Recognition: unknown
LookasideVLN: Direction-Aware Aerial Vision-and-Language Navigation
Pith reviewed 2026-05-10 07:23 UTC · model grok-4.3
The pith
LookasideVLN shows that directional cues in navigation instructions enable more accurate and efficient aerial path planning than landmark-only approaches.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
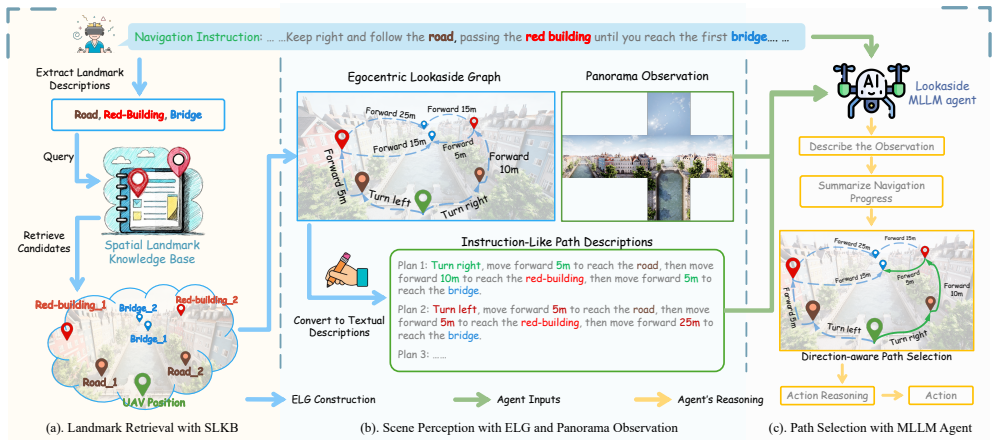
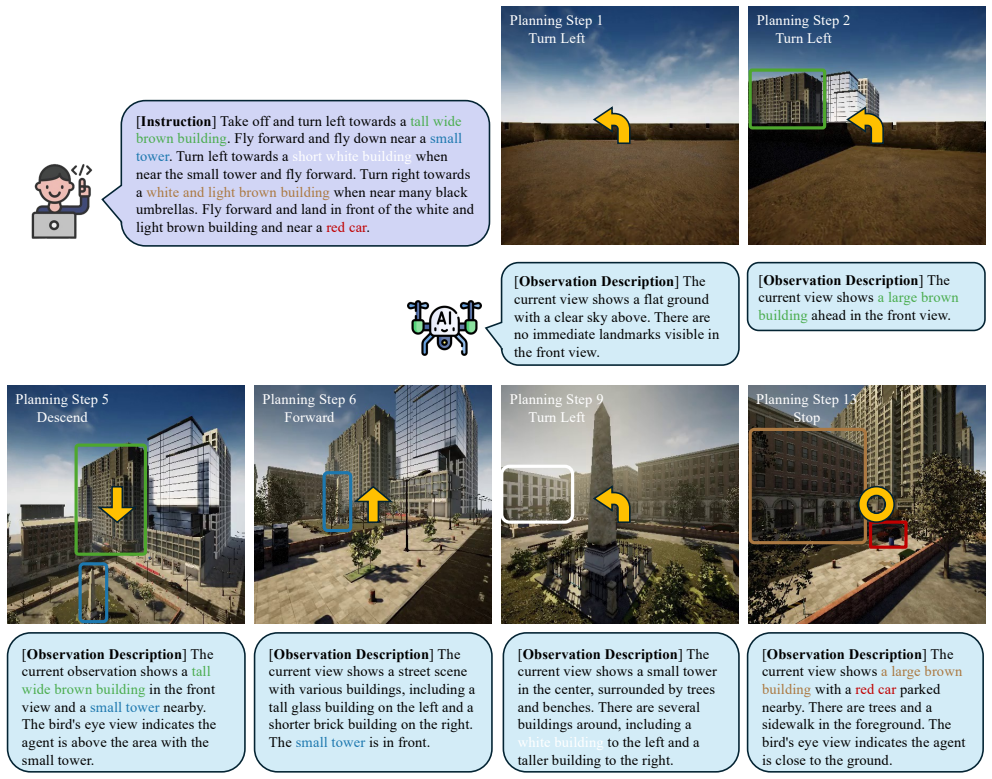
By building an Egocentric Lookaside Graph that encodes instruction-relevant landmarks together with their directional relationships, retrieving from a Spatial Landmark Knowledge Base, and aligning the result with visual input inside a Lookaside MLLM Navigation Agent, LookasideVLN produces more accurate spatial reasoning and lower computational cost than methods limited to landmark descriptions.
What carries the argument
The Egocentric Lookaside Graph (ELG) that dynamically encodes landmarks and directional relationships from instructions, supported by the Spatial Landmark Knowledge Base (SLKB) for memory retrieval and the Lookaside MLLM agent for multimodal alignment.
If this is right
- Aerial VLN success rates can rise while lookahead depth stays minimal.
- Navigation agents can operate with smaller memory graphs when directional information is explicitly modeled.
- Urban UAV tasks become feasible with lighter onboard computation by reusing prior landmark-direction pairs.
- Multimodal agents gain a direct mechanism to ground language directions against current camera views.
Where Pith is reading between the lines
- The same directional encoding pattern could transfer to ground-based or underwater VLN without major redesign.
- Real-time updates to the ELG might allow the system to handle instruction changes mid-flight.
- If the SLKB scales across many flights, cumulative efficiency gains could compound for fleet-level operations.
Load-bearing premise
Natural language directional cues can be parsed reliably enough to be encoded, retrieved, and aligned with visuals without adding substantial new errors or compute overhead.
What would settle it
A controlled test on the same Aerial VLN benchmarks where LookasideVLN with single-level lookahead shows no improvement or higher cost than CityNavAgent would falsify the central claim.
Figures






read the original abstract
Aerial Vision-and-Language Navigation (Aerial VLN) enables unmanned aerial vehicles (UAVs) to follow natural language instructions and navigate complex urban environments. While recent advances have achieved progress through large-scale memory graphs and lookahead path planning, they remain limited by shallow instruction understanding and high computational cost. In particular, existing methods rely primarily on landmark descriptions, overlooking directional cues "a key source of spatial context in human navigation". In this work, we propose LookasideVLN, a new paradigm that exploits directional cues in natural language to achieve both more accurate spatial reasoning and greater computational efficiency. LookasideVLN comprises three core components: (1) an Egocentric Lookaside Graph (ELG) that dynamically encodes instruction-relevant landmarks and their directional relationships, (2) a Spatial Landmark Knowledge Base (SLKB) that provides lightweight memory retrieval from prior navigation experiences, and (3) a Lookaside MLLM Navigation Agent that aligns multimodal information from user instructions, visual observations, and landmark-direction information from ELG for path planning. Extensive experiments show that LookasideVLN significantly outperforms the state-of-the-art CityNavAgent, even with a single-level lookahead, demonstrating that leveraging directional cues is a powerful yet efficient strategy for Aerial VLN.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes LookasideVLN for aerial vision-and-language navigation. It introduces an Egocentric Lookaside Graph (ELG) to dynamically encode instruction-relevant landmarks and their directional relationships, a Spatial Landmark Knowledge Base (SLKB) for lightweight retrieval from prior experiences, and a Lookaside MLLM Navigation Agent that aligns instructions, visual observations, and ELG landmark-direction information for path planning. The central claim, stated in the abstract, is that this direction-aware paradigm significantly outperforms the state-of-the-art CityNavAgent even with single-level lookahead, demonstrating that directional cues supply overlooked spatial context for more accurate and efficient Aerial VLN.
Significance. If the empirical results hold after proper controls, the work would usefully shift emphasis in Aerial VLN from landmark-only or heavy lookahead planning toward explicit directional encoding. The ELG and SLKB construction offers a lightweight, modular alternative to large-scale memory graphs while remaining compatible with existing MLLM agents. This could improve both accuracy and computational cost in UAV navigation tasks.
major comments (2)
- [Abstract / Experiments] Abstract and Experiments section: the central claim of significant outperformance over CityNavAgent (even at single-level lookahead) is asserted without any reported metrics, baselines, statistical tests, or ablation tables. This absence makes it impossible to evaluate whether the headline result is supported by the data.
- [Method / Experiments] Method (ELG, SLKB, and Lookaside MLLM Agent) and Experiments: the three novel components are introduced and evaluated jointly. No ablation isolates the contribution of directional encoding within the ELG from the effects of the dynamic graph construction, SLKB retrieval, or MLLM pipeline as a whole. Because the abstract attributes gains specifically to 'leveraging directional cues,' this missing control is load-bearing for the main conclusion.
minor comments (2)
- [Abstract] The abstract states that existing methods 'rely primarily on landmark descriptions' but does not cite the specific prior works or quantify the claimed limitation; adding 1-2 targeted references would strengthen the motivation.
- [Method] Notation for the ELG (e.g., how directional relationships are formally represented and updated) could be clarified with a small example or pseudocode to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which have helped us identify areas for improvement in the manuscript. We address the major comments below and will make the necessary revisions.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the central claim of significant outperformance over CityNavAgent (even at single-level lookahead) is asserted without any reported metrics, baselines, statistical tests, or ablation tables. This absence makes it impossible to evaluate whether the headline result is supported by the data.
Authors: We agree with this observation. The current version of the manuscript asserts the outperformance in the abstract and describes the experiments but does not include the specific numerical results, baselines, or statistical tests in a way that allows direct evaluation. In the revised manuscript, we will update the abstract to include key metrics (e.g., success rate improvements) and ensure the Experiments section features comprehensive tables with all baselines, metrics, and any statistical analyses performed. revision: yes
-
Referee: [Method / Experiments] Method (ELG, SLKB, and Lookaside MLLM Agent) and Experiments: the three novel components are introduced and evaluated jointly. No ablation isolates the contribution of directional encoding within the ELG from the effects of the dynamic graph construction, SLKB retrieval, or MLLM pipeline as a whole. Because the abstract attributes gains specifically to 'leveraging directional cues,' this missing control is load-bearing for the main conclusion.
Authors: This is a valid point. The manuscript evaluates the complete LookasideVLN system without separate ablations for the directional encoding in ELG. To address this, we will conduct and include an ablation study in the revised version that specifically removes or modifies the directional cue components in the ELG while controlling for the other elements. This will allow us to isolate and quantify the contribution of directional cues as claimed. revision: yes
Circularity Check
No significant circularity; new architecture is additive empirical construction without self-referential reductions.
full rationale
The paper proposes LookasideVLN as a new paradigm with three explicitly constructed components (ELG for encoding landmarks and directions, SLKB for retrieval, MLLM agent for alignment) motivated by the observation that prior work overlooks directional cues. The central claim is empirical outperformance over CityNavAgent even at single-level lookahead. No equations, fitted parameters renamed as predictions, self-definitional loops, uniqueness theorems imported via self-citation, or ansatz smuggling appear in the provided text. The directional encoding is presented as an additive design choice rather than derived from or equivalent to the inputs by construction. The derivation chain remains self-contained as a standard VLN extension with novel but independently motivated modules.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Natural language instructions contain parseable directional cues that supply useful spatial context for navigation.
- domain assumption Visual observations can be reliably aligned with landmark-direction information from the ELG inside the MLLM agent.
invented entities (3)
-
Egocentric Lookaside Graph (ELG)
no independent evidence
-
Spatial Landmark Knowledge Base (SLKB)
no independent evidence
-
Lookaside MLLM Navigation Agent
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ah- mad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Vision-and-language navigation: In- terpreting visually-grounded navigation instructions in real environments
Peter Anderson, Qi Wu, Damien Teney, Jake Bruce, Mark Johnson, Niko S ¨underhauf, Ian Reid, Stephen Gould, and Anton Van Den Hengel. Vision-and-language navigation: In- terpreting visually-grounded navigation instructions in real environments. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3674–3683,
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhao- hai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Jun- yang Lin. Qwen2.5-vl technical repor...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Enhancing large language models with rag for visual language navigation in continuous environments.Electronics, 14(5):909, 2025
Xiaoan Bao, Zhiqiang Lv, and Biao Wu. Enhancing large language models with rag for visual language navigation in continuous environments.Electronics, 14(5):909, 2025. 3
2025
-
[5]
Meghan Booker, Grayson Byrd, Bethany Kemp, Aurora Schmidt, and Corban Rivera. Embodiedrag: Dynamic 3d scene graph retrieval for efficient and scalable robot task planning.arXiv preprint arXiv:2410.23968, 2024. 3
-
[6]
Yue Cao and CS Lee. Robot behavior-tree-based task generation with large language models.arXiv preprint arXiv:2302.12927, 2023. 3
-
[7]
Jiaqi Chen, Bingqian Lin, Ran Xu, Zhenhua Chai, Xi- aodan Liang, and Kwan-Yee K. Wong. Mapgpt: Map- guided prompting with adaptive path planning for vision- and-language navigation. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics,
-
[8]
History aware multimodal transformer for vision-and-language navigation.Advances in neural infor- mation processing systems, 34:5834–5847, 2021
Shizhe Chen, Pierre-Louis Guhur, Cordelia Schmid, and Ivan Laptev. History aware multimodal transformer for vision-and-language navigation.Advances in neural infor- mation processing systems, 34:5834–5847, 2021. 1, 2
2021
-
[9]
Think global, act lo- cal: Dual-scale graph transformer for vision-and-language navigation
Shizhe Chen, Pierre-Louis Guhur, Makarand Tapaswi, Cordelia Schmid, and Ivan Laptev. Think global, act lo- cal: Dual-scale graph transformer for vision-and-language navigation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16537– 16547, 2022. 1, 2
2022
-
[10]
Yongchao Chen, Jacob Arkin, Yang Zhang, Nicholas Roy, and Chuchu Fan. Scalable multi-robot collaboration with large language models: Centralized or decentralized sys- tems? In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 4311–4317. IEEE, 2024. 3
2024
-
[11]
Towards a unified agent with foundation models.arXiv preprint arXiv:2307.09668, 2023
Norman Di Palo, Arunkumar Byravan, Leonard Hasenclever, Markus Wulfmeier, Nicolas Heess, and Martin Riedmiller. Towards a unified agent with foundation models.arXiv preprint arXiv:2307.09668, 2023. 3
-
[12]
Aerial vision-and-dialog nav- igation.arXiv preprint arXiv:2205.12219, 2022
Yue Fan, Winson Chen, Tongzhou Jiang, Chun Zhou, Yi Zhang, and Xin Eric Wang. Aerial vision-and-dialog nav- igation.arXiv preprint arXiv:2205.12219, 2022. 1
-
[13]
Speaker-follower models for vision-and-language naviga- tion.Advances in neural information processing systems, 31, 2018
Daniel Fried, Ronghang Hu, V olkan Cirik, Anna Rohrbach, Jacob Andreas, Louis-Philippe Morency, Taylor Berg- Kirkpatrick, Kate Saenko, Dan Klein, and Trevor Darrell. Speaker-follower models for vision-and-language naviga- tion.Advances in neural information processing systems, 31, 2018. 2
2018
-
[14]
Yunpeng Gao, Zhigang Wang, Linglin Jing, Dong Wang, Xuelong Li, and Bin Zhao. Aerial vision-and-language nav- igation via semantic-topo-metric representation guided llm reasoning.arXiv preprint arXiv:2410.08500, 2024. 3, 6
-
[15]
Openfly: A versatile toolchain and large-scale benchmark for aerial vision-language navi- gation.arXiv e-prints, pages arXiv–2502, 2025
Yunpeng Gao, Chenhui Li, Zhongrui You, Junli Liu, Zhen Li, Pengan Chen, Qizhi Chen, Zhonghan Tang, Liansheng Wang, Penghui Yang, et al. Openfly: A versatile toolchain and large-scale benchmark for aerial vision-language navi- gation.arXiv e-prints, pages arXiv–2502, 2025. 1
2025
-
[16]
Airbert: In-domain pretrain- ing for vision-and-language navigation
Pierre-Louis Guhur, Makarand Tapaswi, Shizhe Chen, Ivan Laptev, and Cordelia Schmid. Airbert: In-domain pretrain- ing for vision-and-language navigation. InProceedings of the IEEE/CVF international conference on computer vision, pages 1634–1643, 2021. 2
2021
-
[17]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Vln bert: A recurrent vision- and-language bert for navigation
Yicong Hong, Qi Wu, Yuankai Qi, Cristian Rodriguez- Opazo, and Stephen Gould. Vln bert: A recurrent vision- and-language bert for navigation. InProceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, pages 1643–1653, 2021. 2
2021
-
[19]
A new path: Scaling vision- and-language navigation with synthetic instructions and imi- tation learning
Aishwarya Kamath, Peter Anderson, Su Wang, Jing Yu Koh, Alexander Ku, Austin Waters, Yinfei Yang, Jason Baldridge, and Zarana Parekh. A new path: Scaling vision- and-language navigation with synthetic instructions and imi- tation learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10813– 10823, 2023. 2
2023
-
[20]
Smart-llm: Smart multi-agent robot task planning using large language models
Shyam Sundar Kannan, Vishnunandan LN Venkatesh, and Byung-Cheol Min. Smart-llm: Smart multi-agent robot task planning using large language models. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 12140–12147. IEEE, 2024. 3
2024
-
[21]
Beyond the nav-graph: Vision-and-language navigation in continuous environments
Jacob Krantz, Erik Wijmans, Arjun Majumdar, Dhruv Batra, and Stefan Lee. Beyond the nav-graph: Vision-and-language navigation in continuous environments. InEuropean Confer- ence on Computer Vision, pages 104–120. Springer, 2020. 2, 6 9
2020
-
[22]
Visual genome: Connecting language and vision using crowdsourced dense image annotations.International journal of computer vision, 123(1):32–73, 2017
Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalan- tidis, Li-Jia Li, David A Shamma, et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations.International journal of computer vision, 123(1):32–73, 2017. 3
2017
-
[23]
Jungdae Lee, Taiki Miyanishi, Shuhei Kurita, Koya Sakamoto, Daichi Azuma, Yutaka Matsuo, and Naka- masa Inoue. Citynav: Language-goal aerial naviga- tion dataset with geographic information.arXiv preprint arXiv:2406.14240, 2024. 1
-
[24]
Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K¨uttler, Mike Lewis, Wen-tau Yih, Tim Rockt ¨aschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020. 3
2020
-
[25]
Kerm: Knowledge enhanced reason- ing for vision-and-language navigation
Xiangyang Li, Zihan Wang, Jiahao Yang, Yaowei Wang, and Shuqiang Jiang. Kerm: Knowledge enhanced reason- ing for vision-and-language navigation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2583–2592, 2023. 1, 2, 3
2023
-
[26]
Towards General Text Embeddings with Multi-stage Contrastive Learning
Zehan Li, Xin Zhang, Yanzhao Zhang, Dingkun Long, Pengjun Xie, and Meishan Zhang. Towards general text embeddings with multi-stage contrastive learning.arXiv preprint arXiv:2308.03281, 2023. 4
work page internal anchor Pith review arXiv 2023
-
[27]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26296–26306, 2024. 8
2024
-
[28]
V olumetric environ- ment representation for vision-language navigation
Rui Liu, Wenguan Wang, and Yi Yang. V olumetric environ- ment representation for vision-language navigation. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16317–16328, 2024. 2
2024
-
[29]
Aerialvln: Vision-and-language navigation for uavs
Shubo Liu, Hongsheng Zhang, Yuankai Qi, Peng Wang, Yan- ning Zhang, and Qi Wu. Aerialvln: Vision-and-language navigation for uavs. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision, pages 15384– 15394, 2023. 1, 2, 6
2023
-
[30]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. In European Conference on Computer Vision, pages 38–55. Springer, 2024. 3
2024
-
[31]
Qwen2.5 technical report, 2025
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Jun- yang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao L...
2025
-
[32]
Sonia Raychaudhuri, Saim Wani, Shivansh Patel, Unnat Jain, and Angel X Chang. Language-aligned waypoint (law) su- pervision for vision-and-language navigation in continuous environments.arXiv preprint arXiv:2109.15207, 2021. 2
-
[33]
Lm- nav: Robotic navigation with large pre-trained models of lan- guage, vision, and action
Dhruv Shah, Bła ˙zej Osi ´nski, Sergey Levine, et al. Lm- nav: Robotic navigation with large pre-trained models of lan- guage, vision, and action. InConference on robot learning, pages 492–504. PMLR, 2023. 2, 3, 4, 5
2023
-
[34]
Towards long-horizon vision- language navigation: Platform, benchmark and method
Xinshuai Song, Weixing Chen, Yang Liu, Weikai Chen, Guanbin Li, and Liang Lin. Towards long-horizon vision- language navigation: Platform, benchmark and method. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 12078–12088, 2025. 3
2025
-
[35]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth´ee Lacroix, Baptiste Rozi`ere, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
Xiangyu Wang, Donglin Yang, Ziqin Wang, Hohin Kwan, Jinyu Chen, Wenjun Wu, Hongsheng Li, Yue Liao, and Si Liu. Towards realistic uav vision-language navigation: Platform, benchmark, and methodology.arXiv preprint arXiv:2410.07087, 2024. 1
-
[37]
Rag-driver: Generalisable driving explanations with retrieval-augmented in-context multi-modal large language model learning
Jianhao Yuan, Shuyang Sun, Daniel Omeiza, Bo Zhao, Paul Newman, Lars Kunze, and Matthew Gadd. Rag-driver: Generalisable driving explanations with retrieval-augmented in-context multi-modal large language model learning. In Robotics: Science and Systems, 2024. 3
2024
-
[38]
Mg-vln: Benchmarking multi-goal and long-horizon vision-language navigation with language enhanced memory map
Junbo Zhang and Kaisheng Ma. Mg-vln: Benchmarking multi-goal and long-horizon vision-language navigation with language enhanced memory map. In2024 IEEE/RSJ In- ternational Conference on Intelligent Robots and Systems (IROS), pages 7750–7757. IEEE, 2024. 1
2024
-
[39]
CityNavAgent: Aerial vision-and-language naviga- tion with hierarchical semantic planning and global memory
Weichen Zhang, Chen Gao, Shiquan Yu, Ruiying Peng, Baining Zhao, Qian Zhang, Jinqiang Cui, Xinlei Chen, and Yong Li. CityNavAgent: Aerial vision-and-language naviga- tion with hierarchical semantic planning and global memory. InProceedings of the 63rd Annual Meeting of the Associa- tion for Computational Linguistics (Volume 1: Long Papers), pages 31292–31...
2025
-
[40]
Aerial vision-and-language navigation with grid-based view selection and map construction,
Ganlong Zhao, Guanbin Li, Jia Pan, and Yizhou Yu. Aerial vision-and-language navigation with grid-based view selec- tion and map construction.arXiv preprint arXiv:2503.11091,
-
[41]
Navgemini: a multi-modal llm agent for vision-and-language navigation
Ganlong Zhao, Guanbin Li, and Yizhou Yu. Navgemini: a multi-modal llm agent for vision-and-language navigation. Visual Intelligence, 4(1):1, 2026. 3
2026
-
[42]
Chat with the envi- ronment: Interactive multimodal perception using large lan- guage models
Xufeng Zhao, Mengdi Li, Cornelius Weber, Muham- mad Burhan Hafez, and Stefan Wermter. Chat with the envi- ronment: Interactive multimodal perception using large lan- guage models. In2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 3590–3596. IEEE, 2023. 3
2023
-
[43]
Navgpt: Explicit reasoning in vision-and-language navigation with large lan- guage models
Gengze Zhou, Yicong Hong, and Qi Wu. Navgpt: Explicit reasoning in vision-and-language navigation with large lan- guage models. InProceedings of the AAAI Conference on Artificial Intelligence, pages 7641–7649, 2024. 6 10 LookasideVLN: Direction-Aware Aerial Vision-and-Language Navigation Supplementary Material
2024
-
[44]
red brick water tower
Spatial Landmark Knowledge Base 1.1. Landmark Recognizer The Landmark Recognizer aims to identify visible land- marks present in historical observations. To this end, we leverage the strong image captioning capabilities of mul- timodal large language models to generate landmark de- scriptions from RGB observations. Specifically, we use Qwen-VL-Max [3] to ...
-
[45]
To address this, we adopt a prun- ing strategy to eliminate redundant nodes and edges in the ELG
Pruning Strategy for ELG Since large-scale urban scenes often contain many visu- ally similar landmark instances that can be grounded by the same landmark description, traversing the entire graph can lead to redundancy. To address this, we adopt a prun- ing strategy to eliminate redundant nodes and edges in the ELG. Specifically, given the ordered set of ...
-
[46]
Next Two Landmarks: A and B. Instruction Snippet:Turn left at A, then move forward to B
Implementation of the Lookaside MLLM Navigation Agent We build the agent with a chain-of-thought mechanism for robust and explainable path planning. Specifically, we de- sign three types of prompts to handle different situations the agent may encounter during navigation: 1)When the Egocentric Lookaside Graph (ELG) is available, the agent selects a navigat...
-
[47]
turn slightly left
More Experiment Results 4.1. Additional MLLM ablations. We add GPT-series and Qwen3VL as MLLM backbones in Tab. 6. We note that Qwen2.5VL-32B is specifically 3 Table 6. Additional ablation study on different MLLMs. Category Method SR↑SDTW↑NE↓ Qwens Qwen-2.5-VL-7B 9.0 1.7 306.6 Qwen-3-VL-8B 11.7 3.8 114.1 Qwen-2.5-VL-32B 14.1 4.9 94.3 Qwen-3-VL-32B 11.7 5....
-
[48]
Future work may focus on bridging the sim-to-real gap and evaluating the system on real UA Vs
Limitations and Future Work Although LookasideVLN achieves state-of-the-art perfor- mance in the simulated environment, it has not yet been deployed in the real world. Future work may focus on bridging the sim-to-real gap and evaluating the system on real UA Vs. Additionally, improving robustness under real- world conditions will be an important direction...
-
[49]
Learning-based baselines are constrained by the scarcity of annotated trajectories and the limited scale of training scenes. While they can perform accurate action selection (at each step) during end-to-end training, they tend to accumulate errors (over the entire navigation process) in evaluation and struggle to generalize to unseen environ- ments. This ...
-
[50]
slightly left
Zero-shot LLM-based approaches are strong in under- standing natural language instructions and visual obser- vations. However, they struggle to comprehend struc- tured 3D scenes when relying solely on language and RGB inputs, lacking access to fine-grained 3D infor- mation such as depth cues. They also face chal- lenges in ego-motion understanding—often m...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.