Recognition: unknown
Step-GRPO: Internalizing Dynamic Early Exit for Efficient Reasoning
Pith reviewed 2026-05-10 07:03 UTC · model grok-4.3
The pith
Step-GRPO trains reasoning models to exit early after semantic steps using linguistic markers, cutting tokens without accuracy loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
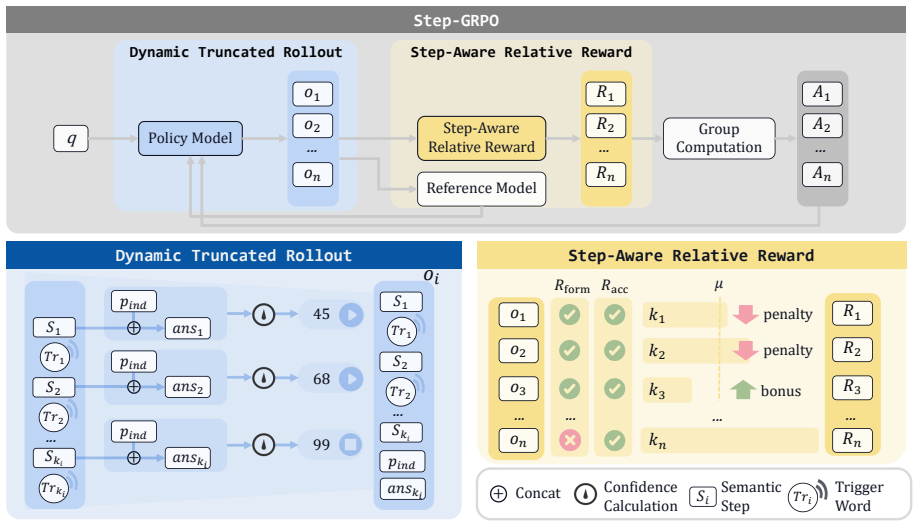
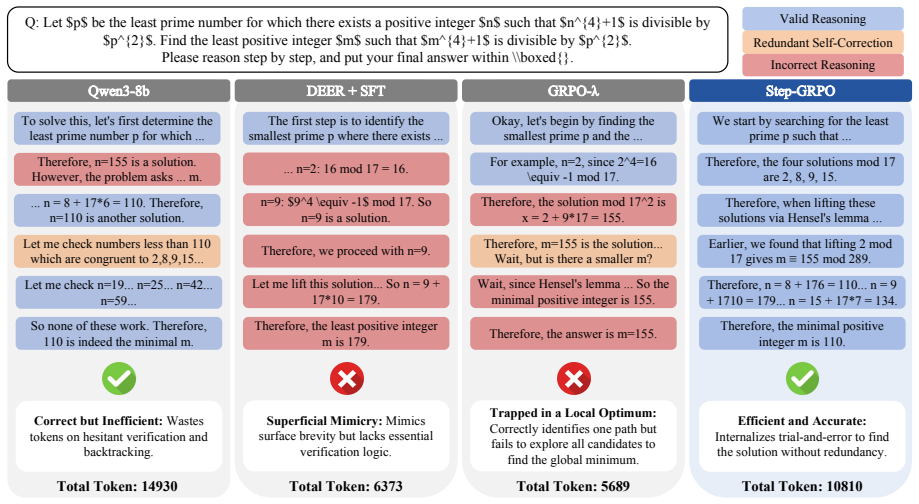
Step-GRPO shifts the optimization target from individual tokens to semantic steps by parsing reasoning traces with linguistic markers, then applies Dynamic Truncated Rollout to sample concise trajectories and Step-Aware Relative Reward to assign penalties based on group-level step counts, thereby embedding early-exit decisions directly into the model weights and delivering a 32 percent token reduction on Qwen3-8B with no accuracy drop relative to vanilla models.
What carries the argument
Dynamic Truncated Rollout paired with Step-Aware Relative Reward, which together restructure the training signal around linguistic-marker-delimited semantic steps rather than raw token length.
If this is right
- Models trained this way spend fewer tokens on repeated checks after a step is finished.
- Accuracy stays stable across benchmarks where length penalties normally cause degradation.
- No separate inference-time early-exit controller is required at deployment.
- The same step-level objective works across multiple model sizes without additional system changes.
Where Pith is reading between the lines
- The internalized exit behavior may transfer to problems whose step boundaries are less clearly marked by language.
- The method could be combined with other reinforcement objectives that also operate on grouped trajectories.
- If step segmentation proves brittle on certain domains, hybrid markers or learned boundary detectors would be a natural next adjustment.
Load-bearing premise
Linguistic markers in the model's output can be trusted to split reasoning into complete, unbiased semantic steps whose termination point can be judged reliably.
What would settle it
Run the trained model on a held-out set of problems where correct solutions require extra verification steps after the first apparent linguistic completion marker; measure whether accuracy falls below the vanilla baseline.
Figures


read the original abstract
Large reasoning models that use long chain-of-thought excel at problem-solving yet waste compute on redundant checks. Curbing this overthinking is hard: training-time length penalties can cripple ability, while inference-time early-exit adds system overhead. To bridge this gap, we propose Step-GRPO, a novel post-training framework that internalizes dynamic early-exit capabilities directly into the model. Step-GRPO shifts the optimization objective from raw tokens to semantic steps by utilizing linguistic markers to structure reasoning. We introduce a Dynamic Truncated Rollout mechanism that exposes the model to concise high-confidence trajectories during exploration, synergized with a Step-Aware Relative Reward that dynamically penalizes redundancy based on group-level baselines. Extensive experiments across three model sizes on diverse benchmarks demonstrate that Step-GRPO achieves a superior accuracy-efficiency trade-off. On Qwen3-8B, our method reduces token consumption by 32.0\% compared to the vanilla model while avoiding the accuracy degradation observed in traditional length-penalty methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Step-GRPO, a post-training framework to internalize dynamic early-exit behavior in large reasoning models. It structures chain-of-thought via linguistic markers to define semantic steps, introduces Dynamic Truncated Rollout to expose the model to concise high-confidence trajectories, and pairs this with a Step-Aware Relative Reward that penalizes redundancy using group-level baselines. Experiments across three model sizes claim superior accuracy-efficiency trade-offs, including a 32% token reduction on Qwen3-8B versus the vanilla model without the accuracy drops seen in length-penalty baselines.
Significance. If the empirical claims hold under rigorous validation, the work could meaningfully advance efficient inference for long-CoT reasoning models by shifting optimization to semantic steps rather than raw length, avoiding the accuracy penalties of prior regularization approaches. The reported gains on diverse benchmarks and multiple model scales indicate practical relevance for reducing compute waste in deployed reasoning systems.
major comments (3)
- [Method (Step-Aware Relative Reward)] The Step-Aware Relative Reward (described in the method) computes penalties relative to group-level baselines drawn from the sampled trajectories themselves. This introduces dependence on the current policy's outputs, creating a circularity risk that could bias the reward toward patterns already present in the rollouts rather than providing an independent signal of redundancy; the central claim of accuracy-preserving efficiency gains rests on this mechanism being unbiased.
- [Method (Dynamic Truncated Rollout) and Experiments] The Dynamic Truncated Rollout and overall efficiency claims depend on linguistic markers (e.g., numbered steps or conclusion phrases) reliably segmenting reasoning into complete semantic units. No ablation or error analysis is reported on marker failure modes, such as early insertion after partial reasoning or omission of verification paths, which directly undermines the assertion that the 32% token reduction on Qwen3-8B occurs without hidden accuracy costs on harder instances.
- [Experiments and Abstract] The abstract and results report clear empirical gains (e.g., 32.0% token reduction on Qwen3-8B with no accuracy degradation) but supply no implementation details, hyperparameter choices, or controls for how markers are detected and applied. This absence makes it impossible to assess reproducibility or whether the reported trade-off is robust to variations in marker heuristics.
minor comments (2)
- [Abstract] The abstract would benefit from explicitly naming the benchmarks and model variants used in the 'extensive experiments' to allow immediate assessment of scope.
- [Method] Notation for the reward components (e.g., how group baselines are normalized) could be clarified with an equation or pseudocode to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, providing clarifications on the methodological design and committing to specific revisions that strengthen the empirical validation and reproducibility of the work.
read point-by-point responses
-
Referee: [Method (Step-Aware Relative Reward)] The Step-Aware Relative Reward (described in the method) computes penalties relative to group-level baselines drawn from the sampled trajectories themselves. This introduces dependence on the current policy's outputs, creating a circularity risk that could bias the reward toward patterns already present in the rollouts rather than providing an independent signal of redundancy; the central claim of accuracy-preserving efficiency gains rests on this mechanism being unbiased.
Authors: The Step-Aware Relative Reward follows the standard group-relative advantage estimation in GRPO, where baselines are derived from the current rollout group to normalize rewards and reduce gradient variance without requiring a separate critic network. This is not intended as an independent external signal but as a within-group comparison that rewards trajectories outperforming the group average in combined accuracy and conciseness. We will revise the method section to explicitly discuss this design rationale, include a short analysis of reward distributions across groups, and demonstrate that the signal favors semantic completeness rather than merely amplifying existing rollout patterns. revision: partial
-
Referee: [Method (Dynamic Truncated Rollout) and Experiments] The Dynamic Truncated Rollout and overall efficiency claims depend on linguistic markers (e.g., numbered steps or conclusion phrases) reliably segmenting reasoning into complete semantic units. No ablation or error analysis is reported on marker failure modes, such as early insertion after partial reasoning or omission of verification paths, which directly undermines the assertion that the 32% token reduction on Qwen3-8B occurs without hidden accuracy costs on harder instances.
Authors: We agree that the reliability of linguistic markers is central to the method and that failure-mode analysis was missing. Although the main results show consistent gains across benchmarks, we will add a dedicated error analysis subsection and an ablation study in the experiments section. This will quantify marker failure rates (early insertion, omitted verification), measure their effect on accuracy for harder instances, and report sensitivity of the 32% token reduction to these cases. revision: yes
-
Referee: [Experiments and Abstract] The abstract and results report clear empirical gains (e.g., 32.0% token reduction on Qwen3-8B with no accuracy degradation) but supply no implementation details, hyperparameter choices, or controls for how markers are detected and applied. This absence makes it impossible to assess reproducibility or whether the reported trade-off is robust to variations in marker heuristics.
Authors: We acknowledge that the initial submission omitted sufficient implementation details. The revised manuscript will include a new appendix with complete hyperparameter tables, the precise marker detection rules and heuristics, the full Dynamic Truncated Rollout procedure, and any controls used during evaluation. This will enable exact reproduction and allow readers to test robustness to marker variations. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper defines Step-GRPO via new components (Dynamic Truncated Rollout using linguistic markers for step boundaries, and Step-Aware Relative Reward using group-level baselines from sampled trajectories) that are presented as independent innovations shifting optimization from tokens to semantic steps. These are then evaluated empirically on benchmarks across model sizes, with the 32% token reduction on Qwen3-8B reported as an experimental outcome rather than a quantity derived by construction from the inputs. No equations or claims reduce the central result to a self-referential fit, renamed ansatz, or load-bearing self-citation; the group baselines follow standard on-policy RL normalization and do not force the efficiency-accuracy tradeoff by definition. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Reason- ing models can be effective without thinking.arXiv preprint arXiv:2504.09858, 2025
Let’s verify step by step. InThe Twelfth Inter- national Conference on Learning Representations. Wenjie Ma, Jingxuan He, Charlie Snell, Tyler Griggs, Sewon Min, and Matei Zaharia. 2025a. Reasoning models can be effective without thinking.arXiv preprint arXiv:2504.09858. Xinyin Ma, Guangnian Wan, Runpeng Yu, Gongfan Fang, and Xinchao Wang. 2025b. Cot-valve...
-
[2]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
Kimi k1. 5: Scaling reinforcement learning with llms.arXiv preprint arXiv:2501.12599. Arne Vanhoyweghen, Brecht Verbeken, Andres Al- gaba, and Vincent Ginis. 2025. Lexical hints of accuracy in llm reasoning chains.arXiv preprint arXiv:2508.15842. Shenzhi Wang, Le Yu, Chang Gao, Chujie Zheng, Shix- uan Liu, Rui Lu, Kai Dang, Xionghui Chen, Jianxin Yang, Zh...
work page internal anchor Pith review arXiv 2025
-
[3]
Llamafactory: Unified efficient fine-tuning of 100+ language models. InProceedings of the 62nd Annual Meeting of the Association for Compu- tational Linguistics (Volume 3: System Demonstra- tions), Bangkok, Thailand. Association for Computa- tional Linguistics. Hourun Zhu, Yang Gao, Wenlong Fei, Jiawei Li, and Huashan Sun. 2025. Entropy-guided reasoning c...
-
[4]
The raw reasoning text (content within <think>tags)
-
[5]
### Task
Whether the problem was solved cor- rectly. ### Task
-
[6]
A "step" is a coherent unit of thought, calculation, or reflection
Segmentation: Break the reasoning text into a list of chronological steps. A "step" is a coherent unit of thought, calculation, or reflection
-
[7]
Classification: Assign one of the fol- lowing labels to each step: • Forward: Constructive reason- ing that moves closer to the so- lution (e.g., proposing a method, performing a calculation, deriv- ing a sub-result). • Verification: Self-correction, double-checking, or validating a previous step (e.g., "Wait, let me check", "Re-calculating this", "Since ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.