Recognition: unknown
TSM-Pose: Topology-Aware Learning with Semantic Mamba for Category-Level Object Pose Estimation
Pith reviewed 2026-05-10 06:46 UTC · model grok-4.3
The pith
A topology extractor combined with a semantic Mamba aggregator enables better generalization to unseen objects in category-level pose estimation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
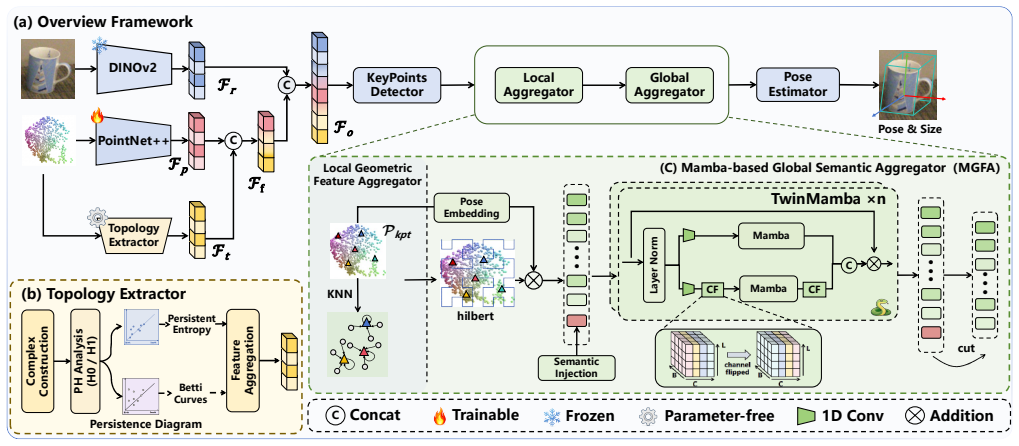
TSM-Pose introduces a Topology Extractor to capture the global topological representation of the point cloud and integrate it into local geometry features for robust category-level structural representation, together with a Mamba-based Global Semantic Aggregator that injects semantic priors into keypoints to boost their expressiveness and employs multiple TwinMamba blocks to model long-range dependencies for more effective global feature aggregation.
What carries the argument
The Topology Extractor for global topological representations from point clouds integrated with local features, and the Mamba-based Global Semantic Aggregator using TwinMamba blocks to incorporate semantic priors and long-range dependency modeling.
If this is right
- The method produces more robust category-level structural representations that support generalization to novel object instances.
- Semantic priors injected via the aggregator increase the usefulness of modeled keypoints for pose determination.
- Long-range dependency modeling through TwinMamba blocks improves the quality of aggregated global features over the point cloud.
- The overall pipeline delivers higher accuracy than prior state-of-the-art approaches on the REAL275, CAMERA25, and HouseCat6D benchmarks.
Where Pith is reading between the lines
- The same topology and semantic-aggregation ideas could be tested on related 3D tasks such as part segmentation or shape completion where category-consistent structures are useful.
- Because Mamba blocks are used for efficiency in long-range modeling, the approach may scale to larger point clouds or real-time robotic settings with lower compute cost than attention-based alternatives.
- If the gains persist outside the three benchmarks, the framework could lower the data requirements for training pose estimators in varied real-world environments.
Load-bearing premise
The reported performance gains arise specifically because the Topology Extractor and Mamba aggregator capture category-shared topological structures and semantic priors rather than from other unmentioned details of the training process or evaluation setup.
What would settle it
An ablation study on the REAL275, CAMERA25, or HouseCat6D datasets in which the Topology Extractor or the TwinMamba blocks are removed and the pose estimation accuracy shows no meaningful decrease compared to the full model.
Figures



read the original abstract
Category-level object pose estimation is fundamental for embodied intelligence, yet achieving robust generalization to unseen instances remains challenging. However, existing methods mainly rely on simple feature extraction and aggregation, which struggle to capture category-shared topological structures and conduct semantic keypoint modeling, limiting their generalization. To address these, we propose a \textbf{T}opology-Aware Learning with \textbf{S}emantic \textbf{M}amba for Category-Level \textbf{P}ose Estimation framework (TSM-Pose). Specifically, we introduce a Topology Extractor to capture the global topological representation of the point cloud, which is integrated into local geometry features and enables robust category-level structural representation. Simultaneously, we propose a Mamba-based Global Semantic Aggregator that injects semantics priors into keypoints to enhance their expressiveness and leverages multiple TwinMamba blocks to model long-range dependencies for more effective global feature aggregation. Extensive experiments on three benchmark datasets (REAL275, CAMERA25, and HouseCat6D) demonstrate that TSM-Pose outperforms existing state-of-the-art methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TSM-Pose, a framework for category-level object pose estimation from point clouds. It introduces a Topology Extractor to capture global topological representations and integrate them with local geometry features for robust category-level structural modeling. It also presents a Mamba-based Global Semantic Aggregator that injects semantic priors into keypoints and employs multiple TwinMamba blocks to model long-range dependencies for global feature aggregation. Extensive experiments on the REAL275, CAMERA25, and HouseCat6D benchmarks are reported to show outperformance over existing state-of-the-art methods.
Significance. If the reported gains are attributable to the Topology Extractor and TwinMamba components rather than uncontrolled factors, the work could advance category-level pose estimation by demonstrating how explicit topological and semantic modeling with efficient Mamba blocks improves generalization to unseen instances, with relevance to embodied AI and robotics applications.
major comments (2)
- [Experiments] The central claim of outperformance on REAL275, CAMERA25, and HouseCat6D lacks ablation studies that disable or replace the Topology Extractor and TwinMamba blocks (while freezing all other hyperparameters, data splits, and optimization settings). Without these controlled comparisons, it is impossible to attribute the gains specifically to the claimed topological and semantic mechanisms rather than implementation details or baseline re-implementations.
- [Method] The description of the Topology Extractor (global topology integrated into local geometry) and the Mamba-based aggregator remains high-level in the method; no explicit equations or pseudocode detail the fusion operation or how TwinMamba blocks inject semantic priors, making it difficult to verify that these components capture category-shared structures beyond standard point-cloud processing.
minor comments (1)
- [Abstract] The abstract introduces 'TwinMamba blocks' without a brief definition or forward reference, which may reduce immediate clarity for readers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will revise the paper to strengthen the experimental validation and methodological clarity.
read point-by-point responses
-
Referee: [Experiments] The central claim of outperformance on REAL275, CAMERA25, and HouseCat6D lacks ablation studies that disable or replace the Topology Extractor and TwinMamba blocks (while freezing all other hyperparameters, data splits, and optimization settings). Without these controlled comparisons, it is impossible to attribute the gains specifically to the claimed topological and semantic mechanisms rather than implementation details or baseline re-implementations.
Authors: We agree that the current experiments do not include the specific controlled ablations requested, which limits direct attribution of gains to the Topology Extractor and TwinMamba components. In the revised manuscript, we will add these studies: one variant with the Topology Extractor disabled (relying only on local geometry features) and another replacing TwinMamba blocks with standard transformer-based aggregation, while strictly freezing all hyperparameters, data splits, and optimization settings. Results will be reported on all three benchmarks to quantify the contribution of each module. revision: yes
-
Referee: [Method] The description of the Topology Extractor (global topology integrated into local geometry) and the Mamba-based aggregator remains high-level in the method; no explicit equations or pseudocode detail the fusion operation or how TwinMamba blocks inject semantic priors, making it difficult to verify that these components capture category-shared structures beyond standard point-cloud processing.
Authors: We acknowledge that the method descriptions are high-level and lack the requested explicit details. In the revision, we will expand Section 3 with mathematical formulations: equations for the Topology Extractor showing how global topological representations (e.g., via graph-based or persistent homology features) are fused with local point features through concatenation or attention-based integration; and equations for semantic prior injection in the Mamba aggregator, including the state-space model updates in TwinMamba blocks. Pseudocode for the full pipeline and TwinMamba forward pass will also be added to clarify the long-range dependency modeling. revision: yes
Circularity Check
No circularity: empirical performance claims rest on external benchmarks, not self-referential definitions or derivations
full rationale
The paper is a standard empirical CV contribution proposing a new architecture (Topology Extractor + TwinMamba aggregator) and reporting accuracy on three public datasets (REAL275, CAMERA25, HouseCat6D). No equations, parameter-fitting steps, or derivation chain appear in the abstract or described claims. Performance is asserted via direct comparison to external SOTA methods rather than any quantity that reduces to the model's own fitted outputs or self-citations. The central attribution of gains to the proposed modules is an empirical question addressed by experiments, not a logical reduction to inputs by construction. This is the normal non-circular case for applied ML papers.
Axiom & Free-Parameter Ledger
free parameters (1)
- hyperparameters of TwinMamba blocks and Topology Extractor
axioms (2)
- domain assumption Point clouds of objects within a category share extractable global topological structures that improve pose estimation when integrated with local features.
- domain assumption Injecting semantic priors into keypoints via Mamba blocks enhances expressiveness and long-range dependency modeling for global aggregation.
invented entities (2)
-
Topology Extractor
no independent evidence
-
TwinMamba blocks
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Carlsson
[Carlsson, 2009] G. Carlsson. Topology and data.Bulletin of the American Mathematical Society, 46(2):255–308,
2009
-
[2]
Chen and H
[Chen and Lin, 2025] Y . Chen and H. Lin. Robust model reconstruction based on the topological understanding of point clouds using persistent homology.Computer-Aided Design, page 103934,
2025
- [3]
-
[4]
[Chenet al., 2024 ] Y . Chen, Y . Di, G. Zhai, F. Manhardt, C. Zhang, R. Zhang, F. Tombari, N. Navab, and B. Busam. Secondpose: Se (3)-consistent dual-stream feature fusion for category-level pose estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9959–9969,
2024
-
[5]
[Conget al., 2021 ] Y . Cong, R. Chen, B. Ma, H. Liu, D. Hou, and C. Yang. A comprehensive study of 3-d vision-based robot manipulation.IEEE Transactions on Cybernetics, 53(3):1682–1698,
2021
-
[6]
Corsetti, F
[Corsettiet al., 2025 ] J. Corsetti, F. Giuliari, A. Fasoli, D. Boscaini, and F. Poiesi. Functionality understanding and segmentation in 3d scenes. InProceedings of the Com- puter Vision and Pattern Recognition Conference, pages 24550–24559,
2025
-
[7]
Edelsbrunner and E
[Edelsbrunner and M¨ucke, 1994] H. Edelsbrunner and E. P. M¨ucke. Three-dimensional alpha shapes.ACM Transac- tions on Graphics (TOG), 13(1):43–72,
1994
-
[8]
Topological persistence and simplification
[Edelsbrunneret al., 2002 ] Edelsbrunner, Letscher, and Zomorodian. Topological persistence and simplification. Discrete & computational geometry, 28(4):511–533,
2002
-
[9]
[Ghosh and Dutta, 2025] A. Ghosh and A. Dutta. Taco-net: Topological signatures triumph in 3d object classification. arXiv preprint arXiv:2509.24802,
-
[10]
Hoque, S
[Hoqueet al., 2023 ] S. Hoque, S. Xu, A. Maiti, Y . Wei, and M. Y . Arafat. Deep learning for 6d pose estimation of ob- jects—a case study for autonomous driving.Expert Sys- tems with Applications, 223:119838,
2023
-
[11]
Jignasu, A
[Jignasuet al., 2024 ] A. Jignasu, A. Balu, S. Sarkar, C. Hegde, B. Ganapathysubramanian, and A. Krishna- murthy. Sdfconnect: Neural implicit surface reconstruc- tion of a sparse point cloud with topological constraints. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5271–5279,
2024
-
[12]
Jung, S.-C
[Junget al., 2024 ] H. Jung, S.-C. Wu, P. Ruhkamp, G. Zhai, H. Schieber, G. Rizzoli, P. Wang, H. Zhao, L. Garattoni, S. Meier, et al. Housecat6d-a large-scale multi-modal category level 6d object perception dataset with house- hold objects in realistic scenarios. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22...
2024
-
[13]
[Liet al., 2025 ] W. Li, H. Xu, J. Huang, H. Jung, P. K. T. Yu, N. Navab, and B. Busam. Gce-pose: Global context enhancement for category-level object pose estimation. In Proceedings of the Computer Vision and Pattern Recogni- tion Conference, pages 27154–27165,
2025
-
[14]
Liang, X
[Lianget al., 2024 ] D. Liang, X. Zhou, W. Xu, X. Zhu, Z. Zou, X. Ye, X. Tan, and X. Bai. Pointmamba: A simple state space model for point cloud analysis. InAdvances in Neural Information Processing Systems,
2024
-
[15]
[Linet al., 2023 ] J. Lin, Z. Wei, Y . Zhang, and K. Jia. Vi- net: Boosting category-level 6d object pose estimation via learning decoupled rotations on the spherical representa- tions. InProceedings of the IEEE/CVF international con- ference on computer vision, pages 14001–14011,
2023
-
[16]
[Linet al., 2025 ] X. Lin, Y . Peng, L. Wang, X. Zhong, M. Zhu, Y . Feng, J. Yang, C. Liu, and Q. Chen. Clean- pose: Category-level object pose estimation via causal learning and knowledge distillation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 5990–6000,
2025
-
[17]
[Liuet al., 2022 ] X. Liu, G. Wang, Y . Li, and X. Ji. CATRE: iterative point clouds alignment for category-level object pose refinement. InEuropean Conference on Computer Vision (ECCV), October
2022
-
[18]
[Liuet al., 2024 ] J. Liu, W. Sun, C. Liu, H. Yang, X. Zhang, and A. Mian. Mh6d: Multi-hypothesis consistency learn- ing for category-level 6-d object pose estimation.IEEE Transactions on Neural Networks and Learning Systems,
2024
-
[19]
[Maet al., 2023 ] B. Ma, Y . Cong, and J. Dong. Topology- aware graph convolution network for few-shot incremental 3-d object learning.IEEE Transactions on Systems, Man, and Cybernetics: Systems, 54(1):324–337,
2023
-
[20]
[Maet al., 2024 ] B. Ma, Y . Cong, and Y . Ren. Iosl: In- cremental open set learning.IEEE Transactions on Cir- cuits and Systems for Video Technology, 34(4):2235–2248,
2024
-
[21]
[Maoet al., 2023 ] J. Mao, S. Shi, X. Wang, and H. Li. 3d object detection for autonomous driving: A comprehen- sive survey.International Journal of Computer Vision, 131(8):1909–1963,
2023
-
[22]
DINOv2: Learning Robust Visual Features without Supervision
[Oquabet al., 2023 ] M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haz- iza, F. Massa, A. El-Nouby, et al. Dinov2: Learning ro- bust visual features without supervision.arXiv preprint arXiv:2304.07193,
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
[Qiet al., 2017 ] C. R. Qi, L. Yi, H. Su, and L. J. Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space.Advances in neural information processing systems, 30,
2017
-
[24]
[Suet al., 2025 ] Z. Su, X. Liu, L. B. Hamdan, V . Maroulas, J. Wu, G. Carlsson, and G.-W. Wei. Topological data anal- ysis and topological deep learning beyond persistent ho- mology: a review.Artificial Intelligence Review,
2025
-
[25]
Data poisoning attacks on federated machine learning.IEEE Internet of Things Journal, 9(13):11365–11375,
[Sunet al., 2021 ] Gan Sun, Yang Cong, Jiahua Dong, Qiang Wang, Lingjuan Lyu, and Ji Liu. Data poisoning attacks on federated machine learning.IEEE Internet of Things Journal, 9(13):11365–11375,
2021
-
[26]
[Sunet al., 2025 ] J. Sun, P. Mao, L. Kong, and J. Wang. A review of embodied grasping.Sensors (Basel, Switzer- land), 25(3):852,
2025
-
[27]
[Tianet al., 2020 ] M. Tian, M. H. Ang Jr, and G. H. Lee. Shape prior deformation for categorical 6d object pose and size estimation. InEuropean Conference on Computer Vi- sion, pages 530–546. Springer,
2020
-
[28]
Vaswani, N
[Vaswaniet al., 2017 ] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polo- sukhin. Attention is all you need.Advances in neural in- formation processing systems, 30,
2017
-
[29]
Velickovic, G
[Velickovicet al., 2017] P. Velickovic, G. Cucurull, A. Casanova, A. Romero, P. Lio, Y . Bengio, et al. Graph attention networks.stat, 1050(20):10–48550,
2017
-
[30]
[Wanget al., 2019 ] H. Wang, S. Sridhar, J. Huang, J. Valentin, S. Song, and L. J. Guibas. Normalized object coordinate space for category-level 6d object pose and size estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2642–2651,
2019
- [31]
-
[32]
[Wuet al., 2020 ] C. Wu, J. Chen, Q. Cao, J. Zhang, Y . Tai, L. Sun, and K. Jia. Grasp proposal networks: An end-to-end solution for visual learning of robotic grasps. Advances in Neural Information Processing Systems, 33:13174–13184,
2020
-
[33]
PoseCNN: A Convolutional Neural Network for 6D Object Pose Estimation in Cluttered Scenes
[Xianget al., 2017 ] Y . Xiang, T. Schmidt, V . Narayanan, and D. Fox. Posecnn: A convolutional neural network for 6d object pose estimation in cluttered scenes.arXiv preprint arXiv:1711.00199,
work page Pith review arXiv 2017
-
[34]
[Xuet al., 2025 ] W. Xu, L. Zhang, L. Liu, Y . Zhong, H. Jiang, X. Wang, and R. Wang. Pre-defined keypoints promote category-level articulation pose estimation via multi-modal alignment. InProceedings of the Thirty- Fourth International Joint Conference on Artificial Intel- ligence, pages 2125–2133,
2025
- [35]
-
[36]
Yu, D.-H
[Yuet al., 2024 ] S. Yu, D.-H. Zhai, and Y . Xia. Catformer: Category-level 6d object pose estimation with transformer. InProceedings of the AAAI Conference on Artificial Intel- ligence, volume 38, pages 6808–6816,
2024
-
[37]
Yu, D.-H
[Yuet al., 2025 ] S. Yu, D.-H. Zhai, and Y . Xia. Key- pose: Category-level 6d object pose estimation with self- adaptive keypoints. InProceedings of the AAAI Confer- ence on Artificial Intelligence, volume 39, pages 9653– 9661,
2025
-
[38]
Zheng, T
[Zhenget al., 2024 ] L. Zheng, T. H. E. Tse, C. Wang, Y . Sun, E. Dasgupta, H. Chen, A. Leonardis, W. Zhang, and H. J. Chang. Georef: Geometric alignment across shape varia- tion for category-level object pose refinement. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June
2024
-
[39]
[Zhuet al., ] L. Zhu, B. Liao, Q. Zhang, X. Wang, W. Liu, and X. Wang. Vision mamba: Efficient visual represen- tation learning with bidirectional state space model. In Forty-first International Conference on Machine Learning. [Zhuet al., 2025 ] Z. Zhu, X. Wang, Y . Li, Z. Zhang, X. Ma, Y . Chen, B. Jia, W. Liang, Q. Yu, Z. Deng, et al. Move to understand...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.