Recognition: unknown
CAM3DNet: Comprehensively mining the multi-scale features for 3D Object Detection with Multi-View Cameras
Pith reviewed 2026-05-10 07:12 UTC · model grok-4.3
The pith
CAM3DNet uses three specialized modules to mine multi-scale features from multi-view camera images for improved 3D object detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
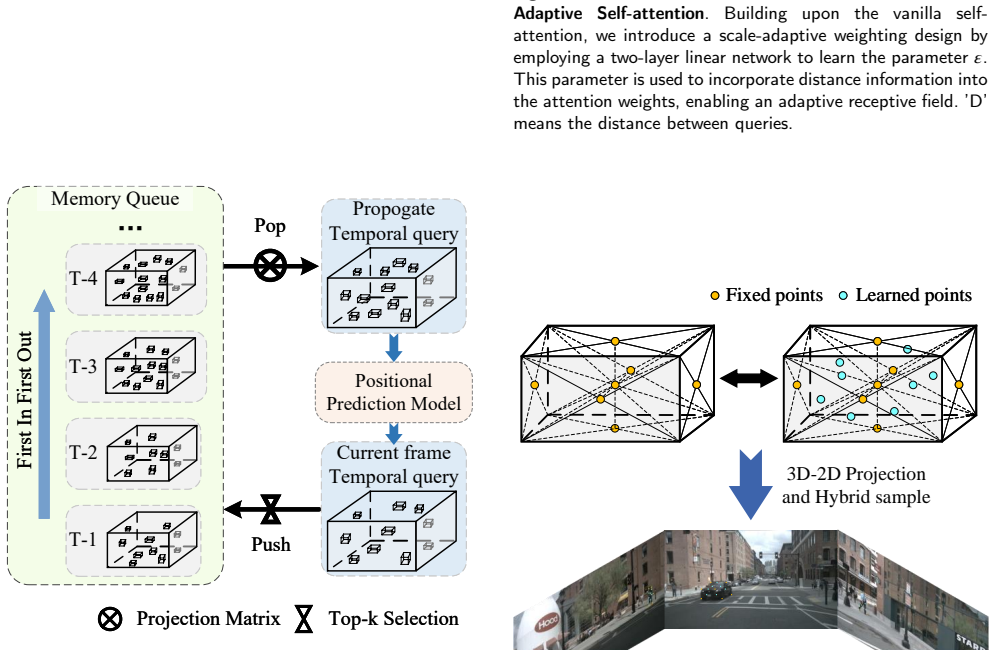
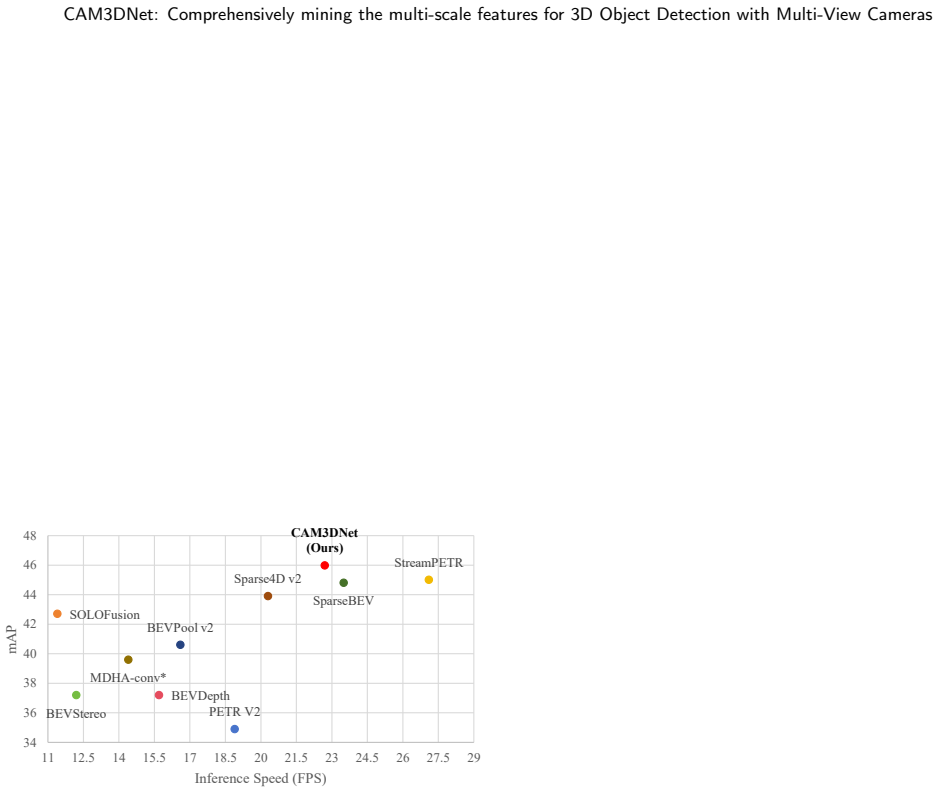
The central claim is that a sparse query-based framework combining a composite query module for multi-scale 2D-to-3D projection, an adaptive self-attention module for spatiotemporal multi-scale query interactions, and a multi-scale hybrid sampling module using deformable attention can comprehensively mine multi-scale features and outperform most existing camera-based 3D object detection methods on the nuScenes, Waymo, and Argoverse datasets.
What carries the argument
The CAM3DNet architecture, which uses a backbone and FPN encoder, YOLOX and DepthNet for generating composite queries, and repeated ASA and MSHS in the decoder to process multi-view image features.
If this is right
- The model demonstrates effectiveness through extensive experiments on nuScenes, Waymo, and Argoverse benchmarks, outperforming most prior camera-based methods.
- Comprehensive ablation studies confirm the individual contributions of the CQ, ASA, and MSHS modules.
- Space and computation complexity remain manageable despite handling multi-scale information.
- The framework enables better learning of object-query geometric relationships and multi-scale spatiotemporal features.
Where Pith is reading between the lines
- This could extend to improving efficiency in other vision tasks that involve multi-scale feature extraction from multiple viewpoints.
- Autonomous driving systems might achieve higher accuracy in 3D detection without relying on LiDAR by adopting similar query-based multi-scale mining.
- Future tests could explore real-time performance on embedded hardware to validate practical deployment.
- The modules might generalize to 3D detection in other environments beyond driving scenes.
Load-bearing premise
The three modules together can capture dynamic multi-scale spatiotemporal relationships efficiently without prohibitive computational costs.
What would settle it
If experiments on nuScenes show that CAM3DNet does not achieve higher detection accuracy than the current best camera-based methods, or if removing any module causes no performance drop, the central claim would be falsified.
Figures







read the original abstract
Query-based 3D object detection methods using multi-view images often struggle to efficiently leverage dynamic multi-scale information, e.g., the relationship between the object features and the geometric of the queries are not sufficiently learned, directly exploring the multi-scale spatiotemporal features will pay too many costs. To address these challenges, we propose CAM3DNet, a novel sparse query-based framework which combines three new modules, composite query (CQ), adaptive self-attention (ASA), and multi-scale hybrid sampling (MSHS). First, the core idea in the CQ module is a multi-scale projection strategy to transform 2D queries into 3D space. Second, the ASA module learns the interactions between the spatiotemporal multi-scale queries. Third, the MSHS module uses the deformable attention mechanism to sample multi-scale object information by considering multi-scales queries, pyramid feature maps, and 2D-camera prior knowledge. The entire model employs a backbone network and a feature pyramid network (FPN) as the encoder, then introduces a YOLOX and a DepthNet as a ROI\_Head to produce CQ, and repeatedly utilizes ASA and MSHS as the decoder to gain detection features. Extensive experiments on the nuScenes, Waymo, and Argoverse benchmark datasets demonstrate the effectiveness of our CAM3DNet, and most existing camera-based 3D object detection methods are outperformed. Besides, we make comprehensive ablation studies to check the individual effect of CQ, ASA, and MSHS, as well as their cost of space and computation complexity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents CAM3DNet, a sparse query-based framework for multi-view camera 3D object detection. It introduces three modules: Composite Query (CQ) using multi-scale projection to map 2D queries to 3D space, Adaptive Self-Attention (ASA) to model interactions among spatiotemporal multi-scale queries, and Multi-Scale Hybrid Sampling (MSHS) employing deformable attention over multi-scale queries, pyramid features, and camera priors. The architecture uses a backbone+FPN encoder, YOLOX+DepthNet ROI_Head to produce CQ, and repeated ASA/MSHS as decoder. The central claim is that this design efficiently captures dynamic multi-scale spatiotemporal relationships and outperforms most existing camera-based 3D detectors on nuScenes, Waymo, and Argoverse, supported by ablation studies on module contributions and computational costs.
Significance. If the benchmark gains and efficiency assertions are substantiated, the work would advance practical camera-only 3D detection for autonomous driving by offering a targeted alternative to high-cost direct multi-scale feature processing. The explicit inclusion of ablation studies covering both individual module effects and space/computation complexity is a strength that aids assessment of design choices and supports empirical validation.
major comments (2)
- Abstract: The assertion that the CQ/ASA/MSHS modules capture dynamic multi-scale spatiotemporal relationships more efficiently than direct multi-scale exploration (contrasted explicitly against 'too many costs') lacks any quantitative anchors such as FLOPs, peak memory, or latency for the pipeline or decoder stages. This is load-bearing for the practicality of the headline outperformance claim on the three benchmarks, even though ablation studies on computation complexity are mentioned.
- Abstract: The claim that 'most existing camera-based 3D object detection methods are outperformed' on nuScenes, Waymo, and Argoverse is stated without reference to specific metrics (e.g., mAP, NDS), tables, error bars, or baseline comparisons, preventing verification of the magnitude and robustness of the reported improvements.
minor comments (2)
- The notation 'ROI_Head' appears with an escaped underscore that should be corrected for readability.
- The abstract would be strengthened by briefly stating key quantitative results (e.g., mAP/NDS deltas) from the experiments and ablations.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive recognition of our ablation studies and potential practical impact. We address the two major comments on the abstract below.
read point-by-point responses
-
Referee: Abstract: The assertion that the CQ/ASA/MSHS modules capture dynamic multi-scale spatiotemporal relationships more efficiently than direct multi-scale exploration (contrasted explicitly against 'too many costs') lacks any quantitative anchors such as FLOPs, peak memory, or latency for the pipeline or decoder stages. This is load-bearing for the practicality of the headline outperformance claim on the three benchmarks, even though ablation studies on computation complexity are mentioned.
Authors: We agree that the abstract would benefit from explicit quantitative anchors to support the efficiency claim. The manuscript already includes detailed ablation results on computational costs (FLOPs, parameters, peak memory, and latency) in Section 4.3 and Table 5, which show that the added modules incur only marginal overhead relative to direct multi-scale baselines while delivering the reported gains. We will revise the abstract to include a brief, specific reference to these metrics (e.g., noting the small increase in FLOPs and latency). revision: yes
-
Referee: Abstract: The claim that 'most existing camera-based 3D object detection methods are outperformed' on nuScenes, Waymo, and Argoverse is stated without reference to specific metrics (e.g., mAP, NDS), tables, error bars, or baseline comparisons, preventing verification of the magnitude and robustness of the reported improvements.
Authors: We acknowledge that the abstract statement is too general. The full paper provides the requested quantitative evidence in Tables 1–3, which report mAP, NDS, and other metrics with direct comparisons to prior camera-based methods on all three benchmarks, demonstrating consistent outperformance. We will revise the abstract to cite the key results (e.g., the achieved NDS/mAP values) and explicitly reference the tables for detailed verification. revision: yes
Circularity Check
No circularity: empirical architecture validated on external benchmarks
full rationale
The paper introduces an architectural framework (CAM3DNet) with three modules (CQ, ASA, MSHS) for multi-view camera 3D detection. It describes the modules in terms of standard operations (multi-scale projection, adaptive self-attention, deformable sampling) and evaluates them via training on public datasets (nuScenes, Waymo, Argoverse) plus ablations. No equations, predictions, or uniqueness claims reduce to self-defined quantities, fitted inputs renamed as outputs, or load-bearing self-citations. The performance claims rest on external benchmark results rather than internal redefinitions or tautological fits.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Deformable attention can sample relevant multi-scale object features when guided by query scale and camera priors
Reference graph
Works this paper leans on
-
[1]
K. Renz, L. Chen, E. Arani, O. Sinavski, Simlingo: Vision-only closed-loop autonomous driving with language-action alignment, in: ProceedingsoftheIEEEConferenceonComputerVisionandPattern Recognition, 2025, pp. 11993–12003
2025
- [2]
-
[3]
P. Wu, X. Jia, L. Chen, J. Yan, H. Li, Y. Qiao, Trajectory-guided control prediction for end-to-end autonomous driving: A simple yet strong baseline, in: Advances in Neural Information Processing Systems, volume 35, 2022, pp. 6119–6132
2022
-
[4]
J.Philion,S.Fidler, Lift,splat,shoot:Encodingimagesfromarbitrary camerarigsbyimplicitlyunprojectingto3d, in:EuropeanConference on Computer Vision, 2020
2020
- [5]
- [6]
-
[7]
Y.Li,Z.Ge,G.Yu,J.Yang,Z.Wang,Y.Shi,J.Sun,Z.Li, Bevdepth: Acquisition of reliable depth for multi-view 3d object detection, in: ProceedingsoftheAAAIConferenceonArtificialIntelligence,2023
2023
- [8]
- [9]
-
[10]
Y. Wang, V. C. Guizilini, T. Zhang, Y. Wang, H. Zhao, J. Solomon, Detr3d: 3d object detection from multi-view images via 3d-to-2d queries, in: Conference on Robot Learning, 2022
2022
-
[11]
X. Zhu, W. Su, L. Lu, B. Li, X. Wang, J. Dai, Deformable detr: Deformable transformers for end-to-end object detection, in: Inter- national Conference on Learning Representations, 2021
2021
-
[12]
Carion, F
N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, S. Zagoruyko, End-to-end object detection with transformers, in: European Conference on Computer Vision, 2020
2020
- [13]
-
[14]
Y. Liu, T. Wang, X. Zhang, J. Sun, Petr: Position embedding transformation for multi-view 3d object detection, in: European Conference on Computer Vision, 2022
2022
-
[15]
Y. Liu, J. Yan, F. Jia, S. Li, A. Gao, T. Wang, X. Zhang, Petrv2: A unified framework for 3d perception from multi-camera images, in: ProceedingsoftheIEEE/CVFInternationalConferenceonComputer Vision, 2023. Mingxi Pang et al.:Preprint submitted to ElsevierPage 11 of 12 CAM3DNet: Comprehensively mining the multi-scale features for 3D Object Detection with M...
2023
-
[16]
S. Wang, Y. Liu, T. Wang, Y. Li, X. Zhang, Exploring object-centric temporal modeling for efficient multi-view 3d object detection, in: ProceedingsoftheIEEE/CVFInternationalConferenceonComputer Vision, 2023
2023
-
[17]
S. Wang, X. Jiang, Y. Li, Focal-petr: Embracing foreground for efficient multi-camera 3d object detection, IEEE Transactions on Intelligent Vehicles 9 (2024) 1481–1489
2024
-
[18]
Zhang, F
H. Zhang, F. Li, S. Liu, L. Zhang, H. Su, J. Zhu, L. M. Ni, H.-Y. Shum, Dino: Detr with improved denoising anchor boxes for end- to-end object detection, in: International Conference on Learning Representations, 2023
2023
-
[19]
Zhang, H
R. Zhang, H. Qiu, T. Wang, Z. Guo, Z. Cui, Y. Qiao, H. Li, P. Gao, Monodetr: Depth-guided transformer for monocular 3d object detec- tion, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 9155–9166
2023
- [20]
- [21]
- [22]
-
[23]
Z. Li, W. Wang, H. Li, E. Xie, C. Sima, T. Lu, Y. Qiao, J. Dai, Bev- former: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers, in: European Conference on Computer Vision, 2022
2022
- [24]
-
[25]
Z. Zong, D. Jiang, G. Song, Z. Xue, J. Su, H. Li, Y. Liu, Temporal enhanced training of multi-view 3d object detector via historical object prediction, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 3781–3790
2023
-
[26]
H. Liu, Y. Teng, T. Lu, H. Wang, L. Wang, Sparsebev: High- performancesparse3dobjectdetectionfrommulti-cameravideos, in: ProceedingsoftheIEEE/CVFInternationalConferenceonComputer Vision, 2023, pp. 18580–18590
2023
-
[27]
2668–2675
M.Adeline,J.Y.Loo,V.M.Baskaran, Mdha:Multi-scaledeformable transformer with hybrid anchors for multi-view 3d object detection, in:2024IEEE/RSJInternationalConferenceonIntelligentRobotsand Systems (IROS), IEEE, 2024, pp. 2668–2675
2024
-
[28]
Z. Wang, Z. Huang, J. Fu, N. Wang, S. Liu, Object as query: Lifting any 2d object detector to 3d detection, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023
2023
-
[29]
Jiang, S
X. Jiang, S. Li, Y. Liu, S. Wang, F. Jia, T. Wang, L. Han, X. Zhang, Far3d: Expanding the horizon for surround-view 3d object detection, in: Proceedings of the AAAI Conference on Artificial Intelligence, 2024
2024
-
[30]
C.Yang,Y.Chen,H.Tian,C.Tao,X.Zhu,Z.Zhang,G.Huang,H.Li, Y.Qiao,L.Lu,J.Zhou,J.Dai,Bevformerv2:Adaptingmodernimage backbonestobird’s-eye-viewrecognitionviaperspectivesupervision, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023
2023
-
[31]
K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016
2016
-
[32]
Lee, J.-w
Y. Lee, J.-w. Hwang, S. Lee, Y. Bae, J. Park, An energy and gpu- computation efficient backbone network for real-time object detec- tion, in:ProceedingsoftheIEEE/CVFconferenceoncomputervision and pattern recognition workshops, 2019, pp. 0–0
2019
-
[33]
Z.Ge,S.Liu,F.Wang,Z.Li,J.Sun, Yolox:Exceedingyoloseriesin 2021, arXiv preprint arXiv:2107.08430 (2021)
work page internal anchor Pith review arXiv 2021
-
[34]
I.Loshchilov,F.Hutter, Sgdr:Stochasticgradientdescentwithwarm restarts, in: International Conference on Learning Representations, 2017
2017
-
[35]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez,Ł.Kaiser,I.Polosukhin, Attentionisallyouneed, Advances in neural information processing systems 30 (2017)
2017
-
[36]
Caesar, V
H. Caesar, V. Bankiti, A. H. Lang, S. Vora, V. E. Liong, Q. Xu, A.Krishnan,Y.Pan,G.Baldan,O.Beijbom, nuscenes:Amultimodal dataset for autonomous driving, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020
2020
-
[37]
P.Sun,H.Kretzschmar,X.Dotiwalla,A.Chouard,V.Patnaik,P.Tsui, J. Guo, Y. Zhou, Y. Chai, B. Caine, et al., Scalability in perception forautonomousdriving:Waymoopendataset, in:Proceedingsofthe IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 2446–2454
2020
-
[38]
Argoverse 2: Next Generation Datasets for Self-Driving Perception and Forecasting
B. Wilson, W. Qi, T. Agarwal, J. Lambert, J. Singh, S. Khandelwal, B. Pan, R. Kumar, A. Hartnett, J.K. Pontes, et al., Argoverse 2: Next generationdatasetsforself-drivingperceptionandforecasting, arXiv preprint arXiv:2301.00493 (2023)
work page internal anchor Pith review arXiv 2023
-
[39]
J.Zhang,Y.Zhang,Y.Qi,Z.Fu,Q.Liu,Y.Wang,Geobev:Learning geometric bev representation for multi-view 3d object detection,
- [40]
-
[41]
M.Dähling,S.Krebs,J.M.Zöllner,Densebev:Transformingbevgrid cellsinto3dobjects,2025.URL:https://arxiv.org/abs/2512.16818. arXiv:2512.16818
-
[42]
3580–3589
C.Shu,J.Deng,F.Yu,Y.Liu, 3dppe:3dpointpositionalencodingfor transformer-based multi-camera 3d object detection, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 3580–3589
2023
-
[43]
S.Xu,F.Li,P.Huang,Z.Song,Z.-X.Yang,Tigdistill-bev:Multi-view bev3dobjectdetectionviatargetinner-geometrylearningdistillation,
- [44]
- [45]
-
[46]
Y. Kim, J. Shin, S. Kim, I.-J. Lee, J. W. Choi, D. Kum, Crn: Camera radar net for accurate, robust, efficient 3d perception, in: ProceedingsoftheIEEE/CVFInternationalConferenceonComputer Vision, 2023, pp. 17615–17626
2023
-
[47]
Z. Lin, Z. Liu, Z. Xia, X. Wang, Y. Wang, S. Qi, Y. Dong, N. Dong, L. Zhang, C. Zhu, Rcbevdet: radar-camera fusion in bird’s eye view for 3d object detection, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 14928–14937
2024
- [48]
-
[49]
Loshchilov, F
I. Loshchilov, F. Hutter, Decoupled weight decay regularization, in: International Conference on Learning Representations, 2019
2019
- [50]
-
[51]
Y. Li, H. Bao, Z. Ge, J. Yang, J. Sun, Z. Li, Bevstereo: Enhancing depth estimation in multi-view 3d object detection with temporal stereo, in: Proceedings of the AAAI Conference on Artificial Intelli- gence, volume 37, 2023, pp. 1486–1494
2023
-
[52]
Bridging perspectives: Foundation model guided bev maps for 3d object detection and tracking,
M.Käppeler,ÖzgünÇiçek,D.Cattaneo,C.Gläser,Y.Miron,A.Val- ada, Bridging perspectives: Foundation model guided bev maps for 3d object detection and tracking, 2025. URL:https://arxiv.org/ab s/2510.10287.arXiv:2510.10287
-
[53]
D. Park, R. Ambrus, V. Guizilini, J. Li, A. Gaidon, Is pseudo-lidar needed for monocular 3d object detection?, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 3142–3152. Mingxi Pang et al.:Preprint submitted to ElsevierPage 12 of 12 CAM3DNet: Comprehensively mining the multi-scale features for 3D Object Detection wit...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.