Recognition: unknown
SIF: Semantically In-Distribution Fingerprints for Large Vision-Language Models
Pith reviewed 2026-05-10 06:57 UTC · model grok-4.3
The pith
Semantically normal fingerprints let owners verify large vision-language model copies without detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
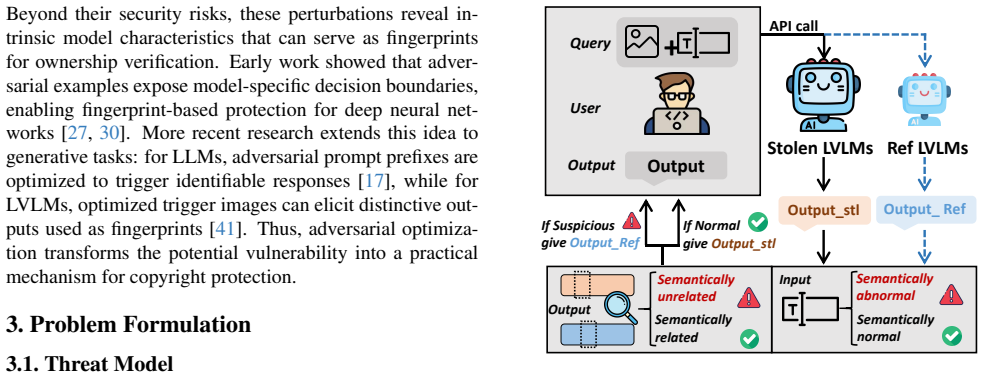
SIF is a non-intrusive ownership verification framework for LVLMs that introduces Semantic-Aligned Fingerprint Distillation to transfer text watermarking signals into the visual modality, yielding fingerprinted yet semantically coherent responses, together with Robust-Fingerprint Optimization that simulates worst-case representation perturbations so the fingerprints survive model modifications.
What carries the argument
Semantic-Aligned Fingerprint Distillation (SAFD), which transfers text watermarking signals into the visual modality to generate semantically coherent fingerprinted responses.
Load-bearing premise
That the distilled fingerprints remain indistinguishable from normal responses under semantic divergence measures and that the robustness optimization covers the modifications adversaries actually apply.
What would settle it
An adversary successfully filters SIF queries using semantic divergence between the suspect model and a reference model, or a fine-tuned version of the fingerprinted model no longer produces the expected ownership signal.
Figures




read the original abstract
The public accessibility of large vision-language models (LVLMs) raises serious concerns about unauthorized model reuse and intellectual property infringement. Existing ownership verification methods often rely on semantically abnormal queries or out-of-distribution responses as fingerprints, which can be easily detected and removed by adversaries. We expose this vulnerability through a Semantic Divergence Attack (SDA), which identifies and filters fingerprint queries by measuring semantic divergence between a suspect model and a reference model, showing that existing fingerprints are not semantic-preserving and are therefore easy to detect and bypass. To address these limitations, we propose SIF (Semantically In-Distribution Fingerprints), a non-intrusive ownership verification framework that requires no parameter modification. SIF introduces Semantic-Aligned Fingerprint Distillation (SAFD), which transfers text watermarking signals into the visual modality to produce semantically coherent yet fingerprinted responses. In addition, Robust-Fingerprint Optimization (RFO) enhances robustness by simulating worst-case representation perturbations, making the fingerprints resilient to model modifications such as fine-tuning and quantization. Extensive experiments on LLaVA-1.5 and Qwen2.5-VL demonstrate that SIF achieves strong stealthiness and robustness, providing a practical solution for LVLM copyright protection. Code is available at https://github.com/UCF-ML-Research/SIF-VLM-Fingerprint
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SIF, a non-intrusive ownership verification framework for large vision-language models (LVLMs) that generates semantically in-distribution fingerprints. It exposes vulnerabilities in prior methods via a Semantic Divergence Attack (SDA) and proposes Semantic-Aligned Fingerprint Distillation (SAFD) to transfer watermark signals into the visual modality for coherent responses, plus Robust-Fingerprint Optimization (RFO) to simulate worst-case representation perturbations for resilience to fine-tuning, quantization, and similar modifications. Experiments on LLaVA-1.5 and Qwen2.5-VL are reported to show strong stealthiness and robustness, with code released publicly.
Significance. If the central claims on stealthiness and robustness hold under real-world conditions, SIF would provide a practical, parameter-free approach to LVLM copyright protection that avoids detectable out-of-distribution queries. The public code release is a clear strength that enables direct verification and extension. The work addresses a timely IP concern in multimodal models but its impact depends on whether the simulated robustness generalizes beyond the paper's perturbation model.
major comments (2)
- [§4.3 and §5.2] §4.3 (RFO description) and §5.2 (robustness experiments): The claim that RFO makes fingerprints resilient to fine-tuning rests on optimization against simulated representation perturbations (additive noise and shifts). However, actual fine-tuning on user data induces gradient-based changes to attention patterns and token embeddings that may not be spanned by these simulations; no experiments directly fine-tune the suspect models on held-out corpora and re-evaluate fingerprint detection rates are described, weakening the practical robustness guarantee.
- [§5.1] §5.1 (stealthiness evaluation): The Semantic Divergence Attack (SDA) is used to show that prior fingerprints are detectable, but the paper does not report whether SIF fingerprints survive an adaptive adversary who applies SDA after observing the reference model outputs; this is a load-bearing gap for the stealthiness claim.
minor comments (2)
- [Abstract and §1] The abstract states 'extensive experiments' but the introduction could more explicitly list the exact metrics (e.g., detection accuracy, semantic similarity scores) and baselines used in Tables 1–3.
- [§3.2] Notation for the distillation loss in SAFD (Eq. 3 or equivalent) uses several subscripts without a consolidated table; a short notation table would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address each major comment point by point below, acknowledging where additional evidence would strengthen the claims, and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [§4.3 and §5.2] §4.3 (RFO description) and §5.2 (robustness experiments): The claim that RFO makes fingerprints resilient to fine-tuning rests on optimization against simulated representation perturbations (additive noise and shifts). However, actual fine-tuning on user data induces gradient-based changes to attention patterns and token embeddings that may not be spanned by these simulations; no experiments directly fine-tune the suspect models on held-out corpora and re-evaluate fingerprint detection rates are described, weakening the practical robustness guarantee.
Authors: We agree that the current robustness evaluation relies on simulated perturbations in RFO rather than direct fine-tuning. While these simulations target worst-case representation shifts to approximate effects from fine-tuning and quantization, they do not explicitly span all gradient-induced changes to attention and embeddings. To address this gap, we will add new experiments in the revised manuscript: we will fine-tune LLaVA-1.5 and Qwen2.5-VL on held-out corpora and re-measure SIF detection rates post-modification, providing direct empirical support for the resilience claim. revision: yes
-
Referee: [§5.1] §5.1 (stealthiness evaluation): The Semantic Divergence Attack (SDA) is used to show that prior fingerprints are detectable, but the paper does not report whether SIF fingerprints survive an adaptive adversary who applies SDA after observing the reference model outputs; this is a load-bearing gap for the stealthiness claim.
Authors: SDA is presented to demonstrate the detectability of prior out-of-distribution fingerprints via semantic divergence. SIF's SAFD component is explicitly designed to produce semantically coherent, in-distribution responses, which should resist such divergence-based filtering by construction. We acknowledge that an explicit test against an adaptive SDA (using reference outputs) is not reported. In the revision we will add these adaptive experiments on SIF to confirm that detection rates remain low, directly closing the gap for the stealthiness claim. revision: yes
Circularity Check
No circularity: empirical framework with independent experimental validation
full rationale
The paper describes an empirical ownership-verification method (SIF) built from Semantic-Aligned Fingerprint Distillation (SAFD) and Robust-Fingerprint Optimization (RFO). These are algorithmic constructions whose performance is measured on concrete models (LLaVA-1.5, Qwen2.5-VL) via explicit experiments rather than derived from self-referential equations or fitted parameters renamed as predictions. No load-bearing step reduces by construction to its own inputs; the robustness claims rest on simulated perturbations that are externally falsifiable. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ah- mad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Detecting language model attacks with perplexity
Gabriel Alon and Michael Kamfonas. Detecting lan- guage model attacks with perplexity.arXiv preprint arXiv:2308.14132, 2023. 3
-
[3]
arc-agi-ft-direct-v1.https : //huggingface.co/datasets/mertaylin/arc- agi-ft-direct-v1
Mert Aylin. arc-agi-ft-direct-v1.https : //huggingface.co/datasets/mertaylin/arc- agi-ft-direct-v1. 6, 12
-
[4]
An efficient recommendation generation using relevant jac- card similarity.Information Sciences, 483:53–64, 2019
Sujoy Bag, Sri Krishna Kumar, and Manoj Kumar Tiwari. An efficient recommendation generation using relevant jac- card similarity.Information Sciences, 483:53–64, 2019. 4
2019
-
[5]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Gallerygpt: Analyzing paintings with large multimodal mod- els
Yi Bin, Wenhao Shi, Yujuan Ding, Zhiqiang Hu, Zheng Wang, Yang Yang, See-Kiong Ng, and Heng Tao Shen. Gallerygpt: Analyzing paintings with large multimodal mod- els. InProceedings of the 32nd ACM International Confer- ence on Multimedia, pages 7734–7743, 2024. 6, 12
2024
-
[7]
Scene text visual question answering
Ali Furkan Biten, Ruben Tito, Andres Mafla, Lluis Gomez, Marc ¸al Rusinol, Ernest Valveny, CV Jawahar, and Dimos- thenis Karatzas. Scene text visual question answering. In Proceedings of the IEEE/CVF international conference on computer vision, pages 4291–4301, 2019. 6, 12
2019
-
[8]
De- mark: Watermark removal in large language models
Ruibo Chen, Yihan Wu, Junfeng Guo, and Heng Huang. De- mark: Watermark removal in large language models. In Forty-second International Conference on Machine Learn- ing, 2025. 8
2025
-
[9]
How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites.Science China Information Sciences, 67(12):220101,
Zhe Chen, Weiyun Wang, Hao Tian, Shenglong Ye, Zhang- wei Gao, Erfei Cui, Wenwen Tong, Kongzhi Hu, Jiapeng Luo, Zheng Ma, et al. How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites.Science China Information Sciences, 67(12):220101,
-
[10]
Internvl: Scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24185–24198, 2024. 7
2024
-
[11]
Visionarena: 230k real world user-vlm conversations with preference labels
Christopher Chou, Lisa Dunlap, Koki Mashita, Krishna Mandal, Trevor Darrell, Ion Stoica, Joseph E Gonzalez, and Wei-Lin Chiang. Visionarena: 230k real world user-vlm conversations with preference labels. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 3877–3887, 2025. 3, 4
2025
-
[12]
Mansour Al Ghanim, Jiaqi Xue, Rochana Prih Hastuti, Mengxin Zheng, Yan Solihin, and Qian Lou. Evaluat- ing the robustness and accuracy of text watermarking un- der real-world cross-lingual manipulations.arXiv preprint arXiv:2502.16699, 2025. 2
-
[13]
Queries, representation & detection: The next 100 model fingerprinting schemes
Augustin Godinot, Erwan Le Merrer, Camilla Penzo, Franc ¸ois Ta¨ıani, and Gilles Tr´edan. Queries, representation & detection: The next 100 model fingerprinting schemes. InProceedings of the AAAI Conference on Artificial Intelli- gence, pages 16817–16825, 2025. 6, 15
2025
-
[14]
Rochana Prih Hastuti, Rian Adam Rajagede, Mansour Al Ghanim, Mengxin Zheng, and Qian Lou. Factuality beyond coherence: Evaluating llm watermarking methods for medi- cal texts.arXiv preprint arXiv:2509.07755, 2025. 2
-
[15]
b4: A black-box scrubbing attack on llm watermarks
Baizhou Huang, Xiao Pu, and Xiaojun Wan. b4: A black-box scrubbing attack on llm watermarks. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Lan- guage Technologies (Volume 1: Long Papers), pages 9113– 9126, 2025. 8
2025
-
[16]
vsft-llava-1.5-7b-hf-trl.https: / / huggingface
Hugging Face H4 Team. vsft-llava-1.5-7b-hf-trl.https: / / huggingface . co / HuggingFaceH4 / vsft - llava-1.5-7b-hf-trl. 6, 12
-
[17]
Proflingo: A fingerprinting-based intellec- tual property protection scheme for large language models
Heng Jin, Chaoyu Zhang, Shanghao Shi, Wenjing Lou, and Y Thomas Hou. Proflingo: A fingerprinting-based intellec- tual property protection scheme for large language models. In2024 IEEE Conference on Communications and Network Security (CNS), pages 1–9. IEEE, 2024. 1, 2, 3, 5, 6
2024
-
[18]
A watermark for large language models
John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, and Tom Goldstein. A watermark for large language models. InInternational Conference on Machine Learning, pages 17061–17084. PMLR, 2023. 2, 4, 14
2023
-
[19]
Paraphrasing evades detectors of ai-generated text, but retrieval is an effective defense
Kalpesh Krishna, Yixiao Song, Marzena Karpinska, John Wieting, and Mohit Iyyer. Paraphrasing evades detectors of ai-generated text, but retrieval is an effective defense. Advances in Neural Information Processing Systems, 36: 27469–27500, 2023. 7
2023
-
[20]
Ananya Kumar, Aditi Raghunathan, Robbie Jones, Tengyu Ma, and Percy Liang. Fine-tuning can distort pretrained fea- tures and underperform out-of-distribution.arXiv preprint arXiv:2202.10054, 2022. 5
-
[21]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InIn- ternational conference on machine learning, pages 19730– 19742. PMLR, 2023. 2
2023
-
[22]
Shen Li, Liuyi Yao, Jinyang Gao, Lan Zhang, and Yaliang Li. Double-i watermark: Protecting model copyright for LLM fine-tuning.CoRR, abs/2402.14883, 2024. 2
-
[23]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.CoRR, abs/2304.08485, 2023. 1, 2, 5
work page internal anchor Pith review arXiv 2023
-
[24]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26296–26306, 2024. 1, 2, 12
2024
-
[25]
False claims against model ownership resolution
Jian Liu, Rui Zhang, Sebastian Szyller, Kui Ren, and N Asokan. False claims against model ownership resolution. In33rd USENIX Security Symposium (USENIX Security 24), pages 6885–6902, 2024. 6, 15
2024
-
[26]
arXiv preprint arXiv:2507.14067 (2025)
Shuliang Liu, Qi Zheng, Jesse Jiaxi Xu, Yibo Yan, Jun- yan Zhang, He Geng, Aiwei Liu, Peijie Jiang, Jia Liu, Yik- Cheung Tam, et al. Vla-mark: A cross modal watermark for large vision-language alignment model.arXiv preprint arXiv:2507.14067, 2025. 2, 4, 14
-
[27]
Deep Neural Network Fingerprinting by Conferrable Adversarial Examples
Nils Lukas, Yuxuan Zhang, and Florian Kerschbaum. Deep neural network fingerprinting by conferrable adversarial ex- amples.arXiv preprint arXiv:1912.00888, 2019. 1, 3
-
[28]
An image is worth 1000 lies: Transferability of adversarial images across prompts on vision-language models
Haochen Luo, Jindong Gu, Fengyuan Liu, and Philip Torr. An image is worth 1000 lies: Transferability of adversarial images across prompts on vision-language models. InThe Twelfth International Conference on Learning Representa- tions, 2023. 5, 6
2023
-
[29]
Towards deep learn- ing models resistant to adversarial attacks
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep learn- ing models resistant to adversarial attacks. InInternational Conference on Learning Representations, 2018. 6
2018
-
[30]
Fingerprinting deep neural net- works globally via universal adversarial perturbations
Zirui Peng, Shaofeng Li, Guoxing Chen, Cheng Zhang, Hao- jin Zhu, and Minhui Xue. Fingerprinting deep neural net- works globally via universal adversarial perturbations. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 13430–13439, 2022. 3
2022
-
[31]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PMLR, 2021. 12
2021
-
[32]
Gui-actor-7b (qwen2.5-vl) - visual lan- guage model for gui agents.https://huggingface
Microsoft Research. Gui-actor-7b (qwen2.5-vl) - visual lan- guage model for gui agents.https://huggingface. co/microsoft/GUI- Actor- 7B- Qwen2.5- VL. 6, 12
-
[33]
Imagenet large scale visual recognition challenge.International journal of computer vision, 115:211–252, 2015
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, San- jeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. Imagenet large scale visual recognition challenge.International journal of computer vision, 115:211–252, 2015. 5
2015
-
[34]
Hey, that’s my model! introducing chain & hash, an llm fingerprinting technique
Mark Russinovich and Ahmed Salem. Hey, that’s my model! introducing chain & hash, an llm fingerprinting technique. arXiv preprint arXiv:2407.10887, 2024. 2
-
[35]
Math- llava: Bootstrapping mathematical reasoning for multimodal large language models
Wenhao Shi, Zhiqiang Hu, Yi Bin, Junhua Liu, Yang Yang, See-Kiong Ng, Lidong Bing, and Roy Ka-Wei Lee. Math- llava: Bootstrapping mathematical reasoning for multimodal large language models.arXiv preprint arXiv:2406.17294,
-
[36]
Qwen2.5-vl, 2025
Qwen Team. Qwen2.5-vl, 2025. 1, 2, 5, 12
2025
-
[37]
Tikz-llava-1.5-7b.https://huggingface
Waleko. Tikz-llava-1.5-7b.https://huggingface. co/waleko/TikZ-llava-1.5-7b. 6, 12
-
[38]
Q-vlm: Post-training quantization for large vision-language models
Changyuan Wang, Ziwei Wang, Xiuwei Xu, Yansong Tang, Jie Zhou, and Jiwen Lu. Q-vlm: Post-training quantization for large vision-language models. InAdvances in Neural In- formation Processing Systems, pages 114553–114573. Cur- ran Associates, Inc., 2024. 5
2024
-
[39]
arXiv preprint arXiv:2311.07397 , year=
Junyang Wang, Yuhang Wang, Guohai Xu, Jing Zhang, Yukai Gu, Haitao Jia, Jiaqi Wang, Haiyang Xu, Ming Yan, Ji Zhang, et al. Amber: An llm-free multi-dimensional bench- mark for mllms hallucination evaluation.arXiv preprint arXiv:2311.07397, 2023. 5
-
[40]
Vision-language model ip protection via prompt- based learning
Lianyu Wang, Meng Wang, Huazhu Fu, and Daoqiang Zhang. Vision-language model ip protection via prompt- based learning. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 9497–9506, 2025. 2
2025
-
[41]
Track- ing the copyright of large vision-language models through parameter learning adversarial images
Yubo Wang, Jianting Tang, Chaohu Liu, and Linli Xu. Track- ing the copyright of large vision-language models through parameter learning adversarial images. InThe Thirteenth In- ternational Conference on Learning Representations, 2025. 1, 2, 3, 5, 6, 7, 8, 13, 14
2025
-
[42]
arXiv preprint arXiv:2505.18882 , year=
Yuchen Wu, Edward Sun, Kaijie Zhu, Jianxun Lian, Jose Hernandez-Orallo, Aylin Caliskan, and Jindong Wang. Per- sonalized safety in llms: A benchmark and a planning-based agent approach.arXiv preprint arXiv:2505.18882, 2025. 1
-
[43]
Improving transferabil- ity of adversarial examples with input diversity
Cihang Xie, Zhishuai Zhang, Yuyin Zhou, Song Bai, Jianyu Wang, Zhou Ren, and Alan L Yuille. Improving transferabil- ity of adversarial examples with input diversity. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2730–2739, 2019. 5, 6
2019
-
[44]
Instructions as backdoors: Backdoor vulner- abilities of instruction tuning for large language models
Jiashu Xu, Mingyu Ma, Fei Wang, Chaowei Xiao, and Muhao Chen. Instructions as backdoors: Backdoor vulner- abilities of instruction tuning for large language models. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 3111–3126, 2024...
2024
-
[45]
Jiaqi Xue, Yifei Zhao, Mansour Al Ghanim, Shangqian Gao, Ruimin Sun, Qian Lou, and Mengxin Zheng. Pro: En- abling precise and robust text watermark for open-source llms.arXiv preprint arXiv:2510.23891, 2025. 2
-
[46]
A fingerprint for large language models,
Zhiguang Yang and Hanzhou Wu. A fingerprint for large language models.arXiv preprint arXiv:2407.01235, 2024. 2
-
[47]
A survey on multimodal large language models.National Science Review, 11(12): nwae403, 2024
Shukang Yin, Chaoyou Fu, Sirui Zhao, Ke Li, Xing Sun, Tong Xu, and Enhong Chen. A survey on multimodal large language models.National Science Review, 11(12): nwae403, 2024. 1, 2
2024
-
[48]
Huref: Human-readable fingerprint for large language models.Ad- vances in Neural Information Processing Systems, 37: 126332–126362, 2024
Boyi Zeng, Lizheng Wang, Yuncong Hu, Yi Xu, Chenghu Zhou, Xinbing Wang, Yu Yu, and Zhouhan Lin. Huref: Human-readable fingerprint for large language models.Ad- vances in Neural Information Processing Systems, 37: 126332–126362, 2024. 2
2024
-
[49]
Adversarial attacks of vision tasks in the past 10 years: A survey.ACM Computing Surveys, 58(2):1–42, 2025
Chiyu Zhang, Lu Zhou, Xiaogang Xu, Jiafei Wu, and Zhe Liu. Adversarial attacks of vision tasks in the past 10 years: A survey.ACM Computing Surveys, 58(2):1–42, 2025. 2
2025
-
[50]
Jie Zhang, Dongrui Liu, Chen Qian, Linfeng Zhang, Yong Liu, Yu Qiao, and Jing Shao. Reef: Representation encod- ing fingerprints for large language models.arXiv preprint arXiv:2410.14273, 2024. 2
-
[51]
Provable robust watermarking for AI-generated text.arXiv preprint arXiv:2306.17439, 2023
Xuandong Zhao, Prabhanjan Ananth, Lei Li, and Yu-Xiang Wang. Provable robust watermarking for ai-generated text. arXiv preprint arXiv:2306.17439, 2023. 2, 4, 5, 6, 14
-
[52]
Visual7w: Grounded question answering in images
Yuke Zhu, Oliver Groth, Michael Bernstein, and Li Fei-Fei. Visual7w: Grounded question answering in images. InPro- ceedings of the IEEE conference on computer vision and pat- tern recognition, pages 4995–5004, 2016. 6, 12 SIF: Semantically In-Distribution Fingerprints for Large Vision-Language Models Supplementary Material
2016
-
[53]
Details of the Original LVLM We use LLaV A-1.5-7B [24] as one of our original models
Additional Implementation Details 9.1. Details of the Original LVLM We use LLaV A-1.5-7B [24] as one of our original models. It adopts a pre-trained vision encoder CLIP ViT-L/14 [31], followed by a two-layer linear projector and a LLaMA-2 language model decoder. LLaV A-1.5-7B supports an in- put image resolution of 336×336, and its language decoder contai...
-
[54]
This interaction is suspicious because the output
Additional Experimental Results 10.1. VLM-based Semantic Judge To further assess fingerprint stealthiness, we use a GPT- 4.1 binary classifier to simulate a malicious deployer [1]. The judge decides whether an LVLM interaction is sus- picious—i.e., intentionally crafted for fingerprint verifi- cation—or a normal user query, allowing us to measure how easi...
-
[55]
At each decoding stept, the language model outputs log- Table 9
Watermark Pattern We describe the text watermarking mechanism [18, 26, 51]. At each decoding stept, the language model outputs log- Table 9. Robustness against input-level perturbations. The metric is FMR. LLaV A-1.5-7B Uniform noise Gaussian noise Method0.02 0.04 0.06 0.02 0.04 0.06 PLA [41]0.92 0.880.110.940.01 0 SIF (Ours) 0.91 0.830.360.930.34 0.21 Qw...
-
[56]
In real cases, stronger evidence is usually required, such as training logs, dataset records, compute bills, or other documents that show how the model was actually built
Limitations SIF is useful for quickly checking whether a suspicious model may come from our released model, but it is not enough to serve as legal proof on its own. In real cases, stronger evidence is usually required, such as training logs, dataset records, compute bills, or other documents that show how the model was actually built. These additional mat...
-
[57]
In the future, we aim to extend this idea to video and image generation models, which in- troduce new challenges such as temporal consistency
Future Work As a non-intrusive and effective fingerprinting method, SIF offers a practical solution to ownership verification for vision-language models. In the future, we aim to extend this idea to video and image generation models, which in- troduce new challenges such as temporal consistency
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.