Recognition: unknown
Comparison Drives Preference: Reference-Aware Modeling for AI-Generated Video Quality Assessment
Pith reviewed 2026-05-10 06:24 UTC · model grok-4.3
The pith
AI-generated video quality improves when assessment compares each video to a graph of semantically related others instead of judging it alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Existing AIGC-VQA methods estimate quality by analyzing each video independently. This work formulates the problem as reference-aware evaluation, in which quality assessment is guided by both intrinsic characteristics and comparisons with related videos. RefVQA implements the idea by building a query-centered reference graph of semantically related samples and performing graph-guided difference aggregation from the reference nodes to the query node, yielding higher alignment with human judgments across multiple quality dimensions.
What carries the argument
A query-centered reference graph that organizes semantically related videos around the query sample, combined with graph-guided difference aggregation that propagates comparative quality signals to the query node.
If this is right
- RefVQA outperforms prior state-of-the-art methods on multiple existing AIGC-VQA datasets across several quality dimensions.
- The method exhibits strong generalization when evaluated in cross-dataset settings.
- The reference-based formulation advances AIGC-VQA by demonstrating the value of inter-video comparisons.
- The same reference-graph structure can be applied to other generative media assessment tasks that currently rely on isolated analysis.
Where Pith is reading between the lines
- The approach could be extended to AI-generated images or audio by constructing analogous reference graphs from semantically similar items.
- Dynamic selection of reference nodes based on user history might allow personalized quality scores without retraining the model.
- Scaling the graph construction to very large video collections would require efficient nearest-neighbor retrieval to remain practical.
Load-bearing premise
Building a query-centered reference graph from semantically related videos and aggregating quality differences across its edges will capture human preferences more reliably than intrinsic features alone.
What would settle it
If a new dataset of human-rated AI-generated videos shows that RefVQA produces no higher correlation with human scores than a non-reference baseline that uses only intrinsic features, the claim that the reference graph adds value would be falsified.
Figures



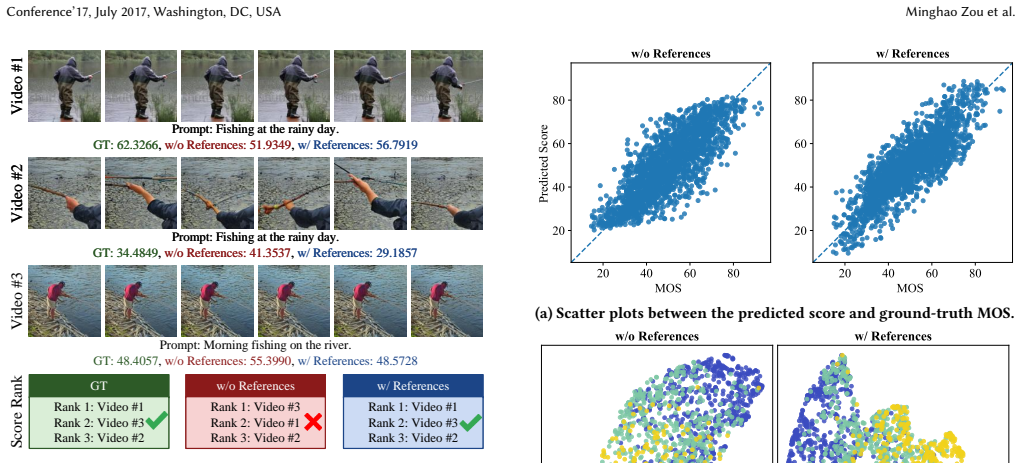


read the original abstract
The rapid advancement of generative models has led to a growing volume of AI-generated videos, making the automatic quality assessment of such videos increasingly important. Existing AI-generated content video quality assessment (AIGC-VQA) methods typically estimate visual quality by analyzing each video independently, ignoring potential relationships among videos. In this work, we revisit AIGC-VQA from an inter-video perspective and formulate it as a reference-aware evaluation problem. Through this formulation, quality assessment is guided not only by intrinsic video characteristics but also by comparisons with related videos, which is more consistent with human perception. To validate its effectiveness, we propose Reference-aware Video Quality Assessment (RefVQA), which utilizes a query-centered reference graph to organize semantically related samples and performs graph-guided difference aggregation from the reference nodes to the query node. Experiments on existing datasets demonstrate that our proposed RefVQA outperforms state-of-the-art methods across multiple quality dimensions, with strong generalization ability validated by cross-dataset evaluation. These results highlight the effectiveness of the proposed reference-based formulation and suggest its potential to advance AIGC-VQA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reformulates AI-generated video quality assessment (AIGC-VQA) as a reference-aware problem rather than independent per-video analysis. It introduces RefVQA, which constructs a query-centered reference graph from semantically related videos and performs graph-guided difference aggregation from reference nodes to the query node. The central claim is that this inter-video comparison mechanism yields better alignment with human perception, demonstrated by outperformance over state-of-the-art methods across multiple quality dimensions on existing datasets together with strong cross-dataset generalization.
Significance. If the empirical results hold, the work is significant for shifting AIGC-VQA toward relational modeling that incorporates comparisons with related videos, which the authors argue is more consistent with human judgment than intrinsic-feature-only approaches. The query-centered graph plus difference aggregation provides a concrete, plausible operationalization of this idea. The cross-dataset evaluation is a positive element that supports broader applicability. The absence of free parameters in the core formulation and the use of existing datasets for validation are strengths that make the contribution falsifiable and reproducible in principle.
major comments (1)
- [Experiments and Results] The central claim that reference-aware graph construction and difference aggregation reliably improve quality assessment beyond intrinsic features rests on the experimental results. The manuscript should include explicit ablation studies isolating the contribution of the reference graph and aggregation step (e.g., comparing against a version using only intrinsic features) with statistical significance tests, as the weakest assumption is that these components capture human preferences in a non-redundant way.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from a brief statement of the specific quality dimensions (e.g., visual quality, temporal consistency) on which outperformance is reported.
- [Method] Notation for the graph construction (e.g., how semantic similarity is computed to select reference nodes) should be defined more explicitly with an equation or pseudocode in the method section to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive recommendation of minor revision. We address the single major comment below.
read point-by-point responses
-
Referee: [Experiments and Results] The central claim that reference-aware graph construction and difference aggregation reliably improve quality assessment beyond intrinsic features rests on the experimental results. The manuscript should include explicit ablation studies isolating the contribution of the reference graph and aggregation step (e.g., comparing against a version using only intrinsic features) with statistical significance tests, as the weakest assumption is that these components capture human preferences in a non-redundant way.
Authors: We agree that explicit ablations are needed to isolate the contributions of the query-centered reference graph and graph-guided difference aggregation. In the revised manuscript we will add a dedicated ablation section that directly compares the full RefVQA model against an intrinsic-features-only baseline (identical backbone and training but without reference-graph construction or difference aggregation). We will also report statistical significance tests (paired t-tests across multiple random seeds and datasets) to quantify whether the observed gains are reliable. These additions will directly test the non-redundancy claim and strengthen the empirical support for the reference-aware formulation. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper formulates AIGC-VQA as a reference-aware problem and introduces RefVQA via a query-centered reference graph plus graph-guided difference aggregation. This modeling choice is presented as a novel operationalization of inter-video comparisons and is validated through empirical outperformance on existing datasets plus cross-dataset tests. No equations, claims, or results in the provided text reduce the proposed method or its performance metrics to self-defined fits, renamed inputs, or load-bearing self-citations by construction. The derivation remains self-contained and externally falsifiable via standard benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Comparisons with related videos provide guidance for quality assessment that is more consistent with human perception than intrinsic characteristics alone
invented entities (1)
-
query-centered reference graph
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Ziyi Bai, Ruiping Wang, Difei Gao, and Xilin Chen. 2024. Event Graph Guided Compositional Spatial-Temporal Reasoning for Video Question Answering.IEEE Transactions on Image Processing33 (2024), 1109–1121
2024
-
[2]
Chaoqi Chen, Yushuang Wu, Qiyuan Dai, Hong-Yu Zhou, Mutian Xu, Sibei Yang, Xiaoguang Han, and Yizhou Yu. 2024. A Survey on Graph Neural Networks and Graph Transformers in Computer Vision: A Task-Oriented Perspective.IEEE Transactions on Pattern Analysis and Machine Intelligence46, 12 (2024), 10297– 10318
2024
-
[3]
Ying Chen, Huasheng Wang, Pengxiang Xiao, Yukang Ding, Enpeng Liu, Chris Wei Zhou, Baojun Li, Jiamian Huang, Jiarui Wang, Xiaorong Zhu, et al
-
[4]
InIEEE/CVF International Conference on Computer Vision Workshops (ICCVW)
VQualA 2025 Challenge on GenAI-Bench AIGC Video Quality Assessment: Methods and Results. InIEEE/CVF International Conference on Computer Vision Workshops (ICCVW). IEEE, 3422–3431
2025
-
[5]
Jiale Cheng, Ruiliang Lyu, Xiaotao Gu, Xiao Liu, Jiazheng Xu, Yida Lu, Jiayan Teng, Zhuoyi Yang, Yuxiao Dong, Jie Tang, et al . 2025. VPO: Aligning Text- to-Video Generation Models with Prompt Optimization. InProceedings of the IEEE/CVF International Conference on Computer Vision. 15636–15645
2025
-
[6]
Shenyuan Gao, Chunluan Zhou, and Jun Zhang. 2023. Generalized Relation Modeling for Transformer Tracking. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 18686–18695
2023
-
[7]
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi
-
[8]
In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing
CLIPScore: A Reference-Free Evaluation Metric for Image Captioning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 7514–7528
2021
-
[9]
Channappayya
Parimala Kancharla and Sumohana S. Channappayya. 2022. Completely Blind Quality Assessment of User Generated Video Content.IEEE Transactions on Image Processing31 (2022), 263–274
2022
-
[10]
Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, et al. 2017. Comparison Drives Preference: Reference-Aware Modeling for AI-Generated Video Quality Assessment Conference’17, July 2017, Washington, DC, USA The Kinetics Human Action Video Dataset.arXiv preprin...
work page internal anchor Pith review arXiv 2017
-
[11]
Junjie Ke, Qifei Wang, Yilin Wang, Peyman Milanfar, and Feng Yang. 2021. MUSIQ: Multi-Scale Image Quality Transformer. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision. 5148–5157
2021
-
[12]
Yuval Kirstain, Adam Polyak, Uriel Singer, Shahbuland Matiana, Joe Penna, and Omer Levy. 2023. Pick-a-Pic: An Open Dataset of User Preferences for Text-to- Image Generation.Advances in Neural Information Processing Systems36 (2023), 36652–36663
2023
-
[13]
Tengchuan Kou, Xiaohong Liu, Zicheng Zhang, Chunyi Li, Haoning Wu, Xiongkuo Min, Guangtao Zhai, and Ning Liu. 2024. Subjective-Aligned Dataset and Metric for Text-to-Video Quality Assessment. InProceedings of the ACM International Conference on Multimedia. 7793–7802
2024
-
[14]
Bowen Li, Weixia Zhang, Meng Tian, Guangtao Zhai, and Xianpei Wang. 2022. Blindly Assess Quality of In-the-Wild Videos via Quality-Aware Pre-training and Motion Perception.IEEE Transactions on Circuits and Systems for Video Technology32, 9 (2022), 5944–5958
2022
-
[15]
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. 2022. BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation. InInternational Conference on Machine Learning. 12888–12900
2022
-
[16]
Jiaze Li, Haoran Xu, Shiding Zhu, Junwei He, and Haozhao Wang. 2025. Multilevel Semantic-Aware Model for AI-Generated Video Quality Assessment. InIEEE International Conference on Acoustics, Speech and Signal Processing. 1–5
2025
-
[17]
Yang Liu, Guanbin Li, and Liang Lin. 2023. Cross-Modal Causal Relational Reasoning for Event-Level Visual Question Answering.IEEE Transactions on Pattern Analysis and Machine Intelligence45, 10 (2023), 11624–11641
2023
-
[18]
Yuanxin Liu, Lei Li, Shuhuai Ren, Rundong Gao, Shicheng Li, Sishuo Chen, Xu Sun, and Lu Hou. 2023. FETV: A Benchmark for Fine-Grained Evaluation of Open- Domain Text-to-Video Generation.Advances in Neural Information Processing Systems36 (2023), 62352–62387
2023
-
[19]
Ze Liu, Jia Ning, Yue Cao, Yixuan Wei, Zheng Zhang, Stephen Lin, and Han Hu
-
[20]
InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Video Swin Transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 3202–3211
-
[21]
Yiting Lu, Xin Li, Bingchen Li, Zihao Yu, Fengbin Guan, Xinrui Wang, Ruling Liao, Yan Ye, and Zhibo Chen. 2024. AIGC-VQA: A Holistic Perception Metric for AIGC Video Quality Assessment. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. 6384–6394
2024
-
[22]
Pavan C Madhusudana, Neil Birkbeck, Yilin Wang, Balu Adsumilli, and Alan C Bovik. 2022. Image Quality Assessment Using Contrastive Learning.IEEE Transactions on Image Processing31 (2022), 4149–4161
2022
-
[23]
Leland McInnes, John Healy, and James Melville. 2018. UMAP: Uniform Man- ifold Approximation and Projection for Dimension Reduction.arXiv preprint arXiv:1802.03426(2018), 1–63
work page internal anchor Pith review arXiv 2018
-
[24]
Xiongkuo Min, Huiyu Duan, Wei Sun, Yucheng Zhu, and Guangtao Zhai. 2024. Perceptual Video Quality Assessment: A Survey.Science China Information Sciences67, 11 (2024), 211301
2024
-
[25]
Zhiqiang Pan, Fei Cai, Wanyu Chen, Honghui Chen, and Maarten De Rijke
-
[26]
InPro- ceedings of the 29th ACM international Conference on Information & Knowledge Management
Star Graph Neural Networks for Session-based Recommendation. InPro- ceedings of the 29th ACM international Conference on Information & Knowledge Management. 1195–1204
- [27]
-
[28]
Zelu Qi, Ping Shi, Chaoyang Zhang, Shuqi Wang, Fei Zhao, Da Pan, and Ze- feng Ying. 2025. Towards Holistic Visual Quality Assessment of AI-Generated Videos: A LLM-Based Multi-Dimensional Evaluation Model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. 1493–1502
2025
-
[29]
Haiyi Qiu, Minghe Gao, Long Qian, Kaihang Pan, Qifan Yu, Juncheng Li, Wenjie Wang, Siliang Tang, Yueting Zhuang, and Tat-Seng Chua. 2025. STEP: Enhancing Video-LLMs’ Compositional Reasoning by Spatio-Temporal Graph-guided Self- Training. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 3284–3294
2025
-
[30]
Bowen Qu, Xiaoyu Liang, Shangkun Sun, and Wei Gao. 2024. Exploring AIGC Video Quality: A Focus on Visual Harmony Video-Text Consistency and Domain Distribution Gap. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. 6652–6660
2024
-
[31]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sand- hini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al
-
[32]
InInternational Conference on Machine Learning
Learning Transferable Visual Models from Natural Language Supervision. InInternational Conference on Machine Learning. 8748–8763
-
[33]
Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. 3982–3992
2019
-
[34]
Lei Sang, Min Xu, Shengsheng Qian, Matt Martin, Peter Li, and Xindong Wu. 2020. Context-Dependent Propagating-Based Video Recommendation in Multimodal Heterogeneous Information Networks.IEEE Transactions on Multimedia23 (2020), 2019–2032
2020
-
[35]
Shangkun Sun, Xiaoyu Liang, Songlin Fan, Wenxu Gao, and Wei Gao. 2025. VE-Bench: Subjective-Aligned Benchmark Suite for Text-Driven Video Editing Quality Assessment. InProceedings of the AAAI Conference on Artificial Intelli- gence, Vol. 39. 7105–7113
2025
- [36]
-
[37]
Wei Sun, Xiongkuo Min, Wei Lu, and Guangtao Zhai. 2022. A Deep Learning based No-reference Quality Assessment Model for UGC Videos. InProceedings of the ACM International Conference on Multimedia. 856–865
2022
-
[38]
Wei Sun, Xiongkuo Min, Danyang Tu, Siwei Ma, and Guangtao Zhai. 2023. Blind Quality Assessment for in-the-Wild Images via Hierarchical Feature Fusion and Iterative Mixed Database Training.IEEE Journal of Selected Topics in Signal Processing17, 6 (2023), 1178–1192
2023
-
[39]
Zhengzhong Tu, Yilin Wang, Neil Birkbeck, Balu Adsumilli, and Alan C. Bovik
-
[40]
UGC-VQA: Benchmarking Blind Video Quality Assessment for User Gen- erated Content.IEEE Transactions on Image Processing30 (2021), 4449–4464
2021
-
[41]
Jianyi Wang, Kelvin CK Chan, and Chen Change Loy. 2023. Exploring CLIP for Assessing the Look and Feel of Images. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 37. 2555–2563
2023
-
[42]
Jiarui Wang, Huiyu Duan, Guangtao Zhai, Juntong Wang, and Xiongkuo Min
-
[43]
InProceedings of the Computer Vision and Pattern Recognition Conference
AIGV-Assessor: Benchmarking and Evaluating the Perceptual Quality of Text-to-Video Generation with LMMs. InProceedings of the Computer Vision and Pattern Recognition Conference. 18869–18880
-
[44]
Yi Wang, Yinan He, Yizhuo Li, Kunchang Li, Jiashuo Yu, Xin Ma, Xinhao Li, Guo Chen, Xinyuan Chen, Yaohui Wang, et al. 2024. InternVid: A Large-Scale Video- Text Dataset for Multimodal Understanding and Generation. InInternational Conference on Learning Representations. 1–25
2024
-
[45]
Yanan Wang, Michihiro Yasunaga, Hongyu Ren, Shinya Wada, and Jure Leskovec
-
[46]
InProceedings of the IEEE/CVF International Conference on Computer Vision
VQA-GNN: Reasoning with Multimodal Knowledge via Graph Neural Net- works for Visual Question Answering. InProceedings of the IEEE/CVF International Conference on Computer Vision. 21582–21592
-
[47]
Yujie Wei, Shiwei Zhang, Hangjie Yuan, Biao Gong, Longxiang Tang, Xiang Wang, Haonan Qiu, Hengjia Li, Shuai Tan, Yingya Zhang, et al. 2025. Dream- Relation: Relation-Centric Video Customization. InProceedings of the IEEE/CVF International Conference on Computer Vision. 12381–12393
2025
-
[48]
Haoning Wu, Chaofeng Chen, Jingwen Hou, Liang Liao, Annan Wang, Wenxiu Sun, Qiong Yan, and Weisi Lin. 2022. FAST-VQA: Efficient End-to-End Video Qual- ity Assessment with Fragment Sampling. InEuropean Conference on Computer Vision. 538–554
2022
- [49]
-
[50]
Haoning Wu, Erli Zhang, Liang Liao, Chaofeng Chen, Jingwen Hou, Annan Wang, Wenxiu Sun, Qiong Yan, and Weisi Lin. 2023. Exploring Video Quality Assessment on User Generated Contents from Aesthetic and Technical Perspec- tives. InProceedings of the IEEE/CVF International Conference on Computer Vision. 20144–20154
2023
-
[51]
Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, and Hongsheng Li. 2023. Human Preference Score v2: A Solid Benchmark for Evaluating Human Preferences of Text-to-Image Synthesis.arXiv preprint arXiv:2306.09341(2023), 1–24
work page internal anchor Pith review arXiv 2023
-
[52]
Junbin Xiao, Pan Zhou, Tat-Seng Chua, and Shuicheng Yan. 2022. Video Graph Transformer for Video Question Answering. InEuropean Conference on Computer Vision. Springer, 39–58
2022
-
[53]
Jiazheng Xing, Mengmeng Wang, Yudi Ruan, Bofan Chen, Yaowei Guo, Boyu Mu, Guang Dai, Jingdong Wang, and Yong Liu. 2023. Boosting Few-shot Action Recognition with Graph-guided Hybrid Matching. InProceedings of the IEEE/CVF international conference on computer vision. 1740–1750
2023
-
[54]
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. 2023. ImageReward: Learning and evaluating human prefer- ences for text-to-image generation.Advances in Neural Information Processing Systems36 (2023), 15903–15935
2023
-
[55]
Yuning You, Tianlong Chen, Yongduo Sui, Ting Chen, Zhangyang Wang, and Yang Shen. 2020. Graph Contrastive Learning with Augmentations.Advances in Neural Information Processing Systems33 (2020), 5812–5823
2020
- [56]
-
[57]
Yawen Zeng, Da Cao, Xiaochi Wei, Meng Liu, Zhou Zhao, and Zheng Qin. 2021. Multi-Modal Relational Graph for Cross-Modal Video Moment Retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2215–2224. Conference’17, July 2017, Washington, DC, USA Minghao Zou et al
2021
-
[58]
Weixia Zhang, Kede Ma, Guangtao Zhai, and Xiaokang Yang. 2021. Uncertainty- Aware Blind Image Quality Assessment in the Laboratory and Wild.IEEE Trans- actions on Image Processing30 (2021), 3474–3486
2021
-
[59]
Weixia Zhang, Guangtao Zhai, Ying Wei, Xiaokang Yang, and Kede Ma. 2023. Blind Image Quality Assessment via Vision-Language Correspondence: A Multi- task Learning Perspective. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 14071–14081
2023
-
[60]
Xuanyu Zhang, Weiqi Li, Shijie Zhao, Junlin Li, Li Zhang, and Jian Zhang. 2026. VQ-Insight: Teaching VLMs for AI-Generated Video Quality Understanding via Progressive Visual Reinforcement Learning. 40, 15 (2026), 12870–12878
2026
-
[61]
Zicheng Zhang, Tengchuan Kou, Shushi Wang, Chunyi Li, Wei Sun, Wei Wang, Xiaoyu Li, Zongyu Wang, Xuezhi Cao, Xiongkuo Min, et al. 2025. Q-Eval-100K: Evaluating Visual Quality and Alignment Level for Text-to-Vision Content. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 10621–10631
2025
-
[62]
Zhichao Zhang, Xinyue Li, Wei Sun, Zicheng Zhang, Xiaohong Liu, Xiongkuo Min, and Guangtao Zhai. 2025. LMVQ: Label-free Metric-learning for General AI- generated Video Quality Assessment.IEEE Transactions on Circuits and Systems for Video Technology(2025). Early Access
2025
-
[63]
Zhichao Zhang, Wei Sun, Li Xinyue, Jun Jia, Xiongkuo Min, Zicheng Zhang, Chunyi Li, Zijian Chen, Wang Puyi, Sun Fengyu, et al. 2025. Benchmarking Multi- dimensional AIGC Video Quality Assessment: A Dataset and Unified Model.ACM Transactions on Multimedia Computing, Communications and Applications21, 9 (2025), 1–24
2025
-
[64]
Zijie Zhou, Mingliang Zhou, Jun Luo, Huayan Pu, Leong Hou U, Xuekai Wei, and Weijia Jia. 2025. VideoGNN: Video Representation Learning via Dynamic Graph Modelling.ACM Transactions on Multimedia Computing, Communications and Applications21, 12 (2025), 1–22
2025
-
[65]
Wencheng Zhu, Yucheng Han, Jiwen Lu, and Jie Zhou. 2022. Relational Reasoning Over Spatial-Temporal Graphs for Video Summarization.IEEE Transactions on Image Processing31 (2022), 3017–3031
2022
-
[66]
Jian Zou, Xiaoyu Xu, Zhihua Wang, Yilin Wang, Balu Adsumilli, and Kede Ma
-
[67]
arXiv preprint arXiv:2603.11525(2026), 1–13
MDS-VQA: Model-Informed Data Selection for Video Quality Assessment. arXiv preprint arXiv:2603.11525(2026), 1–13
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.