Recognition: unknown
DreamShot: Personalized Storyboard Synthesis with Video Diffusion Prior
Pith reviewed 2026-05-10 07:17 UTC · model grok-4.3
The pith
DreamShot adapts video diffusion models to create coherent multi-shot storyboards with consistent characters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
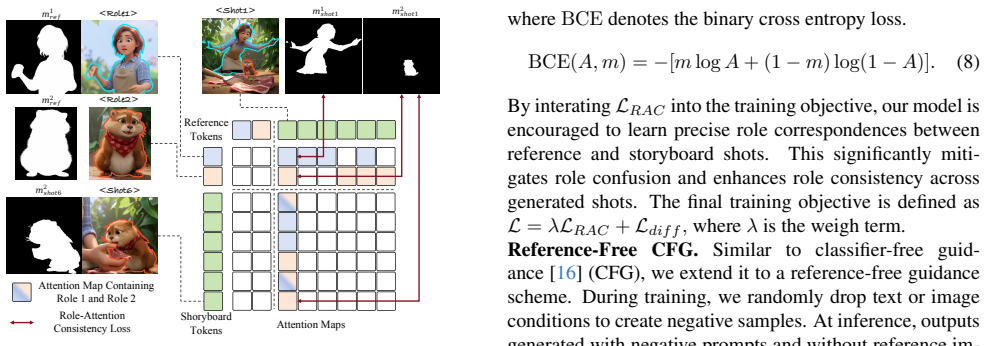
DreamShot is a video generative model based storyboard framework that fully exploits powerful video diffusion priors for controllable multi-shot synthesis. It supports Text-to-Shot and Reference-to-Shot generation as well as story continuation conditioned on previous frames. A multi-reference role conditioning module accepts multiple character reference images and enforces identity alignment via a Role-Attention Consistency Loss that explicitly constrains attention between references and generated roles. Experiments show superior scene coherence, role consistency, and generation efficiency over state-of-the-art text-to-image storyboard models.
What carries the argument
The multi-reference role conditioning module with Role-Attention Consistency Loss, which aligns multiple input character references to generated shots by constraining cross-attention maps.
If this is right
- Storyboard sequences gain improved long-range narrative fidelity through inherent video-model temporal priors.
- Flexible conditioning on prior frames supports incremental story continuation without resetting consistency.
- Multiple reference images can be used to enforce stable character appearance across all shots in one pass.
- Generation efficiency rises because the video prior reduces the need for post-hoc consistency fixes.
Where Pith is reading between the lines
- The same video-prior approach could extend to generating full short clips from storyboards rather than static frames.
- Combining the role-conditioning module with script-level language models might produce end-to-end script-to-visual pipelines.
- Similar attention-constraint techniques may transfer to other multi-image tasks such as consistent comic panel creation.
Load-bearing premise
Spatial-temporal consistency learned inside video diffusion models transfers directly to separate storyboard shots without introducing new long-range coherence failures.
What would settle it
A head-to-head test on stories longer than six shots that measures character identity drift and scene mismatch rates, checking whether DreamShot rates exceed those of strong text-to-image baselines.
Figures















read the original abstract
Storyboard synthesis plays a crucial role in visual storytelling, aiming to generate coherent shot sequences that visually narrate cinematic events with consistent characters, scenes, and transitions. However, existing approaches are mostly adapted from text-to-image diffusion models, which struggle to maintain long-range temporal coherence, consistent character identities, and narrative flow across multiple shots. In this paper, we introduce DreamShot, a video generative model based storyboard framework that fully exploits powerful video diffusion priors for controllable multi-shot synthesis. DreamShot supports both Text-to-Shot and Reference-to-Shot generation, as well as story continuation conditioned on previous frames, enabling flexible and context-aware storyboard generation. By leveraging the spatial-temporal consistency inherent in video generative models, DreamShot produces visually and semantically coherent sequences with improved narrative fidelity and character continuity. Furthermore, DreamShot incorporates a multi-reference role conditioning module that accepts multiple character reference images and enforces identity alignment via a Role-Attention Consistency Loss, explicitly constraining attention between reference and generated roles. Extensive experiments demonstrate that DreamShot achieves superior scene coherence, role consistency, and generation efficiency compared to state-of-the-art text-to-image storyboard models, establishing a new direction toward controllable video model-driven visual storytelling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DreamShot, a video diffusion prior-based framework for personalized storyboard synthesis. It supports Text-to-Shot, Reference-to-Shot, and story continuation generation modes. A multi-reference role conditioning module is introduced along with a Role-Attention Consistency Loss to enforce character identity alignment. The authors claim that leveraging spatial-temporal consistency from video models yields superior scene coherence, role consistency, and generation efficiency relative to state-of-the-art text-to-image storyboard approaches.
Significance. If the experimental claims are substantiated with rigorous validation, the work could meaningfully advance visual storytelling by demonstrating that video diffusion priors can be effectively adapted for controllable multi-shot synthesis, addressing longstanding issues of temporal coherence and identity drift that limit image-only methods. This would establish a viable new direction for narrative visual generation with potential applications in film pre-visualization and digital media production.
major comments (2)
- Abstract: The superiority claims for scene coherence, role consistency, and generation efficiency are asserted without any quantitative results, ablation studies, dataset descriptions, baseline comparisons, or experimental protocols. This absence directly undermines evaluation of the central claim that video diffusion priors transfer effectively to storyboard synthesis.
- Abstract: The Role-Attention Consistency Loss is described as explicitly constraining attention for identity alignment, yet no formulation, implementation details, or analysis of its impact on long-sequence drift is supplied. This leaves the weakest assumption (direct transfer without new coherence failures) untestable and load-bearing for the method's contribution.
minor comments (1)
- Abstract: The abstract would benefit from naming the specific video diffusion model serving as the prior and the evaluation metrics for coherence and consistency to improve clarity and reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments on our manuscript. We address each major comment point by point below. The full paper contains the requested experimental details and method formulations in dedicated sections, but we agree that the abstract can be strengthened for clarity and will revise it accordingly.
read point-by-point responses
-
Referee: Abstract: The superiority claims for scene coherence, role consistency, and generation efficiency are asserted without any quantitative results, ablation studies, dataset descriptions, baseline comparisons, or experimental protocols. This absence directly undermines evaluation of the central claim that video diffusion priors transfer effectively to storyboard synthesis.
Authors: The abstract summarizes the paper's key claims, while the full experimental validation—including quantitative metrics (e.g., FID, CLIP similarity for role consistency), ablation studies, dataset details (e.g., custom storyboard dataset), baseline comparisons (against text-to-image methods like Stable Diffusion variants), and protocols—is provided in Section 4. To address the concern directly, we will revise the abstract to incorporate specific quantitative highlights from our results, such as reported improvements in coherence and efficiency. revision: yes
-
Referee: Abstract: The Role-Attention Consistency Loss is described as explicitly constraining attention for identity alignment, yet no formulation, implementation details, or analysis of its impact on long-sequence drift is supplied. This leaves the weakest assumption (direct transfer without new coherence failures) untestable and load-bearing for the method's contribution.
Authors: The abstract provides a high-level description of the loss. The full formulation (as a regularization term on cross-attention maps between references and generated frames), implementation details, and analysis of its effect on identity alignment and long-sequence drift are presented in Section 3.3 (with the equation) and Section 4.3 (ablations). We will revise the abstract to briefly note the loss's mathematical role and reference the analysis on drift prevention. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The abstract and available context describe DreamShot as leveraging external video diffusion priors for multi-shot synthesis, with a new multi-reference role conditioning module and Role-Attention Consistency Loss introduced to enforce identity alignment. No equations, parameter-fitting procedures, self-citations as load-bearing premises, or uniqueness theorems are quoted that would reduce any claimed result (such as coherence or consistency) to the inputs by construction. The central claims rest on experimental comparisons to text-to-image baselines and the transfer of spatial-temporal consistency from video models, which are independent of the present work's outputs. This satisfies the default expectation of a non-circular paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
com / Breakthrough/PySceneDetect, 2025
Pyscenedetect.https : / / github . com / Breakthrough/PySceneDetect, 2025. 5, 12
2025
-
[2]
com / boomb0om/watermark-detection, 2025
watermark-detection.https : / / github . com / boomb0om/watermark-detection, 2025. 12
2025
-
[3]
Stephen Batifol, Andreas Blattmann, Frederic Boesel, Sak- sham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, Sumith Kulal, et al. Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space.arXiv e-prints, pages arXiv–2506,
-
[4]
Xverse: Consistent multi-subject control of identity and semantic attributes via dit modulation.NeurIPS, 2025
Bowen Chen, Mengyi Zhao, Haomiao Sun, Li Chen, Xu Wang, Kang Du, and Xinglong Wu. Xverse: Consistent multi-subject control of identity and semantic attributes via dit modulation.NeurIPS, 2025. 3
2025
-
[5]
Unimax: Fairer and more effective language sampling for large-scale multilingual pretraining.ICLR, 2023
Hyung Won Chung, Noah Constant, Xavier Garcia, Adam Roberts, Yi Tay, Sharan Narang, and Orhan Firat. Unimax: Fairer and more effective language sampling for large-scale multilingual pretraining.ICLR, 2023. 3
2023
-
[6]
Arcface: Additive angular margin loss for deep face recognition
Jiankang Deng, Jia Guo, Niannan Xue, and Stefanos Zafeiriou. Arcface: Additive angular margin loss for deep face recognition. InCVPR, pages 4690–4699, 2019. 4, 6, 12
2019
-
[7]
David Dinkevich, Matan Levy, Omri Avrahami, Dvir Samuel, and Dani Lischinski. Story2board: A training- free approach for expressive storyboard generation.arXiv preprint arXiv:2508.09983, 2025. 2, 3, 6, 7
-
[8]
Aesthetic predictor v2.5.https : / / github
Discus0434. Aesthetic predictor v2.5.https : / / github . com / discus0434 / aesthetic - predictor-v2-5, 2024. 5, 7, 12
2024
-
[9]
A survey on long-video storytelling generation: Architectures, consistency, and cinematic quality
Mohamed Elmoghany, Ryan Rossi, Seunghyun Yoon, Sub- hojyoti Mukherjee, Eslam Mohamed Bakr, Puneet Mathur, Gang Wu, Viet Dac Lai, Nedim Lipka, Ruiyi Zhang, et al. A survey on long-video storytelling generation: Architectures, consistency, and cinematic quality. InICCV, pages 7023– 7035, 2025. 2
2025
-
[10]
An image is worth one word: Personalizing text-to-image gen- eration using textual inversion.ICLR, 2023
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit H Bermano, Gal Chechik, and Daniel Cohen-Or. An image is worth one word: Personalizing text-to-image gen- eration using textual inversion.ICLR, 2023. 3
2023
-
[11]
Seedance 1.0: Exploring the Boundaries of Video Generation Models
Yu Gao, Haoyuan Guo, Tuyen Hoang, Weilin Huang, Lu Jiang, Fangyuan Kong, Huixia Li, Jiashi Li, Liang Li, Xi- aojie Li, et al. Seedance 1.0: Exploring the boundaries of video generation models.arXiv preprint arXiv:2506.09113,
work page internal anchor Pith review arXiv
-
[12]
Tokenverse: Versatile multi-concept personalization in token modulation space.ACM Transactions on Graphics (TOG), 44(4):1–11, 2025
Daniel Garibi, Shahar Yadin, Roni Paiss, Omer Tov, Shiran Zada, Ariel Ephrat, Tomer Michaeli, Inbar Mosseri, and Tali Dekel. Tokenverse: Versatile multi-concept personalization in token modulation space.ACM Transactions on Graphics (TOG), 44(4):1–11, 2025. 3
2025
-
[13]
Dong Guo, Faming Wu, Feida Zhu, Fuxing Leng, Guang Shi, Haobin Chen, Haoqi Fan, Jian Wang, Jianyu Jiang, Jiawei Wang, et al. Seed1. 5-vl technical report.arXiv preprint arXiv:2505.07062, 2025. 5, 6, 12
work page internal anchor Pith review arXiv 2025
-
[14]
Svdiff: Compact param- eter space for diffusion fine-tuning
Ligong Han, Yinxiao Li, Han Zhang, Peyman Milanfar, Dimitris Metaxas, and Feng Yang. Svdiff: Compact param- eter space for diffusion fine-tuning. InICCV, pages 7323– 7334, 2023. 3
2023
-
[15]
Junjie He, Yuxiang Tuo, Binghui Chen, Chongyang Zhong, Yifeng Geng, and Liefeng Bo. Anystory: Towards unified single and multiple subject personalization in text-to-image generation.arXiv preprint arXiv:2501.09503, 2025. 2, 3
-
[16]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022. 5
work page internal anchor Pith review arXiv 2022
-
[17]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022. 6
2022
-
[18]
Dreamlayer: Simultaneous multi-layer generation via diffu- sion model
Junjia Huang, Pengxiang Yan, Jinhang Cai, Jiyang Liu, Zhao Wang, Yitong Wang, Xinglong Wu, and Guanbin Li. Dreamlayer: Simultaneous multi-layer generation via diffu- sion model. InICCV, pages 3357–3366, 2025. 3
2025
-
[19]
Dream- fuse: Adaptive image fusion with diffusion transformer
Junjia Huang, Pengxiang Yan, Jiyang Liu, Jie Wu, Zhao Wang, Yitong Wang, Liang Lin, and Guanbin Li. Dream- fuse: Adaptive image fusion with diffusion transformer. In ICCV, pages 17292–17301, 2025. 3
2025
-
[20]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Flux.https://github.com/ black-forest-labs/flux, 2024
Black Forest Labs. Flux.https://github.com/ black-forest-labs/flux, 2024. 2, 3
2024
-
[22]
Decoupled weight decay regularization.ICLR, 2019
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.ICLR, 2019. 6
2019
-
[23]
Guoqing Ma, Haoyang Huang, Kun Yan, Liangyu Chen, Nan Duan, Shengming Yin, Changyi Wan, Ranchen Ming, Xi- aoniu Song, Xing Chen, et al. Step-video-t2v technical re- port: The practice, challenges, and future of video founda- tion model.arXiv preprint arXiv:2502.10248, 2025. 3
-
[24]
Chaojie Mao, Jingfeng Zhang, Yulin Pan, Zeyinzi Jiang, Zhen Han, Yu Liu, and Jingren Zhou. Ace++: Instruction- based image creation and editing via context-aware content filling.arXiv preprint arXiv:2501.02487, 2025. 3
-
[25]
arXiv preprint arXiv:2410.06244 (2024)
Jiawei Mao, Xiaoke Huang, Yunfei Xie, Yuanqi Chang, Mude Hui, Bingjie Xu, and Yuyin Zhou. Story-adapter: A training-free iterative framework for long story visualization. arXiv preprint arXiv:2410.06244, 2024. 2, 3, 6, 7
-
[26]
Yihao Meng, Hao Ouyang, Yue Yu, Qiuyu Wang, Wen Wang, Ka Leong Cheng, Hanlin Wang, Yixuan Li, Cheng Chen, Yanhong Zeng, et al. Holocine: Holistic generation of cinematic multi-shot long video narratives.arXiv preprint arXiv:2510.20822, 2025. 2, 3
-
[27]
Dreamo: A unified framework for image customization.arXiv preprint arXiv:2504.16915,
Chong Mou, Yanze Wu, Wenxu Wu, Zinan Guo, Pengze Zhang, Yufeng Cheng, Yiming Luo, Fei Ding, Shiwen Zhang, Xinghui Li, et al. Dreamo: A unified framework for image customization.arXiv preprint arXiv:2504.16915,
-
[28]
Openvid-1m: A large-scale high-quality dataset for text-to- video generation.ICLR, 2025
Kepan Nan, Rui Xie, Penghao Zhou, Tiehan Fan, Zhen- heng Yang, Zhijie Chen, Xiang Li, Jian Yang, and Ying Tai. Openvid-1m: A large-scale high-quality dataset for text-to- video generation.ICLR, 2025. 5
2025
-
[29]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InICCV, pages 4195–4205, 2023. 3
2023
-
[30]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M ¨uller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion mod- els for high-resolution image synthesis.arXiv preprint arXiv:2307.01952, 2023. 3
work page internal anchor Pith review arXiv 2023
-
[31]
Make-a-story: Visual memory conditioned consistent story generation
Tanzila Rahman, Hsin-Ying Lee, Jian Ren, Sergey Tulyakov, Shweta Mahajan, and Leonid Sigal. Make-a-story: Visual memory conditioned consistent story generation. InCVPR, pages 2493–2502, 2023. 2
2023
-
[32]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Kunchang Li, He Cao, Jiayu Chen, Xinyu Huang, Yukang Chen, Feng Yan, et al. Grounded sam: Assembling open-world models for diverse visual tasks.arXiv preprint arXiv:2401.14159,
-
[33]
High-resolution image syn- thesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High-resolution image syn- thesis with latent diffusion models. InCVPR, pages 10684– 10695, 2022. 3
2022
-
[34]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. InMICCAI, pages 234–241. Springer, 2015. 3
2015
-
[35]
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. InCVPR, pages 22500–22510, 2023. 3
2023
-
[36]
Seedream 4.0: Toward Next-generation Multimodal Image Generation
Team Seedream, Yunpeng Chen, Yu Gao, Lixue Gong, Meng Guo, Qiushan Guo, Zhiyao Guo, Xiaoxia Hou, Weilin Huang, Yixuan Huang, et al. Seedream 4.0: Toward next- generation multimodal image generation.arXiv preprint arXiv:2509.20427, 2025. 6, 12
work page internal anchor Pith review arXiv 2025
-
[37]
Dong She, Siming Fu, Mushui Liu, Qiaoqiao Jin, Hualiang Wang, Mu Liu, and Jidong Jiang. Mosaic: Multi-subject per- sonalized generation via correspondence-aware alignment and disentanglement.arXiv preprint arXiv:2509.01977,
-
[38]
Measuring style similarity in diffusion models.ECCV, 2024
Gowthami Somepalli, Anubhav Gupta, Kamal Gupta, Shra- may Palta, Micah Goldblum, Jonas Geiping, Abhinav Shri- vastava, and Tom Goldstein. Measuring style similarity in diffusion models.ECCV, 2024. 7
2024
-
[39]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063,
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063,
-
[40]
Ominicontrol: Minimal and universal control for diffusion transformer
Zhenxiong Tan, Songhua Liu, Xingyi Yang, Qiaochu Xue, and Xinchao Wang. Ominicontrol: Minimal and universal control for diffusion transformer. InICCV, pages 14940– 14950, 2025. 2
2025
-
[41]
Longcat-video technical report
Meituan LongCat Team. Longcat-video technical report. arXiv preprint arXiv:2510.22200, 2025. 2, 3
-
[42]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video gen- erative models.arXiv preprint arXiv:2503.20314, 2025. 2, 3, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Bo Wang, Haoyang Huang, Zhiying Lu, Fengyuan Liu, Guoqing Ma, Jianlong Yuan, Yuan Zhang, Nan Duan, and Daxin Jiang. Storyanchors: Generating consistent multi- scene story frames for long-form narratives.arXiv preprint arXiv:2505.08350, 2025. 3, 5
-
[44]
Instantid: Zero-shot identity-preserving generation in seconds.arXiv preprint arXiv:2401.07519,
Qixun Wang, Xu Bai, Haofan Wang, Zekui Qin, Anthony Chen, Huaxia Li, Xu Tang, and Yao Hu. Instantid: Zero-shot identity-preserving generation in seconds.arXiv preprint arXiv:2401.07519, 2024. 2
-
[45]
Koala-36m: A large-scale video dataset improving consistency between fine-grained conditions and video content
Qiuheng Wang, Yukai Shi, Jiarong Ou, Rui Chen, Ke Lin, Jiahao Wang, Boyuan Jiang, Haotian Yang, Mingwu Zheng, Xin Tao, et al. Koala-36m: A large-scale video dataset improving consistency between fine-grained conditions and video content. InCVPR, pages 8428–8437, 2025. 5
2025
-
[46]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025. 2, 6
work page internal anchor Pith review arXiv 2025
-
[47]
OmniGen2: Towards Instruction-Aligned Multimodal Generation
Chenyuan Wu, Pengfei Zheng, Ruiran Yan, Shitao Xiao, Xin Luo, Yueze Wang, Wanli Li, Xiyan Jiang, Yexin Liu, Junjie Zhou, et al. Omnigen2: Exploration to advanced multimodal generation.arXiv preprint arXiv:2506.18871, 2025. 3, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Less-to-more generalization: Unlock- ing more controllability by in-context generation
Shaojin Wu, Mengqi Huang, Wenxu Wu, Yufeng Cheng, Fei Ding, and Qian He. Less-to-more generalization: Unlock- ing more controllability by in-context generation. InICCV,
-
[49]
Videoauteur: Towards long narrative video gener- ation
Junfei Xiao, Feng Cheng, Lu Qi, Liangke Gui, Yang Zhao, Shanchuan Lin, Jiepeng Cen, Zhibei Ma, Alan Yuille, and Lu Jiang. Videoauteur: Towards long narrative video gener- ation. InICCV, pages 19163–19173, 2025. 3
2025
-
[50]
Captain cinema: Towards short movie generation,
Junfei Xiao, Ceyuan Yang, Lvmin Zhang, Shengqu Cai, Yang Zhao, Yuwei Guo, Gordon Wetzstein, Maneesh Agrawala, Alan Yuille, and Lu Jiang. Captain cin- ema: Towards short movie generation.arXiv preprint arXiv:2507.18634, 2025. 2, 3
-
[51]
Jiazheng Xu, Yu Huang, Jiale Cheng, Yuanming Yang, Jiajun Xu, Yuan Wang, Wenbo Duan, Shen Yang, Qunlin Jin, Shu- run Li, et al. Visionreward: Fine-grained multi-dimensional human preference learning for image and video generation. arXiv preprint arXiv:2412.21059, 2024. 12
-
[52]
Seed-story: Multimodal long story generation with large language model
Shuai Yang, Yuying Ge, Yang Li, Yukang Chen, Yixiao Ge, Ying Shan, and Ying-Cong Chen. Seed-story: Multimodal long story generation with large language model. InICCV, pages 1850–1860, 2025. 2, 6
2025
-
[53]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiao- han Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024. 3
work page internal anchor Pith review arXiv 2024
-
[54]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. Ip- adapter: Text compatible image prompt adapter for text-to- image diffusion models.arXiv preprint arXiv:2308.06721,
work page internal anchor Pith review arXiv
-
[55]
Storyweaver: A unified world model 10 for knowledge-enhanced story character customization
Jinlu Zhang, Jiji Tang, Rongsheng Zhang, Tangjie Lv, and Xiaoshuai Sun. Storyweaver: A unified world model 10 for knowledge-enhanced story character customization. In AAAI, pages 9951–9959, 2025. 3
2025
-
[56]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In CVPR, pages 3836–3847, 2023. 2
2023
-
[57]
arXiv preprint arXiv:2505.18612 (2025)
Weizhi Zhong, Huan Yang, Zheng Liu, Huiguo He, Zijian He, Xuesong Niu, Di Zhang, and Guanbin Li. Mod-adapter: Tuning-free and versatile multi-concept personalization via modulation adapter.arXiv preprint arXiv:2505.18612, 2025. 3
-
[58]
Storydiffusion: Consistent self-attention for long-range image and video generation
Yupeng Zhou, Daquan Zhou, Ming-Ming Cheng, Ji- ashi Feng, and Qibin Hou. Storydiffusion: Consistent self-attention for long-range image and video generation. NeurIPS, 37:110315–110340, 2024. 2, 3, 6, 7
2024
-
[59]
Zhengguang Zhou, Jing Li, Huaxia Li, Nemo Chen, and Xu Tang. Storymaker: Towards holistic consistent characters in text-to-image generation.arXiv preprint arXiv:2409.12576,
-
[60]
scene” and the cinematic concept of a “shot
Cailin Zhuang, Ailin Huang, Wei Cheng, Jingwei Wu, Yaoqi Hu, Jiaqi Liao, Hongyuan Wang, Xinyao Liao, Weiwei Cai, Hengyuan Xu, et al. Vistorybench: Comprehensive benchmark suite for story visualization.arXiv preprint arXiv:2505.24862, 2025. 2, 7, 14, 15 11 A. Storyboard Dataset A.1. More Details about the Data Construction In this section, we provide a det...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.