Recognition: unknown
Anonymization, Not Elimination: Utility-Preserved Speech Anonymization
Pith reviewed 2026-05-10 06:44 UTC · model grok-4.3
The pith
A two-stage framework anonymizes speech by replacing personal information and changing voices while keeping the data useful for training recognition and synthesis models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The two-stage framework protects both linguistic content and acoustic identity by employing a generative speech editing model to replace personally identifiable information and F3-VA, a flow-matching-based anonymization framework with a three-stage design, to produce diverse and distinct anonymized speakers, resulting in stronger privacy protection and minimal utility degradation when utility is measured by training ASR, TTS, and SER models from scratch.
What carries the argument
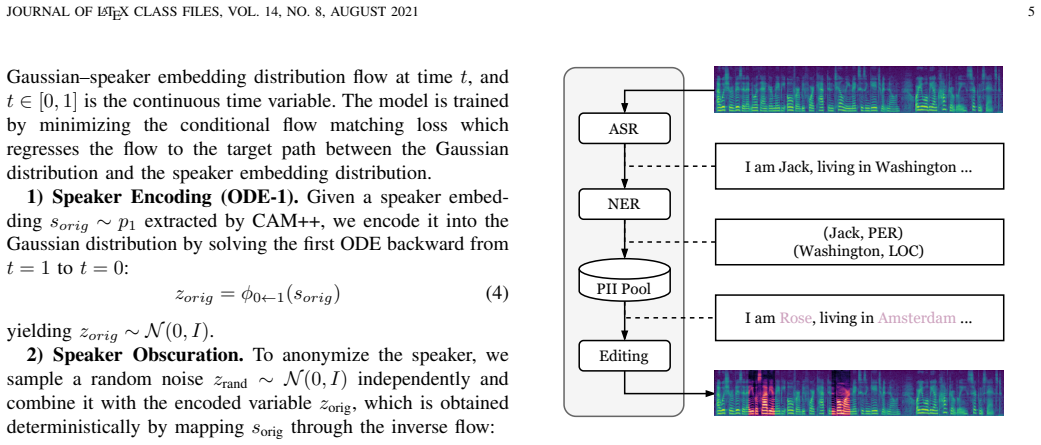
The two-stage anonymization framework that combines generative speech editing to remove personally identifiable information from linguistic content with F3-VA, a flow-matching-based voice anonymizer that generates diverse and distinct speakers.
If this is right
- Privacy evaluation becomes more complete when both acoustic and content-based speaker verification metrics are used together.
- Utility assessment is more realistic when models are trained from scratch on the anonymized data instead of tested with pretrained models.
- The approach delivers better privacy-utility trade-offs than the VoicePrivacy Challenge baseline methods.
Where Pith is reading between the lines
- Larger speech datasets could be shared more freely for research once such anonymization becomes reliable.
- Similar editing pipelines might extend to anonymizing video or multimodal recordings while retaining their training value.
- Retraining task-specific models on anonymized versions could become a standard test for whether privacy techniques actually preserve usefulness.
Load-bearing premise
The generative speech editing model can replace personally identifiable information without introducing artifacts that degrade downstream task performance in ways the chosen metrics miss, and training ASR, TTS, and SER models from scratch on the anonymized data provides a sufficient and unbiased measure of real-world utility.
What would settle it
If ASR, TTS, or SER models trained from scratch on the anonymized speech show large performance drops relative to models trained on the original speech, or if acoustic and content-based speaker verification still succeeds in identifying the original speakers.
Figures





read the original abstract
The growing reliance on large-scale speech data has made privacy protection a critical concern. However, existing anonymization approaches often degrade data utility, for example by disrupting acoustic continuity or reducing vocal diversity, which compromises the value of speech data for downstream tasks such as Automatic Speech Recognition (ASR), Text-to-Speech (TTS), and Speech Emotion Recognition (SER). Current evaluation practices are also limited, as they mainly rely on direct testing of anonymized speech with pretrained models, providing only a partial view of utility. To address these issues, we propose a novel two-stage framework that protects both linguistic content and acoustic identity while maintaining usability. For content privacy, we employ a generative speech editing model to seamlessly replace personally identifiable information (PII), and for voice privacy, we introduce F3-VA, a flow-matching-based anonymization framework with a three-stage design that produces diverse and distinct anonymized speakers. To enable a more comprehensive assessment, we evaluate privacy using both acoustic- and content-based speaker verification metrics, and assess utility by training ASR, TTS, and SER models from scratch. Experimental results show that our framework achieves stronger privacy protection with minimal utility degradation compared to baselines from the VoicePrivacy Challenge, while the proposed evaluation protocol provides a more realistic reflection of the utility of anonymized speech under privacy protection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a two-stage framework for speech anonymization: a generative speech editing model to replace personally identifiable information (PII) while preserving linguistic content, followed by F3-VA, a flow-matching-based voice anonymization method with a three-stage design to generate diverse and distinct anonymized speakers. Privacy is assessed via acoustic- and content-based speaker verification metrics, and utility via training ASR, TTS, and SER models from scratch on the anonymized corpus. The central claim is that the framework delivers stronger privacy than VoicePrivacy Challenge baselines with minimal utility degradation, and that the from-scratch training protocol offers a more realistic utility evaluation than direct testing with pretrained models.
Significance. If the results hold under scrutiny, the work would advance privacy-preserving speech processing by demonstrating a practical method to protect both content and voice identity without substantial downstream performance loss. The F3-VA component and the emphasis on training models from scratch address real gaps in current anonymization evaluations and could influence how large speech datasets are prepared for ML tasks.
major comments (2)
- [Evaluation section] Evaluation section (and abstract): The claim that training ASR/TTS/SER models from scratch provides a 'more realistic reflection of the utility' is load-bearing for the minimal-degradation conclusion, yet the protocol may understate true utility loss. In practice, utility is typically measured by fine-tuning large pretrained models, which can adapt to localized artifacts (e.g., prosody mismatches or spectral discontinuities at edit boundaries) that a from-scratch model must learn around. No ablation or comparison to fine-tuning is reported, weakening the central privacy-utility trade-off claim.
- [Methods section] Methods section describing the generative speech editing stage: The assertion of 'seamless' PII replacement is central to the utility-preservation argument, but no quantitative verification (e.g., boundary continuity metrics, perceptual artifact detection, or ablation on edit quality) is provided to confirm that downstream task degradation is not masked by the from-scratch training protocol.
minor comments (2)
- [Abstract] Abstract: 'F3-VA' is introduced without expansion on first use; define the acronym and briefly state its three-stage structure at first mention for clarity.
- [Results section] The manuscript would benefit from a table summarizing the privacy and utility metrics across all baselines and the proposed method, including confidence intervals or standard deviations, to make the 'stronger privacy with minimal degradation' comparison easier to assess.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and indicate the revisions we will incorporate in the next version of the manuscript.
read point-by-point responses
-
Referee: [Evaluation section] Evaluation section (and abstract): The claim that training ASR/TTS/SER models from scratch provides a 'more realistic reflection of the utility' is load-bearing for the minimal-degradation conclusion, yet the protocol may understate true utility loss. In practice, utility is typically measured by fine-tuning large pretrained models, which can adapt to localized artifacts (e.g., prosody mismatches or spectral discontinuities at edit boundaries) that a from-scratch model must learn around. No ablation or comparison to fine-tuning is reported, weakening the central privacy-utility trade-off claim.
Authors: We agree that fine-tuning of large pretrained models is the dominant practical workflow and that such models can adapt to localized artifacts. Our from-scratch protocol was chosen to provide a stricter, more conservative estimate of utility that does not rely on external pretraining, thereby better reflecting the value of the released anonymized corpus itself. Nevertheless, the absence of a direct comparison leaves the claim open to the interpretation raised by the referee. In the revised manuscript we will (i) expand the discussion of the evaluation protocol to explicitly acknowledge this limitation and (ii) add a limited fine-tuning ablation on at least one task (ASR) using publicly available pretrained checkpoints, thereby strengthening the privacy-utility analysis. revision: partial
-
Referee: [Methods section] Methods section describing the generative speech editing stage: The assertion of 'seamless' PII replacement is central to the utility-preservation argument, but no quantitative verification (e.g., boundary continuity metrics, perceptual artifact detection, or ablation on edit quality) is provided to confirm that downstream task degradation is not masked by the from-scratch training protocol.
Authors: The generative editing stage was designed to produce natural replacements, and the overall downstream results provide indirect support for its effectiveness. We concur, however, that explicit quantitative verification of seamlessness is missing and would directly address the concern that any utility degradation might be masked by the training protocol. In the revised manuscript we will add, in the Methods and Evaluation sections, (i) boundary continuity metrics (e.g., spectral flux and mel-cepstral distortion at edit points), (ii) a small-scale perceptual artifact detection study, and (iii) an ablation isolating the editing stage, thereby providing the requested quantitative grounding. revision: yes
Circularity Check
Empirical framework with no derivation chain or self-referential reductions
full rationale
The paper proposes a two-stage empirical framework (generative PII editing + F3-VA flow-matching anonymization) and supports its claims solely through experimental comparisons on ASR/TTS/SER tasks trained from scratch, plus privacy metrics. No equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The evaluation protocol and results are presented as direct measurements rather than reductions to inputs by construction, making the work self-contained against external benchmarks like VoicePrivacy Challenge baselines.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Generative speech editing models can seamlessly replace personally identifiable information while preserving acoustic continuity and downstream task utility.
- domain assumption Flow-matching-based anonymization with a three-stage design can produce diverse and distinct anonymized speakers without collapsing vocal variety.
invented entities (1)
-
F3-VA
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Automatic speech recognition: A survey of deep learning techniques and approaches,
H. Ahlawat, N. Aggarwal, and D. Gupta, “Automatic speech recognition: A survey of deep learning techniques and approaches,”Int. J. Cogn. Comput. Eng., 2025
2025
-
[2]
Towards controllable speech synthesis in the era of large language models: A systematic survey,
T. Xie, Y . Rong, P. Zhang, W. Wang, and L. Liu, “Towards controllable speech synthesis in the era of large language models: A systematic survey,” inProc. EMNLP, 2025, pp. 764–791
2025
-
[3]
A review on speech emotion recognition: A survey, recent advances, challenges, and the influence of noise,
S. M. George and P. M. Ilyas, “A review on speech emotion recognition: A survey, recent advances, challenges, and the influence of noise,” Neurocomputing, vol. 568, p. 127015, 2024
2024
-
[4]
Privacy in speech technology,
T. B ¨ackstr¨om, “Privacy in speech technology,”Proc. IEEE, 2025
2025
-
[5]
The GDPR & speech data: Reflections of legal and tech- nology communities, first steps towards a common understanding,
A. Nautsch, C. Jasserand, E. Kindt, M. Todisco, I. Trancoso, and N. Evans, “The GDPR & speech data: Reflections of legal and tech- nology communities, first steps towards a common understanding,” in Proc. Interspeech, 2019, pp. 3695–3699
2019
-
[6]
SynV ox2: Towards a privacy- friendly V oxCeleb2 dataset,
X. Miao, X. Wang, E. Cooperet al., “SynV ox2: Towards a privacy- friendly V oxCeleb2 dataset,” inProc. ICASSP, 2024, pp. 11 421–11 425. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 11
2024
-
[7]
Review of methods for automatic speaker verifi- cation,
D. O’Shaughnessy, “Review of methods for automatic speaker verifi- cation,”IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 32, pp. 1776–1789, 2023
2023
-
[8]
The V oicePrivacy 2020 challenge: Results and findings,
N. Tomashenko, X. Wang, E. Vincent, J. Patino, B. M. L. Srivastava, P.-G. No´e, A. Nautsch, N. Evans, J. Yamagishi, B. O’Brienet al., “The V oicePrivacy 2020 challenge: Results and findings,”Comput. Speech Lang., vol. 74, p. 101362, 2022
2020
-
[9]
N. Tomashenko, X. Miao, P. Champion, S. Meyer, X. Wang, E. Vincent, M. Panariello, N. Evans, J. Yamagishi, and M. Todisco, “The V oicePri- vacy 2024 challenge evaluation plan,”arXiv preprint arXiv:2404.02677, 2024
-
[10]
Are disentangled representa- tions all you need to build speaker anonymization systems?
P. Champion, A. Larcher, and D. Jouvet, “Are disentangled representa- tions all you need to build speaker anonymization systems?” inProc. Interspeech, 2022, pp. 2793–2797
2022
-
[11]
DiffVC+: improving diffusion-based voice conversion for speaker anonymization,
F. Huang, K. Zeng, and W. Zhu, “DiffVC+: improving diffusion-based voice conversion for speaker anonymization,” inProc. Interspeech, vol. 2024, 2024, pp. 4453–4457
2024
-
[12]
Anonymiz- ing speech with generative adversarial networks to preserve speaker privacy,
S. Meyer, P. Tilli, P. Denisov, F. Lux, J. Koch, and N. T. Vu, “Anonymiz- ing speech with generative adversarial networks to preserve speaker privacy,” inProc. SLT, 2023
2023
-
[13]
Exploratory evaluation of speech content masking,
J. Williams, K. Pizzi, P.-G. Noe, and S. Das, “Exploratory evaluation of speech content masking,” inProc. ITG Conf. Speech Commun., 2023, pp. 215–219
2023
-
[14]
En- hancing speech de-identification with LLM-based data augmentation,
P. Dhingra, S. Agrawal, C. S. Veerappan, E. S. Chng, and R. Tong, “En- hancing speech de-identification with LLM-based data augmentation,” inProc. ICAICTA, 2024, pp. 1–5
2024
-
[15]
Privacy preserving encrypted phonetic search of speech data,
C. Glackin, G. Chollet, N. Dugan, N. Cannings, J. Wall, S. Tahir, I. G. Ray, and M. Rajarajan, “Privacy preserving encrypted phonetic search of speech data,” inProc. ICASSP, 2017
2017
-
[16]
wav2vec 2.0: A framework for self-supervised learning of speech representations,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representations,” in Proc. NeurIPS, vol. 33, 2020, pp. 12 449–12 460
2020
-
[17]
HuBERT: Self-supervised speech representation learning by masked prediction of hidden units,
W.-N. Hsu, B. Bolte, Y .-H. H. Tsai, K. Lakhotia, R. Salakhutdinov, and A. Mohamed, “HuBERT: Self-supervised speech representation learning by masked prediction of hidden units,”IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 29, pp. 3451–3460, 2021
2021
-
[18]
WavLM: Large-scale self-supervised pre- training for full stack speech processing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiaoet al., “WavLM: Large-scale self-supervised pre- training for full stack speech processing,”IEEE J. Sel. Top. Signal Process., vol. 16, no. 6, pp. 1505–1518, 2022
2022
-
[19]
Crepe: A convolutional representation for pitch estimation,
J. W. Kim, J. Salamon, P. Li, and J. P. Bello, “Crepe: A convolutional representation for pitch estimation,” inProc. ICASSP, 2018, pp. 161– 165
2018
-
[20]
RMVPE: A robust model for vocal pitch estimation in polyphonic music,
H. Wei, X. Cao, T. Dan, and Y . Chen, “RMVPE: A robust model for vocal pitch estimation in polyphonic music,” inProc. Interspeech, 2023, pp. 5421–5425
2023
-
[21]
X-vectors: Robust DNN embeddings for speaker recognition,
D. Snyder, D. Garcia-Romero, G. Sell, D. Povey, and S. Khudanpur, “X-vectors: Robust DNN embeddings for speaker recognition,” inProc. ICASSP, 2018, pp. 5329–5333
2018
-
[22]
ECAPA-TDNN: Emphasized channel attention, propagation and aggregation in TDNN based speaker verification,
B. Desplanques, J. Thienpondt, and K. Demuynck, “ECAPA-TDNN: Emphasized channel attention, propagation and aggregation in TDNN based speaker verification,” inProc. Interspeech, 2020, pp. 3830–3834
2020
-
[23]
CAM++: A fast and efficient network for speaker verification using context-aware masking,
H. Wang, S. Zheng, Y . Chen, L. Cheng, and Q. Chen, “CAM++: A fast and efficient network for speaker verification using context-aware masking,” inProc. Interspeech, 2023, pp. 5301–5305
2023
-
[24]
Speaker anonymization using x-vector and neural waveform models,
F. Fang, X. Wang, J. Yamagishi, I. Echizen, M. Todisco, N. Evans, and J.-F. Bonastre, “Speaker anonymization using x-vector and neural waveform models,” inProc. ISCA Workshop Speech Synth. (SSW), 2019, pp. 155–160
2019
-
[25]
Design Choices for X-vector Based Speaker Anonymization,
B. M. L. Srivastava, N. Tomashenko, X. Wang, E. Vincent, J. Yamagishi, M. Maouche, A. Bellet, and M. Tommasi, “Design Choices for X-vector Based Speaker Anonymization,” inProc. Interspeech, 2020, pp. 1713– 1717
2020
-
[26]
Privacy and utility of x-vector based speaker anonymization,
B. M. L. Srivastava, M. Maouche, M. Sahidullah, E. Vincent, A. Bellet, M. Tommasi, N. Tomashenko, X. Wang, and J. Yamagishi, “Privacy and utility of x-vector based speaker anonymization,”IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 30, pp. 2383–2395, 2022
2022
-
[27]
Speaker anonymization using orthogonal householder neural network,
X. Miao, X. Wang, E. Cooper, J. Yamagishi, and N. Tomashenko, “Speaker anonymization using orthogonal householder neural network,” IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 31, pp. 3681– 3695, 2023
2023
-
[28]
Speaker anonymization for voice biomet- rics protection using voice conversion and multi-target speaker voice fusion,
Y . A. Wubet and K.-Y . Lian, “Speaker anonymization for voice biomet- rics protection using voice conversion and multi-target speaker voice fusion,”IEEE Trans. Inf. F orensics Security, 2025
2025
-
[29]
Speaker anonymization for personal information protection using voice conver- sion techniques,
I.-C. Yoo, K. Lee, S. Leem, H. Oh, B. Ko, and D. Yook, “Speaker anonymization for personal information protection using voice conver- sion techniques,”IEEE Access, 2020
2020
-
[30]
MUSA: Multi-lingual speaker anonymization via serial disentangle- ment,
J. Yao, Q. Wang, P. Guo, Z. Ning, Y . Yang, Y . Pan, and L. Xie, “MUSA: Multi-lingual speaker anonymization via serial disentangle- ment,”IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 33, pp. 1664–1674, 2025
2025
-
[31]
Speaker anonymization using generative adversarial networks,
A. Jafari, A. Al-Mousa, and I. Jafar, “Speaker anonymization using generative adversarial networks,”J. Intell. Fuzzy Syst., vol. 45, no. 2, pp. 3345–3359, 2023
2023
-
[32]
Flow matching for generative modeling,
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,” inProc. ICLR, 2023
2023
-
[33]
Content anonymiza- tion for privacy in long-form audio,
C. Aggazzotti, A. Garg, Z. Cai, and N. Andrews, “Content anonymiza- tion for privacy in long-form audio,”arXiv preprint arXiv:2510.12780, 2025
-
[34]
V oice privacy preservation with multiple random orthogonal secret keys: Attack resistance analysis,
K. Tanaka, H. Kiya, and S. Shiota, “V oice privacy preservation with multiple random orthogonal secret keys: Attack resistance analysis,” arXiv preprint arXiv:2509.19906, 2025
-
[35]
Speech privacy-preserving methods using secret key for convolutional neural network models and their robustness evaluation,
N. Shoko, S. Shiota, and H. Kiya, “Speech privacy-preserving methods using secret key for convolutional neural network models and their robustness evaluation,”APSIPA Trans. Signal Inf. Process., pp. 1–30, 2024
2024
-
[36]
V oco: Text- based insertion and replacement in audio narration,
Z. Jin, G. J. Mysore, S. Diverdi, J. Lu, and A. Finkelstein, “V oco: Text- based insertion and replacement in audio narration,”ACM Trans. Graph., vol. 36, no. 4, pp. 1–13, 2017
2017
-
[37]
V oice- Craft: Zero-shot speech editing and text-to-speech in the wild,
P. Peng, P.-Y . Huang, S.-W. Li, A. Mohamed, and D. Harwath, “V oice- Craft: Zero-shot speech editing and text-to-speech in the wild,” inProc. ACL, 2024, pp. 12 442–12 462
2024
-
[38]
Addressing challenges in speaker anonymization to maintain utility while ensuring privacy of pathological speech,
S. Tayebi Arasteh, T. Arias-Vergara, P. A. P ´erez-Toro, T. Weise, K. Packh ¨auser, M. Schuster, E. Noeth, A. Maier, and S. H. Yang, “Addressing challenges in speaker anonymization to maintain utility while ensuring privacy of pathological speech,”Commun. Med., vol. 4, no. 1, p. 182, 2024
2024
-
[39]
A speech obfuscation system to preserve data privacy in 24-hour ambulatory cough monitoring,
T. E. Taylor, F. Keane, and Y . Zigel, “A speech obfuscation system to preserve data privacy in 24-hour ambulatory cough monitoring,”IEEE J. Sel. Top. Signal Process., 2022
2022
-
[40]
You Are What You Say: Exploiting Linguistic Content for V oicePrivacy Attacks,
¨U. E. Gaznepoglu, A. Leschanowsky, A. Aloradi, P. Singh, D. Tenbrinck, E. A. P. Habets, and N. Peters, “You Are What You Say: Exploiting Linguistic Content for V oicePrivacy Attacks,” inProc. Interspeech, 2025, pp. 4238–4242
2025
-
[41]
Scalable diffusion models with transformers,
W. Peebles and S. Xie, “Scalable diffusion models with transformers,” inProc. ICCV, 2023, pp. 4195–4205
2023
-
[42]
Vector quantization,
R. Gray, “Vector quantization,”IEEE ASSP Mag., vol. 1, no. 2, pp. 4–29, 1984
1984
-
[43]
RoFormer: En- hanced transformer with rotary position embedding,
J. Su, M. Ahmed, Y . Lu, S. Pan, W. Bo, and Y . Liu, “RoFormer: En- hanced transformer with rotary position embedding,”Neurocomputing, vol. 568, p. 127063, 2024
2024
-
[44]
Librispeech: An ASR corpus based on public domain audio books,
V . Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Librispeech: An ASR corpus based on public domain audio books,” inProc. ICASSP, 2015, pp. 5206–5210
2015
-
[45]
LibriTTS: A corpus derived from LibriSpeech for text-to- speech,
H. Zen, V . Dang, R. Clark, Y . Zhang, R. J. Weiss, Y . Jia, Z. Chen, and Y . Wu, “LibriTTS: A corpus derived from LibriSpeech for text-to- speech,” inProc. Interspeech, 2019, pp. 1526–1530
2019
-
[46]
IEMOCAP: Interactive emotional dyadic motion capture database,
C. Busso, M. Bulut, C.-C. Lee, A. Kazemzadeh, E. Mower, S. Kim, J. N. Chang, S. Lee, and S. S. Narayanan, “IEMOCAP: Interactive emotional dyadic motion capture database,”Lang. Resour . Eval., pp. 335–359, 2008
2008
-
[47]
ConvNeXt V2: Co-designing and scaling convnets with masked autoencoders,
S. Woo, S. Debnath, R. Hu, X. Chen, Z. Liu, I. S. Kweon, and S. Xie, “ConvNeXt V2: Co-designing and scaling convnets with masked autoencoders,” inProc. CVPR, 2023, pp. 16 133–16 142
2023
-
[48]
N. Tomashenko, X. Miao, E. Vincent, and J. Yamagishi, “The first V oicePrivacy attacker challenge evaluation plan,”arXiv preprint arXiv:2410.07428, 2024
-
[49]
Speaker anonymization using neural audio codec language models,
M. Panariello, F. Nespoli, M. Todisco, and N. Evans, “Speaker anonymization using neural audio codec language models,” inProc. ICASSP, 2024, pp. 4725–4729
2024
-
[50]
Anonymizing speech: Evaluating and designing speaker anonymization techniques,
P. Champion, “Anonymizing speech: Evaluating and designing speaker anonymization techniques,”arXiv preprint arXiv:2308.04455, 2023
-
[51]
The T05 system for the V oiceMOS challenge 2024: Transfer learning from deep image clas- sifier to naturalness MOS prediction of high-quality synthetic speech,
K. Baba, W. Nakata, Y . Saito, and H. Saruwatari, “The T05 system for the V oiceMOS challenge 2024: Transfer learning from deep image clas- sifier to naturalness MOS prediction of high-quality synthetic speech,” inProc. SLT, 2024, pp. 818–824
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.