Recognition: unknown
CrossFlowDG: Bridging the Modality Gap with Cross-modal Flow Matching for Domain Generalization
Pith reviewed 2026-05-10 07:42 UTC · model grok-4.3
The pith
CrossFlowDG transports domain-biased image embeddings to class-matching text embeddings via cross-modal flow matching to close the modality gap in domain generalization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
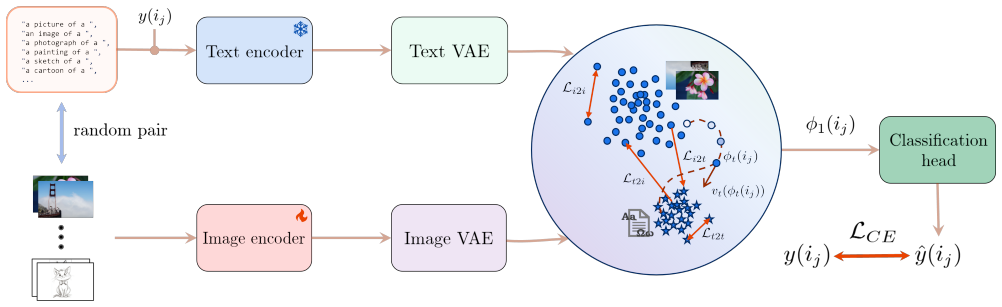
The framework learns a continuous transformation in the joint Euclidean latent space that explicitly transports domain-biased image embeddings toward domain-invariant text embeddings of the correct class, using noise-free cross-modal flow matching to close the residual modality gap left by cosine similarity-based contrastive alignment.
What carries the argument
Cross-modal flow matching that learns a continuous transport map from image embeddings to matching text embeddings in the shared latent space.
Load-bearing premise
CLIP text embeddings serve as truly domain-invariant anchors and the learned flow preserves semantic content without introducing new biases or artifacts.
What would settle it
If transported image embeddings no longer retrieve the correct class label when matched to text embeddings on a held-out domain shift, the claim that the flow maintains semantics would be falsified.
Figures

read the original abstract
Domain generalization (DG) aims to maintain performance under domain shift, which in computer vision appears primarily as stylistic variations that cause models to overfit to domain-specific appearance cues rather than class semantics. To overcome this, recent methods use textual representations as stable, domain-invariant anchors. However, multimodal approaches that rely on cosine similarity-based contrastive alignment leave a modality gap where image and text embeddings remain geometrically separated despite semantic correspondence. We propose CrossFlowDG, a novel DG framework that addresses this residual gap using noise-free, cross-modal flow matching. By learning a continuous transformation in the joint Euclidean latent space, our framework explicitly transports domain-biased image embeddings toward domain-invariant text embeddings of the correct class. Using the efficient VMamba image encoder and CLIP's text encoder, CrossFlowDG is tested against four common DG benchmarks, and achieves competitive performance on several benchmarks and state-of-the-art on TerraIncognita. Code is available at: https://github.com/ajkrit/CrossFlowDG
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CrossFlowDG, a domain generalization (DG) method that learns a noise-free cross-modal flow to transport domain-biased image embeddings (from VMamba) toward fixed, class-matched CLIP text embeddings in a shared Euclidean space. Trained end-to-end on source domains only, the framework aims to close the residual modality gap left by contrastive alignment while preserving semantics, and reports competitive results on standard DG benchmarks with state-of-the-art performance on TerraIncognita.
Significance. If the empirical claims hold, the work is significant for introducing deterministic flow matching as an explicit transport mechanism in multimodal DG, moving beyond cosine-similarity alignment. The noise-free, straight-path design and use of an efficient VMamba encoder are strengths; the released code supports reproducibility and allows independent verification of the transport's effect on domain invariance.
major comments (2)
- [§5] §5 (Experiments): The abstract asserts competitive performance across four DG benchmarks and SOTA on TerraIncognita, yet the manuscript must include full quantitative tables (with per-domain accuracies, means, and standard deviations over multiple seeds) and direct numerical comparisons to the strongest baselines; without these, the magnitude and reliability of the claimed improvement cannot be assessed.
- [§3] §3 (Method): The central claim that the learned flow preserves class semantics during transport rests on the unverified assumption that CLIP text embeddings serve as unbiased anchors; the paper should add an ablation or diagnostic (e.g., nearest-neighbor class consistency or t-SNE before/after transport) to show that the ODE integration does not introduce new inter-class confusion or domain-specific artifacts.
minor comments (2)
- [§3] Notation in the flow-matching formulation should explicitly define the velocity field and integration time interval to facilitate exact reproduction from the released code.
- [§2] The related-work section would benefit from a concise comparison table contrasting CrossFlowDG with prior multimodal DG methods that also use CLIP text anchors.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment below, indicating the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [§5] §5 (Experiments): The abstract asserts competitive performance across four DG benchmarks and SOTA on TerraIncognita, yet the manuscript must include full quantitative tables (with per-domain accuracies, means, and standard deviations over multiple seeds) and direct numerical comparisons to the strongest baselines; without these, the magnitude and reliability of the claimed improvement cannot be assessed.
Authors: We agree that comprehensive quantitative reporting is necessary to substantiate the performance claims. The manuscript currently presents mean accuracies across the four DG benchmarks with comparisons to baselines. In the revised version, we will expand the tables to report per-domain accuracies, include standard deviations computed over multiple random seeds, and provide explicit numerical comparisons to the strongest baselines for each benchmark. revision: yes
-
Referee: [§3] §3 (Method): The central claim that the learned flow preserves class semantics during transport rests on the unverified assumption that CLIP text embeddings serve as unbiased anchors; the paper should add an ablation or diagnostic (e.g., nearest-neighbor class consistency or t-SNE before/after transport) to show that the ODE integration does not introduce new inter-class confusion or domain-specific artifacts.
Authors: We acknowledge that empirical verification of semantic preservation during transport strengthens the central claim. While the framework relies on class-matched CLIP text embeddings as anchors, we will add the suggested diagnostics in the revision: nearest-neighbor class consistency metrics and t-SNE visualizations of image embeddings before and after ODE integration, to demonstrate that the process does not introduce inter-class confusion or domain-specific artifacts. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents CrossFlowDG as an independent framework that learns a deterministic cross-modal flow to transport image embeddings toward fixed CLIP text embeddings using standard flow matching in a shared Euclidean space. No equations, derivations, or self-referential constructions are described that reduce the claimed transport or performance gains to fitted parameters by construction, self-citations as load-bearing premises, or ansatzes smuggled from prior author work. The method is trained end-to-end on source domains only with VMamba and CLIP encoders, evaluated on external DG benchmarks, and supported by released code. The derivation chain remains self-contained without reducing to its inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Domain-adversarial neural networks
Hana Ajakan, Pascal Germain, Hugo Larochelle, Franc ¸ois Laviolette, and Mario Marchand. Domain-adversarial neural networks.arXiv preprint arXiv:1412.4446, 2014. 2
-
[2]
Albergo and Eric Vanden-Eijnden
Michael S. Albergo and Eric Vanden-Eijnden. Building nor- malizing flows with stochastic interpolants, 2023. 2
2023
-
[3]
Albergo, Nicholas M
Michael S. Albergo, Nicholas M. Boffi, and Eric Vanden- Eijnden. Stochastic interpolants: A unifying framework for flows and diffusions, 2023. 2
2023
-
[4]
Recognition in terra incognita
Sara Beery, Grant Van Horn, and Pietro Perona. Recognition in terra incognita. InProceedings of the European confer- ence on computer vision (ECCV), pages 456–473, 2018. 4
2018
-
[5]
Dgfamba: Learning flow factor- ized state space for visual domain generalization
Qi Bi, Jingjun Yi, Hao Zheng, Haolan Zhan, Wei Ji, Yawen Huang, and Yuexiang Li. Dgfamba: Learning flow factor- ized state space for visual domain generalization. InPro- ceedings of the AAAI Conference on Artificial Intelligence, pages 1862–1870, 2025. 2
2025
-
[6]
Domain generalization by marginal transfer learning.Journal of machine learning re- search, 22(2):1–55, 2021
Gilles Blanchard, Aniket Anand Deshmukh, Urun Dogan, Gyemin Lee, and Clayton Scott. Domain generalization by marginal transfer learning.Journal of machine learning re- search, 22(2):1–55, 2021. 2
2021
-
[7]
Boffi, Michael S
Nicholas M. Boffi, Michael S. Albergo, and Eric Vanden- Eijnden. How to build a consistency model: Learning flow maps via self-distillation, 2025. 1
2025
-
[8]
Boffi, Michael S
Nicholas M. Boffi, Michael S. Albergo, and Eric Vanden- Eijnden. Flow map matching with stochastic interpolants: A mathematical framework for consistency models, 2025. 1
2025
-
[9]
Swad: Domain generalization by seeking flat minima
Junbum Cha, Sanghyuk Chun, Kyungjae Lee, Han-Cheol Cho, Seunghyun Park, Yunsung Lee, and Sungrae Park. Swad: Domain generalization by seeking flat minima. Advances in Neural Information Processing Systems, 34: 22405–22418, 2021. 2
2021
-
[10]
Ricky T. Q. Chen, Yulia Rubanova, Jesse Bettencourt, and David Duvenaud. Neural ordinary differential equations,
-
[11]
A simple framework for contrastive learning of visual representations, 2020
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Ge- offrey Hinton. A simple framework for contrastive learning of visual representations, 2020. 5
2020
-
[12]
Jing Du, John Zelek, and Jonathan Li. Weather-aware au- topilot: Domain generalization for point cloud semantic seg- mentation in diverse weather scenarios.ISPRS Journal of Photogrammetry and Remote Sensing, 218:204–219, 2024. 1
2024
-
[13]
Mitigate the gap: Improving cross-modal alignment in CLIP
Sedigheh Eslami and Gerard de Melo. Mitigate the gap: Improving cross-modal alignment in CLIP. InThe Thir- teenth International Conference on Learning Representa- tions, 2025. 2
2025
-
[14]
Unbiased met- ric learning: On the utilization of multiple datasets and web images for softening bias
Chen Fang, Ye Xu, and Daniel N Rockmore. Unbiased met- ric learning: On the utilization of multiple datasets and web images for softening bias. InProceedings of the IEEE inter- national conference on computer vision, pages 1657–1664,
-
[15]
Domain-adversarial training of neural networks.Journal of machine learning research, 17(59):1–35, 2016
Yaroslav Ganin, Evgeniya Ustinova, Hana Ajakan, Pas- cal Germain, Hugo Larochelle, Franc ¸ois Laviolette, Mario March, and Victor Lempitsky. Domain-adversarial training of neural networks.Journal of machine learning research, 17(59):1–35, 2016. 2
2016
-
[16]
Flow- tok: Flowing seamlessly across text and image tokens, 2025
Ju He, Qihang Yu, Qihao Liu, and Liang-Chieh Chen. Flow- tok: Flowing seamlessly across text and image tokens, 2025. 2
2025
-
[17]
Momentum contrast for unsupervised visual rep- resentation learning, 2020
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual rep- resentation learning, 2020. 7
2020
-
[18]
Denoising diffu- sion probabilistic models, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffu- sion probabilistic models, 2020. 1, 2
2020
-
[19]
Self-challenging improves cross-domain generalization
Zeyi Huang, Haohan Wang, Eric P Xing, and Dong Huang. Self-challenging improves cross-domain generalization. In European conference on computer vision, pages 124–140. Springer, 2020. 2
2020
-
[20]
idag: Invariant dag searching for domain general- ization
Zenan Huang, Haobo Wang, Junbo Zhao, and Nenggan Zheng. idag: Invariant dag searching for domain general- ization. InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 19169–19179, 2023. 2
2023
-
[21]
Out-of-distribution general- ization via risk extrapolation (rex)
David Krueger, Ethan Caballero, Joern-Henrik Jacobsen, Amy Zhang, Jonathan Binas, Dinghuai Zhang, Remi Le Priol, and Aaron Courville. Out-of-distribution general- ization via risk extrapolation (rex). InInternational confer- ence on machine learning, pages 5815–5826. PMLR, 2021. 2
2021
-
[22]
Sparse mixture- of-experts are domain generalizable learners.arXiv preprint arXiv:2206.04046, 2022
Bo Li, Yifei Shen, Jingkang Yang, Yezhen Wang, Jiawei Ren, Tong Che, Jun Zhang, and Ziwei Liu. Sparse mixture- of-experts are domain generalizable learners.arXiv preprint arXiv:2206.04046, 2022. 2
-
[23]
V2x-dgw: Domain generalization for multi-agent percep- tion under adverse weather conditions
Baolu Li, Jinlong Li, Xinyu Liu, Runsheng Xu, Zhengzhong Tu, Jiacheng Guo, Qin Zou, Xiaopeng Li, and Hongkai Yu. V2x-dgw: Domain generalization for multi-agent percep- tion under adverse weather conditions. In2025 IEEE In- ternational Conference on Robotics and Automation (ICRA), pages 974–980. IEEE, 2025. 1
2025
-
[24]
Hospedales
Da Li, Yongxin Yang, Yi-Zhe Song, and Timothy M. Hospedales. Deeper, broader and artier domain generaliza- tion. InProceedings of the IEEE International Conference on Computer Vision (ICCV), 2017. 4
2017
-
[25]
Domain generalization for med- ical imaging classification with linear-dependency regular- ization.Advances in neural information processing systems, 33:3118–3129, 2020
Haoliang Li, YuFei Wang, Renjie Wan, Shiqi Wang, Tie- Qiang Li, and Alex Kot. Domain generalization for med- ical imaging classification with linear-dependency regular- ization.Advances in neural information processing systems, 33:3118–3129, 2020. 1
2020
-
[26]
Mind the gap: Understanding the modality gap in multi-modal contrastive representation learning, 2022
Weixin Liang, Yuhui Zhang, Yongchan Kwon, Serena Ye- ung, and James Zou. Mind the gap: Understanding the modality gap in multi-modal contrastive representation learning, 2022. 1, 2, 6
2022
-
[27]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maxi- milian Nickel, and Matt Le. Flow matching for generative modeling, 2023. 1, 2
2023
-
[28]
Flowing from words to pixels: A noise-free frame- work for cross-modality evolution
Qihao Liu, Xi Yin, Alan Yuille, Andrew Brown, and Mannat Singh. Flowing from words to pixels: A noise-free frame- work for cross-modality evolution. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 2755–2765, 2025. 2
2025
-
[29]
Dgmamba: Domain generalization via generalized state space model
Shaocong Long, Qianyu Zhou, Xiangtai Li, Xuequan Lu, Chenhao Ying, Yuan Luo, Lizhuang Ma, and Shuicheng Yan. Dgmamba: Domain generalization via generalized state space model. InProceedings of the 32nd ACM International Conference on Multimedia, pages 3607–3616, 2024. 2
2024
-
[30]
Unified deep supervised domain adapta- tion and generalization
Saeid Motiian, Marco Piccirilli, Donald A Adjeroh, and Gi- anfranco Doretto. Unified deep supervised domain adapta- tion and generalization. InProceedings of the IEEE inter- national conference on computer vision, pages 5715–5725,
-
[31]
Domain generalization via invariant fea- ture representation
Krikamol Muandet, David Balduzzi, and Bernhard Sch¨olkopf. Domain generalization via invariant fea- ture representation. InInternational conference on machine learning, pages 10–18. PMLR, 2013. 2
2013
-
[32]
A Survey on Domain Generalization for Medical Image Analysis,
Ziwei Niu, Shuyi Ouyang, Shiao Xie, Yen-wei Chen, and Lanfen Lin. A survey on domain generalization for medical image analysis.arXiv preprint arXiv:2402.05035, 2024. 1
-
[33]
Causality-inspired single- source domain generalization for medical image segmenta- tion.IEEE Transactions on Medical Imaging, 42(4):1095– 1106, 2022
Cheng Ouyang, Chen Chen, Surui Li, Zeju Li, Chen Qin, Wenjia Bai, and Daniel Rueckert. Causality-inspired single- source domain generalization for medical image segmenta- tion.IEEE Transactions on Medical Imaging, 42(4):1095– 1106, 2022. 1
2022
-
[34]
Learning transferable visual models from natural language supervision, 2021
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision, 2021. 2
2021
-
[35]
Hierarchical text-conditional image gener- ation with clip latents, 2022
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image gener- ation with clip latents, 2022. 2
2022
-
[36]
Shiori Sagawa, Pang Wei Koh, Tatsunori B Hashimoto, and Percy Liang. Distributionally robust neural networks for group shifts: On the importance of regularization for worst- case generalization.arXiv preprint arXiv:1911.08731, 2019. 2
work page internal anchor Pith review arXiv 1911
-
[37]
Domain generalization of 3d semantic segmenta- tion in autonomous driving
Jules Sanchez, Jean-Emmanuel Deschaud, and Franc ¸ois Goulette. Domain generalization of 3d semantic segmenta- tion in autonomous driving. InProceedings of the IEEE/CVF international conference on computer vision, pages 18077– 18087, 2023. 1
2023
-
[38]
Towards universal representa- tion learning for deep face recognition
Yichun Shi, Xiang Yu, Kihyuk Sohn, Manmohan Chan- draker, and Anil K Jain. Towards universal representa- tion learning for deep face recognition. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6817–6826, 2020. 2
2020
-
[39]
Deep unsupervised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. InInternational confer- ence on machine learning, pages 2256–2265. pmlr, 2015. 1
2015
-
[40]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Ab- hishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equa- tions.arXiv preprint arXiv:2011.13456, 2020. 2
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[41]
Kingma, Ab- hishek Kumar, Stefano Ermon, and Ben Poole
Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Ab- hishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equa- tions, 2021. 1
2021
-
[42]
Self-distilled vision transformer for domain generalization
Maryam Sultana, Muzammal Naseer, Muhammad Haris Khan, Salman Khan, and Fahad Shahbaz Khan. Self-distilled vision transformer for domain generalization. InProceed- ings of the Asian conference on computer vision, pages 3068–3085, 2022. 2
2022
-
[43]
Rethinking multi- domain generalization with a general learning objective
Zhaorui Tan, Xi Yang, and Kaizhu Huang. Rethinking multi- domain generalization with a general learning objective. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 23512–23522, 2024. 2
2024
-
[44]
Repre- sentation learning with contrastive predictive coding, 2019
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Repre- sentation learning with contrastive predictive coding, 2019. 3, 5
2019
-
[45]
Deep hashing network for unsupervised domain adaptation
Hemanth Venkateswara, Jose Eusebio, Shayok Chakraborty, and Sethuraman Panchanathan. Deep hashing network for unsupervised domain adaptation. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 5018–5027, 2017. 4
2017
-
[46]
Addressing model vul- nerability to distributional shifts over image transformation sets
Riccardo V olpi and Vittorio Murino. Addressing model vul- nerability to distributional shifts over image transformation sets. InProceedings of the IEEE/CVF International Confer- ence on Computer Vision, pages 7980–7989, 2019. 2
2019
-
[47]
Deep generative learning via schr ¨odinger bridge,
Gefei Wang, Yuling Jiao, Qian Xu, Yang Wang, and Can Yang. Deep generative learning via schr ¨odinger bridge,
-
[48]
Jindong Wang, Cuiling Lan, Chang Liu, Yidong Ouyang, Tao Qin, Wang Lu, Yiqiang Chen, Wenjun Zeng, and Philip S. Yu. Generalizing to unseen domains: A survey on domain generalization, 2022. 1
2022
-
[49]
Sharpness-aware gradient matching for domain generaliza- tion
Pengfei Wang, Zhaoxiang Zhang, Zhen Lei, and Lei Zhang. Sharpness-aware gradient matching for domain generaliza- tion. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 3769–3778,
-
[50]
Pcl: Proxy-based con- trastive learning for domain generalization
Xufeng Yao, Yang Bai, Xinyun Zhang, Yuechen Zhang, Qi Sun, Ran Chen, Ruiyu Li, and Bei Yu. Pcl: Proxy-based con- trastive learning for domain generalization. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7097–7107, 2022. 2
2022
-
[51]
Can Yaras, Siyi Chen, Peng Wang, and Qing Qu. Explaining and mitigating the modality gap in contrastive multimodal learning.arXiv preprint arXiv:2412.07909, 2024. 2
-
[52]
Domain generalization for medical image analysis: A review.Proceedings of the IEEE,
Jee Seok Yoon, Kwanseok Oh, Yooseung Shin, Maciej A Mazurowski, and Heung-Il Suk. Domain generalization for medical image analysis: A review.Proceedings of the IEEE,
-
[53]
Adaptive risk min- imization: Learning to adapt to domain shift.Advances in Neural Information Processing Systems, 34:23664–23678,
Marvin Zhang, Henrik Marklund, Nikita Dhawan, Abhishek Gupta, Sergey Levine, and Chelsea Finn. Adaptive risk min- imization: Learning to adapt to domain shift.Advances in Neural Information Processing Systems, 34:23664–23678,
-
[54]
Learning a cross-modal schr¨odinger bridge for visual domain generalization
Hao Zheng, Jingjun Yi, Qi Bi, Huimin Huang, Haolan Zhan, Yawen Huang, Yuexiang Li, Xian Wu, and Yefeng Zheng. Learning a cross-modal schr¨odinger bridge for visual domain generalization. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. 2
2025
-
[55]
Deep domain-adversarial image generation for do- main generalisation
Kaiyang Zhou, Yongxin Yang, Timothy Hospedales, and Tao Xiang. Deep domain-adversarial image generation for do- main generalisation. InProceedings of the AAAI conference on artificial intelligence, pages 13025–13032, 2020. 2
2020
-
[56]
arXiv preprint arXiv:2104.02008 , year=
Kaiyang Zhou, Yongxin Yang, Yu Qiao, and Tao Xi- ang. Domain generalization with mixstyle.arXiv preprint arXiv:2104.02008, 2021. 2
-
[57]
Domain generalization: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, page 1–20, 2022
Kaiyang Zhou, Ziwei Liu, Yu Qiao, Tao Xiang, and Chen Change Loy. Domain generalization: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, page 1–20, 2022. 1, 2
2022
-
[58]
Mixstyle neural networks for domain generalization and adaptation.International Journal of Computer Vision, 132 (3):822–836, 2024
Kaiyang Zhou, Yongxin Yang, Yu Qiao, and Tao Xiang. Mixstyle neural networks for domain generalization and adaptation.International Journal of Computer Vision, 132 (3):822–836, 2024. 2 CrossFlowDG: Bridging the Modality Gap with Cross-modal Flow Matching for Domain Generalization Supplementary Material A. Textual Domain Bank Entries Table S1 enumerates th...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.