Recognition: unknown
EmbodiedHead: Real-Time Listening and Speaking Avatar for Conversational Agents
Pith reviewed 2026-05-10 07:08 UTC · model grok-4.3
The pith
A Rectified-Flow Diffusion Transformer paired with a differentiable renderer generates real-time listening and speaking avatars for LLMs in four sampling steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EmbodiedHead shows that a Rectified-Flow Diffusion Transformer for talking-head synthesis, when combined with a differentiable renderer and operated under a single-stream interface with per-frame listening-speaking state conditioning and a Streaming Audio Scheduler, produces diverse high-fidelity animations in as few as four sampling steps while suppressing unwanted mouth motion in listening phases and supporting seamless turn-taking in causal user-LLM interaction.
What carries the argument
The Rectified-Flow Diffusion Transformer (DiT) coupled with a differentiable renderer, which performs high-fidelity generation in four sampling steps while the Streaming Audio Scheduler and state conditioning manage listening-speaking transitions.
If this is right
- Enables real-time visual embodiment for LLMs without requiring future audio information.
- Achieves unified listening and speaking behavior with state-of-the-art motion fidelity and rendered quality.
- Removes look-ahead dependency that previously blocked deployment in live conversational agents.
- Closes the gap between motion-level training signals and final image quality through two-stage coefficient then image-domain refinement.
Where Pith is reading between the lines
- This approach could support deployment of embodied agents on consumer hardware due to the low sampling-step count.
- Integration with full-body or gesture models would extend the avatar to more complete virtual presence.
- The single-stream design opens the possibility of multi-party conversation avatars where each participant streams independently.
Load-bearing premise
Explicit per-frame listening-speaking state conditioning plus a Streaming Audio Scheduler can fully suppress spurious mouth motion during listening and enable seamless turn-taking in causal single-stream user-LLM interaction without new artifacts or dual-stream look-ahead.
What would settle it
Run the model on live single-stream audio in causal mode and measure whether mouth motion appears during user-speaking segments or whether four-step sampling produces visibly lower visual quality than slower baselines.
Figures




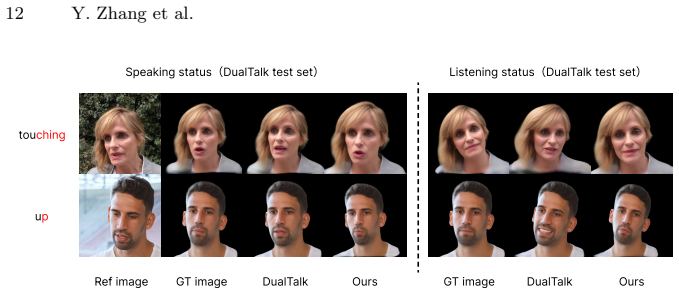

read the original abstract
We present EmbodiedHead, a speech-driven talking-head framework that equips LLMs with real-time visual avatars for conversation. A practical embodied avatar must achieve real-time generation, unified listening-speaking behavior, and high rendered visual quality simultaneously. Our framework couples the first Rectified-Flow Diffusion Transformer (DiT) for this task with a differentiable renderer, enabling diverse, high-fidelity generation in as few as four sampling steps. Prior listening-speaking methods rely on dual-stream audio, introducing an interlocutor look-ahead dependency incompatible with causal user--LLM interaction. We instead adopt a single-stream interface with explicit per-frame listening-speaking state conditioning and a Streaming Audio Scheduler, suppressing spurious mouth motion during listening while enabling seamless turn-taking. A two-stage training scheme of coefficient-space pretraining and joint image-domain refinement further closes the gap between motion-level supervision and rendered quality. Extensive experiments demonstrate state-of-the-art visual quality and motion fidelity in both speaking and listening scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents EmbodiedHead, a speech-driven talking-head framework for real-time conversational avatars with LLMs. It introduces the first Rectified-Flow Diffusion Transformer (DiT) paired with a differentiable renderer to enable diverse, high-fidelity avatar generation in as few as four sampling steps. To support causal user-LLM interaction, the approach replaces dual-stream audio with a single-stream interface that incorporates explicit per-frame listening-speaking state conditioning and a Streaming Audio Scheduler to suppress spurious mouth motion during listening. A two-stage training procedure (coefficient-space pretraining followed by joint image-domain refinement) is used to improve rendered output quality. The authors report state-of-the-art visual quality and motion fidelity in both speaking and listening scenarios based on extensive experiments.
Significance. If the empirical results hold, the work is significant for embodied conversational AI. The combination of rectified-flow DiT for fast sampling, the causal single-stream design for seamless turn-taking, and the two-stage training scheme that bridges motion-level supervision to rendered quality offers a practical advance over prior dual-stream methods that require interlocutor look-ahead. This could enable more natural real-time visual avatars for LLMs without sacrificing fidelity or introducing latency.
major comments (2)
- [Abstract] Abstract: The central claim of 'state-of-the-art visual quality and motion fidelity' in both speaking and listening scenarios is unsupported by any quantitative metrics, baseline comparisons, error bars, dataset details, or evaluation protocols. This absence is load-bearing because the paper's primary contribution is the superiority of the proposed framework over prior methods.
- [§3] §3 (Method, Streaming Audio Scheduler and state conditioning): The assertion that explicit per-frame listening-speaking conditioning plus the Streaming Audio Scheduler fully suppresses spurious mouth motion during listening and enables seamless causal turn-taking without new artifacts lacks supporting ablation studies or quantitative comparisons against dual-stream baselines in causal settings. This mechanism is load-bearing for the claimed practical advantage over prior work.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for identifying areas where our claims require stronger empirical grounding. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of 'state-of-the-art visual quality and motion fidelity' in both speaking and listening scenarios is unsupported by any quantitative metrics, baseline comparisons, error bars, dataset details, or evaluation protocols. This absence is load-bearing because the paper's primary contribution is the superiority of the proposed framework over prior methods.
Authors: We acknowledge that the abstract is a high-level summary and does not itself contain the quantitative details. The manuscript states that extensive experiments demonstrate the claimed performance. To directly address the load-bearing nature of this claim, we will revise the abstract to concisely incorporate key quantitative results, baseline comparisons, error bars, dataset information, and evaluation protocols drawn from the experiments section. revision: yes
-
Referee: [§3] §3 (Method, Streaming Audio Scheduler and state conditioning): The assertion that explicit per-frame listening-speaking conditioning plus the Streaming Audio Scheduler fully suppresses spurious mouth motion during listening and enables seamless causal turn-taking without new artifacts lacks supporting ablation studies or quantitative comparisons against dual-stream baselines in causal settings. This mechanism is load-bearing for the claimed practical advantage over prior work.
Authors: We agree that the current description of the single-stream design, per-frame state conditioning, and Streaming Audio Scheduler would benefit from additional empirical support. The manuscript explains how these elements enable causal operation without interlocutor look-ahead. We will add ablation studies and quantitative comparisons against dual-stream baselines under causal conditions, measuring spurious motion suppression and turn-taking quality, to substantiate the practical advantages. revision: yes
Circularity Check
No significant circularity; claims rest on standard diffusion and rendering techniques without self-referential reduction
full rationale
The provided abstract and description outline an architectural framework (Rectified-Flow DiT coupled with differentiable renderer, single-stream state conditioning, Streaming Audio Scheduler, and two-stage training) but contain no equations, derivations, fitted parameters presented as predictions, or load-bearing self-citations. All components are described as novel combinations of existing methods applied to external training data, with no step reducing a claimed result to its own inputs by construction. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aneja, S., Sevastopolsky, A., Kirschstein, T., Thies, J., Dai, A., Nießner, M.: Gaus- sianspeech: Audio-driven gaussian avatars (2024),https://arxiv.org/abs/2411. 18675
2024
-
[2]
Ba, J.L., Kiros, J.R., Hinton, G.E.: Layer normalization. arXiv preprint arXiv:1607.06450 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[3]
Chen, J., Wang, F., Huang, Z., Zhou, Q., Li, K., Guo, D., Zhang, L., Yang, X.: To- wards Seamless Interaction: Causal Turn-Level Modeling of Interactive 3D Conver- sational Head Dynamics (2025).https://doi.org/10.48550/arXiv.2512.15340
-
[4]
Chen, J., Yu, J., Ge, C., Yao, L., Xie, E., Wu, Y., Wang, Z., Kwok, J., Luo, P., Lu, H., Li, Z.: Pixart-α: Fast training of diffusion transformer for photorealistic text-to-image synthesis (2023),https://arxiv.org/abs/2310.00426
work page internal anchor Pith review arXiv 2023
-
[5]
Chen, S., Huang, H., Liu, Y., Ye, Z., Chen, P., Zhu, C., Guan, M., Wang, R., Chen, J., Li, G., et al.: Talkvid: A large-scale diversified dataset for audio-driven talking head synthesis. arXiv preprint arXiv:2508.13618 (2025)
- [6]
-
[7]
Advances in Neural Information Processing Systems37, 57642–57670 (2024)
Chu, X., Harada, T.: Generalizable and animatable gaussian head avatar. Advances in Neural Information Processing Systems37, 57642–57670 (2024)
2024
-
[8]
Chu, X., Liu, R., Huang, Y., Liu, Y., Peng, Y., Zheng, B.: UniLS: End-to-End Audio-Driven Avatars for Unified Listening and Speaking (2025).https://doi. org/10.48550/arXiv.2512.09327
-
[9]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2019)
Cudeiro, D., Bolkart, T., Laidlaw, C., Ranjan, A., Black, M.J.: Capture, learning, and synthesis of 3d speaking styles. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2019)
2019
-
[10]
Cui, J., Li, H., Zhan, Y., Shang, H., Cheng, K., Ma, Y., Mu, S., Zhou, H., Wang, J., Zhu, S.: Hallo3: Highly Dynamic and Realistic Portrait Image Animation with Diffusion Transformer Networks (2025).https://doi.org/10.48550/arXiv.2412. 00733
-
[11]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Fan, Y., Lin, Z., Saito, J., Wang, W., Komura, T.: Faceformer: Speech-driven 3d facial animation with transformers. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 18770–18780 (June 2022)
2022
- [12]
-
[13]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Guo, Y., Chen, K., Liang, S., Liu, Y.J., Bao, H., Zhang, J.: Ad-nerf: Audio driven neural radiance fields for talking head synthesis. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 5784–5794 (October 2021)
2021
-
[14]
In: Advances in Neural Information Processing Systems
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. In: Advances in Neural Information Processing Systems. vol. 33, pp. 6840–6851 (2020)
2020
-
[15]
HuBERT: Self-supervised speech representation learning by masked prediction of hidden units,
Hsu, W.N., Bolte, B., Tsai, Y.H.H., Lakhotia, K., Salakhutdinov, R., Mohamed, A.: Hubert: Self-supervised speech representation learning by masked prediction of hidden units. IEEE/ACM Transactions on Audio, Speech, and Language Pro- cessing29, 3451–3460 (2021).https://doi.org/10.1109/TASLP.2021.3122291
-
[16]
In: The Thirteenth International Conference on Learning Representations (2024) 16 Y
Jiang, J., Liang, C., Yang, J., Lin, G., Zhong, T., Zheng, Y.: Loopy: Taming Audio- Driven Portrait Avatar with Long-Term Motion Dependency. In: The Thirteenth International Conference on Learning Representations (2024) 16 Y. Zhang et al
2024
-
[17]
ACM Transactions on Graphics42(4) (July 2023),https://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/
Kerbl, B., Kopanas, G., Leimk¨ uhler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics42(4) (July 2023),https://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/
2023
-
[18]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Li, J., Zhang, J., Bai, X., Zhou, J., Gu, L.: Efficient region-aware neural radiance fields for high-fidelity talking portrait synthesis. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 7568–7578 (2023)
2023
-
[19]
Available: http://dx.doi.org/10.1145/3130800.3130810
Li, T., Bolkart, T., Black, M.J., Li, H., Romero, J.: Learning a model of facial shape and expression from 4D scans. ACM Transactions on Graphics, (Proc. SIGGRAPH Asia)36(6), 194:1–194:17 (2017),https://doi.org/10.1145/3130800.3130813
- [20]
-
[21]
Lipman, Y., Chen, R.T.Q., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling (2023),https://arxiv.org/abs/2210.02747
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Liu, X., Gong, C., Liu, Q.: Flow straight and fast: Learning to generate and transfer data with rectified flow (2022),https://arxiv.org/abs/2209.03003
work page internal anchor Pith review arXiv 2022
-
[23]
Loshchilov, I., Hutter, F.: Decoupled Weight Decay Regularization (2017).https: //doi.org/10.48550/arXiv.1711.05101
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1711.05101 2017
-
[24]
In: 2010 43rd Hawaii International Conference on System Sciences
Mennecke, B.E., Triplett, J.L., Hassall, L.M., Conde, Z.J.: Embodied social pres- ence theory. In: 2010 43rd Hawaii International Conference on System Sciences. pp. 1–10 (2010).https://doi.org/10.1109/HICSS.2010.179
- [25]
-
[26]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Ng, E., Joo, H., Hu, L., Li, H., Darrell, T., Kanazawa, A., Ginosar, S.: Learning to listen: Modeling non-deterministic dyadic facial motion. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 20395–20405 (June 2022)
2022
-
[27]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Peebles, W., Xie, S.: Scalable diffusion models with transformers. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 4195– 4205 (October 2023)
2023
-
[28]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Peng, Z., Fan, Y., Wu, H., Wang, X., Liu, H., He, J., Fan, Z.: DualTalk: Dual- Speaker Interaction for 3D Talking Head Conversations. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21055– 21064 (2025)
2025
-
[29]
In: Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) (2018)
Perez, E., Strub, F., de Vries, H., Dumoulin, V., Courville, A.: Film: Visual rea- soning with a general conditioning layer. In: Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) (2018)
2018
-
[30]
https://doi.org/10.48550/arXiv.2312.02069
Qian, S., Kirschstein, T., Schoneveld, L., Davoli, D., Giebenhain, S., Nießner, M.: GaussianAvatars: Photorealistic Head Avatars with Rigged 3D Gaussians (2024). https://doi.org/10.48550/arXiv.2312.02069
-
[31]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Richard, A., Zollh¨ ofer, M., Wen, Y., et al.: Meshtalk: 3d face animation from speech using cross-modality disentanglement. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 1173–1182 (2021)
2021
-
[32]
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition (2015),https://arxiv.org/abs/1409.1556
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[33]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Siyao, L., Yu, W., Gu, T., et al.: Bailando: 3d dance generation by actor-critic gpt with choreographic memory. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 11050–11059 (2022)
2022
-
[34]
Neurocomputing (2024) EmbodiedHead 17
Su, J., Lu, Y., Pan, S., Murtadha, A., Wen, B., Liu, Y.: Roformer: Enhanced transformer with rotary position embedding. Neurocomputing (2024) EmbodiedHead 17
2024
-
[35]
Sun, Z., Lv, T., Ye, S., Lin, M., Sheng, J., Wen, Y.H., Yu, M., Liu, Y.J.: Diff- PoseTalk: Speech-Driven Stylistic 3D Facial Animation and Head Pose Generation via Diffusion Models (2024).https://doi.org/10.48550/arXiv.2310.00434
-
[36]
In: Proceedings of the 29th ACM International Conference on Multimedia
Tao, R., Pan, Z., Das, R.K., Qian, X., Shou, M.Z., Li, H.: Is someone speak- ing? exploring long-term temporal features for audio-visual active speaker detec- tion. In: Proceedings of the 29th ACM International Conference on Multimedia. p. 3927–3935. MM ’21, Association for Computing Machinery, New York, NY, USA (2021).https://doi.org/10.1145/3474085.3475...
-
[37]
In: Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L.u., Polosukhin, I.: Attention is all you need. In: Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R. (eds.) Advances in Neural Information Processing Systems. vol. 30. Curran Associates, Inc. (2017),https://proceedings.neurips....
2017
-
[38]
IEEE Transactions on Image Processing13(4), 600–612 (2004)
Wang, Z., Bovik, A.C., Sheikh, H.R., et al.: Image quality assessment: from error visibility to structural similarity. IEEE Transactions on Image Processing13(4), 600–612 (2004)
2004
-
[39]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops
Xie, L., Wang, X., Zhang, H., Dong, C., Shan, Y.: Vfhq: A high-quality dataset and benchmark for video face super-resolution. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops. pp. 657–666 (June 2022)
2022
-
[40]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Xing, J., Xia, M., Zhang, Y., Cun, X., Wang, J., Wong, T.T.: Codetalker: Speech- driven 3d facial animation with discrete motion prior. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 12780–12790 (June 2023)
2023
-
[41]
ACM computing surveys56(4), 1–39 (2023)
Yang, L., Zhang, Z., Song, Y., Hong, S., Xu, R., Zhao, Y., Zhang, W., Cui, B., Yang, M.H.: Diffusion models: A comprehensive survey of methods and applications. ACM computing surveys56(4), 1–39 (2023)
2023
-
[42]
Zanon Boito, M., Iyer, V., Lagos, N., Besacier, L., Calapodescu, I.: mHuBERT- 147: A Compact Multilingual HuBERT Model. In: Interspeech 2024. pp. 3939–3943 (2024).https://doi.org/10.21437/Interspeech.2024-938
-
[43]
In: The Thirty- ninth Annual Conference on Neural Information Processing Systems (2025)
Zhang, L., Cai, S., Li, M., Wetzstein, G., Agrawala, M.: Frame context packing and drift prevention in next-frame-prediction video diffusion models. In: The Thirty- ninth Annual Conference on Neural Information Processing Systems (2025)
2025
-
[44]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Zhang, R., Isola, P., Efros, A.A., et al.: The unreasonable effectiveness of deep fea- tures as a perceptual metric. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 586–595 (2018)
2018
-
[45]
Zhu, L., Lin, L., Zhu, Y., Wu, J., Hou, X., Li, Y., Liu, Y., Chen, J.: MANGO:Natural Multi-speaker 3D Talking Head Generation via 2D-Lifted En- hancement (2026).https://doi.org/10.48550/arXiv.2601.01749
-
[46]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Zhu, Y., Zhang, L., Rong, Z., Hu, T., Liang, S., Ge, Z.: Infp: Audio-driven inter- active head generation in dyadic conversations. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 10667– 10677 (June 2025) 18 Y. Zhang et al. EmbodiedHead: Real-Time Listening and Speaking Avatar for Conversational Agents Supp...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.