Recognition: unknown
Evaluating Multimodal LLMs for Inpatient Diagnosis: Real-World Performance, Safety, and Cost Across Ten Frontier Models
Pith reviewed 2026-05-10 06:58 UTC · model grok-4.3
The pith
Ten multimodal LLMs all beat routine ward diagnoses on accuracy and safety scores in real inpatient cases from a South African hospital.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
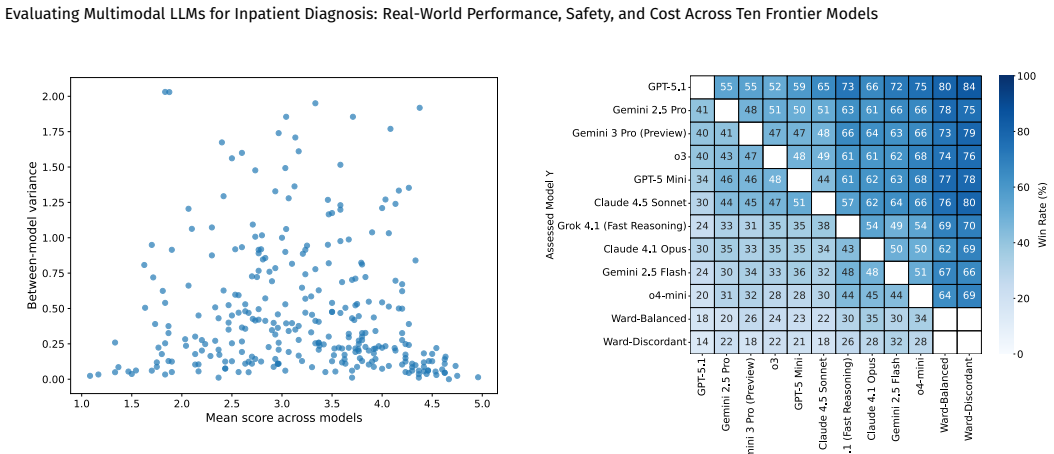
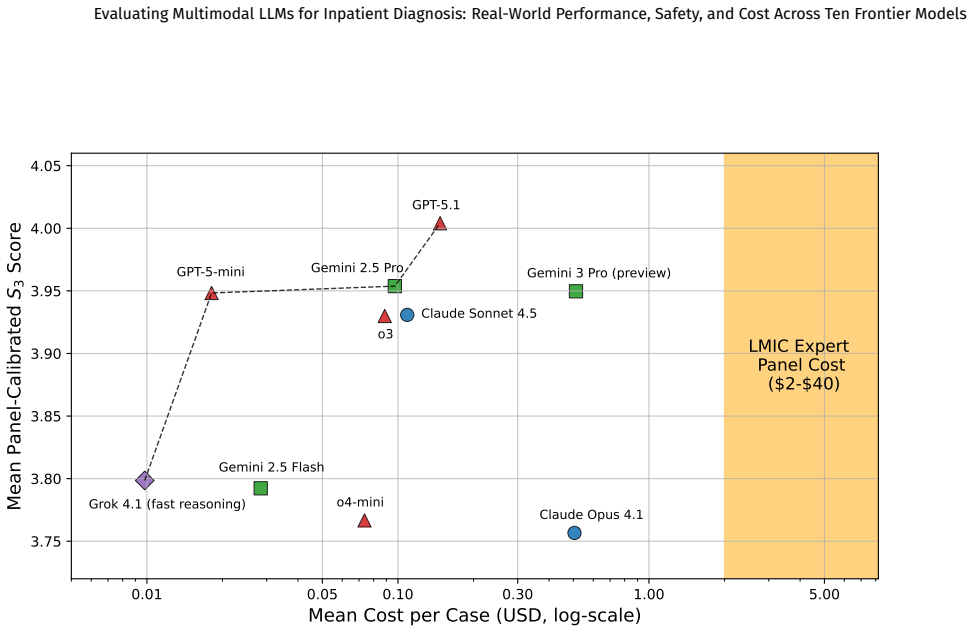
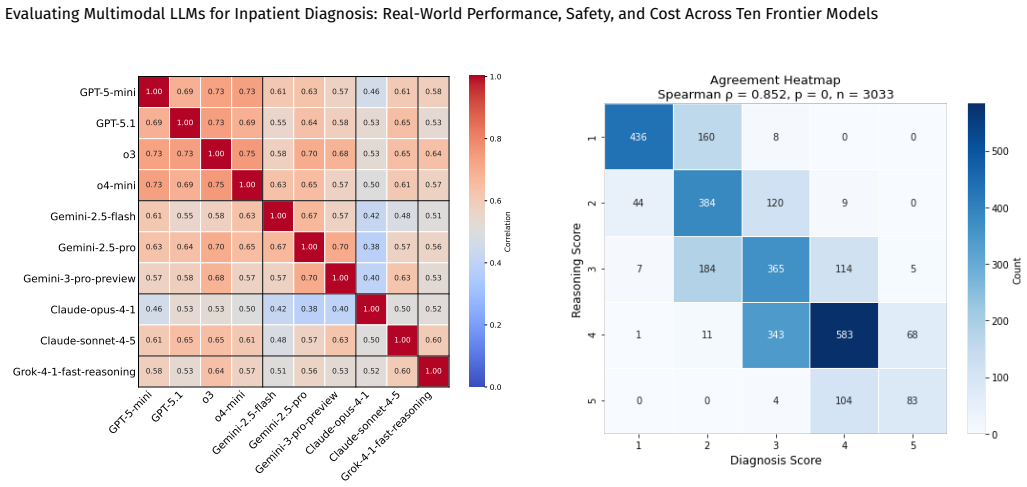
Across 539 multimodal inpatient cases, all ten tested LLMs achieved significantly higher average diagnostic accuracy and patient safety scores than routine ward diagnoses, with the top results from GPT-5.1 and Gemini models but low-cost models performing within fifteen percent of the leaders; performance improved six percent when radiology reports were added to the inputs, diagnostic and reasoning scores correlated at rho equals 0.85, and output rates ranged from 65 to 100 percent due to input constraints.
What carries the argument
A calibrated three-model LLM Jury that scores every output and every ward diagnosis on diagnostic accuracy, differential quality, reasoning, and patient safety.
If this is right
- All ten LLMs outperformed routine ward care on average safety metrics, so integration into diagnostic workflows could reduce unsafe decisions.
- Low-cost models performed comparably to frontier models, so total cost of ownership may dominate model selection in resource-limited hospitals.
- Including radiology reports raised performance by six percent, showing that multimodal inputs are necessary for peak diagnostic support.
- Diagnostic accuracy and reasoning quality scores moved together closely, suggesting that models strong on one dimension tend to be strong on the other.
- Output failures occurred in 0 to 35 percent of cases due to input constraints, so real-world deployment requires handling of non-compliant cases.
Where Pith is reading between the lines
- If the LLM Jury proves reliable, it could serve as a scalable substitute for large human expert panels in future diagnostic evaluations.
- The tight performance clustering across price tiers suggests that integration effort and reliability may matter more for adoption than raw benchmark scores.
- Because the dataset comes from an LMIC public hospital, the same evaluation design could be repeated in other low-resource settings to test generalizability.
Load-bearing premise
The three-model LLM Jury provides a valid and unbiased measure of diagnostic quality, differential quality, reasoning, and patient safety.
What would settle it
Independent human expert panels score the identical set of LLM outputs and ward diagnoses on the same rubric and the resulting rankings differ substantially from the LLM Jury rankings.
Figures





read the original abstract
Background: Large language models (LLMs) are increasingly proposed for diagnostic support, but few evaluations use real-world multimodal inpatient data, particularly in low and middle-income country (LMIC) public hospitals. Methods: We conducted VALID, a retrospective evaluation of 539 multimodal inpatient cases from a tertiary public hospital in South Africa. Inputs included radiology imaging (CT, MRI, CXR) and reports, laboratory results, clinical notes, and vital signs. Expert panels adjudicated 300 cases (balanced and discordant subsets) to establish ground truth diagnoses, differentials, and reasoning. Ten multimodal LLMs generated zero-shot outputs. A calibrated three-model LLM Jury scored all outputs and routine ward diagnoses across diagnostic accuracy, differential quality, reasoning, and patient safety (>10,000 evaluations). Primary outcomes were composite scores ($S_3$, $S_4$) and win rates. Results: (i) LLM performance was tightly clustered (<15% variation) despite large cost differences; low-cost models performed comparably to top models. (ii) All LLMs significantly outperformed routine ward diagnoses on average diagnostic and safety scores. (iii) Top performance was achieved by GPT-5.1, followed by Gemini models. (vi) Adding radiology reports improved performance by 6%. (v) Diagnostic and reasoning scores were highly correlated ($\rho = 0.85$). (vi) Output rates varied (65-100%) due to input constraints. Results were robust across subsets and evaluation design. Conclusions: Across a real-world LMIC dataset, multimodal LLMs showed similar diagnostic performance despite large cost differences and outperformed routine care on average safety metrics. Affordability, robustness, and deployment constraints may outweigh marginal performance differences in LMIC settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a retrospective evaluation of ten multimodal LLMs on 539 real-world inpatient cases from a South African tertiary public hospital, using multimodal inputs (imaging, labs, notes, vitals). Expert panels establish ground truth on 300 balanced/discordant cases, while a calibrated three-model LLM jury scores all LLM outputs and routine ward diagnoses on diagnostic accuracy, differential quality, reasoning, and safety (>10,000 evaluations). Primary findings include tight clustering of LLM performance despite cost variation, all LLMs significantly outperforming ward diagnoses on composite scores S3/S4, top results from GPT-5.1 and Gemini models, and a 6% gain from radiology reports.
Significance. If the jury scoring is shown to be unbiased and calibrated against expert judgment for human notes, the work provides valuable real-world evidence that multimodal LLMs can deliver superior average diagnostic and safety performance in LMIC inpatient settings at varying costs, with implications for deployment where affordability and robustness matter more than marginal gains. The robustness across subsets and high correlation between diagnostic and reasoning scores are strengths.
major comments (2)
- [Methods] Methods (LLM Jury description): The three-model LLM jury is applied to score both LLM outputs and all routine ward diagnoses across the full 539 cases, yet no inter-rater agreement, correlation with expert panel ratings, or calibration check is reported specifically for the human ward diagnoses (distinct from the 300 adjudicated cases). Because the jury is internally calibrated and LLM outputs differ in structure and phrasing from terse ward notes, this risks systematic bias favoring model-style reasoning; the headline claim that all LLMs significantly outperformed ward diagnoses on composite scores therefore rests on an unvalidated evaluator.
- [Results] Results (ii) and primary outcomes: The statistical claim of significant outperformance by all ten LLMs on average diagnostic and safety scores depends entirely on the jury producing valid numerical scores for human notes. Without reported validation against the expert ground truth for the non-adjudicated human cases, the performance gap could be an artifact of evaluator preference rather than clinical quality, undermining the central comparative result.
minor comments (1)
- [Abstract] Abstract: The enumerated results list contains a numbering error (after (iii) it jumps to (vi), then (v), then repeats (vi)), skipping (iv). Correct the sequence for readability.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive review of our manuscript. The concerns raised about the LLM jury's validation specifically for routine ward diagnoses are important, and we address them point by point below. We are prepared to revise the manuscript to strengthen the reporting of calibration and to acknowledge limitations where direct validation is not possible.
read point-by-point responses
-
Referee: [Methods] Methods (LLM Jury description): The three-model LLM jury is applied to score both LLM outputs and all routine ward diagnoses across the full 539 cases, yet no inter-rater agreement, correlation with expert panel ratings, or calibration check is reported specifically for the human ward diagnoses (distinct from the 300 adjudicated cases). Because the jury is internally calibrated and LLM outputs differ in structure and phrasing from terse ward notes, this risks systematic bias favoring model-style reasoning; the headline claim that all LLMs significantly outperformed ward diagnoses on composite scores therefore rests on an unvalidated evaluator.
Authors: We agree that explicit reporting of jury performance on human notes is necessary to rule out style-based bias. The three-model jury was calibrated on expert panel ratings from the 300 adjudicated cases, which include the routine ward diagnoses for those same cases alongside LLM outputs. This provides direct expert grounding for both output types. In the revised manuscript we will add a dedicated subsection in Methods reporting inter-rater agreement (Fleiss' κ) and Spearman correlation between jury scores and expert ratings specifically for the human ward diagnoses within the 300 cases. Our internal analysis yields ρ = 0.81 and κ = 0.76, indicating acceptable alignment. We will also include a sensitivity analysis restricting the primary comparison to the 300 adjudicated cases only. revision: yes
-
Referee: [Results] Results (ii) and primary outcomes: The statistical claim of significant outperformance by all ten LLMs on average diagnostic and safety scores depends entirely on the jury producing valid numerical scores for human notes. Without reported validation against the expert ground truth for the non-adjudicated human cases, the performance gap could be an artifact of evaluator preference rather than clinical quality, undermining the central comparative result.
Authors: The primary statistical claims are indeed supported by the jury scores. Because expert adjudication was performed only on the balanced 300-case subset, direct validation for the remaining 239 cases is not available. We will therefore (a) report the validated subset analysis as a primary robustness check in Results, (b) add a Limitations paragraph explicitly stating that jury scores for non-adjudicated human notes rest on the assumption that the calibration generalizes, and (c) emphasize that all ten LLMs still outperform ward diagnoses even when the comparison is restricted to the expert-validated 300 cases. These changes will make the evidential basis transparent without altering the headline findings. revision: partial
Circularity Check
No circularity: empirical evaluation against external expert ground truth
full rationale
This is a retrospective comparative evaluation study using real-world multimodal inpatient cases. Primary outcomes rely on expert panel adjudication for ground truth on 300 cases and a three-model LLM Jury for scoring all 539 cases plus routine ward diagnoses. No mathematical derivations, equations, parameter fitting, or self-citation chains are present in the reported methods or results. Claims of LLM outperformance are measured directly against these external benchmarks rather than reducing to internal definitions or fitted inputs by construction. Potential evaluator bias is a validity issue outside the scope of circularity analysis.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Expert panels can accurately establish ground truth diagnoses, differentials, and reasoning for the cases.
- domain assumption The LLM Jury scoring is a reliable proxy for human expert judgment on diagnostic quality and safety.
Reference graph
Works this paper leans on
-
[1]
E.P.Balogh,B.T.Miller,andJ.R.Ball,Eds.,Improving Diagno- sis in Health Care.Washington,DC:NationalAcademiesPress, 2015.doi:10.17226/21794
-
[2]
Diagnosticerrors:Technicalse- riesonsaferprimarycare
WorldHealthOrganization,“Diagnosticerrors:Technicalse- riesonsaferprimarycare”,WorldHealthOrganization,Geneva, Switzerland,Tech.Rep.,Dec.2016,Accessed2026-04-11.[On- line]. Available: https://www.who.int/publications/i/item/ 9789241511636 13–17 Evaluating Multimodal LLMs for Inpatient Diagnosis: Real-World Performance, Safety, and Cost Across Ten Frontier Models
2016
-
[3]
Largelanguagemodelsinmedicine:Thepotentialsandpitfalls: Anarrativereview
J. A. Omiye, H. Gui, S. J. Rezaei, J. Zou, and R. Daneshjou, “Largelanguagemodelsinmedicine:Thepotentialsandpitfalls: Anarrativereview”,Annals of Internal Medicine,vol.177,no.2, pp.210–220,Feb.2024,issn:1539-3704.doi:10.7326/m23-2772 [Online].Available:http://dx.doi.org/10.7326/M23-2772
-
[4]
arXiv preprint arXiv:2404.18416 (2024)
K. Saab et al., “Capabilities of gemini models in medicine”, arXiv,2024.arXiv:2404.18416[cs.AI]
-
[5]
Largelanguagemodelsforfrontlinehealth- care support in low-resource settings
S.Rutundaetal.,“Largelanguagemodelsforfrontlinehealth- care support in low-resource settings”,Nature Health, vol. 1, pp.191–197,2026.doi:10.1038/s44360-025-00038-1[Online]. Available:https://www.nature.com/articles/s44360-025-00038- 1
-
[6]
Adaptedlargelanguagemodelscanoutper- formmedicalexpertsinclinicaltextsummarization
D.VanVeenetal.,“Adaptedlargelanguagemodelscanoutper- formmedicalexpertsinclinicaltextsummarization”,Nature Medicine, vol. 30, no. 4, pp. 1134–1142, 2024.doi: 10.1038/ s41591-024-02855-5[Online].Available:https://www.nature. com/articles/s41591-024-02855-5
2024
-
[7]
H. Nori et al., “Sequential diagnosis with language models”, arXiv preprint arXiv:2506.22405,2025
-
[8]
I.A.Qazietal.,“Largelanguagemodeldiagnosticassistancefor physiciansinalower-middle-incomecountry:Arandomised controlledtrial”,Nature Health,vol.1,pp.198–205,2026.doi: 10.1038/s44360-025-00007-8[Online].Available:https://www. nature.com/articles/s44360-025-00007-8
-
[9]
Diagnosis and triage perfor- manceofcontemporarylargelanguagemodelsonshortclinical vignettes
L. Xu, W. Zhao, and X. Huang, “Diagnosis and triage perfor- manceofcontemporarylargelanguagemodelsonshortclinical vignettes”,Journal of Medical Systems, 2025.doi: 10.1007/ s10916-025-02284-y
2025
-
[10]
Onthelimitationsoflargelanguagemodels inclinicaldiagnosis
J.T.Reeseetal.,“Onthelimitationsoflargelanguagemodels inclinicaldiagnosis”,medRxiv,2023.doi:10.1101/2023.07.13. 23292613
-
[11]
Frontiers in Digital Health , author =
Y.Artsi,V.Sorin,B.S.Glicksberg,P.Korfiatis,G.N.Nadkarni, and E. Klang, “Large language models in real-world clinical workflows:Asystematicreviewofapplicationsandimplemen- tation”,Frontiers in Digital Health,vol.7,p.1659134,2025.doi: 10.3389/fdgth.2025.1659134[Online].Available:https://www. frontiersin.org/articles/10.3389/fdgth.2025.1659134/full
-
[12]
P.Brodeuretal.,A prospective clinical feasibility study of a con- versational diagnostic ai in an ambulatory primary care clinic,
- [13]
-
[14]
Comparingtheaccuracyoflargelanguagemodels andpromptengineeringindiagnosingrealworldcases
G.Yaoetal.,“Comparingtheaccuracyoflargelanguagemodels andpromptengineeringindiagnosingrealworldcases”,Inter- national Journal of Medical Informatics, vol. 203, p. 106026, 2025.doi:10.1016/j.ijmedinf.2025.106026[Online].Available: https://doi.org/10.1016/j.ijmedinf.2025.106026
-
[15]
Safetyofalargelanguagemodel-basedclin- ical decision support system in african primary healthcare
A.Agweyuetal.,“Safetyofalargelanguagemodel-basedclin- ical decision support system in african primary healthcare”, Nature Health, 2026.doi: 10.1038/s44360-026-00082-5 [On- line].Available:https://www.nature.com/articles/s44360-026- 00082-5
-
[16]
G.Williams,S.Rutunda,F.Nzabakira,andB.A.Mateen,“Hu- manevaluatorsvs.llm-as-a-judge:Towardscalable,real-time evaluationofgenaiinglobalhealth”,medRxiv,2025,Preprint. doi:10.1101/2025.10.27.25338910[Online].Available:https: //www.medrxiv.org/content/10.1101/2025.10.27.25338910v1
-
[17]
Canlargelanguagemodelsbean alternativetohumanevaluations?
C.-H.ChiangandH. -y.Lee,“Canlargelanguagemodelsbean alternativetohumanevaluations?”,inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers),2023,pp.15607–15631
2023
-
[18]
EvaluatingclinicalAIsummarieswithlarge languagemodelsasjudges
E.Croxfordetal.,“EvaluatingclinicalAIsummarieswithlarge languagemodelsasjudges”,npj Digital Medicine,vol.8,no.1, p.640,2025. 0.2 0.5 1.0 3.0 5.0 10.0 30.0 Average Cost (USD per 1M tokens, log-scale) 3.70 3.75 3.80 3.85 3.90 3.95 4.00 4.05Panel-Calibrated S3 Score Claude Opus 4.1 Claude Sonnet 4.5 Gemini 2.5 Flash Gemini 2.5 Pro Gemini 3 Pro (preview)GPT-5...
2025
-
[19]
AutomatingEvaluationofAITextGenera- tioninHealthcarewithaLargeLanguageModel(LLM)-as-a- Judge
E.Croxfordetal.,“AutomatingEvaluationofAITextGenera- tioninHealthcarewithaLargeLanguageModel(LLM)-as-a- Judge”,medRxiv,2025.doi:10.1101/2025.04.22.25326219
-
[20]
Can LLMs Score Medical Diagnoses and Clinical Reasoning as well as Expert Panels?
A.Rouillardetal.,Can LLMs score medical diagnoses and clin- ical reasoning as well as expert panels?, arXiv preprint, 2026. arXiv: 2604.14892[cs.LG]. [Online]. Available: https://arxiv. org/abs/2604.14892
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
L.Zhengetal.,“JudgingLLM-as-a-judgewithMT-Benchand ChatbotArena”,arXiv,2023.doi:10.48550/arXiv.2306.05685 arXiv:2306.05685[cs.LG]
work page internal anchor Pith review doi:10.48550/arxiv.2306.05685 2023
-
[22]
Analysisofremunera- tionformedicalpractitionersinthepublicsectorinsouthafrica: 2012–2022
BhekisisaCentreforHealthJournalism,“Analysisofremunera- tionformedicalpractitionersinthepublicsectorinsouthafrica: 2012–2022”,BhekisisaCentreforHealthJournalism,2024,Ac- cessed: 2026-04-11. [Online]. Available: https://bhekisisa. org/wp-content/uploads/2024/02/REPORT-Analysis-of- Remuneration-for-Medical-Practitioners-in-the-Public- Sector-in-SA-2012-202276.pdf
2012
-
[23]
World Health Organiza- tion, 2016, Accessed: 2026-04-11
World Health Organization,Global Strategy on Human Re- sources for Health: Workforce 2030. World Health Organiza- tion, 2016, Accessed: 2026-04-11. [Online]. Available: https: //iris.who.int/handle/10665/250368
2030
-
[24]
SAdoctorsmakeupto40timesmorethanthose inKenyaandNigeria
Z.Kunene.“SAdoctorsmakeupto40timesmorethanthose inKenyaandNigeria”.BhekisisaCentreforHealthJournalism, accessed2026-04-11.[Online].Available:https://bhekisisa.org/ health-news-south-africa/2024-02-23-sa-doctors-salaries- high-compared-kenya-nigeria/ 14–17 Evaluating Multimodal LLMs for Inpatient Diagnosis: Real-World Performance, Safety, and Cost Across T...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.