Recognition: unknown
Mini-BEHAVIOR-Gran: Revealing U-Shaped Effects of Instruction Granularity on Language-Guided Embodied Agents
Pith reviewed 2026-05-10 06:42 UTC · model grok-4.3
The pith
Embodied agents show U-shaped performance with instruction granularity, performing best at both fine and coarse extremes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
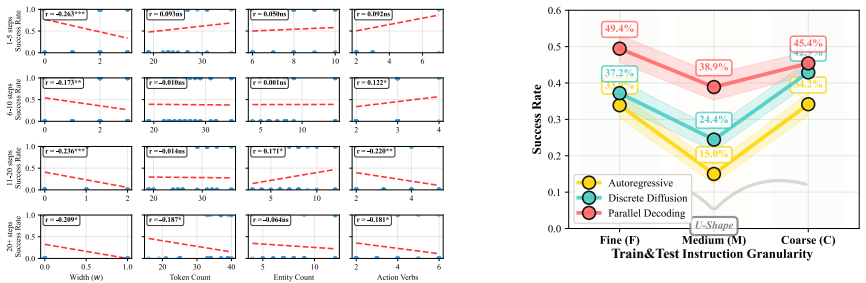
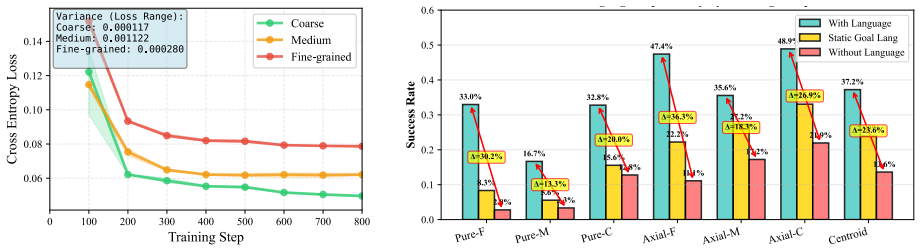
Using width to organize training and evaluation further reveals a non-monotonic U-shaped relationship between instruction granularity and performance, with peaks at both fine and coarse extremes. Further analysis suggests that the coarse-granularity performance rebound is associated with shallow grounding, where agents learn vision-dominant policies.
What carries the argument
Planning-width, the metric that counts the breadth of planning steps implied by an instruction, which organizes data and reveals the U-shaped performance pattern more consistently than token count, entity count, or action-verb count.
If this is right
- Coarse instructions cause agents to fall back on vision-dominant policies with shallow language use.
- Medium-granularity instructions produce the weakest results across the tested agents.
- Benchmarks limited to one static instruction per task will miss these non-monotonic effects.
- Choosing the right granularity metric matters, since width tracks behavior better than simpler counts.
Where Pith is reading between the lines
- Instruction design in robotics applications may benefit from deliberately choosing either very high-level or very precise phrasing rather than aiming for balanced detail.
- The shallow-grounding explanation implies that scaling language model size alone may not fix medium-granularity failures without changes to perception or training.
- The benchmark could be extended to measure how quickly agents shift from language to vision shortcuts as granularity coarsens.
- Similar U-shaped patterns might appear in other sequential decision domains where intermediate abstraction levels create optimization difficulties.
Load-bearing premise
That the planning-width metric supplies a valid, causal quantification of instruction granularity that drives performance differences on its own, separate from agent architecture or task specifics.
What would settle it
Running the same agents on the benchmark but replacing width-sorted instructions with random granularity assignments and finding that the U-shape and coarse rebound both disappear.
Figures






read the original abstract
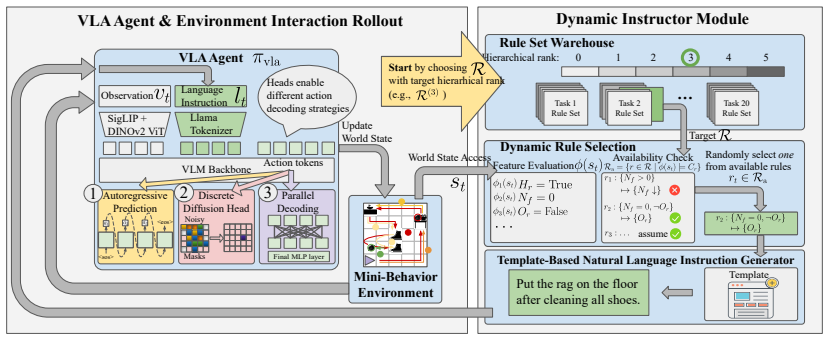
Instruction granularity is an important yet poorly controlled variable in language-guided embodied AI. Existing benchmarks typically pair each task with a single static instruction, making it difficult to study how agent behavior changes when the same task is described at different levels of detail. We introduce Mini-BEHAVIOR-Gran, a new benchmark for controlled studies of instruction granularity that extends Mini-BEHAVIOR with multiple instruction variants per task, ranging from high-level goal descriptions to step-by-step guidance. Using this benchmark, we compare four candidate metrics for cross-task granularity quantification: token count, entity count, action-verb count, and planning-width, and find that width correlates most consistently with agent performance. Using width to organize training and evaluation further reveals a non-monotonic U-shaped relationship between instruction granularity and performance, with peaks at both fine and coarse extremes. Further analysis suggests that the coarse-granularity performance rebound is associated with shallow grounding, where agents learn vision-dominant policies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Mini-BEHAVIOR-Gran, an extension of Mini-BEHAVIOR that supplies multiple instruction variants per task spanning high-level goals to step-by-step guidance. It evaluates four candidate metrics for quantifying instruction granularity (token count, entity count, action-verb count, planning-width) and reports that planning-width correlates most consistently with agent performance. Organizing training and evaluation by this width metric reveals a non-monotonic U-shaped performance curve with peaks at both fine-grained and coarse-grained extremes; the coarse extreme is attributed to agents learning shallow, vision-dominant policies.
Significance. If the U-shaped pattern and the superiority of planning-width prove robust after controlling for confounders, the work would be significant for language-guided embodied AI. It supplies a controlled benchmark for studying granularity, challenges the common assumption that finer instructions are uniformly superior, and offers a mechanistic hypothesis (shallow grounding) that could guide future instruction design and policy analysis. The empirical focus on cross-task quantification is a useful contribution even if the causal interpretation requires strengthening.
major comments (3)
- [Abstract] Abstract: The claim that planning-width 'correlates most consistently' with performance is presented without any quantitative support (correlation coefficients, rank-order statistics, or per-task comparisons). This absence prevents assessment of whether width is meaningfully superior to the other three metrics and whether it can serve as the organizing variable for the U-shape experiments.
- [Abstract] Abstract: The U-shaped relationship is asserted as the central empirical result, yet the abstract contains no performance numbers, variance estimates, number of runs, or statistical tests. Without these data it is impossible to judge whether the reported peaks at the fine and coarse extremes are reliable or whether they could arise from task-specific factors unrelated to granularity.
- [Abstract] Abstract: The attribution of the coarse-granularity rebound to 'shallow grounding' and 'vision-dominant policies' is stated without reference to supporting analyses (attention visualizations, ablation results, or policy probes). This leaves open the possibility that width simply proxies for easier-to-ground coarse goals rather than causally isolating granularity effects from visual ambiguity or task difficulty.
minor comments (1)
- The manuscript would benefit from explicit definitions and illustrative examples of each of the four granularity metrics, ideally placed early in the methods section so readers can replicate the width calculations.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each of the major comments below. We agree that the abstract can be strengthened with additional quantitative details and references to the supporting analyses present in the main text, and we will make these revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that planning-width 'correlates most consistently' with performance is presented without any quantitative support (correlation coefficients, rank-order statistics, or per-task comparisons). This absence prevents assessment of whether width is meaningfully superior to the other three metrics and whether it can serve as the organizing variable for the U-shape experiments.
Authors: We thank the referee for this observation. Although the main manuscript (Section 4.2) provides a full quantitative comparison of the four metrics, including correlation coefficients and consistency across tasks, the abstract summarizes the finding without these details. To make the abstract more informative and self-contained, we will revise it to include the key correlation values and note that planning-width is the most consistent metric. revision: yes
-
Referee: [Abstract] Abstract: The U-shaped relationship is asserted as the central empirical result, yet the abstract contains no performance numbers, variance estimates, number of runs, or statistical tests. Without these data it is impossible to judge whether the reported peaks at the fine and coarse extremes are reliable or whether they could arise from task-specific factors unrelated to granularity.
Authors: The abstract prioritizes brevity, but we agree that including high-level performance indicators would help readers assess the result. The full paper reports all results as averages over multiple runs (with standard deviations) and confirms the U-shape across tasks. We will update the abstract to mention the number of runs and provide example performance figures for the different granularity levels. revision: yes
-
Referee: [Abstract] Abstract: The attribution of the coarse-granularity rebound to 'shallow grounding' and 'vision-dominant policies' is stated without reference to supporting analyses (attention visualizations, ablation results, or policy probes). This leaves open the possibility that width simply proxies for easier-to-ground coarse goals rather than causally isolating granularity effects from visual ambiguity or task difficulty.
Authors: We acknowledge that the abstract does not explicitly reference the supporting evidence. However, the manuscript contains attention visualizations (Figure 5) and ablation experiments (Section 5.3) demonstrating the vision-dominant behavior for coarse instructions. We will revise the abstract to briefly cite these analyses, e.g., 'supported by attention and ablation studies'. This should clarify that the interpretation is grounded in the presented evidence rather than being a post-hoc attribution. revision: yes
Circularity Check
Empirical benchmark study shows no circularity
full rationale
The paper introduces a new benchmark (Mini-BEHAVIOR-Gran) with multiple instruction variants per task and reports empirical comparisons of four granularity metrics, selecting planning-width for its consistent correlation with agent performance. The non-monotonic U-shaped relationship is presented as an observed pattern when organizing training and evaluation by this metric, with further analysis linking coarse-granularity rebound to vision-dominant policies. No mathematical derivations, self-definitional equivalences, fitted parameters called predictions, or load-bearing self-citations appear in the chain. All central claims reduce to direct experimental results on the constructed benchmark rather than any reduction to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mini-BEHAVIOR tasks and environments provide a representative and controlled setting for measuring effects of language instruction on embodied agents.
Reference graph
Works this paper leans on
-
[1]
Accurately and efficiently interpreting human- robot instructions of varying granularities.arXiv preprint arXiv:1704.06616. Hongzhe Bi, Hengkai Tan, Shenghao Xie, Zeyuan Wang, Shuhe Huang, Haitian Liu, Ruowen Zhao, Yao Feng, Chendong Xiang, Yinze Rong, Hongyan Zhao, Hanyu Liu, Zhizhong Su, Lei Ma, Hang Su, and Jun Zhu. 2025. Motus: A unified latent action...
-
[2]
Expressing and exploiting subgoal structure in classical planning using sketches.J. Artif. Intell. Res., 80. Senyu Fei, Siyin Wang, Junhao Shi, Zihao Dai, Jikun Cai, Pengfang Qian, Li Ji, Xinzhe He, Shiduo Zhang, Zhaoye Fei, Jinlan Fu, Jingjing Gong, and Xipeng Qiu. 2025. Libero-plus: In-depth robustness anal- ysis of vision-language-action models.Preprin...
work page internal anchor Pith review arXiv 2025
-
[3]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Mini-BEHA VIOR: A procedurally generated benchmark for long-horizon decision-making in em- bodied AI. InNeurIPS 2023 Workshop on General- ization in Planning. Siddharth Karamcheti, Suraj Nair, Ashwin Balakrishna, Percy Liang, Thomas Kollar, and Dorsa Sadigh. 2024. Prismatic vlms: Investigating the design space of visually-conditioned language models. InFo...
work page internal anchor Pith review arXiv 2023
-
[4]
IEEE. Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mido Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, and 7 others. 2024. Dinov2: Learning robust visual featu...
-
[5]
PD-VLA: accelerating vision-language-action model integrated with action chunking via parallel decoding. InIROS, pages 13162–13169. IEEE. Gerald Jay Sussman. 1975.A computer model of skill acquisition. Elsevier Science Inc. Hongyu Wang, Chuyan Xiong, Ruiping Wang, and Xilin Chen. 2025. Bitvla: 1-bit vision-language-action models for robotics manipulation....
-
[6]
A pragmatic vla foundation model,
A pragmatic vla foundation model.Preprint, arXiv:2601.18692. Lei Xiao, Jifeng Li, Juntao Gao, Feiyang Ye, Yan Jin, Jingjing Qian, Jing Zhang, Yong Wu, and Xiaoyuan Yu. 2025. Ava-vla: Improving vision-language- action models with active visual attention.arXiv preprint arXiv:2511.18960. Youguang Xing, Xu Luo, Junlin Xie, Lianli Gao, Heng Tao Shen, and Jingk...
-
[7]
DeepThinkVLA: Enhancing Reasoning Capability of Vision-Language-Action Models
Deepthinkvla: Enhancing reasoning capabil- ity of vision-language-action models.arXiv preprint arXiv:2511.15669. Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. 2023. Sigmoid loss for language image pre-training. InICCV, pages 11941–11952. IEEE. Ninghao Zhang, Bin Zhu, Shijie Zhou, and Jingjing Chen. 2026. Restoring linguistic groundin...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Anticipatory defense on the choice of test en- vironments and metrics(§ C) Justification for using MINI-BEHAVIOR over alternatives (e.g., iGibson, CALVIN) based on controllability, symbolic abstraction, and isola- tion of language-grounding challenges. 12
-
[9]
Symbolic Representation of the Embodied Task(§ D) Formal definition of states, actions, and planning problems using classical STRIP- S/PDDL semantics
-
[10]
Details of the MINI-BEHAVIOR Environ- ment(§ E) Overview of scene layout, object types, action space, and perception model
-
[11]
Details of the MINI-BEHAVIOR-GRANEx- tension(§ F) Procedure for generating multi- granularity instructions, details on the feature set, dynamic instructor, and dataset construc- tion
-
[12]
Rule Set and Natural Language Prompt Ex- amples(§ G) Details of the rule set bank of 20 tasks and sample generated instructions at different granularities
-
[13]
VLM Predictor architecture and training details
Implementation Details(§ H) Model architec- ture (Prismatic-7B backbone, SigLIP+DINOv2 visual encoders), training hyperparameters, opti- mizer settings. VLM Predictor architecture and training details
-
[14]
distance decreased
Additional Experimental Results(§ I) Ex- tended analysis and ablations. C Anticipatory defense on the choice of test environments and metrics In this work, we selected Mini-BEHA VIOR as our testbed. This choice is motivated by several key considerations aligned with our research objectives. Our research objective is not to solve the full stack of robotic ...
2021
-
[15]
Head Averaging: attn(R) = 1 H PH h=1 attnh(R)
-
[16]
Sample Mean: Values are averaged across all samples within a specific granularity-model pair
-
[17]
reduce the count of
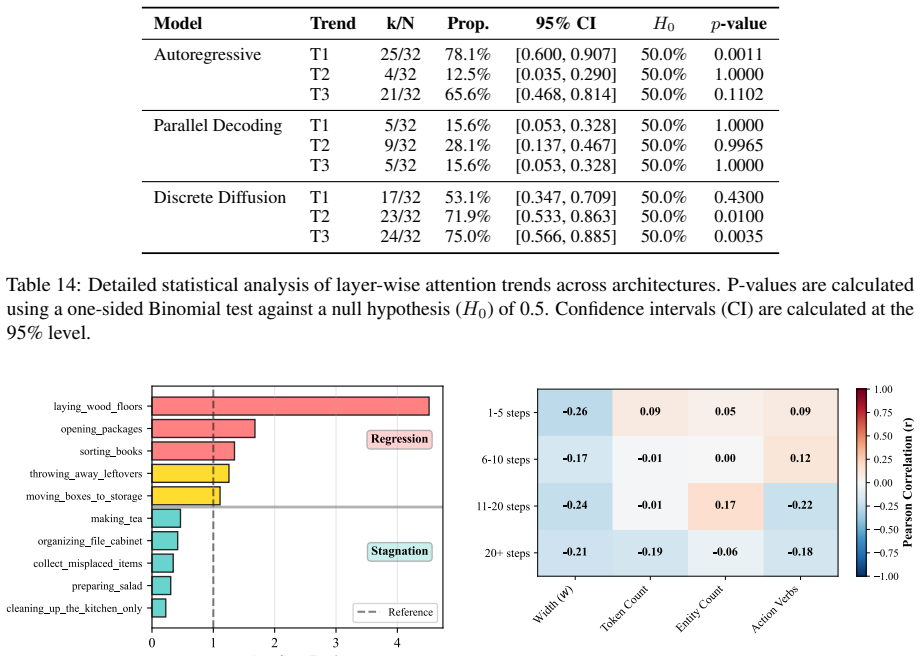
Simplex Normalization: The final regional shares ˆaR are normalized such that P R ˆaR = 1. I.2.5 Statistical Trend Hypothesis Testing We define three binary indicators to test theShal- low Grounding Hypothesislayer-wise: •T1 (Lang↑):ˆa text(Medium)>ˆatext(Fine) •T2 (Lang↓):ˆa text(Medium)>ˆatext(Coarse) •T3 (Vis↑):ˆa vis(Coarse)>ˆavis(Medium) We assess th...
-
[18]
At step 11: When the count of uncleaned plate is above 0, not yet at sink 0 and sink is off, please try to move toward sink 0
-
[19]
At step 8: When not yet at soap 0, not holding soap 0, the count of unwiped car is 0 and the count of rag not inside bucket is 0, please try to move toward soap 0
-
[20]
At step 27: When the count of chip and oatmeal sugar and vegetable oil not inside cabinet is above 0, you are at oatmeal 1 and not holding oatmeal 1, please pick up oatmeal 1
-
[21]
At step 15: When the count of plate not inside cabinet is above 0, you are at plate 3, the count of closed cabinet is 0 and not holding plate 3, please pick up plate 3
-
[22]
Medium Granularity (M) Samples
At step 13: When the count of fish and olive not near sink is above 0, not yet at olive 0 and not holding olive 0, please try to move toward olive 0. Medium Granularity (M) Samples
-
[23]
At step 2: When the count of plate not inside cabinet is above 0, the count of closed cabinet is 0 and not holding plate 2, please pick up plate 2
-
[24]
At step 6: When the count of uncleaned plate is above 0, the count of dry rag is above 0 and holding rag 0, please reduce the count of dry rag
-
[25]
At step 9: When the count of plate not inside cabinet 0 is above 0, the count of closed cabinet is 0, the count of vegetable oil not inside cabinet 1 is 0, the count of uncleaned plate is 0 and not holding plate 0, please pick up plate 0
-
[26]
At step 13: When the count of book not inside box is above 0 and not holding book 2, please pick up book 2
-
[27]
Coarse Granularity (C) Samples
At step 9: When the count of chip and oatmeal sugar and vegetable oil not inside cabinet is above 0, holding chip 1 and the count of closed cabinet is 0, please not holding chip 1, then reduce the count of chip and oatmeal sugar and vegetable oil not inside cabinet. Coarse Granularity (C) Samples
-
[28]
At step 2: When the count of hamburger not inside ashcan is above 0, please reduce the count of hamburger not inside ashcan
-
[29]
At step 5: When the count of plate not inside cabinet is above 0 and the count of closed cabinet is 0, please reduce the count of plate not inside cabinet
-
[30]
At step 3: When the count of teapot not on stove is above 0, please reduce the count of teapot not on stove
-
[31]
At step 9: When the count of plate not inside cabinet is above 0 and the count of closed cabinet is 0, please reduce the count of plate not inside cabinet
-
[32]
Table 15: Sample generated instructions across granularity levels
At step 8: When the count of chip and oatmeal sugar and vegetable oil not inside cabinet is above 0 and the count of closed cabinet is 0, please reduce the count of chip and oatmeal sugar and vegetable oil not inside cabinet. Table 15: Sample generated instructions across granularity levels. 23
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.