Recognition: unknown
DVAR: Adversarial Multi-Agent Debate for Video Authenticity Detection
Pith reviewed 2026-05-10 07:45 UTC · model grok-4.3
The pith
A training-free debate between generative and natural agents detects fake videos competitively with supervised methods and generalizes better to new generators.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
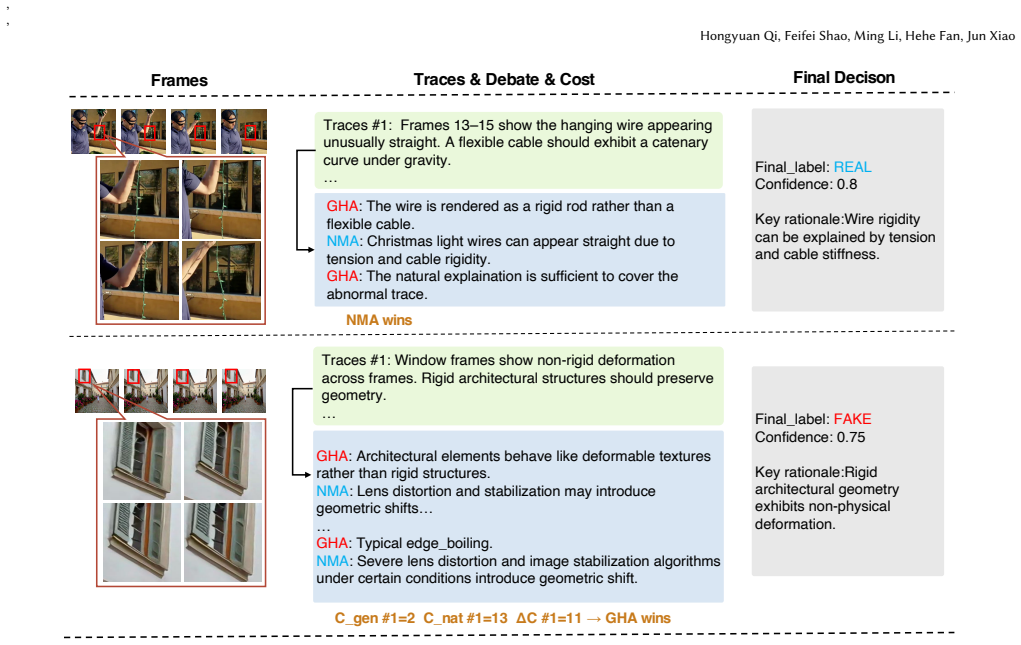
DVAR is a training-free framework that casts video authenticity assessment as a multi-agent forensic debate in which a Generative Hypothesis Agent and a Natural Mechanism Agent iteratively defend their accounts against abnormal evidence; the Minimum Description Length principle adjudicates by comparing the explanatory cost of each path, augmented by heuristics from GenVideoKB, yielding performance competitive with supervised state-of-the-art detectors and markedly stronger generalization to unseen generative architectures.
What carries the argument
The adversarial cross-examination loop between the Generative Hypothesis Agent and Natural Mechanism Agent, resolved by computing Explanatory Cost under the Minimum Description Length (MDL) framework and informed by GenVideoKB generative-boundary heuristics.
If this is right
- Detection performance remains stable when entirely new video generators appear, without retraining on fresh labeled data.
- The system produces inspectable reasoning traces that reveal which pieces of evidence drove the final decision.
- The method operates in a zero-shot regime for novel architectures while matching the accuracy of fully supervised alternatives on seen generators.
- The framework converts an opaque classification task into a transparent logical stress-test of competing explanations.
Where Pith is reading between the lines
- The same debate structure could be tested on generated images or audio to check whether cross-examination generalizes beyond video.
- Maintaining an up-to-date knowledge base of generator failure modes becomes the primary maintenance task for sustained performance.
- One could measure whether adding a third agent representing a hybrid explanation improves convergence speed or accuracy.
- The explicit cost comparison may expose systematic weaknesses in current generative models that could guide future generator design.
Load-bearing premise
Iterative cross-examination between the two agents plus MDL adjudication will reliably converge on the correct authenticity label without training data or fine-tuning, provided GenVideoKB supplies accurate and current heuristics on generative boundaries.
What would settle it
Evaluating DVAR on videos produced by a generative architecture absent from GenVideoKB and checking whether its accuracy falls below supervised baselines trained only on older generators.
Figures


read the original abstract
The rapid evolution of video generation technologies poses a significant challenge to media forensics, as conventional detection methods often fail to generalize beyond their training distributions. To address this, we propose DVAR (Debate-based Video Authenticity Reasoning), a training-free framework that reformulates video detection as a structured multi-agent forensic reasoning process. Moving beyond the paradigm of pattern matching, DVAR orchestrates a competition between a Generative Hypothesis Agent and a Natural Mechanism Agent. Through iterative rounds of cross-examination, these agents defend their respective explanations against abnormal evidence, driving a logical convergence where the truth emerges from rigorous stress-testing. To adjudicate these conflicting claims, we apply Occam's Razor through the Minimum Description Length (MDL) framework, defining an Explanatory Cost to quantify the "logical burden" of each reasoning path. Furthermore, we integrate GenVideoKB, a dynamic knowledge repository that provides high-level reasoning heuristics on generative boundaries and failure modes. Extensive experiments demonstrate that DVAR achieves competitive performance against supervised state-of-the-art methods while exhibiting superior generalization to unseen generative architectures. By transforming detection into a transparent debate, DVAR provides explicit, interpretable reasoning traces for robust video authenticity assessment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DVAR (Debate-based Video Authenticity Reasoning), a training-free framework that reformulates video authenticity detection as a multi-agent debate between a Generative Hypothesis Agent and a Natural Mechanism Agent. The agents engage in iterative cross-examination, with adjudication via an MDL-based Explanatory Cost that applies Occam's Razor, augmented by the GenVideoKB knowledge repository for generative heuristics. The central claim is that this process yields competitive performance against supervised state-of-the-art detectors while providing superior generalization to unseen generative architectures, along with interpretable reasoning traces.
Significance. If the empirical claims hold, the work would be significant for media forensics: it offers a training-free, interpretable alternative to supervised detectors that typically overfit to specific generators and fail on new architectures. The adversarial debate plus MDL adjudication mechanism could provide a principled way to leverage external knowledge without parameter fitting, addressing a key limitation in the field.
major comments (3)
- [Abstract] Abstract: The central claims of 'competitive performance against supervised state-of-the-art methods' and 'superior generalization to unseen generative architectures' are asserted without any quantitative results, tables, ablation studies, or baseline comparisons. This absence makes it impossible to evaluate whether the debate process plus MDL adjudication actually delivers the stated gains.
- [Abstract] Abstract: No equations, pseudocode, or procedural details are supplied for computing the Explanatory Cost under the MDL framework or for how the agents are prompted and how cross-examination is structured. These omissions are load-bearing because the reliability of convergence on correct labels depends directly on these mechanisms.
- [Abstract] Abstract: The description of GenVideoKB as supplying 'high-level reasoning heuristics on generative boundaries and failure modes' is given without any characterization of its coverage, update mechanism, or handling of novel generators, leaving the generalization claim without concrete support.
minor comments (1)
- [Abstract] The abstract introduces several invented entities (Generative Hypothesis Agent, Natural Mechanism Agent, GenVideoKB) without initial definitions or references to later sections where they are formalized.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We address each major comment point by point below, clarifying where the full paper provides supporting material and indicating the revisions we will make to improve the abstract's informativeness and self-containment.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of 'competitive performance against supervised state-of-the-art methods' and 'superior generalization to unseen generative architectures' are asserted without any quantitative results, tables, ablation studies, or baseline comparisons. This absence makes it impossible to evaluate whether the debate process plus MDL adjudication actually delivers the stated gains.
Authors: We acknowledge the referee's point that the abstract, as a high-level summary, does not embed specific numerical results or tables. The full manuscript contains these in Section 4 (Experiments), including Table 1 for direct comparisons against supervised SOTA detectors on standard benchmarks, Table 2 and associated analysis for generalization performance on unseen generative architectures, and Section 4.3 for ablations on the debate and MDL components. To make the abstract more self-contained and address the evaluation concern, we will revise it to include a concise statement of key quantitative outcomes. revision: partial
-
Referee: [Abstract] Abstract: No equations, pseudocode, or procedural details are supplied for computing the Explanatory Cost under the MDL framework or for how the agents are prompted and how cross-examination is structured. These omissions are load-bearing because the reliability of convergence on correct labels depends directly on these mechanisms.
Authors: The manuscript supplies the requested details outside the abstract: the MDL Explanatory Cost is formally defined with its computation in Section 3.2 (including the relevant equation), while agent prompting, cross-examination structure, and iteration protocol appear in Section 3.1 together with pseudocode as Algorithm 1. We agree that the abstract would benefit from a brief procedural pointer to these mechanisms, and we will add one sentence summarizing the MDL adjudication and debate structure in the revised version. revision: yes
-
Referee: [Abstract] Abstract: The description of GenVideoKB as supplying 'high-level reasoning heuristics on generative boundaries and failure modes' is given without any characterization of its coverage, update mechanism, or handling of novel generators, leaving the generalization claim without concrete support.
Authors: Section 3.4 of the manuscript provides the requested characterization of GenVideoKB, covering its construction and scope (heuristics drawn from analysis of multiple generative video models), the update process, and the extrapolation rules used for novel generators. We will incorporate a short supporting clause into the abstract to make this concrete and strengthen the generalization claim. revision: yes
Circularity Check
No significant circularity detected
full rationale
The DVAR framework is presented as a training-free process relying on multi-agent cross-examination, MDL-based Explanatory Cost adjudication, and external GenVideoKB heuristics. The abstract and described mechanism contain no equations, fitted parameters, self-definitional loops, or load-bearing self-citations that reduce any claimed result to its own inputs by construction. The central claims rest on logical convergence and external knowledge rather than any statistical fitting or renaming of known patterns within the target data, rendering the derivation self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Occam's Razor can be operationalized via Minimum Description Length to adjudicate between competing explanations
invented entities (3)
-
Generative Hypothesis Agent
no independent evidence
-
Natural Mechanism Agent
no independent evidence
-
GenVideoKB
no independent evidence
Reference graph
Works this paper leans on
- [1]
-
[2]
2022.Deepfakes and synthetic media in the financial system: Assessing threat scenarios
Jon Bateman. 2022.Deepfakes and synthetic media in the financial system: Assessing threat scenarios. Carnegie Endowment for International Peace
2022
-
[3]
Gedas Bertasius, Heng Wang, and Lorenzo Torresani. 2021. Is Space-Time Atten- tion All You Need for Video Understanding?. InProceedings of the International Conference on Machine Learning (ICML)
2021
-
[4]
Yinqi Cai, Jichang Li, Zhaolun Li, Weikai Chen, Rushi Lan, Xi Xie, Xiaonan Luo, and Guanbin Li. 2025. DeepShield: Fortifying Deepfake Video Detection with Local and Global Forgery Analysis. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 12524–12534
2025
-
[5]
Joao Carreira and Andrew Zisserman. 2018. Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. arXiv:1705.07750 [cs.CV] https://arxiv.org/ abs/1705.07750
work page Pith review arXiv 2018
- [6]
- [7]
- [8]
-
[9]
Prafulla Dhariwal and Alex Nichol. 2021. Diffusion Models Beat GANs on Image Synthesis. arXiv:2105.05233 [cs.LG] https://arxiv.org/abs/2105.05233
work page internal anchor Pith review arXiv 2021
- [10]
- [11]
- [12]
- [13]
- [14]
-
[15]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2015. Deep Residual Learning for Image Recognition. arXiv:1512.03385 [cs.CV] https://arxiv.org/abs/ 1512.03385
work page internal anchor Pith review arXiv 2015
-
[16]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising diffusion probabilistic models. InProceedings of the 34th International Conference on Neural Information Processing Systems. Curran Associates Inc., Red Hook, NY, USA
2020
-
[17]
Sohail Ahmed Khan and Duc-Tien Dang-Nguyen. 2024. CLIPping the Deception: Adapting Vision-Language Models for Universal Deepfake Detection. InProceed- ings of the 2024 International Conference on Multimedia Retrieval. 1006–1015
2024
-
[18]
Dong Li, Jiaying Zhu, Xueyang Fu, Xun Guo, Yidi Liu, Gang Yang, Jiawei Liu, and Zheng-Jun Zha. 2024. Noise-Assisted Prompt Learning for Image Forgery Detection and Localization. InComputer Vision – ECCV 2024: 18th European Conference, Milan, Italy, September 29–October 4, 2024, Proceedings, Part XI(Milan, Italy). Springer-Verlag, Berlin, Heidelberg, 18–36...
- [19]
- [20]
-
[21]
Yanghao Li, Chao-Yuan Wu, Haoqi Fan, Karttikeya Mangalam, Bo Xiong, Jitendra Malik, and Christoph Feichtenhofer. 2022. MViTv2: Improved multiscale vision transformers for classification and detection. InCVPR
2022
- [22]
- [23]
-
[24]
Kaiqing Lin, Yuzhen Lin, Weixiang Li, Taiping Yao, and Bin Li. 2025. Standing on the Shoulders of Giants: Reprogramming Visual-Language Model for General Deepfake Detection. arXiv:2409.02664 [cs.CV] https://arxiv.org/abs/2409.02664 , , Hongyuan Qi, Feifei Shao, Ming Li, Hehe Fan, Jun Xiao
-
[25]
Yixin Liu, Kai Zhang, Yuan Li, Zhiling Yan, Chujie Gao, Ruoxi Chen, Zhengqing Yuan, Yue Huang, Hanchi Sun, Jianfeng Gao, Lifang He, and Lichao Sun. 2024. Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models. arXiv:2402.17177 [cs.CV] https://arxiv.org/abs/2402.17177
work page internal anchor Pith review arXiv 2024
- [26]
-
[27]
Ze Liu, Jia Ning, Yue Cao, Yixuan Wei, Zheng Zhang, Stephen Lin, and Han Hu
- [28]
-
[29]
Abdullahi, and Ahmad Neyaz Khan
Asad Malik, Minoru Kuribayashi, Sani M. Abdullahi, and Ahmad Neyaz Khan
-
[30]
doi:10.1109/ACCESS.2022.3151186
DeepFake Detection for Human Face Images and Videos: A Survey.IEEE Access10 (2022), 18757–18775. doi:10.1109/ACCESS.2022.3151186
- [31]
-
[32]
Bappy, Amit K
Lakshmanan Nataraj, Tajuddin Manhar Mohammed, Shivkumar Chandrasekaran, Arjuna Flenner, Jawadul H. Bappy, Amit K. Roy-Chowdhury, and B. S. Manjunath
-
[33]
arXiv preprint arXiv:1903.06836 (2019)
Detecting GAN generated Fake Images using Co-occurrence Matrices. arXiv:1903.06836 [cs.CV] https://arxiv.org/abs/1903.06836
- [34]
-
[35]
Utkarsh Ojha, Yuheng Li, and Yong Jae Lee. 2023. Towards Universal Fake Image Detectors that Generalize Across Generative Models. InCVPR
2023
- [36]
-
[37]
Andreas Rössler, Davide Cozzolino, Luisa Verdoliva, Christian Riess, Justus Thies, and Matthias Nießner. 2019. FaceForensics++: Learning to Detect Manipulated Facial Images. InInternational Conference on Computer Vision (ICCV)
2019
- [38]
-
[39]
Khoa-Dang Tran. 2025. Explainable Manipulated Videos Detection Using Multi- modal Large Language Models. InCompanion Proceedings of the ACM on Web Conference 2025(Sydney NSW, Australia)(WWW ’25). Association for Computing Machinery, New York, NY, USA, 725–728. doi:10.1145/3701716.3715283
- [40]
-
[41]
Haiquan Wen, Tianxiao Li, Zhenglin Huang, Yiwei He, and Guangliang Cheng
-
[42]
arXiv:2507.14632 [cs.CV] https://arxiv.org/abs/ 2507.14632
BusterX++: Towards Unified Cross-Modal AI-Generated Content Detection and Explanation with MLLM. arXiv:2507.14632 [cs.CV] https://arxiv.org/abs/ 2507.14632
-
[43]
Mika Westerlund. 2019. The emergence of deepfake technology: A review.Tech- nology innovation management review9, 11 (2019)
2019
- [44]
-
[45]
Yongqi Yang, Zhihao Qian, Ye Zhu, Olga Russakovsky, and Yu Wu. 2025. D3: Scaling Up Deepfake Detection by Learning from Discrepancy. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
2025
- [46]
-
[47]
Ziyin Zhou, Yunpeng Luo, Yuanchen Wu, Ke Sun, Jiayi Ji, Ke Yan, Shouhong Ding, Xiaoshuai Sun, Yunsheng Wu, and Rongrong Ji. 2025. AIGI-Holmes: Towards Explainable and Generalizable AI-Generated Image Detection via Multimodal Large Language Models.arXiv preprint arXiv:2507.02664(2025)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.