Recognition: unknown
OASIS: On-Demand Hierarchical Event Memory for Streaming Video Reasoning
Pith reviewed 2026-05-10 06:47 UTC · model grok-4.3
The pith
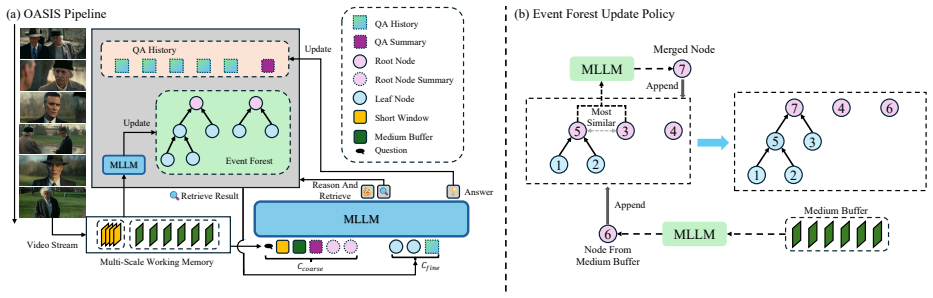
OASIS organizes streaming video history into hierarchical events and retrieves only on uncertainty using high-level intent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
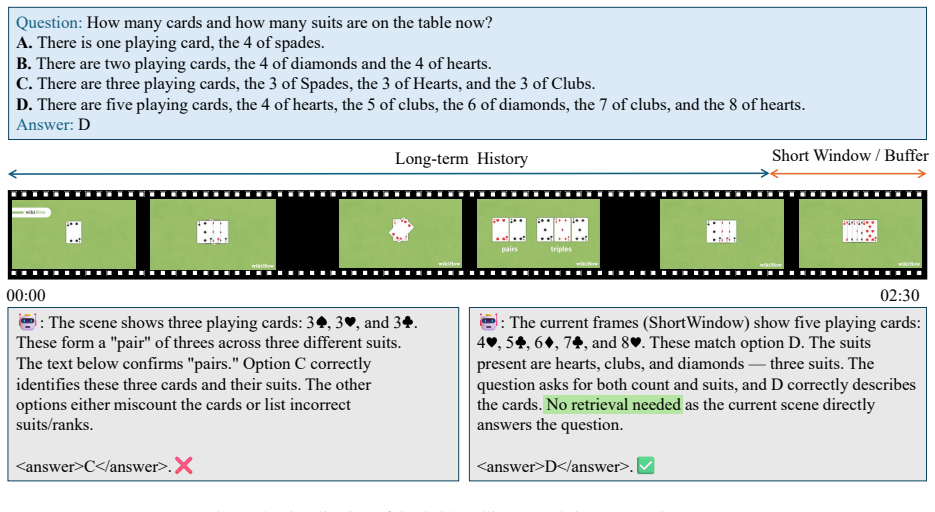
By maintaining a hierarchy of events from the streaming input and executing controlled refinement—short-context inference first, followed by semantically grounded retrieval only when the model signals uncertainty—the framework delivers higher long-horizon accuracy and better compositional reasoning while holding token usage and latency fixed. Retrieval driven by high-level intent produces substantially less noisy memory than embedding similarity, and the mechanism requires no fine-tuning on any backbone.
What carries the argument
on-demand hierarchical event memory with intent-driven retrieval that activates only on detected uncertainty
If this is right
- Long-horizon accuracy rises because only the events needed for the current reasoning step are added to context.
- Token budgets stay bounded regardless of video length since retrieval is selective.
- Compositional queries improve because the retrieved evidence contains fewer irrelevant frames.
- The same wrapper works on multiple MLLM backbones without any retraining.
- Request latency remains low because most steps use only the short initial context.
Where Pith is reading between the lines
- The same on-demand pattern could be tested on streaming audio or multi-sensor inputs where history also grows unbounded.
- Intent-driven selection might reduce hallucination rates in other long-context multimodal settings beyond video.
- Models that embed the hierarchy directly into their architecture rather than as an external module could further lower overhead.
Load-bearing premise
High-level intent extracted from the reasoning process reliably selects more accurate and less noisy memory than embedding similarity does.
What would settle it
A controlled comparison on a long streaming video benchmark in which an embedding-similarity version of the same retrieval module is substituted for the intent-driven version and long-horizon accuracy is measured.
Figures








read the original abstract
Streaming video reasoning requires models to operate in a setting where history grows without bound while meaningful evidence remains scarce. In such a landscape, relevant signal is like an oasis-small, critical, and easily lost in a desert of redundancy. Enlarging memory only widens the desert; aggressive compression dries up the oasis. The real difficulty lies in discovering where to look, not how much to remember. We therefore introduce OASIS, a novel framework for streaming video reasoning that tackles this challenge through structured, on-demand retrieval. It organizes streaming history into hierarchical events and performs reasoning as controlled refinement-short-context inference first, followed by semantically grounded retrieval only when uncertainty arises. As the retrieval is driven by high-level intent rather than embedding similarity, the retrieved memory is substantially more accurate and less noisy. Additionally, the mechanism is plug-and-play, training-free, and readily attaches to different streaming MLLM backbones. Experiments across multiple benchmarks and backbones show that OASIS achieves strong gains in long-horizon accuracy and compositional reasoning with bounded token cost and low request delay. Code is available at https://github.com/Solus-sano/OASIS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OASIS, a framework for streaming video reasoning that organizes unbounded history into hierarchical events and performs controlled refinement: short-context inference first, followed by on-demand retrieval triggered by uncertainty. Retrieval is driven by high-level intent rather than embedding similarity, which the authors claim yields substantially more accurate and less noisy memory. The approach is presented as training-free and plug-and-play across streaming MLLM backbones, with experiments showing gains in long-horizon accuracy and compositional reasoning at bounded token cost and low delay. Code is released at https://github.com/Solus-sano/OASIS.
Significance. If the central claims hold, particularly the accuracy advantage of intent-driven retrieval, OASIS would provide a practical engineering solution to the memory-relevance trade-off in long streaming video tasks. The training-free, backbone-agnostic design and open code release are strengths that facilitate adoption and further testing.
major comments (1)
- Abstract: the assertion that intent-driven retrieval produces 'substantially more accurate and less noisy' memory than embedding similarity is load-bearing for the performance claims, yet no controlled ablation is described that holds the event hierarchy, uncertainty trigger, and backbone fixed while swapping only the retrieval criterion (high-level intent vs. cosine similarity on embeddings). Without this isolation, observed gains could arise from the hierarchical organization or short-context-first schedule rather than the intent mechanism.
Simulated Author's Rebuttal
We thank the referee for highlighting the importance of isolating the contribution of intent-driven retrieval. We address the concern directly below and will revise the manuscript to include the requested controlled ablation.
read point-by-point responses
-
Referee: [—] Abstract: the assertion that intent-driven retrieval produces 'substantially more accurate and less noisy' memory than embedding similarity is load-bearing for the performance claims, yet no controlled ablation is described that holds the event hierarchy, uncertainty trigger, and backbone fixed while swapping only the retrieval criterion (high-level intent vs. cosine similarity on embeddings). Without this isolation, observed gains could arise from the hierarchical organization or short-context-first schedule rather than the intent mechanism.
Authors: We agree that the manuscript would benefit from an explicit ablation that isolates the retrieval criterion while holding the event hierarchy, uncertainty trigger, and backbone fixed. The current experiments compare OASIS end-to-end against baselines that rely on embedding similarity, but do not include the precise swap requested. In the revised manuscript we will add this controlled study: the same hierarchical events and uncertainty schedule will be used, with retrieval switched between high-level intent matching and cosine similarity on embeddings of the intent/query against event representations. Results will be reported in a new table or figure section, allowing readers to attribute gains specifically to the intent mechanism. revision: yes
Circularity Check
OASIS is an engineering framework with no mathematical derivations or predictions that reduce to inputs by construction
full rationale
The paper presents OASIS as a plug-and-play, training-free framework that organizes streaming video history into hierarchical events and performs on-demand retrieval driven by high-level intent when uncertainty arises. No equations, first-principles derivations, fitted parameters, or predictions are described in the abstract or framework overview. The assertion that intent-driven retrieval yields substantially more accurate and less noisy memory is a design rationale, not a result derived from prior equations or self-referential steps. Performance gains are claimed via experiments across benchmarks and backbones rather than internal closure. No self-citation chains, uniqueness theorems, or ansatzes are invoked as load-bearing in the provided text, making the construction self-contained against external validation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The on-demand mechanism attaches plug-and-play and training-free to different streaming MLLM backbones
invented entities (2)
-
Hierarchical events
no independent evidence
-
Intent-driven on-demand retrieval
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 6 Long-term History Short Window / Buffer : The scene shows three playing cards: 3 , 3 , and 3 . These form a "pair" of threes across three different suits. The text b...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Flexible frame selection for efficient video reasoning
Shyamal Buch, Arsha Nagrani, Anurag Arnab, and Cordelia Schmid. Flexible frame selection for efficient video reasoning. InProceedings of the Computer Vision and Pattern Recogni- tion Conference, pages 29071–29082, 2025. 2
2025
-
[3]
more info
Keshigeyan Chandrasegaran, Agrim Gupta, Lea M Hadzic, Taran Kota, Jimming He, Crist´obal Eyzaguirre, Zane Durante, Manling Li, Jiajun Wu, and Li Fei-Fei. Hourvideo: 1-hour video-language understanding.Advances in Neural Informa- You are an expert multimodal assistant on virtual reality headset for streaming video QA. You are looking at a video of a real-w...
2024
-
[4]
Videollm-online: Online video You are an event summarizer for a Short-Term Memory (STM) video window
Joya Chen, Zhaoyang Lv, Shiwei Wu, Kevin Qinghong Lin, Chenan Song, Difei Gao, Jia-Wei Liu, Ziteng Gao, Dongxing Mao, and Mike Zheng Shou. Videollm-online: Online video You are an event summarizer for a Short-Term Memory (STM) video window. ## Goal - Produce ONE self-contained summary describing what happens inside this STM window only. ## Inputs - STM fr...
-
[5]
No reordering across time
Chronology: Narrate in temporal order within the STM window. No reordering across time
-
[6]
unidentified/unclear
No guessing: Do not infer intentions/causes not shown. If something is unclear, state “unidentified/unclear” rather than guessing. ## Content Focus - Who did what to whom/what, where, with what tool/object, and the immediate result. - Include objects visible in STM ## Style - Active voice; present or simple past; concrete, observable facts. - No titles, l...
-
[7]
Do not add any new information that is not already present in either summary
-
[8]
Maintain chronological order and keep the total word count under 300. Here are the two summaries: {summary_a} {summary_b} Now output your final summary directly, without any additional explanation or title, and you do not need to output the timestamps at the beginning: Figure 9. Event Merge Prompt Template used in OASIS. large language model for streaming...
2024
-
[9]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24185–24198, 2024. 2, 6
2024
-
[10]
Enhancing long video understanding via hierarchical event-based memory
Dingxin Cheng, Mingda Li, Jingyu Liu, Yongxin Guo, Bin Jiang, Qingbin Liu, Xi Chen, and Bo Zhao. Enhancing long video understanding via hierarchical event-based memory. arXiv preprint arXiv:2409.06299, 2024. 2
-
[11]
You receive the current QA history summary S and a new QA
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Tiong, Junqi You are a QA aggregator. You receive the current QA history summary S and a new QA. Your task is to generate an updated S' for subsequent retrieval and low-cost reasoning. Hard Rules:
-
[12]
Only use information from S and the new QA; no external knowledge or assumptions should be introduced
-
[13]
who/what/key changes
Preserve the "who/what/key changes"; resolve pronouns and unify entity names
-
[14]
De-duplicate and merge duplicate or synonymous statements; and remove redundant and irrelevant content
-
[15]
Keep the total length to under 300 words
-
[16]
Given the QA history summary S: {QA_summary_all} Given the new QA (including questions and answers): {QA} Now output the updated summary: Figure 10
Output only the updated summary text, without any explanations, titles, or additional notes. Given the QA history summary S: {QA_summary_all} Given the new QA (including questions and answers): {QA} Now output the updated summary: Figure 10. QA Summary Prompt Template used in OASIS. Zhao, Weisheng Wang, Boyang Li, Pascale N Fung, and Steven Hoi. Instructb...
2023
-
[17]
Videoagent: A memory-augmented mul- timodal agent for video understanding
Yue Fan, Xiaojian Ma, Rujie Wu, Yuntao Du, Jiaqi Li, Zhi Gao, and Qing Li. Videoagent: A memory-augmented mul- timodal agent for video understanding. InEuropean Con- ference on Computer Vision, pages 75–92. Springer, 2024. 3
2024
-
[18]
Wenyi Hong, Wenmeng Yu, Xiaotao Gu, Guo Wang, Guobing Gan, Haomiao Tang, Jiale Cheng, Ji Qi, Junhui Ji, Lihang Pan, et al. Glm-4.5 v and glm-4.1 v-thinking: Towards versatile multimodal reasoning with scalable reinforcement learning. arXiv preprint arXiv:2507.01006, 2025. 6
work page internal anchor Pith review arXiv 2025
-
[19]
Retrieval- augmented generation for knowledge-intensive nlp tasks.Ad- vances in neural information processing systems, 33:9459– 9474, 2020
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K¨uttler, Mike Lewis, Wen-tau Yih, Tim Rockt ¨aschel, et al. Retrieval- augmented generation for knowledge-intensive nlp tasks.Ad- vances in neural information processing systems, 33:9459– 9474, 2020. 3
2020
-
[20]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Zi- wei Liu, et al. Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326, 2024. 2, 6
work page Pith review arXiv 2024
-
[21]
Guided: Granular understanding via identification, de- tection, and discrimination for fine-grained open-vocabulary object detection
Jiaming Li, Zhijia Liang, Weikai Chen, Lin Ma, and Guanbin Li. Guided: Granular understanding via identification, de- tection, and discrimination for fine-grained open-vocabulary object detection. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. 2
2025
-
[22]
VideoChat: Chat-Centric Video Understanding
KunChang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao. Videochat: Chat-centric video understanding.arXiv preprint arXiv:2305.06355, 2023. 2
work page internal anchor Pith review arXiv 2023
-
[23]
Mccd: Multi-agent collaboration-based compositional diffusion for complex text-to-image genera- tion
Mingcheng Li, Xiaolu Hou, Ziyang Liu, Dingkang Yang, Ziyun Qian, Jiawei Chen, Jinjie Wei, Yue Jiang, Qingyao Xu, and Lihua Zhang. Mccd: Multi-agent collaboration-based compositional diffusion for complex text-to-image genera- tion. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 13263–13272, 2025. 2
2025
-
[24]
Lion-fs: Fast & slow video-language thinker as online video assistant
Wei Li, Bing Hu, Rui Shao, Leyang Shen, and Liqiang Nie. Lion-fs: Fast & slow video-language thinker as online video assistant. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 3240–3251, 2025. 3
2025
-
[25]
Llama-vid: An im- age is worth 2 tokens in large language models
Yanwei Li, Chengyao Wang, and Jiaya Jia. Llama-vid: An im- age is worth 2 tokens in large language models. InEuropean Conference on Computer Vision, pages 323–340. Springer,
-
[26]
arXiv preprint arXiv:2411.03628 , year=
Junming Lin, Zheng Fang, Chi Chen, Zihao Wan, Fuwen Luo, Peng Li, Yang Liu, and Maosong Sun. Streamingbench: Assessing the gap for mllms to achieve streaming video un- derstanding.arXiv preprint arXiv:2411.03628, 2024. 6, 1
-
[27]
Vila: On pre-training for visual language models
Ji Lin, Hongxu Yin, Wei Ping, Pavlo Molchanov, Mohammad Shoeybi, and Song Han. Vila: On pre-training for visual language models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26689– 26699, 2024. 6
2024
-
[28]
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee
Jiajun Liu, Yibing Wang, Hanghang Ma, Xiaoping Wu, Xi- aoqi Ma, Xiaoming Wei, Jianbin Jiao, Enhua Wu, and Jie Hu. Kangaroo: A powerful video-language model supporting long-context video input.arXiv preprint arXiv:2408.15542,
-
[29]
Ye Liu, Kevin Qinghong Lin, Chang Wen Chen, and Mike Zheng Shou. Videomind: A chain-of-lora agent for long video reasoning.arXiv preprint arXiv:2503.13444, 2025. 3
-
[30]
Yongdong Luo, Xiawu Zheng, Xiao Yang, Guilin Li, Haojia Lin, Jinfa Huang, Jiayi Ji, Fei Chao, Jiebo Luo, and Ron- grong Ji. Video-rag: Visually-aligned retrieval-augmented long video comprehension.arXiv preprint arXiv:2411.13093,
-
[31]
Video-chatgpt: Towards detailed video un- derstanding via large vision and language models
Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Khan. Video-chatgpt: Towards detailed video un- derstanding via large vision and language models. InPro- ceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12585–12602, 2024. 2
2024
-
[32]
Mingyang Mao, Mariela M Perez-Cabarcas, Utteja Kallakuri, Nicholas R Waytowich, Xiaomin Lin, and Tinoosh Mohs- enin. Multi-rag: A multimodal retrieval-augmented genera- tion system for adaptive video understanding.arXiv preprint arXiv:2505.23990, 2025. 3
-
[33]
Ovo-bench: How far is your video-llms from real-world online video understanding? InProceedings of the Computer Vision and Pattern Recognition Conference, pages 18902–18913, 2025
Junbo Niu, Yifei Li, Ziyang Miao, Chunjiang Ge, Yuanhang Zhou, Qihao He, Xiaoyi Dong, Haodong Duan, Shuangrui Ding, Rui Qian, et al. Ovo-bench: How far is your video-llms from real-world online video understanding? InProceedings of the Computer Vision and Pattern Recognition Conference, pages 18902–18913, 2025. 6, 1
2025
-
[34]
Gpt-4o system card
OpenAI. Gpt-4o system card. Technical report, OpenAI,
-
[35]
OpenAI (2024)
System card. Accessed: 2025-11-12. Please cite as “OpenAI (2024)” per the document. 6
2025
-
[36]
Streaming long video un- derstanding with large language models.Advances in Neural Information Processing Systems, 37:119336–119360, 2024
Rui Qian, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Shuangrui Ding, Dahua Lin, and Jiaqi Wang. Streaming long video un- derstanding with large language models.Advances in Neural Information Processing Systems, 37:119336–119360, 2024. 3
2024
-
[37]
Dispider: Enabling video llms with active real-time interaction via dis- entangled perception, decision, and reaction
Rui Qian, Shuangrui Ding, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Yuhang Cao, Dahua Lin, and Jiaqi Wang. Dispider: Enabling video llms with active real-time interaction via dis- entangled perception, decision, and reaction. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 24045–24055, 2025. 6
2025
-
[38]
Qwen3-vl
QwenLM. Qwen3-vl. https : / / github . com / QwenLM/Qwen3-VL , 2025. GitHub repository. Apache- 2.0 license. Accessed: 2025-11-12. 6
2025
-
[39]
Hybridrag: Integrating knowledge graphs and vector retrieval augmented generation for efficient information extraction
Bhaskarjit Sarmah, Dhagash Mehta, Benika Hall, Rohan Rao, Sunil Patel, and Stefano Pasquali. Hybridrag: Integrating knowledge graphs and vector retrieval augmented generation for efficient information extraction. InProceedings of the 5th ACM International Conference on AI in Finance, pages 608–616, 2024. 3
2024
-
[40]
Enhancing retrieval-augmented large language models with iterative retrieval-generation synergy
Zhihong Shao, Yeyun Gong, Yelong Shen, Minlie Huang, Nan Duan, and Weizhu Chen. Enhancing retrieval-augmented large language models with iterative retrieval-generation syn- ergy.arXiv preprint arXiv:2305.15294, 2023. 3
-
[41]
Moviechat: From dense token to sparse memory for long video understanding
Enxin Song, Wenhao Chai, Guanhong Wang, Yucheng Zhang, Haoyang Zhou, Feiyang Wu, Haozhe Chi, Xun Guo, Tian Ye, Yanting Zhang, et al. Moviechat: From dense token to sparse memory for long video understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18221–18232, 2024. 6
2024
-
[42]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking mul- timodal understanding across millions of tokens of context. arXiv preprint arXiv:2403.05530, 2024. 6
work page internal anchor Pith review arXiv 2024
-
[43]
Sketchagent: Language- driven sequential sketch generation
Yael Vinker, Tamar Rott Shaham, Kristine Zheng, Alex Zhao, Judith E Fan, and Antonio Torralba. Sketchagent: Language- driven sequential sketch generation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 23355–23368, 2025. 2
2025
-
[44]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024. 2, 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
Episodic memory representation for long- form video understanding.arXiv preprint arXiv:2508.09486,
Yun Wang, Long Zhang, Jingren Liu, Jiaqi Yan, Zhanjie Zhang, Jiahao Zheng, Xun Yang, Dapeng Wu, Xiangyu Chen, and Xuelong Li. Episodic memory representation for long- form video understanding.arXiv preprint arXiv:2508.09486,
-
[46]
Videotree: Adaptive tree-based video representation for llm reasoning on long videos
Ziyang Wang, Shoubin Yu, Elias Stengel-Eskin, Jaehong Yoon, Feng Cheng, Gedas Bertasius, and Mohit Bansal. Videotree: Adaptive tree-based video representation for llm reasoning on long videos. InProceedings of the Computer Vi- sion and Pattern Recognition Conference, pages 3272–3283,
-
[47]
Visual causal scene refinement for video question answering
Yushen Wei, Yang Liu, Hong Yan, Guanbin Li, and Liang Lin. Visual causal scene refinement for video question answering. InProceedings of the 31st ACM International Conference on Multimedia, pages 377–386, 2023. 2
2023
-
[48]
Freeva: Offline mllm as training-free video assistant.arXiv preprint arXiv:2405.07798, 2024
Wenhao Wu. Freeva: Offline mllm as training-free video assistant.arXiv preprint arXiv:2405.07798, 2024. 6
-
[49]
Large multimodal agents: A survey.arXiv preprint arXiv:2402.15116, 2024
Junlin Xie, Zhihong Chen, Ruifei Zhang, Xiang Wan, and Guanbin Li. Large multimodal agents: A survey.arXiv preprint arXiv:2402.15116, 2024. 2
-
[50]
Weijian Xie, Xuefeng Liang, Yuhui Liu, Kaihua Ni, Hong Cheng, and Zetian Hu. Weknow-rag: An adaptive approach for retrieval-augmented generation integrating web search and knowledge graphs.arXiv preprint arXiv:2408.07611, 2024. 3
-
[51]
arXiv preprint arXiv:2501.13468 , year=
Haomiao Xiong, Zongxin Yang, Jiazuo Yu, Yunzhi Zhuge, Lu Zhang, Jiawen Zhu, and Huchuan Lu. Streaming video under- standing and multi-round interaction with memory-enhanced knowledge.arXiv preprint arXiv:2501.13468, 2025. 3, 6, 8, 1, 2
-
[52]
arXiv preprint arXiv:2502.10810 (2025)
Zhenyu Yang, Yuhang Hu, Zemin Du, Dizhan Xue, Sheng- sheng Qian, Jiahong Wu, Fan Yang, Weiming Dong, and Changsheng Xu. Svbench: A benchmark with temporal multi-turn dialogues for streaming video understanding.arXiv preprint arXiv:2502.10810, 2025. 3
-
[53]
Timechat-online: 80% visual tokens are naturally redundant in streaming videos
Linli Yao, Yicheng Li, Yuancheng Wei, Lei Li, Shuhuai Ren, Yuanxin Liu, Kun Ouyang, Lean Wang, Shicheng Li, Sida Li, et al. Timechat-online: 80% visual tokens are naturally redundant in streaming videos. InProceedings of the 33rd ACM International Conference on Multimedia, pages 10807– 10816, 2025. 3
2025
-
[54]
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, et al. Minicpm-v: A gpt-4v level mllm on your phone.arXiv preprint arXiv:2408.01800, 2024. 6
work page internal anchor Pith review arXiv 2024
-
[55]
Re- thinking temporal search for long-form video understanding
Jinhui Ye, Zihan Wang, Haosen Sun, Keshigeyan Chan- drasegaran, Zane Durante, Cristobal Eyzaguirre, Yonatan Bisk, Juan Carlos Niebles, Ehsan Adeli, Li Fei-Fei, et al. Re- thinking temporal search for long-form video understanding. InProceedings of the Computer Vision and Pattern Recogni- tion Conference, pages 8579–8591, 2025. 2
2025
-
[56]
Sicheng Yu, Chengkai Jin, Huanyu Wang, Zhenghao Chen, Sheng Jin, Zhongrong Zuo, Xiaolei Xu, Zhenbang Sun, Bingni Zhang, Jiawei Wu, et al. Frame-voyager: Learning to query frames for video large language models.arXiv preprint arXiv:2410.03226, 2024. 2
-
[57]
V-stylist: Video stylization via collaboration and reflection of mllm agents
Zhengrong Yue, Shaobin Zhuang, Kunchang Li, Yanbo Ding, and Yali Wang. V-stylist: Video stylization via collaboration and reflection of mllm agents. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 3195–3205,
-
[58]
VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
Boqiang Zhang, Kehan Li, Zesen Cheng, Zhiqiang Hu, Yuqian Yuan, Guanzheng Chen, Sicong Leng, Yuming Jiang, Hang Zhang, Xin Li, et al. Videollama 3: Frontier multimodal foundation models for image and video understanding.arXiv preprint arXiv:2501.13106, 2025. 2
work page internal anchor Pith review arXiv 2025
-
[59]
Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding
Hang Zhang, Xin Li, and Lidong Bing. Video-llama: An instruction-tuned audio-visual language model for video un- derstanding.arXiv preprint arXiv:2306.02858, 2023. 2, 6
work page internal anchor Pith review arXiv 2023
-
[60]
Haoji Zhang, Yiqin Wang, Yansong Tang, Yong Liu, Jiashi Feng, Jifeng Dai, and Xiaojie Jin. Flash-vstream: Memory- based real-time understanding for long video streams.arXiv preprint arXiv:2406.08085, 2024. 3, 6
-
[61]
arXiv preprint arXiv:2506.23825 , year=
Haoji Zhang, Yiqin Wang, Yansong Tang, Yong Liu, Ji- ashi Feng, and Xiaojie Jin. Flash-vstream: Efficient real- time understanding for long video streams.arXiv preprint arXiv:2506.23825, 2025. 3
-
[62]
Pan Zhang, Xiaoyi Dong, Yuhang Zang, Yuhang Cao, Rui Qian, Lin Chen, Qipeng Guo, Haodong Duan, Bin Wang, Linke Ouyang, et al. Internlm-xcomposer-2.5: A versatile large vision language model supporting long-contextual input and output.arXiv preprint arXiv:2407.03320, 2024. 6
-
[63]
Long Context Transfer from Language to Vision
Peiyuan Zhang, Kaichen Zhang, Bo Li, Guangtao Zeng, Jingkang Yang, Yuanhan Zhang, Ziyue Wang, Haoran Tan, Chunyuan Li, and Ziwei Liu. Long context transfer from language to vision.arXiv preprint arXiv:2406.16852, 2024. 6
work page internal anchor Pith review arXiv 2024
-
[64]
Direct preference op- timization of video large multimodal models from language model reward
Ruohong Zhang, Liangke Gui, Zhiqing Sun, Yihao Feng, Keyang Xu, Yuanhan Zhang, Di Fu, Chunyuan Li, Alexan- der G Hauptmann, Yonatan Bisk, et al. Direct preference op- timization of video large multimodal models from language model reward. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Lingu...
2025
-
[65]
LLaVA-Video: Video Instruction Tuning With Synthetic Data
Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Ziwei Liu, and Chunyuan Li. Video instruction tuning with synthetic data, 2024.URL https://arxiv. org/abs/2410.02713, 17. 2, 6
work page Pith review arXiv 2024
-
[66]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, et al. Qwen3 embedding: Advancing text embedding and reranking through foundation models.arXiv preprint arXiv:2506.05176, 2025. 6
work page internal anchor Pith review arXiv 2025
-
[67]
Cogstream: Context-guided streaming video question answering.arXiv preprint arXiv:2506.10516,
Zicheng Zhao, Kangyu Wang, Shijie Li, Rui Qian, Weiyao Lin, and Huabin Liu. Cogstream: Context-guided streaming video question answering.arXiv preprint arXiv:2506.10516,
-
[68]
Hierarchical event memory for accurate and low- latency online video temporal grounding
Minghang Zheng, Yuxin Peng, Benyuan Sun, Yi Yang, and Yang Liu. Hierarchical event memory for accurate and low- latency online video temporal grounding. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 21589–21599, 2025. 3
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.