Recognition: 2 theorem links
· Lean TheoremPrune, Interpret, Evaluate: A Cross-Layer Transcoder-Native Framework for Efficient Circuit Discovery via Feature Attribution
Pith reviewed 2026-05-11 01:49 UTC · model grok-4.3
The pith
Pruning CLT features first via attribution and synergy reranking matches full circuit fidelity at two-thirds the feature budget.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PIE is the first CLT-native end-to-end pruning framework that prunes before interpreting. FAP scores features by aggregating gradient-weighted write contributions from patching interventions. FAP-Synergy applies a systematic reranking that favors synergistic combinations. Across models and tasks, FAP-Synergy at K=50 achieves the same KL-divergence behavior retention as standard circuits at K=75 on IOI for both Llama-3.2-1B and Gemma-2-2B, which cuts downstream interpretation costs by 33 percent because those costs scale linearly with feature count.
What carries the argument
The PIE pipeline, which sequences feature pruning via FAP attribution scores followed by FAP-Synergy reranking before any interpretation step occurs.
If this is right
- Pruning-first pipelines perform best in the strictest budget regimes rather than relaxed ones.
- Behavioral fidelity is retained while interpretation costs fall in direct proportion to the number of features kept.
- Distinct operational regimes appear across K values from 50 to 800, with synergy methods pulling ahead only at low K.
- The same K=50 versus K=75 advantage holds on both Llama-3.2-1B and Gemma-2-2B for the IOI task.
Where Pith is reading between the lines
- The same pruning logic could be tested on circuit discovery methods that do not rely on cross-layer transcoders.
- Lowering the required feature count may make mechanistic analysis feasible for models much larger than those studied here.
- Integrating FAP-Synergy with other attribution or activation patching techniques could produce further budget reductions.
Load-bearing premise
Feature attribution scores and synergy reranking together identify and preserve the minimal set of features that still produce the original behavioral output.
What would settle it
An experiment that measures KL-divergence on the IOI task and finds FAP-Synergy at K=50 yields reliably higher divergence than the K=75 baseline would falsify the claimed efficiency gain.
Figures



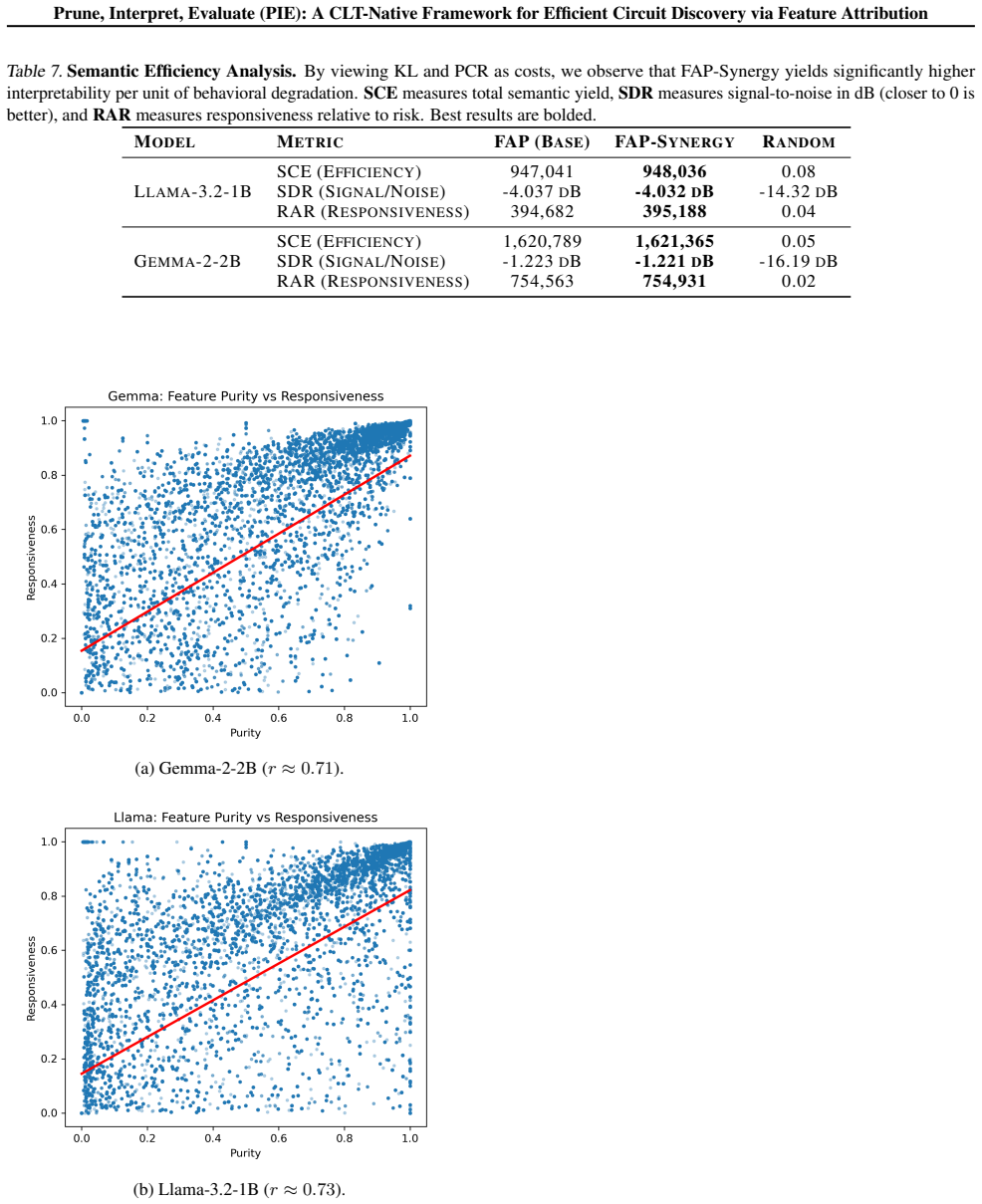

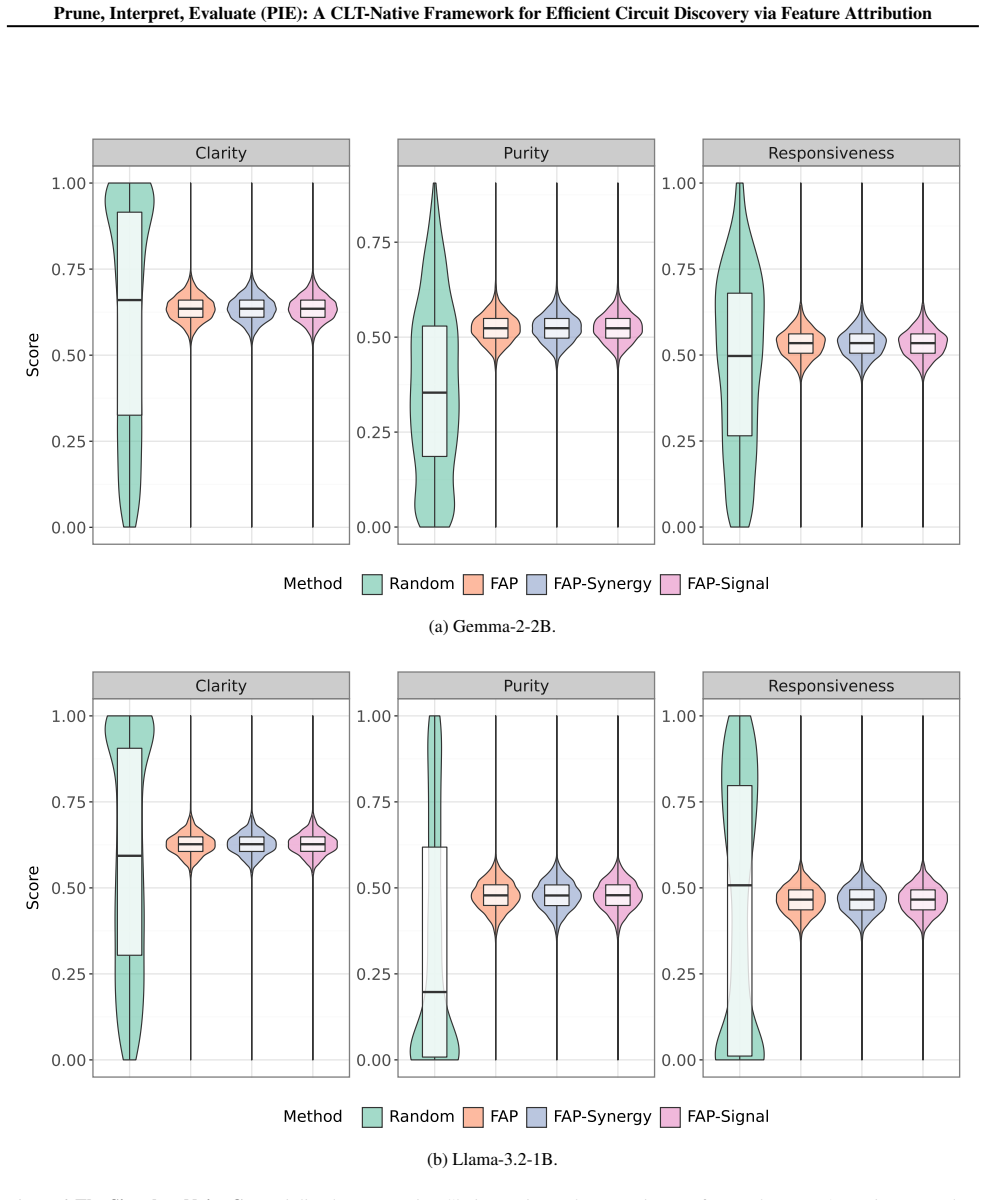
read the original abstract
Existing feature-interpretation pipelines typically operate on uniformly sampled units or exhaustive feature sets, incurring massive costs on units irrelevant to target behaviors. To address this, we introduce the first CLT-native end-to-end pruning framework, PIE, which pioneers the paradigm of pruning first and interpreting later. PIE connects Pruning, automatic Interpretation, and interpretation Evaluation, establishing a comprehensive benchmarking environment to systematically measure behavioral fidelity and downstream interpretability under pruning. Within this framework, we adapt strong relevance baselines and propose Feature Attribution Patching (FAP), a patch-grounded attribution method that scores CLT features by aggregating gradient-weighted write contributions. Furthermore, we introduce FAP-Synergy, a systematic synergy-aware reranking procedure. We evaluate pruning using KL-divergence behavior retention and assess interpretation quality with FADE-style metrics across IOI and Doc-String datasets. Across budget constraints of K in {50, 100, 200, 400, 800}, our rigorous benchmarking reveals distinct operational regimes: while base FAP and adapted baselines perform robustly at relaxed budgets, FAP-Synergy excels in highly constrained, strict-budget regimes. Crucially, we demonstrate a practical "Effective Budget" advantage: on the IOI task for both Llama-3.2-1B and Gemma-2-2B, FAP-Synergy at K=50 functionally matches the behavioral fidelity of baseline circuits at K=75. Because downstream evaluation costs scale linearly per feature, Synergy effectively grants the pipeline 25 "free" features, achieving K=75 fidelity while reducing interpretation costs by 33%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the PIE framework for efficient circuit discovery in cross-layer transcoders (CLTs). It prunes features first via Feature Attribution Patching (FAP), a gradient-weighted write-contribution method, and FAP-Synergy, a synergy-aware reranking procedure, before performing interpretation. The framework is evaluated on IOI and Doc-String tasks using Llama-3.2-1B and Gemma-2-2B, with behavioral fidelity measured by KL-divergence retention and interpretability assessed via FADE-style metrics across K budgets of 50, 100, 200, 400, and 800. The central empirical claim is that FAP-Synergy at K=50 achieves behavioral fidelity on IOI equivalent to baseline circuits at K=75 for both models, yielding an 'Effective Budget' advantage and 33% reduction in downstream interpretation costs.
Significance. If the efficiency claim is statistically substantiated, the work would provide a practical, CLT-native method for reducing the high cost of feature interpretation in mechanistic interpretability pipelines by focusing effort on behaviorally relevant units. The systematic benchmarking environment connecting pruning, automatic interpretation, and evaluation across multiple budgets and models offers a reusable template for future studies. Adaptation of strong relevance baselines and the patch-grounded FAP scoring constitute useful methodological contributions to the circuit-discovery toolkit.
major comments (2)
- [Abstract] Abstract: The claim that 'FAP-Synergy at K=50 functionally matches the behavioral fidelity of baseline circuits at K=75' on the IOI task for both models is presented without reported standard deviations, confidence intervals, or equivalence tests (e.g., TOST) on the KL-divergence values. Because downstream costs scale linearly with K, the 33% cost-reduction and '25 free features' interpretation cannot be assessed for robustness against single-run noise or post-hoc threshold choices.
- [Evaluation section] Evaluation (framework description and results): No ablation isolates the incremental benefit of the FAP-Synergy reranking procedure over base FAP or the adapted baselines under matched random seeds and circuit-construction protocols. Without such controls, it is impossible to confirm that the observed K=50 vs. K=75 equivalence is attributable to the proposed synergy mechanism rather than variability in feature selection.
minor comments (2)
- The abstract invokes 'FADE-style metrics' for interpretation quality without an explicit definition or citation in the summary; the main text should supply the precise formulation and reference.
- Notation for CLT features, the exact aggregation in the FAP scoring function, and the synergy reranking algorithm would benefit from a dedicated equation or pseudocode block for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the practical value of the PIE framework for reducing interpretation costs in CLT-based circuit discovery. We address each major comment below with clarifications and commit to targeted revisions that enhance statistical reporting and experimental controls without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'FAP-Synergy at K=50 functionally matches the behavioral fidelity of baseline circuits at K=75' on the IOI task for both models is presented without reported standard deviations, confidence intervals, or equivalence tests (e.g., TOST) on the KL-divergence values. Because downstream costs scale linearly with K, the 33% cost-reduction and '25 free features' interpretation cannot be assessed for robustness against single-run noise or post-hoc threshold choices.
Authors: We agree that explicit variability measures would improve confidence in the 'Effective Budget' claim. The reported KL values derive from single runs per (model, K) configuration, reflecting standard practice in compute-intensive mechanistic interpretability work. In revision we will (i) rerun the IOI experiments for both models with 3 independent seeds, reporting mean KL-divergence and standard deviation at K=50 and K=75, and (ii) add a short sensitivity paragraph confirming that the K=50 vs. K=75 equivalence holds under small perturbations of the selection threshold. These additions will allow readers to evaluate the robustness of the 33% cost-reduction statement. revision: yes
-
Referee: [Evaluation section] Evaluation (framework description and results): No ablation isolates the incremental benefit of the FAP-Synergy reranking procedure over base FAP or the adapted baselines under matched random seeds and circuit-construction protocols. Without such controls, it is impossible to confirm that the observed K=50 vs. K=75 equivalence is attributable to the proposed synergy mechanism rather than variability in feature selection.
Authors: We acknowledge the need for a controlled isolation of the reranking step. The current manuscript already shows that FAP-Synergy outperforms both base FAP and the adapted baselines specifically at the strictest budget (K=50) while converging at higher budgets; however, these comparisons were not performed under explicitly matched seeds. In the revised evaluation section we will insert a dedicated ablation subsection that re-runs feature selection for base FAP, FAP-Synergy, and the strongest baseline using identical random seeds and identical downstream circuit-construction code. This will quantify the incremental fidelity gain attributable to the synergy-aware reranking and directly address the concern about feature-selection variability. revision: yes
Circularity Check
No significant circularity detected in derivation or claims.
full rationale
The paper introduces an empirical pruning-and-interpretation framework (PIE) with methods FAP and FAP-Synergy, evaluated via standard external metrics (KL-divergence for fidelity, FADE-style for interpretability) on public datasets (IOI, Doc-String). The central claim of an 'Effective Budget' advantage (FAP-Synergy at K=50 matching baseline fidelity at K=75) is a direct empirical benchmarking result across fixed K budgets, not a derived prediction or first-principles result that reduces to fitted inputs or self-citations by construction. No equations, ansatzes, or uniqueness theorems are presented that would make the reported gains tautological with the method's own parameters. The framework is self-contained against external benchmarks with no load-bearing self-citation chains or renaming of known results.
Axiom & Free-Parameter Ledger
free parameters (1)
- K (feature budget)
axioms (1)
- domain assumption Gradient-weighted write contributions accurately reflect causal importance of CLT features for target behaviors
invented entities (1)
-
FAP-Synergy reranking procedure
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SFAP(f) = sum_t,s (Δaf(t)·W(s)f )^T ∇hs(t)L ; FAP-Synergy reranks via Syn(fb,fc)=M({fb,fc})−M({fb})−M({fc})
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
KL divergence retention and FADE metrics (clarity, purity, responsiveness) across budgets K=50..800
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
https://transformer-circuits.pub/ 2022/toy_model/index.html. Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., Yang, A., Fan, A., Goyal, A., Hartshorn, A., Yang, A., Mitra, A., Sravankumar, A., Korenev, A., Hinsvark, A., Rao, A., Zhang, A., Rodriguez, A., Gregerson, A., Spataru...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/ 2022
-
[2]
Gemma 2: Improving Open Language Models at a Practical Size
URL https://aclanthology.org/2024. blackboxnlp-1.25/. Team, G., Riviere, M., Pathak, S., Sessa, P. G., Hardin, C., Bhupatiraju, S., Hussenot, L., Mesnard, T., Shahriari, B., Ram´e, A., Ferret, J., Liu, P., Tafti, P., Friesen, A., Casbon, M., Ramos, S., Kumar, R., Lan, C. L., Jerome, S., Tsit- sulin, A., Vieillard, N., Stanczyk, P., Girgin, S., Momchev, N....
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
URL https://openreview.net/forum? id=NpsVSN6o4ul. Yang, G., Ye, Q., and Xia, J. Unbox the black-box for the medical explainable ai via multi-modal and multi- centre data fusion: A mini-review, two showcases and beyond.Information Fusion, 77:29–52, 2022. ISSN 1566-2535. doi: https://doi.org/10.1016/j.inffus.2021.07
-
[4]
URL https://www.sciencedirect.com/ science/article/pii/S1566253521001597. A. Hyperparameter Selection for FAP-Synergy Baseline.We use the ordinary FAP setting (synergy weight λ= 0 ) as the baseline on IOI with N=500, K=100. The baseline metrics are: mean last-token KL = 1.1399 , std = 0.5393, prediction-change rate = 0.446. All results below are reported ...
-
[5]
Then, Arthur and Ruby had a long argument, and afterwards Ruby said to Arthur,
The data reveals a consistent trend across all tested λ values: increasing the boundary percent beyond bp= 25 degrades performance (e.g., at bp= 40 , the improvement drops significantly to ≈ −0.758 milli-KL compared to > −1.0 at bp= 25 ). This suggests that widening the reranking window too far introduces noise or dilutes the high-synergy pairs with less ...
work page 2023
-
[6]
Select the top γK features from {f:S FAP(f)>0} by score magnitude
-
[7]
Select the top γK features from {f:S FAP(f)<0} by score magnitude
-
[8]
Fill the remaining (1−2γ)K slots by the largest |SFAP(f)|among all remaining features. This procedure preserves a signed “floor” of inhibitory fea- tures while retaining the simplicity and speed of the base top-Kselection. Experimental setting.We evaluate FAP-Signal under the same protocol as the main paper: IOI pruning with K=100, followed by automated i...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.