Recognition: unknown
Do LLM-derived graph priors improve multi-agent coordination?
Pith reviewed 2026-05-10 06:05 UTC · model grok-4.3
The pith
LLM-generated coordination graph priors improve performance in multi-agent reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
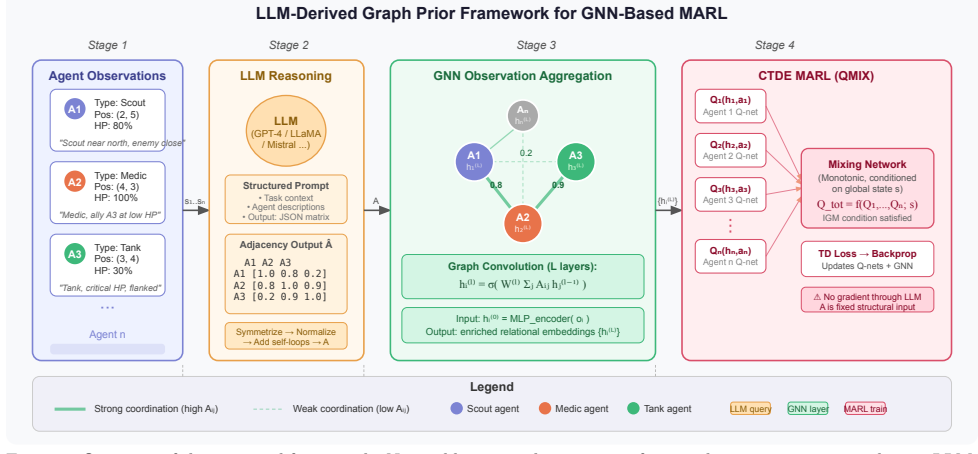
LLM-derived graph priors, obtained by prompting models with minimal natural language descriptions of agent observations, can be integrated via graph convolutional layers into GNN-based MARL pipelines to yield measurable improvements in coordination and adaptability over baselines that either ignore graph structure, use proximity heuristics, or learn structure entirely from interaction data, with models as small as 1.5B parameters proving sufficient on the tested MPE scenarios.
What carries the argument
LLM-generated coordination graph priors embedded through graph convolutional layers within a GNN-based MARL training pipeline
If this is right
- MARL systems can incorporate semantic coordination knowledge without requiring hand-specified topologies or exhaustive interaction-based learning.
- Effective priors become accessible using compact open-source LLMs rather than only the largest models.
- Dynamic multi-agent environments gain improved adaptability when initial graph structure carries inferred interaction semantics.
- The four evaluated MPE scenarios demonstrate consistent quantitative benefits across independent learners, proximity-based graphs, and state-of-the-art learned-graph methods.
Where Pith is reading between the lines
- The same prior-generation step could lower sample complexity in MARL by supplying an informed starting structure before environment interaction begins.
- The technique may extend beyond cooperative particle tasks to domains such as swarm robotics or distributed sensor networks where agent roles have latent semantic relationships.
- Pairing LLM priors with continued online graph adaptation could address settings where coordination patterns shift more rapidly than the initial inference captures.
Load-bearing premise
Large language models can reliably infer latent, semantically meaningful coordination patterns from minimal natural language descriptions of agent observations that transfer usefully into MARL training.
What would settle it
If the same MARL training runs on the four MPE cooperative scenarios produce no performance gain or show degradation when using the LLM-derived graph priors compared with the full set of baselines, the claim of enhancement would be falsified.
Figures

read the original abstract
Multi-agent reinforcement learning (MARL) is crucial for AI systems that operate collaboratively in distributed and adversarial settings, particularly in multi-domain operations (MDO). A central challenge in cooperative MARL is determining how agents should coordinate: existing approaches must either hand-specify graph topology, rely on proximity-based heuristics, or learn structure entirely from environment interaction; all of which are brittle, semantically uninformed, or data-intensive. We investigate whether large language models (LLMs) can generate useful coordination graph priors for MARL by using minimal natural language descriptions of agent observations to infer latent coordination patterns. These priors are integrated into MARL algorithms via graph convolutional layers within a graph neural network (GNN)-based pipeline, and evaluated on four cooperative scenarios from the Multi-Agent Particle Environment (MPE) benchmark against baselines spanning the full spectrum of coordination modeling, from independent learners to state-of-the-art graph-based methods. We further ablate across five compact open-source LLMs to assess the sensitivity of prior quality to model choice. Our results provide the first quantitative evidence that LLM-derived graph priors can enhance coordination and adaptability in dynamic multi-agent environments, and demonstrate that models as small as 1.5B parameters are sufficient for effective prior generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes using LLMs to generate coordination graph priors from minimal natural-language descriptions of agent observations in multi-agent reinforcement learning (MARL). These priors are inserted as adjacency matrices into GNN layers within a GNN-MARL pipeline and evaluated on four cooperative MPE scenarios against baselines ranging from independent learners to existing graph-based MARL methods. The authors also ablate across five compact open-source LLMs (down to 1.5B parameters) and claim the first quantitative evidence that such LLM-derived priors improve coordination and adaptability.
Significance. If the central claim holds after proper controls, the work would offer a practical route to injecting semantic coordination knowledge into MARL without hand-crafted topologies or purely data-driven structure learning, which could be valuable for dynamic multi-domain operations. The ablation across small LLMs is a positive feature that broadens accessibility. However, the current evidence base is too preliminary to assess whether the approach genuinely advances the state of the art.
major comments (2)
- [Experimental evaluation / Results] The experimental design does not isolate the semantic contribution of the LLM-derived graphs. The evaluation (described in the results and experimental setup) compares only against independent learners and prior graph-based MARL methods; no control conditions are reported that replace the LLM adjacency matrix with a random graph of matched density, a proximity heuristic, or a fixed complete graph while keeping the GNN-MARL training pipeline identical. Without these, any observed gains could be explained by the mere presence of a static graph bias rather than by the latent coordination patterns inferred by the LLM.
- [Abstract and Methods] The abstract and methods description provide no information on statistical significance testing, number of random seeds, exact hyperparameter matching across baselines, or whether graph construction involved any post-hoc selection. These omissions make it impossible to determine whether the reported improvements are robust or could be artifacts of experimental choices.
minor comments (2)
- [Methods] Notation for the LLM-to-graph mapping and the precise integration of the adjacency matrix into the GNN layers should be formalized with equations rather than prose descriptions.
- [Ablation study] The paper should include a table or figure explicitly listing the five LLMs tested, their parameter counts, and the exact prompt templates used for prior generation.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments identify key areas where additional controls and reporting details will strengthen the manuscript. We address each major comment below and commit to the corresponding revisions.
read point-by-point responses
-
Referee: [Experimental evaluation / Results] The experimental design does not isolate the semantic contribution of the LLM-derived graphs. The evaluation (described in the results and experimental setup) compares only against independent learners and prior graph-based MARL methods; no control conditions are reported that replace the LLM adjacency matrix with a random graph of matched density, a proximity heuristic, or a fixed complete graph while keeping the GNN-MARL training pipeline identical. Without these, any observed gains could be explained by the mere presence of a static graph bias rather than by the latent coordination patterns inferred by the LLM.
Authors: We agree that the current experiments do not fully isolate the semantic contribution of the LLM-derived priors from the general effect of introducing graph structure. In the revised manuscript we will add the requested control conditions: random graphs of matched density, proximity-based heuristics, and fixed complete graphs, all inserted into the identical GNN-MARL training pipeline. These new results will be reported alongside the existing baselines and discussed in the experimental evaluation section to show whether performance gains are attributable to the coordination patterns inferred by the LLM. revision: yes
-
Referee: [Abstract and Methods] The abstract and methods description provide no information on statistical significance testing, number of random seeds, exact hyperparameter matching across baselines, or whether graph construction involved any post-hoc selection. These omissions make it impossible to determine whether the reported improvements are robust or could be artifacts of experimental choices.
Authors: We acknowledge that these details are missing from the current manuscript. In the revision we will expand the methods and experimental setup sections (and the abstract where space allows) to report: the statistical significance testing performed (including means, standard deviations, and any hypothesis tests), the number of random seeds used for all runs, explicit confirmation that hyperparameters were matched exactly across baselines and our method, and a statement that LLM graph construction involved no post-hoc selection or filtering. These additions will make the robustness of the results transparent. revision: yes
Circularity Check
No derivation chain present; empirical pipeline uses external LLM outputs without self-referential reduction.
full rationale
The paper describes an empirical pipeline that feeds LLM-generated adjacency matrices into a GNN-MARL architecture and evaluates performance on MPE benchmarks against standard baselines. No equations, parameter fittings, or mathematical derivations are referenced in the provided text that could reduce the claimed result to its inputs by construction. The central claim rests on experimental comparisons rather than any self-definitional, fitted-prediction, or self-citation load-bearing step, rendering the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Swarms of unmanned aerial vehicles—a survey,
Tahir, A., Böling, J., Haghbayan, M.-H., Toivonen, H. T., and Plosila, J., “Swarms of unmanned aerial vehicles—a survey,” Journal of Industrial Information Integration 16, 100106 (2019)
2019
-
[2]
Uav swarms: research, challenges, and future directions,
Alqudsi, Y. and Makaraci, M., “Uav swarms: research, challenges, and future directions,” Journal of Engi- neering and Applied Science 72(1), 12 (2025)
2025
-
[3]
Optimizing warehouse operations with autonomous mobile robots,
Zhen, L., Tan, Z., de Koster, R., He, X., Wang, S., and Wang, H., “Optimizing warehouse operations with autonomous mobile robots,” Transportation Science (2025)
2025
-
[4]
Review of autonomous mobile robots for the warehouse environment,
Keith, R. and La, H. M., “Review of autonomous mobile robots for the warehouse environment,” arXiv preprint arXiv:2406.08333 (2024)
-
[5]
Multi-agent reinforcement learning for coordinating communication and control,
Mason, F., Chiariotti, F., Zanella, A., and Popovski, P., “Multi-agent reinforcement learning for coordinating communication and control,” IEEE Transactions on Cognitive Communications and Networking 10(4), 1566–1581 (2024)
2024
-
[6]
A framework for dynamic situational awareness in human robot teams: An interview study,
Senaratne, H., Tian, L., Sikka, P., Williams, J., Howard, D., Kulić, D., and Paris, C., “A framework for dynamic situational awareness in human robot teams: An interview study,” ACM Transactions on Human- Robot Interaction (2025)
2025
-
[7]
Accelerating multi-domain operations,
Townsend, S. J., “Accelerating multi-domain operations,” Military Review , 4–7 (2018)
2018
-
[8]
Multi-domain operations at division and below,
Skates, J. L., “Multi-domain operations at division and below,” Military Review 101(1), 68–76 (2021)
2021
-
[9]
Multi-domain battle: new doctrine of the united states armed forces,
Wójtowicz, T. and Król, D., “Multi-domain battle: new doctrine of the united states armed forces,” Zeszyty Naukowe Akademii Sztuki Wojennej (3 (112), 64–78 (2018)
2018
-
[10]
The complexity of decentralized control of markov decision processes,
Bernstein, D. S., Givan, R., Immerman, N., and Zilberstein, S., “The complexity of decentralized control of markov decision processes,” Mathematics of operations research 27(4), 819–840 (2002)
2002
-
[11]
A., Amato, C., et al., [ A concise introduction to decentralized POMDPs ], vol
Oliehoek, F. A., Amato, C., et al., [ A concise introduction to decentralized POMDPs ], vol. 1, Springer (2016)
2016
-
[12]
Multi-agent reinforcement learning: Independent vs. cooperative agents,
Tan, M., “Multi-agent reinforcement learning: Independent vs. cooperative agents,” in [ Proceedings of the tenth international conference on machine learning ], 330–337 (1993)
1993
-
[13]
Multi-agent reinforcement learning: A selective overview of theories and algorithms,
Zhang, K., Yang, Z., and Başar, T., “Multi-agent reinforcement learning: A selective overview of theories and algorithms,” Handbook of reinforcement learning and control , 321–384 (2021)
2021
-
[14]
A review of cooperative multi-agent deep reinforcement learning,
Oroojlooy, A. and Hajinezhad, D., “A review of cooperative multi-agent deep reinforcement learning,” Applied Intelligence 53(11), 13677–13722 (2023)
2023
-
[15]
Multi-agent reinforcement learning as a rehearsal for decentralized planning,
Kraemer, L. and Banerjee, B., “Multi-agent reinforcement learning as a rehearsal for decentralized planning,” Neurocomputing 190, 82–94 (2016)
2016
-
[16]
arXiv preprint arXiv:2409.03052 , year=
Amato, C., “An introduction to centralized training for decentralized execution in cooperative multi-agent reinforcement learning,” arXiv preprint arXiv:2409.03052 (2024)
-
[17]
Value-Decomposition Networks For Cooperative Multi-Agent Learning
Sunehag, P., Lever, G., Gruslys, A., Czarnecki, W. M., Zambaldi, V., Jaderberg, M., Lanctot, M., Sonnerat, N., Leibo, J. Z., Tuyls, K., et al., “Value-decomposition networks for cooperative multi-agent learning,” arXiv preprint arXiv:1706.05296 (2017)
work page Pith review arXiv 2017
-
[18]
Monotonic value function factorisation for deep multi-agent reinforcement learning,
Rashid, T., Samvelyan, M., De Witt, C. S., Farquhar, G., Foerster, J., and Whiteson, S., “Monotonic value function factorisation for deep multi-agent reinforcement learning,” Journal of Machine Learning Research 21(178), 1–51 (2020)
2020
-
[19]
Qtran: Learning to factorize with transforma- tion for cooperative multi-agent reinforcement learning,
Son, K., Kim, D., Kang, W. J., Hostallero, D. E., and Yi, Y., “Qtran: Learning to factorize with transforma- tion for cooperative multi-agent reinforcement learning,” in [ International conference on machine learning ], 5887–5896, PMLR (2019)
2019
-
[20]
arXiv preprint arXiv:2008.01062 , year=
Wang, J., Ren, Z., Liu, T., Yu, Y., and Zhang, C., “Qplex: Duplex dueling multi-agent q-learning,” arXiv preprint arXiv:2008.01062 (2020)
-
[21]
Graph attention networks,
Veličković, P., Cucurull, G., Casanova, A., Romero, A., Liò, P., and Bengio, Y., “Graph attention networks,” in [ International Conference on Learning Representations ], (2018)
2018
-
[22]
Deep coordination graphs,
Böhmer, W., Kurin, V., and Whiteson, S., “Deep coordination graphs,” in [ International Conference on Machine Learning ], 980–991, PMLR (2020)
2020
-
[23]
Deep implicit coordination graphs for multi-agent reinforcement learning,
Li, S., Gupta, J. K., Morales, P., Allen, R., and Kochenderfer, M. J., “Deep implicit coordination graphs for multi-agent reinforcement learning,” in [ Adaptive Agents and Multi-Agent Systems ], (2020)
2020
-
[24]
Context-aware sparse deep coordination graphs,
Wang, T., Zeng, L., Dong, W., Yang, Q., Yu, Y., and Zhang, C., “Context-aware sparse deep coordination graphs,” in [ International Conference on Learning Representations ], (2022)
2022
-
[25]
Non-linear coordination graphs,
Kang, Y., Wang, T., Yang, Q., Wu, X., and Zhang, C., “Non-linear coordination graphs,” Advances in neural information processing systems 35, 25655–25666 (2022)
2022
-
[26]
Self-organized polynomial-time coordi- nation graphs,
Yang, Q., Dong, W., Ren, Z., Wang, J., Wang, T., and Zhang, C., “Self-organized polynomial-time coordi- nation graphs,” in [ International conference on machine learning ], 24963–24979, PMLR (2022)
2022
-
[27]
Group-aware coordination graph for multi-agent reinforcement learning,
Duan, W., Lu, J., and Xuan, J., “Group-aware coordination graph for multi-agent reinforcement learning,” in [ Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence ], IJCAI ’24 (2024)
2024
-
[28]
Deep meta coordination graphs for multi-agent reinforcement learning,
Gupta, N., Hare, J. Z., Kannan, R., and Prasanna, V., “Deep meta coordination graphs for multi-agent reinforcement learning,” arXiv preprint arXiv:2502.04028 (2025)
-
[29]
Chain-of- thought prompting elicits reasoning in large language models,
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., Le, Q. V., Zhou, D., et al., “Chain-of- thought prompting elicits reasoning in large language models,” Advances in neural information processing systems 35, 24824–24837 (2022)
2022
-
[30]
React: Synergizing reasoning and acting in language models,
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K. R., and Cao, Y., “React: Synergizing reasoning and acting in language models,” in [ The eleventh international conference on learning representations ], (2022)
2022
-
[31]
Language models as zero-shot planners: Extracting actionable knowledge for embodied agents,
Huang, W., Abbeel, P., Pathak, D., and Mordatch, I., “Language models as zero-shot planners: Extracting actionable knowledge for embodied agents,” in [ International conference on machine learning ], 9118–9147, PMLR (2022)
2022
-
[32]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Wang, G., Xie, Y., Jiang, Y., Mandlekar, A., Xiao, C., Zhu, Y., Fan, L., and Anandkumar, A., “Voyager: An open-ended embodied agent with large language models,” arXiv preprint arXiv:2305.16291 (2023)
work page internal anchor Pith review arXiv 2023
-
[33]
Mooney, J., [ The principles of organization ], Harper & Row (1947)
1947
-
[34]
LLM-based multi-agent rein- forcement learning: Current and future directions,
Sun, C., Huang, S., and Pompili, D., “Llm-based multi-agent reinforcement learning: Current and future directions,” arXiv preprint arXiv:2405.11106 (2024)
-
[35]
Leveraging large language models for optimised coordination in textual multi-agent reinforcement learning,
Slumbers, O., Mguni, D. H., Shao, K., and Wang, J., “Leveraging large language models for optimised coordination in textual multi-agent reinforcement learning,” (2023)
2023
-
[36]
Multi-agent actor-critic for mixed cooperative-competitive environments,
Lowe, R., Wu, Y., Tamar, A., Harb, J., Abbeel, P., and Mordatch, I., “Multi-agent actor-critic for mixed cooperative-competitive environments,” Neural Information Processing Systems (NIPS) (2017)
2017
-
[37]
arXiv preprint arXiv:1703.04908 , year=
Mordatch, I. and Abbeel, P., “Emergence of grounded compositional language in multi-agent populations,” arXiv preprint arXiv:1703.04908 (2017)
-
[38]
Action-graph policies: Learning action co-dependencies in multi-agent reinforcement learning,
Gupta, N., Hare, J. Z., Milzman, J., Kannan, R., and Prasanna, V., “Action-graph policies: Learning action co-dependencies in multi-agent reinforcement learning,” arXiv preprint arXiv:2602.17009 (2026)
-
[39]
Weighted qmix: Expanding monotonic value func- tion factorisation for deep multi-agent reinforcement learning,
Rashid, T., Farquhar, G., Peng, B., and Whiteson, S., “Weighted qmix: Expanding monotonic value func- tion factorisation for deep multi-agent reinforcement learning,” Advances in neural information processing systems 33, 10199–10210 (2020)
2020
-
[40]
The surprising effectiveness of ppo in cooperative multi-agent games,
Yu, C., Velu, A., Vinitsky, E., Gao, J., Wang, Y., Bayen, A., and Wu, Y., “The surprising effectiveness of ppo in cooperative multi-agent games,” Advances in neural information processing systems 35, 24611–24624 (2022)
2022
-
[41]
Multi-agent reinforcement learning is a sequence modeling problem,
Wen, M., Kuba, J., Lin, R., Zhang, W., Wen, Y., Wang, J., and Yang, Y., “Multi-agent reinforcement learning is a sequence modeling problem,” Advances in Neural Information Processing Systems 35, 16509– 16521 (2022)
2022
-
[42]
More centralized training, still decentralized execution: Multi-agent con- ditional policy factorization,
Wang, J., Ye, D., and Lu, Z., “More centralized training, still decentralized execution: Multi-agent con- ditional policy factorization,” in [ The Eleventh International Conference on Learning Representations ], (2023)
2023
-
[43]
Agentmixer: Multi-agent correlated policy factorization,
Li, Z., Zhao, W., Wu, L., and Pajarinen, J., “Agentmixer: Multi-agent correlated policy factorization,” in [Proceedings of the AAAI Conference on Artificial Intelligence ], 39(17), 18611–18619 (2025)
2025
-
[44]
Cammarl: Conformal action modeling in multi agent reinforcement learning,
Gupta, N., Nath, S., and Kahou, S. E., “Cammarl: Conformal action modeling in multi agent reinforcement learning,” arXiv preprint arXiv:2306.11128 (2023)
-
[45]
Arc: A runtime engine for accelerating independent multi-agent reinforcement learning on multi-core processors,
Wiggins, S., Gupta, N., Zgheib, G., Iyer, M. A., and Prasanna, V., “Arc: A runtime engine for accelerating independent multi-agent reinforcement learning on multi-core processors,” in [ 2025 IEEE 31th International Conference on Parallel and Distributed Systems (ICPADS) ], 1–10, IEEE (2025)
2025
-
[46]
Accelerating independent multi-agent reinforcement learning on multi-gpu platforms,
Wiggins, S., Gupta, N., Zgheib, G., Iyer, M. A., and Prasanna, V., “Accelerating independent multi-agent reinforcement learning on multi-gpu platforms,” in [ European Conference on Parallel Processing ], 313–326, Springer (2025)
2025
-
[47]
Gcs: Graph- based coordination strategy for multi-agent reinforcement learning,
Ruan, J., Du, Y., Xiong, X., Xing, D., Li, X., Meng, L., Zhang, H., Wang, J., and Xu, B., “Gcs: Graph- based coordination strategy for multi-agent reinforcement learning,” AAMAS ’22 , 1128–1136, International Foundation for Autonomous Agents and Multiagent Systems, Richland, SC (2022)
2022
-
[48]
Deep hierarchical communication graph in multi-agent reinforcement learning.,
Liu, Z., Wan, L., Sui, X., Chen, Z., Sun, K., and Lan, X., “Deep hierarchical communication graph in multi-agent reinforcement learning.,” in [ IJCAI ], 208–216 (2023)
2023
-
[49]
Hammer: Multi-level coordi- nation of reinforcement learning agents via learned messaging,
Gupta, N., Srinivasaraghavan, G., Mohalik, S., Kumar, N., and Taylor, M. E., “Hammer: Multi-level coordi- nation of reinforcement learning agents via learned messaging,” Neural Computing and Applications 37(19), 13221–13236 (2025)
2025
-
[50]
Gupta, N., Twardecka, L., Hare, J. Z., Milzman, J., Kannan, R., and Prasanna, V., “Tiger-marl: Enhanc- ing multi-agent reinforcement learning with temporal information through graph-based embeddings and representations,” arXiv preprint arXiv:2511.08832 (2025)
-
[51]
Survey on graph-based reinforcement learning for networked coordination and control,
Liu, Y., Wu, D., and Liang, Y., “Survey on graph-based reinforcement learning for networked coordination and control,” Automation 6(4), 65 (2025)
2025
-
[52]
Eureka: Human-Level Reward Design via Coding Large Language Models
Ma, Y. J., Liang, W., Wang, G., Huang, D.-A., Bastani, O., Jayaraman, D., Zhu, Y., Fan, L., and Anandkumar, A., “Eureka: Human-level reward design via coding large language models,” arXiv preprint arXiv:2310.12931 (2023)
work page internal anchor Pith review arXiv 2023
-
[53]
Multi-agent collaboration via evolving orchestration,
Dang, Y., Qian, C., Luo, X., Fan, J., Xie, Z., Shi, R., Chen, W., Yang, C., Che, X., Tian, Y., Xiong, X., Han, L., Liu, Z., and Sun, M., “Multi-agent collaboration via evolving orchestration,” in [ The Thirty-ninth Annual Conference on Neural Information Processing Systems ], (2025)
2025
-
[54]
Hierrouter: Coordinated routing of specialized large language models via reinforcement learning,
Gupta, N., Guo, B., Kannan, R., and Prasanna, V. K., “Hierrouter: Coordinated routing of specialized large language models via reinforcement learning,” arXiv preprint arXiv:2511.09873 (2025)
-
[55]
Team, Q., “Qwen2.5 technical report,” arXiv preprint arXiv:2412.15115 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al., “The llama 3 herd of models,” arXiv preprint arXiv:2407.21783 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[57]
Gemma 2: Improving Open Language Models at a Practical Size
Team, G., Riviere, M., Pathak, S., Sessa, P. G., Hardin, C., Bhupatiraju, S., Hussenot, L., Mesnard, T., Shahriari, B., Ramé, A., et al., “Gemma 2: Improving open language models at a practical size,” arXiv preprint arXiv:2408.00118 (2024)
work page internal anchor Pith review arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.