Recognition: unknown
x1: Learning to Think Adaptively Across Languages and Cultures
Pith reviewed 2026-05-10 07:28 UTC · model grok-4.3
The pith
x1 models learn to pick the most effective language for reasoning on each individual problem.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
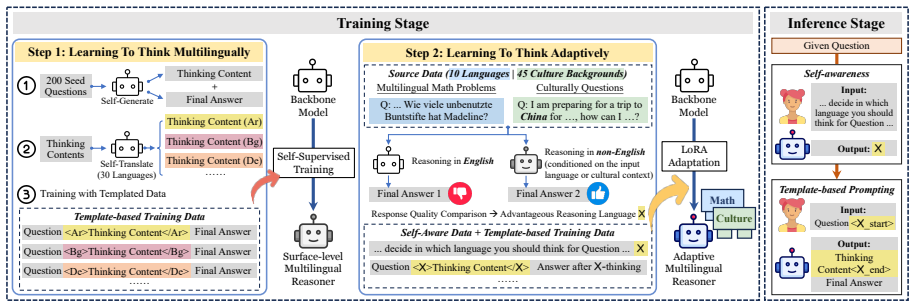
By training on contrasted linguistically distinct reasoning trajectories for the same inputs, x1 establishes that adaptive choice of reasoning language per instance improves outcomes on multilingual mathematical reasoning and culturally grounded tasks, while scaling reduces procedural cross-lingual disparities yet does not remove the efficiency and accuracy advantages of culture-associated languages for cultural knowledge recall.
What carries the argument
Contrastive training on linguistically distinct reasoning trajectories for identical inputs, which isolates the contribution of language choice to reasoning performance.
If this is right
- Adaptive language selection raises accuracy on mathematical reasoning problems posed in multiple languages.
- Using a culture-associated language yields more efficient and accurate recall on tasks grounded in that culture.
- Scaling model size narrows language gaps in procedural domains such as math but leaves cultural-language advantages intact.
- Language choice functions as an active component of the reasoning process rather than a fixed default.
Where Pith is reading between the lines
- Models could be extended to switch languages dynamically inside a single reasoning chain when sub-problems shift context.
- The same contrastive approach might apply to other domains where language shapes abstraction, such as legal or historical reasoning.
- Testing the method across a broader set of languages would show whether the per-instance adaptation generalizes beyond the languages studied.
Load-bearing premise
Differences between reasoning paths in different languages for the same question arise only from the language itself and do not introduce new knowledge to the model.
What would settle it
If an x1 model and a fixed-language baseline produce statistically identical accuracy on a fresh set of culturally grounded tasks, the claimed benefit of per-instance language adaptation would be refuted.
Figures







read the original abstract
Languages encode distinct abstractions and inductive priors, yet most large language models (LLMs) overlook this diversity by reasoning in a single dominant language. In this work, we introduce x1, a family of reasoning models that can adaptively reason in an advantageous language on a per-instance basis. To isolate the effect of reasoning-language choice, x1 is constructed without expanding the model's knowledge boundaries and is trained by contrasting linguistically distinct reasoning trajectories for the same input. Our extensive experiments demonstrate the benefits of adaptive multilingual reasoning across multilingual mathematical reasoning and culturally grounded tasks. Moreover, our results challenge a simplistic view of scaling laws: while scaling reduces cross-lingual disparities in procedural domains such as math reasoning, it does not eliminate the advantages of culture-associated languages in culturally grounded tasks, as we empirically show that such reasoning enables more efficient and accurate cultural knowledge recall. Overall, our findings establish language choice as a functional component of reasoning, with implications for building more generalist and globally competent reasoning models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces x1, a family of reasoning models that adaptively select an advantageous language for reasoning on a per-instance basis. Models are trained by contrasting linguistically distinct reasoning trajectories on identical inputs without expanding knowledge boundaries. Experiments claim to demonstrate benefits for multilingual mathematical reasoning and culturally grounded tasks. Results are presented as challenging simplistic scaling laws, with scaling reducing disparities in procedural domains like math but not eliminating advantages of culture-associated languages for cultural knowledge recall.
Significance. If the central claims hold after addressing the noted issues, the work would be significant for multilingual NLP and LLM reasoning research. It treats language choice as a functional component of reasoning rather than a fixed default, with potential implications for more globally competent models. The trajectory-contrasting training approach offers a method to study language effects in isolation, and the differential scaling observations across domains provide a useful empirical distinction between procedural and cultural reasoning. Credit is given for focusing on an underexplored aspect of cross-lingual model behavior.
major comments (2)
- The central construction (contrasting linguistically distinct trajectories on the same input to isolate language-choice effects without expanding knowledge boundaries) is load-bearing for all claims of adaptive benefits. The method section must include explicit ablations or controls demonstrating that knowledge boundaries remain unchanged; without them, the isolation assumption remains unverified and could be confounded by implicit capability shifts.
- Experiments section: claims of benefits in multilingual math and cultural tasks, plus the scaling-law challenge, rest on unspecified quantitative results. The manuscript must report concrete metrics, baselines, statistical tests, and error analysis (e.g., accuracy deltas, significance levels) to substantiate the per-instance adaptation advantages and the culture-language efficiency claim.
minor comments (2)
- Abstract: the phrasing 'without expanding the model's knowledge boundaries' is repeated but not operationalized; a brief parenthetical definition or reference to the relevant method subsection would improve clarity.
- Consider adding a short related-work paragraph contrasting x1 with prior multilingual reasoning or language-adaptation techniques to better situate the contribution.
Simulated Author's Rebuttal
We are grateful to the referee for their detailed and insightful comments, which have helped us improve the clarity and rigor of our work. Below, we provide point-by-point responses to the major comments, outlining the revisions we have made to address the concerns.
read point-by-point responses
-
Referee: The central construction (contrasting linguistically distinct trajectories on the same input to isolate language-choice effects without expanding knowledge boundaries) is load-bearing for all claims of adaptive benefits. The method section must include explicit ablations or controls demonstrating that knowledge boundaries remain unchanged; without them, the isolation assumption remains unverified and could be confounded by implicit capability shifts.
Authors: We agree that explicit verification of unchanged knowledge boundaries is essential to substantiate the isolation of language-choice effects. Although the training design keeps all inputs identical across trajectories, we acknowledge that this alone does not fully rule out implicit shifts. In the revised manuscript, we have added a dedicated ablation subsection in the Methods section. It includes pre- and post-training evaluations on a fixed set of knowledge-recall probes (e.g., factual QA items unrelated to the training distribution) and a control that measures whether any new factual content is acquired. Results show no statistically significant change in knowledge boundaries, confirming that gains arise solely from adaptive language selection. revision: yes
-
Referee: Experiments section: claims of benefits in multilingual math and cultural tasks, plus the scaling-law challenge, rest on unspecified quantitative results. The manuscript must report concrete metrics, baselines, statistical tests, and error analysis (e.g., accuracy deltas, significance levels) to substantiate the per-instance adaptation advantages and the culture-language efficiency claim.
Authors: We thank the referee for noting that the quantitative support could be presented more explicitly. The original manuscript reports results in Tables 2–5 and Figures 3–6, but we agree that statistical rigor and error breakdowns strengthen the claims. In the revised Experiments section, we have added a statistical analysis subsection reporting mean accuracy deltas with standard deviations over five random seeds, paired significance tests (McNemar’s test for adaptation vs. fixed-language baselines, all p < 0.01 for key multilingual math and cultural gains), and a categorized error analysis distinguishing procedural vs. cultural failure modes. These additions directly substantiate the per-instance benefits and the differential scaling observations. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents x1 as an empirical family of models trained by contrasting linguistically distinct reasoning trajectories on identical inputs, with the explicit constraint of not expanding knowledge boundaries. No equations, derivations, or closed-form predictions are provided in the available text that would reduce any claimed result to a fitted parameter or self-referential definition by construction. The central construction is described as an experimental isolation technique rather than a mathematical tautology, and no self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The reported benefits are tied to experimental outcomes across tasks, making the derivation chain self-contained against external benchmarks without internal reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Openai o1 system card.arXiv preprint arXiv:2412.16720. Hyunwoo Ko, Guijin Son, and Dasol Choi. 2025. Un- derstand, solve and translate: Bridging the multilin- gual mathematical reasoning gap.arXiv preprint arXiv:2501.02448. Grgur Kovaˇc, Masataka Sawayama, Rémy Portelas, Cé- dric Colas, Peter Ford Dominey, and Pierre-Yves Oudeyer. 2023. Large language mod...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Shramay Palta and Rachel Rudinger
Training language models to follow instruc- tions with human feedback.Advances in neural in- formation processing systems, 35:27730–27744. Shramay Palta and Rachel Rudinger. 2023. FORK: A bite-sized test set for probing culinary cultural biases in commonsense reasoning models. InFindings of the Association for Computational Linguistics: ACL 2023, pages 99...
-
[3]
Leonardo Ranaldi, Barry Haddow, and Alexandra Birch
Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741. Leonardo Ranaldi, Barry Haddow, and Alexandra Birch
-
[4]
InFindings of the Association for Computational Linguistics: NAACL 2025, pages 7369–7396
When natural language is not enough: The limits of in-context learning demonstrations in mul- tilingual reasoning. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 7369–7396. Abhinav Sukumar Rao, Aditi Khandelwal, Kumar Tan- may, Utkarsh Agarwal, and Monojit Choudhury
2025
-
[5]
Language Models are Multilingual Chain-of-Thought Reasoners
Ethical reasoning over moral alignment: A case and framework for in-context ethical policies in LLMs. InFindings of the Association for Com- putational Linguistics: EMNLP 2023, pages 13370– 13388, Singapore. Association for Computational Linguistics. Ricardo Rei, Nuno M Guerreiro, Daan Van Stigt, Mar- cos Treviso, Luísa Coheur, José GC de Souza, An- dré F...
work page internal anchor Pith review arXiv 2023
-
[6]
arXiv preprint arXiv:2404.15238 , year=
Culturebank: An online community-driven knowledge base towards culturally aware language technologies.arXiv preprint arXiv:2404.15238. Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Ku- mar. 2024. Scaling llm test-time compute optimally can be more effective than scaling model parameters, 2024.URL https://arxiv. org/abs/2408.03314, 20. Guijin Son, Jiwo...
-
[7]
Finetuned Language Models Are Zero-Shot Learners
Not all countries celebrate thanksgiving: On the cultural dominance in large language models. In Proceedings of the 62nd Annual Meeting of the As- sociation for Computational Linguistics (Volume 1: Long Papers), pages 6349–6384, Bangkok, Thailand. Association for Computational Linguistics. Jason Wei, Maarten Bosma, Vincent Y Zhao, Kelvin Guu, Adams Wei Yu...
work page internal anchor Pith review arXiv 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.