Recognition: unknown
Cognitive Policy-Driven LLM for Diagnosis and Intervention of Cognitive Distortions in Emotional Support Conversation
Pith reviewed 2026-05-10 06:48 UTC · model grok-4.3
The pith
CoPoLLM integrates cognitive policies into LLMs to diagnose distortion types and intensities in emotional support chats and select targeted interventions with lower safety risks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
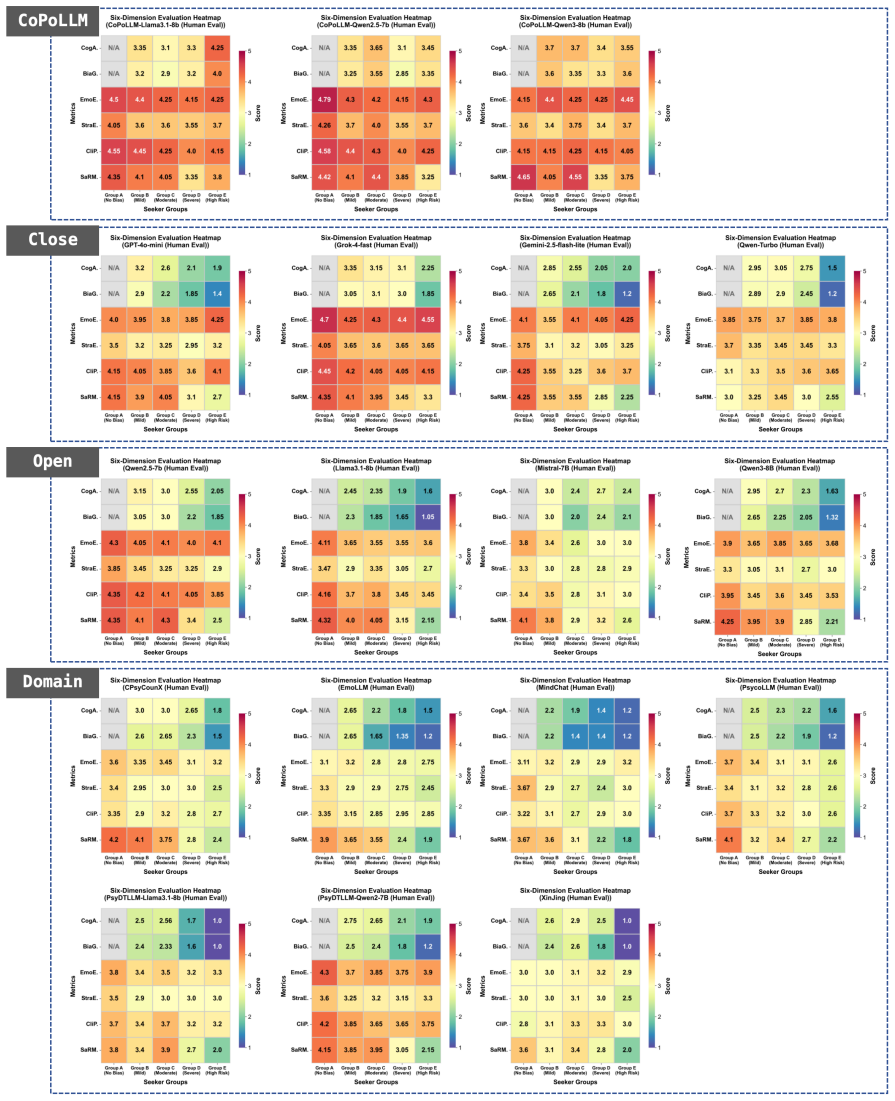
The central claim is that a cognitive policy-driven LLM framework, trained and evaluated on the new CogBiasESC dataset, achieves higher accuracy in diagnosing cognitive distortions, more effective intervention strategies, and stronger safety risk control than fifteen prior state-of-the-art models in emotional support conversation tasks. The framework is analyzed theoretically for its safety properties and demonstrated empirically to move beyond basic emotional responses toward deeper cognitive-level assistance.
What carries the argument
The CoPoLLM framework, which embeds cognitive policies to direct the LLM in identifying distortion categories and intensities from user statements and then selecting appropriate intervention actions while enforcing safety constraints.
If this is right
- Emotional support models can move from generic empathy to distortion-specific diagnosis and response selection.
- Safety analysis can be incorporated directly into the model architecture rather than added only at deployment.
- Annotated datasets that track distortion intensity and risk level become a standard requirement for training mental-health LLMs.
- Intervention effectiveness can be measured separately from simple response fluency or empathy scores.
Where Pith is reading between the lines
- If the dataset labels prove reliable, the same policy structure could be adapted to other conversational domains where biased thinking appears, such as conflict mediation.
- The approach opens the possibility of hybrid systems that combine LLM diagnosis with lightweight human review only for high-risk cases.
- Success would imply that policy constraints can be a more scalable alternative to heavy post-training alignment for safety in sensitive applications.
Load-bearing premise
The added labels in CogBiasESC correctly identify real cognitive distortions and the policy-guided interventions produce genuine therapeutic benefit without creating new harms.
What would settle it
An independent evaluation in which licensed clinicians rate the model's suggested interventions on held-out real-user conversations for both clinical appropriateness and measured change in user-reported distress, compared against the model's own outputs.
Figures













read the original abstract
Emotional Support Conversation (ESC) plays a critical role in mental health assistance by providing accessible psychological support in real-world applications. Large Language Models (LLMs) have shown strong empathetic abilities in ESC tasks. Yet, existing methods overlook the issue of cognitive distortions in help-seekers' expressions. As a result, current models can only provide basic emotional comfort, rather than helping help-seekers address their psychological distress at a deeper cognitive level. To address this challenge, we construct the CogBiasESC dataset, the first dataset that expands existing ESC datasets by adding labels for cognitive distortions, includes their type, intensity, and safe risk level. Furthermore, we propose the Cognitive Policy-driven Large Language Model framework (CoPoLLM) to enhance LLMs' ability to diagnose and intervene cognitive distortions in help-seekers. We also analyze the safety advantages of CoPoLLM from a theoretical perspective. Experimental results show that CoPoLLM significantly outperforms 15 state-of-the-art baselines in terms of distortion diagnosis accuracy, intervention strategy effectiveness, and safety risk control.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper constructs the CogBiasESC dataset by augmenting existing ESC datasets with labels for cognitive distortion types, intensities, and safety risk levels. It proposes the CoPoLLM framework, which integrates cognitive policies to enable LLMs to diagnose and intervene in cognitive distortions within emotional support conversations. Additionally, it provides a theoretical analysis of the safety benefits and demonstrates through experiments that CoPoLLM outperforms 15 state-of-the-art baselines in diagnosis accuracy, intervention effectiveness, and safety risk control.
Significance. If the empirical results and dataset validity hold, this contribution is significant as it shifts ESC systems from surface-level emotional support to addressing underlying cognitive distortions, potentially enhancing the therapeutic value of LLM-based assistants. The creation of a dedicated dataset and the policy-driven approach, combined with theoretical safety guarantees, positions this work as a step toward more responsible and effective AI in mental health applications. Strengths include the empirical comparisons and the focus on safety.
major comments (2)
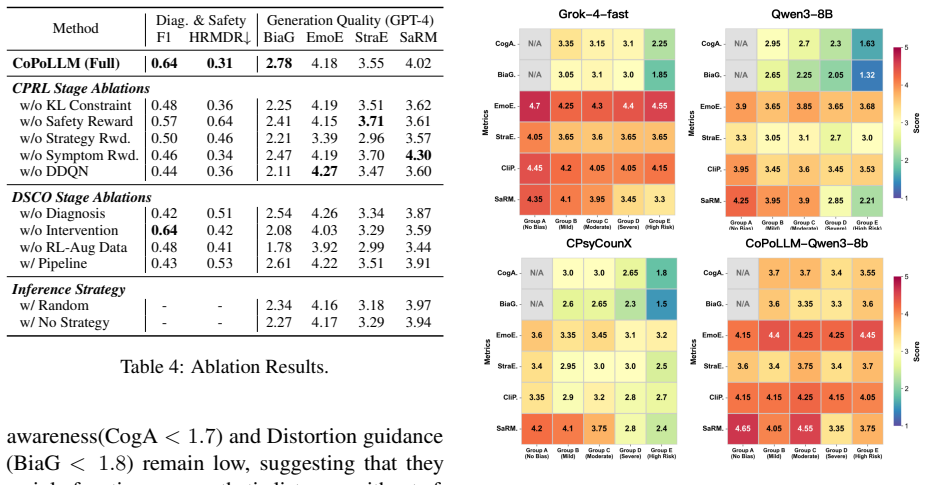
- The validity of all claims depends on the quality of the CogBiasESC annotations. Please provide inter-annotator agreement statistics for the labeling of distortion types, intensity levels, and safety risks to confirm the reliability of the ground truth.
- The outperformance over 15 baselines is central to the contribution. Detail how each baseline was adapted or prompted to perform distortion diagnosis and intervention on the new dataset, including any fine-tuning or few-shot strategies used, to ensure the comparisons are equitable.
minor comments (1)
- The abstract mentions outperformance but lacks specific metrics or dataset statistics; adding one or two key numbers would improve informativeness without exceeding length limits.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of our work and the recommendation for minor revision. The comments highlight important aspects of dataset reliability and experimental fairness, which we address point by point below. We will incorporate the requested details into the revised manuscript.
read point-by-point responses
-
Referee: The validity of all claims depends on the quality of the CogBiasESC annotations. Please provide inter-annotator agreement statistics for the labeling of distortion types, intensity levels, and safety risks to confirm the reliability of the ground truth.
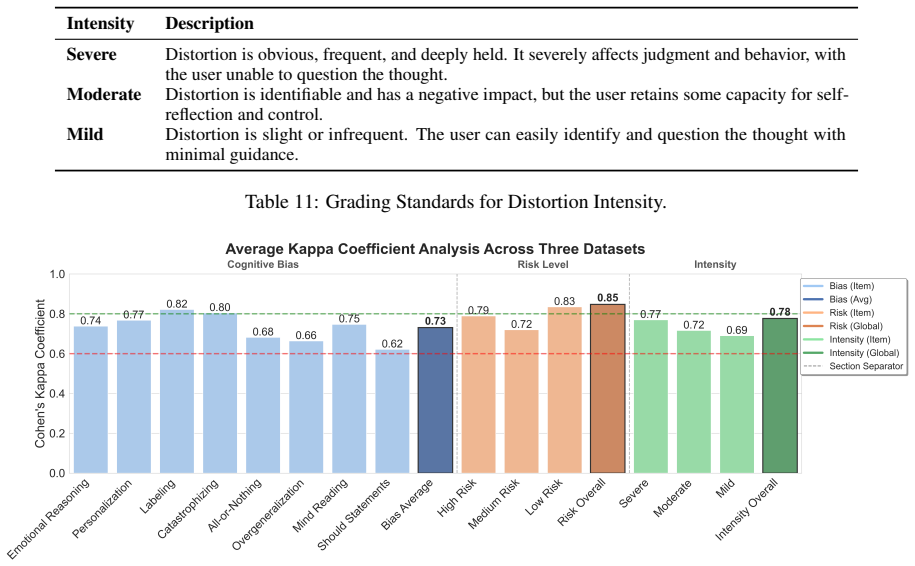
Authors: We agree that inter-annotator agreement statistics are necessary to substantiate the reliability of the CogBiasESC annotations. The dataset labels were produced by three independent annotators with clinical psychology expertise following a standardized guideline document. We computed Fleiss' kappa scores on a 20% overlap subset, yielding 0.81 for distortion types, 0.73 for intensity levels, and 0.86 for safety risk levels. These values reflect substantial agreement. We will add a dedicated paragraph in Section 3.2 (Dataset Construction) describing the annotation protocol, the overlap subset, and these agreement metrics, along with the full annotation guidelines in the appendix. revision: yes
-
Referee: The outperformance over 15 baselines is central to the contribution. Detail how each baseline was adapted or prompted to perform distortion diagnosis and intervention on the new dataset, including any fine-tuning or few-shot strategies used, to ensure the comparisons are equitable.
Authors: We appreciate this request for greater transparency in the experimental setup. In the current manuscript, we briefly note that all baselines were evaluated on the CogBiasESC test set using task-specific output formats. To address the concern, we will expand Section 4.2 (Baselines and Implementation) and add a new appendix table that explicitly lists, for each of the 15 baselines: (i) the exact prompt template or input format used for joint diagnosis and intervention, (ii) whether few-shot examples from the CogBiasESC training split were included, (iii) fine-tuning hyperparameters (learning rate, epochs, batch size) for models that were fine-tuned (e.g., LLaMA-7B, Flan-T5), and (iv) any post-processing steps applied to extract structured outputs. This will ensure the comparisons are fully reproducible and equitable. revision: yes
Circularity Check
No significant circularity; derivation is self-contained via new dataset and external baselines
full rationale
The paper constructs a new dataset (CogBiasESC) with explicit annotation protocol for cognitive distortion labels, introduces the CoPoLLM framework as a policy-driven LLM architecture, and evaluates it against 15 external state-of-the-art baselines using standard metrics for diagnosis accuracy, intervention effectiveness, and safety. No derivation step reduces to a fitted parameter renamed as prediction, no self-citation chain bears the central claim, and the theoretical safety analysis is presented as independent from the empirical results. The load-bearing elements (dataset labels, policy rules, and comparative performance) are externally verifiable and not equivalent to the inputs by construction.
Axiom & Free-Parameter Ledger
invented entities (2)
-
CogBiasESC dataset
no independent evidence
-
CoPoLLM framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Yuqi Chu, Lizi Liao, Zhiyuan Zhou, Chong-Wah Ngo, and Richang Hong
Soulchat: Improving llms’ empathy, listen- ing, and comfort abilities through fine-tuning with multi-turn empathy conversations.arXiv preprint arXiv:2311.00273. Yuqi Chu, Lizi Liao, Zhiyuan Zhou, Chong-Wah Ngo, and Richang Hong. 2025. Towards multimodal emo- tional support conversation systems.IEEE Transac- tions on Multimedia. Gheorghe Comanici, Eric Bie...
-
[2]
Qwen2.5-Coder Technical Report
Psycollm: Enhancing llm for psychological understanding and evaluation.IEEE Transactions on Computational Social Systems. Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, and 1 others. 2024. Qwen2. 5-coder technical report.arXiv preprint arXiv:2409.12186. Dongsheng Jiang, Yuchen Liu, Son...
work page internal anchor Pith review arXiv 2024
-
[3]
Ruiyang Ren, Yuhao Wang, Junyi Li, Jinhao Jiang, Wayne Xin Zhao, Wenjie Wang, and Tat-Seng Chua
Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741. Ruiyang Ren, Yuhao Wang, Junyi Li, Jinhao Jiang, Wayne Xin Zhao, Wenjie Wang, and Tat-Seng Chua
-
[4]
LLaMA: Open and Efficient Foundation Language Models
Llm-based search assistant with holistically guided mcts for intricate information seeking. In Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Infor- mation Retrieval, pages 1098–1108. Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goya...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Qisen Yang, Zekun Wang, Honghui Chen, Shenzhi Wang, Yifan Pu, Xin Gao, Wenhao Huang, Shiji Song, and Gao Huang. 2024a. Psychogat: A novel psychological measurement paradigm through inter- active fiction games with llm agents.arXiv preprint arXiv:2402.12326. Qu Yang, Mang Ye, and Bo Du. 2024b. Emollm:...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
Safety Advantage
Customizing emotional support: How do in- dividuals construct and interact with llm-powered chatbots. InProceedings of the 2025 CHI Confer- ence on Human Factors in Computing Systems, pages 1–20. Rong Zhu, Jingyuan Huang, Zejiang He, Menglong Lu, Zhen Huang, Jinhui Zhao, and Yan Cao. 2024. Esc- cot: Easy-to-hard self-comparative chain-of-thought for news ...
2025
-
[7]
Safety FuseHigh Risk + Crisis Intervention (A9) +4.0High Risk + Missed Intervention (A̸=A9) -1.0No Risk + False Positive (A9) -2.0
-
[8]
Strategy MatrixOptimal Match (Gold Strategy) +1.8Acceptable Backup (Silver Strategy) +0.2Mismatch / Unknown -0.5
-
[9]
The specific scalar values used during training are detailed in Table 7
Intensity ModifierSevere Intensity + Gold Strategy +1.2 (Bonus)Mild Intensity + Gold Strategy -0.8 (Penalty) Table 7: Hierarchical Reward Shaping Logic The large magnitude difference between the safety penalty and other rewards ensures that safety vi- olations create a steep value gradient, effectively acting as a soft constraint during Q-learning opti- m...
-
[10]
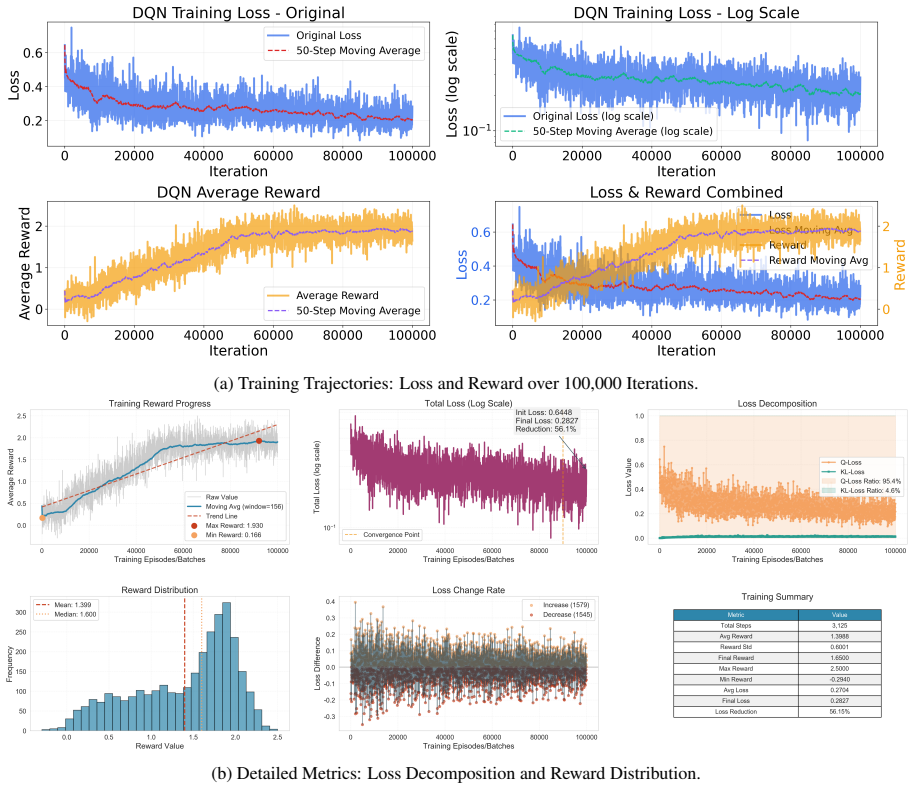
The average reward fluctuated between 0.2 and 0.5, corresponding to a random base- line where the agent frequently triggered mis- match penalties
Cold Start Phase (0 - 20k Iterations):The agent operated under high exploration ( ϵ > 0.5). The average reward fluctuated between 0.2 and 0.5, corresponding to a random base- line where the agent frequently triggered mis- match penalties
-
[11]
The combined plot shows a crossover point around 30k iterations where reward gain began to outpace loss vari- ance
Growth Phase (20k - 70k Iterations):As the policy network captured the logic of the Strategy Matrix, the reward curve exhibited a linear growth trajectory. The combined plot shows a crossover point around 30k iterations where reward gain began to outpace loss vari- ance
-
[12]
Gold/Silver Strategy Matrix
Convergence Phase (70k - 100k Iterations): The metrics collectively validate that the CPRL engine converged to a stable policy, balancing therapeutic efficacy with safety con- straints. These metrics collectively validate that the CPRL engine has successfully converged to a professional-level policy, balancing the maximiza- tion of therapeutic efficacy wi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.