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 11097–11107,
work page internal anchor Pith review arXiv
-
[15]
Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V
Jianwei Yang, Hao Zhang, Feng Li, Xueyan Zou, Chunyuan Li, and Jianfeng Gao. Set-of-mark prompting unleashes extraordinary visual grounding in gpt-4v.arXiv preprint arXiv:2310.11441,
work page internal anchor Pith review arXiv
-
[16]
12 Rui Yang, Hanyang Chen, Junyu Zhang, Mark Zhao, Cheng Qian, Kangrui Wang, Qineng Wang, Teja Venkat Koripella, Marziyeh Movahedi, Manling Li, Heng Ji, Huan Zhang, and Tong Zhang. EmbodiedBench: Comprehensive benchmarking multi-modal large language models for vision- driven embodied agents. (arXiv:2502.09560). doi: 10.48550/arXiv.2502.09560. URL http: //...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.