Recognition: unknown
Modeling Multi-Dimensional Cognitive States in Large Language Models under Cognitive Crowding
Pith reviewed 2026-05-10 06:53 UTC · model grok-4.3
The pith
HyCoLLM embeds cognitive states in hyperbolic space to resolve representation overlap, letting an 8B model outperform GPT-4o on joint emotion, stance, thinking style, and intention tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CognitiveBench demonstrates that joint multi-dimensional cognitive modeling exposes a fundamental geometric mismatch: hierarchical states require exponential capacity, yet Euclidean LLM spaces grow polynomially and therefore overlap. HyCoLLM corrects this by performing cognitive-state modeling directly in hyperbolic space and aligning the LLM via Hyperbolic Guided Alignment Tuning, which preserves hierarchy without crowding and restores joint-task accuracy.
What carries the argument
Hyperbolic space embedding of cognitive states combined with Hyperbolic Guided Alignment Tuning, which realigns LLM representations to match the hierarchical geometry revealed by Gromov delta-hyperbolicity analysis.
If this is right
- Joint multi-dimensional cognitive understanding becomes practical for LLMs without the observed accuracy collapse.
- Smaller-parameter models can exceed much larger baselines once the geometric mismatch is removed.
- Hyperbolic embeddings become a viable replacement for Euclidean ones on any psychological or hierarchical annotation task.
- Alignment tuning that respects hyperbolic geometry improves simultaneous performance across emotion, stance, intention, and thinking style.
Where Pith is reading between the lines
- The same crowding mechanism may limit LLM performance on other hierarchically organized tasks such as multi-hop reasoning or nested planning.
- CognitiveBench-style benchmarks could be extended to measure crowding in real-time dialogue systems that must track emotion and intention simultaneously.
- If hyperbolic alignment generalizes, it offers a parameter-efficient route to richer internal state representations without increasing model size.
Load-bearing premise
The performance collapse on joint tasks is caused by the mismatch between exponential space demands of hierarchical cognitive states and the polynomial growth of Euclidean LLM embeddings.
What would settle it
A controlled experiment that keeps all other factors fixed and shows that joint accuracy on CognitiveBench does not recover when the same 8B model is fine-tuned in Euclidean space with otherwise identical alignment tuning.
Figures








read the original abstract
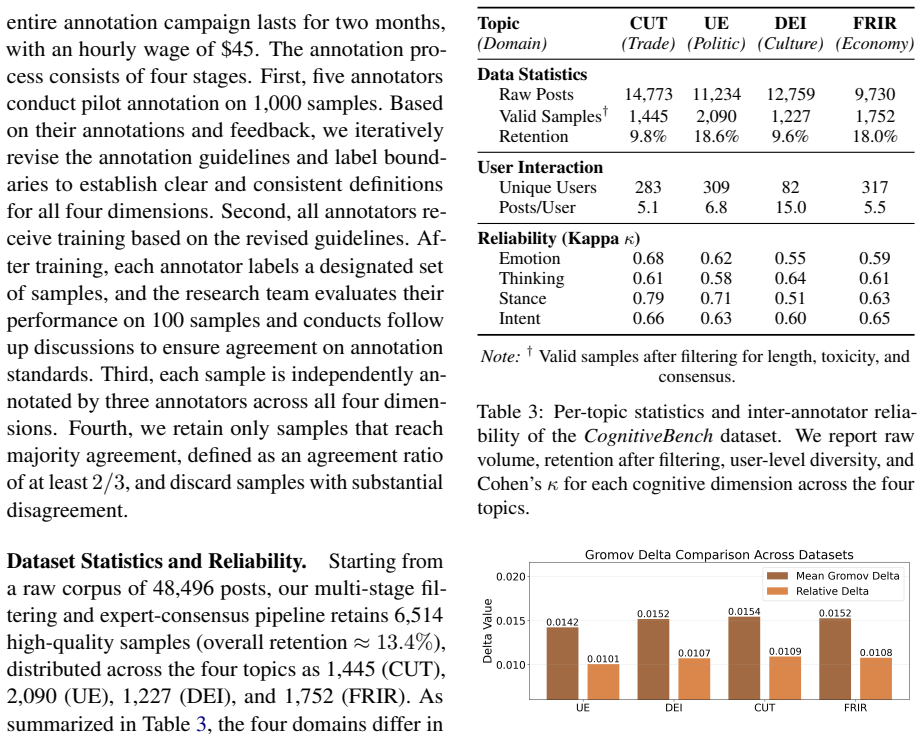
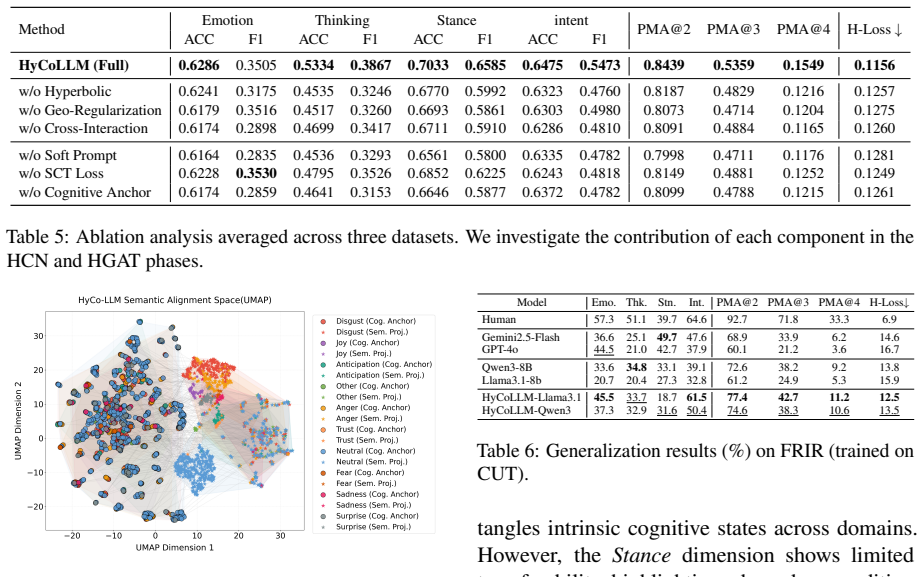
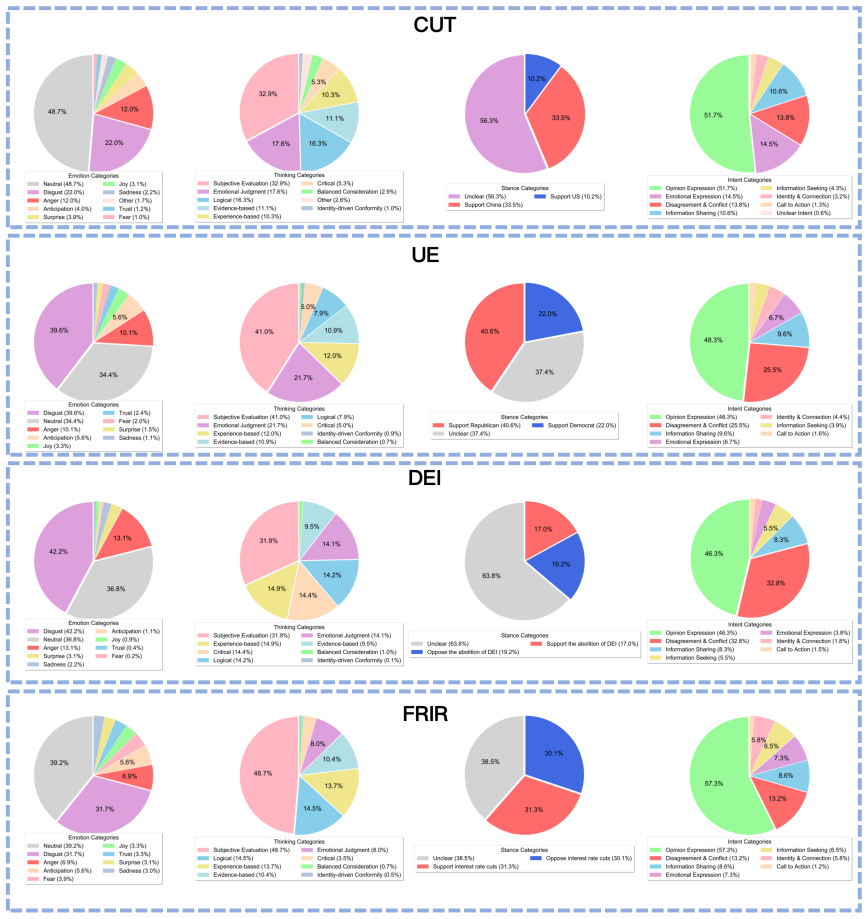
Modeling human cognitive states is essential for advanced artificial intelligence. Existing Large Language Models (LLMs) mainly address isolated tasks such as emotion analysis or stance detection, and fail to capture interactions among cognitive dimensions defined in psychology, including emotion, thinking style, stance, and intention. To bridge this gap, we construct CognitiveBench, the first benchmark with unified annotations across the above four dimensions. Experiments on CognitiveBench show that although LLMs perform well on single dimension tasks, their performance drops sharply in joint multi-dimensional modeling. Using Gromov $\delta$-hyperbolicity analysis, we find that CognitiveBench exhibits a strong hierarchical structure. We attribute the performance bottleneck to ``Cognitive Crowding'', where hierarchical cognitive states require exponential representational space, while the Euclidean space of LLMs grows only polynomially, causing representation overlap and degraded performance. To address this mismatch, we propose HyCoLLM, which models cognitive states in hyperbolic space and aligns LLM representations via Hyperbolic Guided Alignment Tuning. Results show that HyCoLLM substantially improves multi-dimensional cognitive understanding, allowing 8B parameter model to outperform strong baselines, including GPT-4o.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper constructs CognitiveBench, the first benchmark with unified annotations across four cognitive dimensions (emotion, thinking style, stance, intention). It reports that LLMs perform well on single-dimension tasks but exhibit sharp degradation on joint multi-dimensional modeling. Gromov δ-hyperbolicity analysis reveals strong hierarchical structure in the data, which the authors attribute to 'Cognitive Crowding' arising from the mismatch between exponential representational requirements of hierarchies and the polynomial volume growth of Euclidean LLM spaces, leading to representation overlap. To address this, they introduce HyCoLLM, which embeds cognitive states in hyperbolic space and applies Hyperbolic Guided Alignment Tuning; experiments indicate substantial gains, with an 8B-parameter model outperforming strong baselines including GPT-4o.
Significance. If the causal mechanism is substantiated, the work offers a principled approach to multi-dimensional cognitive modeling by leveraging hyperbolic geometry for hierarchical structures, potentially benefiting dialogue systems, psychological AI, and multi-task NLP. The unified CognitiveBench provides a reusable resource for standardized evaluation across dimensions. Credit is due for the benchmark construction with joint annotations and the empirical demonstration of gains via hyperbolic alignment, which could inspire further geometry-aware methods if the crowding hypothesis is isolated from confounds.
major comments (3)
- [Abstract] Abstract and hyperbolicity analysis: The central claim attributes joint-task degradation to Cognitive Crowding from exponential-vs-polynomial space mismatch, supported only by δ-hyperbolicity on CognitiveBench plus observed performance drops. No direct measurements (e.g., embedding overlap, pairwise distance distortion, or effective capacity under joint vs. single-dimension conditions) are provided to establish the posited representational overlap, leaving alternative explanations such as task interference or label correlations unaddressed and the hyperbolic fix's specificity unisolated.
- [Experiments] Experiments section: The headline result that an 8B HyCoLLM outperforms GPT-4o and other strong baselines lacks reported details on exact baselines, statistical significance tests, error bars, data splits, and ablation controls that isolate the hyperbolic component. This undermines interpretability of the performance gains and the claim that the method resolves the identified bottleneck.
- [Method] Method and analysis: The definition and operationalization of Cognitive Crowding (as distinct from general multi-task interference) is introduced without a quantitative metric beyond hyperbolicity; the Hyperbolic Guided Alignment Tuning procedure requires explicit equations for the alignment loss and any projection steps to allow reproduction and verification that it specifically mitigates the claimed volume mismatch.
minor comments (2)
- [Abstract] The abstract states 'strong hierarchical structure' but does not report the specific δ-hyperbolicity values or comparisons against non-hierarchical baselines.
- Ensure all tables and figures include error bars, exact metric definitions, and legends; clarify notation for any hyperbolic operations (e.g., Möbius addition) in the method description.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which has identified important areas for strengthening the manuscript. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract and hyperbolicity analysis: The central claim attributes joint-task degradation to Cognitive Crowding from exponential-vs-polynomial space mismatch, supported only by δ-hyperbolicity on CognitiveBench plus observed performance drops. No direct measurements (e.g., embedding overlap, pairwise distance distortion, or effective capacity under joint vs. single-dimension conditions) are provided to establish the posited representational overlap, leaving alternative explanations such as task interference or label correlations unaddressed and the hyperbolic fix's specificity unisolated.
Authors: We agree that direct measurements of representational overlap would provide stronger causal evidence for the Cognitive Crowding mechanism. The current manuscript relies on the combination of sharp performance degradation in joint tasks and high Gromov δ-hyperbolicity as supporting indicators of hierarchical structure leading to volume mismatch. In the revision we will add explicit analyses of embedding overlap, pairwise distance distortion, and effective capacity comparisons between joint and single-dimension conditions. We will also expand the discussion to address alternative explanations such as task interference and label correlations, and include further controls to assess the specificity of the hyperbolic intervention. revision: partial
-
Referee: [Experiments] Experiments section: The headline result that an 8B HyCoLLM outperforms GPT-4o and other strong baselines lacks reported details on exact baselines, statistical significance tests, error bars, data splits, and ablation controls that isolate the hyperbolic component. This undermines interpretability of the performance gains and the claim that the method resolves the identified bottleneck.
Authors: We accept that the experimental reporting requires greater detail and transparency to support the claims. In the revised manuscript we will specify all baseline models and prompting configurations exactly, report statistical significance tests with p-values, include error bars computed over multiple random seeds, document the train/validation/test splits, and add ablation studies that isolate the hyperbolic embedding and Hyperbolic Guided Alignment Tuning components. revision: yes
-
Referee: [Method] Method and analysis: The definition and operationalization of Cognitive Crowding (as distinct from general multi-task interference) is introduced without a quantitative metric beyond hyperbolicity; the Hyperbolic Guided Alignment Tuning procedure requires explicit equations for the alignment loss and any projection steps to allow reproduction and verification that it specifically mitigates the claimed volume mismatch.
Authors: We agree that a quantitative metric for Cognitive Crowding beyond hyperbolicity and full mathematical specifications are necessary for reproducibility. In the revision we will introduce an explicit quantitative measure of representational overlap (e.g., based on embedding similarity or distortion) to operationalize Cognitive Crowding as distinct from generic multi-task effects. We will also provide the complete equations for the alignment loss and all projection operations in Hyperbolic Guided Alignment Tuning. revision: yes
Circularity Check
No significant circularity; derivation chain is self-contained with independent empirical components
full rationale
The paper introduces CognitiveBench, measures its Gromov δ-hyperbolicity to establish hierarchy, reports observed performance drops on joint vs. single-dimension tasks, offers an interpretive attribution to a space-mismatch effect labeled Cognitive Crowding, and then presents HyCoLLM with empirical gains. No step reduces to another by construction: the hyperbolicity result is a direct computation on the benchmark data, the performance numbers are experimental outcomes, and the hyperbolic modeling proposal is a distinct architectural choice whose success is evaluated separately. No self-citations, fitted parameters renamed as predictions, or definitional loops appear in the provided chain. The attribution is an explanatory hypothesis rather than a tautological reduction, leaving the overall derivation independent.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Cognitive states across emotion, thinking style, stance, and intention form a hierarchical structure that can be quantified by Gromov δ-hyperbolicity
invented entities (1)
-
Cognitive Crowding
no independent evidence
Reference graph
Works this paper leans on
-
[1]
I understand your perspective
“I understand your perspective”: LLM Persuasion through the Lens of Communicative Action Theory , author =. Findings of the Association for Computational Linguistics: ACL 2025 , pages =
2025
-
[2]
Machine Learning , volume =
Evaluating large language models for user stance detection on X (Twitter) , author =. Machine Learning , volume =. 2024 , publisher =
2024
-
[3]
Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021 , pages =
P-stance: A large dataset for stance detection in political domain , author =. Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021 , pages =
2021
-
[4]
Journal of Scientific & Industrial Research , volume =
Stance and Sentiment Analysis of Health-related Tweets with Data Augmentation , author =. Journal of Scientific & Industrial Research , volume =
-
[5]
Proceedings of the 2021 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining , pages =
SentiStance: quantifying the intertwined changes of sentiment and stance in response to an event in online forums , author =. Proceedings of the 2021 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining , pages =
2021
-
[6]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =
What is the real intention behind this question? dataset collection and intention classification , author =. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =
-
[7]
Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Papers , pages =
A dataset for multi-target stance detection , author =. Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Papers , pages =
-
[8]
2015 IEEE international conference on data mining workshop (ICDMW) , pages =
An ensemble sentiment classification system of twitter data for airline services analysis , author =. 2015 IEEE international conference on data mining workshop (ICDMW) , pages =
2015
-
[9]
Proceedings of the 10th international workshop on semantic evaluation (SemEval-2016) , pages =
Semeval-2016 task 6: Detecting stance in tweets , author =. Proceedings of the 10th international workshop on semantic evaluation (SemEval-2016) , pages =
2016
-
[10]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages =
Improving multi-task stance detection with multi-task interaction network , author =. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages =
2022
-
[11]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =
Gunstance: Stance detection for gun control and gun regulation , author =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =
-
[12]
2024 , eprint =
EcoVerse: An annotated Twitter dataset for eco-relevance classification, environmental impact analysis, and stance detection , author =. 2024 , eprint =
2024
-
[13]
Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics , pages =
Stance detection in COVID-19 tweets , author =. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics , pages =
-
[14]
Electronics , volume =
Integrating emotional features for stance detection aimed at social network security: A multi-task learning approach , author =. Electronics , volume =
-
[15]
Proceedings of the ACM Web Conference 2023 , pages =
A multi-task model for emotion and offensive aided stance detection of climate change tweets , author =. Proceedings of the ACM Web Conference 2023 , pages =
2023
-
[16]
Scientific reports , volume =
The global landscape of cognition: hierarchical aggregation as an organizational principle of human cortical networks and functions , author =. Scientific reports , volume =. 2015 , publisher =
2015
-
[17]
, author =
Emotion knowledge: further exploration of a prototype approach. , author =. Journal of personality and social psychology , volume =. 1987 , publisher =
1987
-
[18]
Large language models fail on trivial alterations to theory-of-mind tasks, 2023
Large language models fail on trivial alterations to theory-of-mind tasks , author =. arXiv preprint arXiv:2302.08399 , year =
-
[19]
Proceedings of the AAAI conference on artificial intelligence , volume =
Atomic: An atlas of machine commonsense for if-then reasoning , author =. Proceedings of the AAAI conference on artificial intelligence , volume =
-
[20]
, author =
Empirical validation of affect, behavior, and cognition as distinct components of attitude. , author =. Journal of personality and social psychology , volume =. 1984 , publisher =
1984
-
[21]
Thomson Wadsworth , year =
The psychology of attitudes , author =. Thomson Wadsworth , year =
-
[22]
Theories of emotion , pages =
A general psychoevolutionary theory of emotion , author =. Theories of emotion , pages =. 1980 , publisher =
1980
-
[23]
Proceedings of the 33rd ACM International Conference on Information and Knowledge Management , pages =
Can llms reason like humans? assessing theory of mind reasoning in llms for open-ended questions , author =. Proceedings of the 33rd ACM International Conference on Information and Knowledge Management , pages =
-
[24]
Proceedings of the AAAI Conference on Artificial Intelligence , volume =
Tomato: Verbalizing the mental states of role-playing llms for benchmarking theory of mind , author =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =
-
[25]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Act2P: LLM-Driven Online Dialogue Act Classification for Power Analysis , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[26]
arXiv preprint arXiv:2507.01543 , year=
Is External Information Useful for Stance Detection with LLMs? , author=. arXiv preprint arXiv:2507.01543 , year=
-
[27]
Australasian Joint Conference on Artificial Intelligence , pages=
Beyond Factualism: A Study of LLM Calibration Through the Lens of Conversational Emotion Recognition , author=. Australasian Joint Conference on Artificial Intelligence , pages=. 2024 , organization=
2024
-
[28]
Tsinghua Science and Technology , volume=
LLM4DEU: fine tuning large language model for medical diagnosis in outpatient and emergency department visits of neurosurgery , author=. Tsinghua Science and Technology , volume=. 2025 , publisher=
2025
-
[29]
Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
Comapoi: A collaborative multi-agent framework for next poi prediction bridging the gap between trajectory and language , author=. Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[30]
Nature reviews neuroscience , volume=
On the relationship between emotion and cognition , author=. Nature reviews neuroscience , volume=. 2008 , publisher=
2008
-
[31]
Proceedings of the 2018 international conference on technical debt , pages=
Cognitive complexity: An overview and evaluation , author=. Proceedings of the 2018 international conference on technical debt , pages=
2018
-
[32]
theory of mind
What is “theory of mind”? Concepts, cognitive processes and individual differences , author=. Quarterly journal of experimental psychology , volume=. 2012 , publisher=
2012
-
[33]
, author =
Social judgment: Assimilation and contrast effects in communication and attitude change. , author =. 1961 , publisher =
1961
-
[34]
Attitude Organization and Change , year =
Cognitive, affective, and behavioral components of attitudes , author =. Attitude Organization and Change , year =
-
[35]
1975 , publisher =
How to do things with words , author =. 1975 , publisher =
1975
-
[36]
Language in society , volume =
A classification of illocutionary acts1 , author =. Language in society , volume =. 1976 , publisher =
1976
-
[37]
British journal of social psychology , volume =
The significance of the social identity concept for social psychology with reference to individualism, interactionism and social influence , author =. British journal of social psychology , volume =. 1986 , publisher =
1986
-
[38]
1980 , publisher =
Emotion, theory, research, and experience , author =. 1980 , publisher =
1980
-
[39]
2011 , publisher =
Thinking, fast and slow , author =. 2011 , publisher =
2011
-
[40]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
Qwen2.5-Coder Technical Report
Qwen2. 5-coder technical report , author=. arXiv preprint arXiv:2409.12186 , year=
work page internal anchor Pith review arXiv
-
[43]
LLaMA: Open and Efficient Foundation Language Models
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [45]
-
[46]
GitHub repository , howpublished=
Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec , title=. GitHub repository , howpublished=. 2020 , publisher=
2020
-
[47]
Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
Efficient Memory Management for Large Language Model Serving with PagedAttention , author=. Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
-
[48]
arXiv preprint arXiv:2402.06044 , year =
OpenToM: A comprehensive benchmark for evaluating theory-of-mind reasoning capabilities of large language models , author =. arXiv preprint arXiv:2402.06044 , year =
-
[49]
Proceedings of the National Academy of Sciences , volume =
Evaluating large language models in theory of mind tasks , author =. Proceedings of the National Academy of Sciences , volume =. 2024 , publisher =
2024
-
[50]
Nature Human Behaviour , volume =
Testing theory of mind in large language models and humans , author =. Nature Human Behaviour , volume =. 2024 , publisher =
2024
-
[51]
Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =
Clever hans or neural theory of mind? stress testing social reasoning in large language models , author =. Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =
-
[52]
Proceedings of the 33rd ACM International Conference on Information and Knowledge Management , pages =
Two heads are better than one: zero-shot cognitive reasoning via multi-LLM knowledge fusion , author =. Proceedings of the 33rd ACM International Conference on Information and Knowledge Management , pages =
-
[53]
arXiv preprint arXiv:2402.07092 , year =
Generalizing conversational dense retrieval via llm-cognition data augmentation , author =. arXiv preprint arXiv:2402.07092 , year =
-
[54]
arXiv preprint arXiv:2405.16964 , year =
Exploring the llm journey from cognition to expression with linear representations , author =. arXiv preprint arXiv:2405.16964 , year =
-
[55]
International Journal of Human-Computer Studies , volume =
Integrating augmented reality and LLM for enhanced cognitive support in critical audio communications , author =. International Journal of Human-Computer Studies , volume =. 2025 , publisher =
2025
-
[56]
Findings of the association for computational linguistics: EMNLP 2024 , pages =
Cognitive bias in decision-making with LLMs , author =. Findings of the association for computational linguistics: EMNLP 2024 , pages =
2024
-
[57]
arXiv preprint arXiv:2403.16008 , year =
CBT-LLM: A Chinese large language model for cognitive behavioral therapy-based mental health question answering , author =. arXiv preprint arXiv:2403.16008 , year =
-
[58]
ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages =
Llm supervised pre-training for multimodal emotion recognition in conversations , author =. ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages =. 2025 , organization =
2025
-
[59]
Proceedings of the 32nd ACM International Conference on Multimedia , pages =
Towards emotion-enriched text-to-motion generation via LLM-guided limb-level emotion manipulating , author =. Proceedings of the 32nd ACM International Conference on Multimedia , pages =
-
[60]
Proceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems , pages =
Don't Get Too Excited-Eliciting Emotions in LLMs , author =. Proceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems , pages =
-
[61]
Proceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems , pages =
Context over Categories: Implementing the Theory of Constructed Emotion with LLM-Guided User Analysis , author =. Proceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems , pages =
-
[62]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers) , pages =
LLM-driven knowledge injection advances zero-shot and cross-target stance detection , author =. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers) , pages =
2024
-
[63]
Findings of the Association for Computational Linguistics: ACL 2025 , pages =
Can Large Language Models Address Open-Target Stance Detection? , author =. Findings of the Association for Computational Linguistics: ACL 2025 , pages =
2025
-
[64]
Companion Proceedings of the ACM on Web Conference 2025 , pages =
TAT: Improving Stance Detection on Social Media through Thought Alignment with LLMs , author =. Companion Proceedings of the ACM on Web Conference 2025 , pages =
2025
-
[65]
Proceedings of the 47th international ACM SIGIR conference on research and development in information retrieval , pages =
Pag-llm: Paraphrase and aggregate with large language models for minimizing intent classification errors , author =. Proceedings of the 47th international ACM SIGIR conference on research and development in information retrieval , pages =
-
[66]
arXiv preprint arXiv:2404.13940 , year =
A user-centric multi-intent benchmark for evaluating large language models , author =. arXiv preprint arXiv:2404.13940 , year =
-
[67]
Nickel, Maximillian and Kiela, Douwe , journal =. Poincar
-
[68]
Advances in neural information processing systems , volume =
Hyperbolic neural networks , author =. Advances in neural information processing systems , volume =
-
[69]
Poincaré glove: Hyperbolic word embeddings
Poincar 'e glove: Hyperbolic word embeddings , author =. arXiv preprint arXiv:1810.06546 , year =
-
[70]
IEEE Transactions on pattern analysis and machine intelligence , volume =
Hyperbolic deep neural networks: A survey , author =. IEEE Transactions on pattern analysis and machine intelligence , volume =. 2021 , publisher =
2021
-
[71]
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =
Fully hyperbolic neural networks , author =. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =
-
[72]
Proceedings of the IEEE/CVF international conference on computer vision , pages =
Pointr: Diverse point cloud completion with geometry-aware transformers , author =. Proceedings of the IEEE/CVF international conference on computer vision , pages =
-
[73]
Advances in Neural Information Processing Systems , volume =
Context and geometry aware voxel transformer for semantic scene completion , author =. Advances in Neural Information Processing Systems , volume =
-
[74]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages =
Geometry-aware scene text detection with instance transformation network , author =. Proceedings of the IEEE conference on computer vision and pattern recognition , pages =
-
[75]
Continuous hierarchical representations with poincar
Mathieu, Emile and Le Lan, Charline and Maddison, Chris J and Tomioka, Ryota and Teh, Yee Whye , journal =. Continuous hierarchical representations with poincar
-
[76]
Multi-relational poincar
Balazevic, Ivana and Allen, Carl and Hospedales, Timothy , journal =. Multi-relational poincar
-
[77]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
Hyperbolic contrastive learning for visual representations beyond objects , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
-
[78]
Proceedings of the 40th International Conference on Machine Learning (ICML) , pages =
Hyperbolic image-text representations , author =. Proceedings of the 40th International Conference on Machine Learning (ICML) , pages =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.