Recognition: unknown
Beyond the Basics: Leveraging Large Language Model for Fine-Grained Medical Entity Recognition
Pith reviewed 2026-05-10 06:49 UTC · model grok-4.3
The pith
Fine-tuning LLaMA3 with LoRA on 18 detailed categories reaches 81.24% F1 for medical entity recognition in clinical notes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
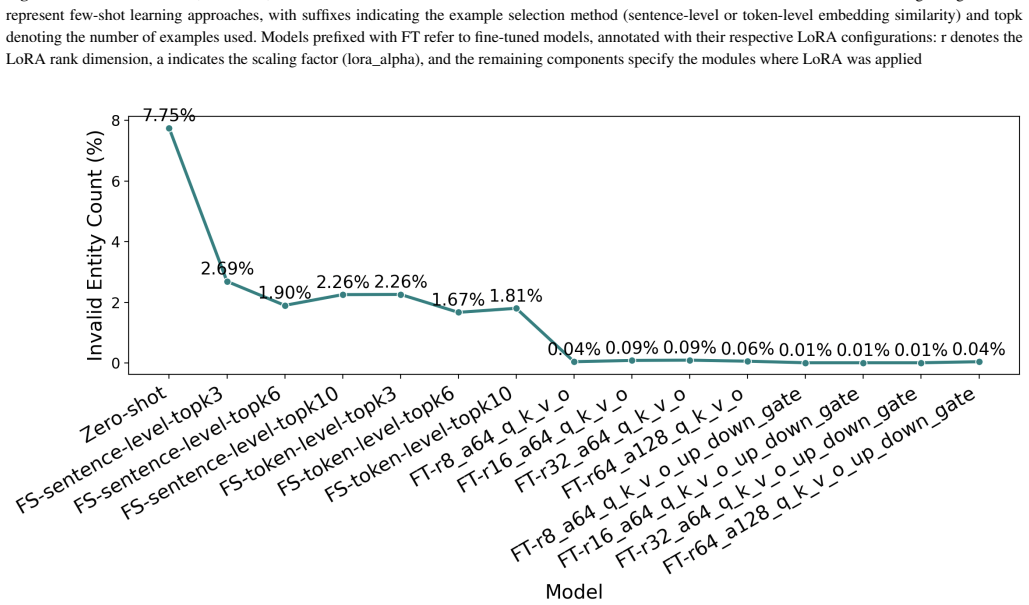
Fine-tuned LLaMA3 surpasses zero-shot and few-shot approaches by 63.11% and 35.63%, respectively, achieving an F1 score of 81.24% in granular medical entity extraction. The work applies all three learning paradigms consistently to one LLaMA3 backbone while introducing token- and sentence-level BioBERT embedding similarity for better few-shot example selection.
What carries the argument
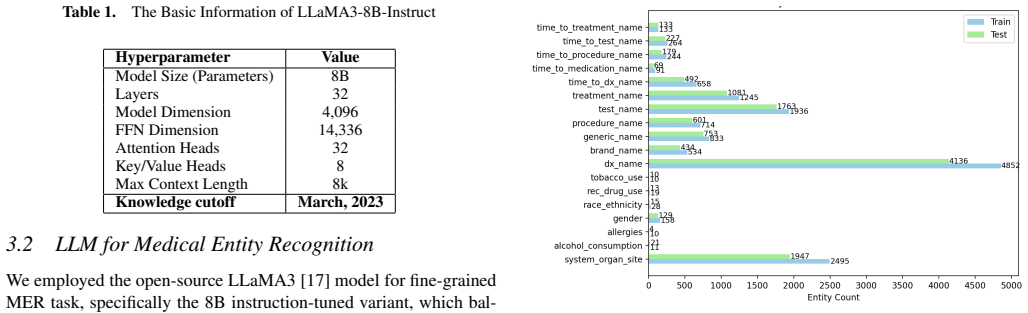
Fine-tuning LLaMA3 via Low-Rank Adaptation (LoRA) on a dataset annotated with 18 granular clinical entity categories, which teaches the model precise distinctions that zero-shot and few-shot prompting alone fail to capture.
If this is right
- Open-source LLMs become viable for high-precision extraction of detailed clinical concepts without proprietary models.
- Consistent backbone use across learning methods produces reliable head-to-head performance comparisons.
- BioBERT-based embedding similarity improves few-shot example selection for medical text.
- Granular entity extraction becomes more feasible for processing real admission notes and discharge summaries.
Where Pith is reading between the lines
- Hospitals could run similar fine-tuned models locally to process internal notes without external data transfer.
- The same fine-tuning recipe could transfer to other text domains that need fine-grained entity labels.
- Pairing the approach with longer context handling might improve results on extended documents.
Load-bearing premise
The 18 categories and the underlying dataset of clinical notes represent the variety and style found in real hospital records, so performance will hold when applied elsewhere.
What would settle it
Apply the fine-tuned model to clinical notes from a different hospital system and measure whether the F1 score stays near 81.24% or drops substantially.
Figures





read the original abstract
Extracting clinically relevant information from unstructured medical narratives such as admission notes, discharge summaries, and emergency case histories remains a challenge in clinical natural language processing (NLP). Medical Entity Recognition (MER) identifies meaningful concepts embedded in these records. Recent advancements in large language models (LLMs) have shown competitive MER performance; however, evaluations often focus on general entity types, offering limited utility for real-world clinical needs requiring finer-grained extraction. To address this gap, we rigorously evaluated the open-source LLaMA3 model for fine-grained medical entity recognition across 18 clinically detailed categories. To optimize performance, we employed three learning paradigms: zero-shot, few-shot, and fine-tuning with Low-Rank Adaptation (LoRA). To further enhance few-shot learning, we introduced two example selection methods based on token- and sentence-level embedding similarity, utilizing a pre-trained BioBERT model. Unlike prior work assessing zero-shot and few-shot performance on proprietary models (e.g., GPT-4) or fine-tuning different architectures, we ensured methodological consistency by applying all strategies to a unified LLaMA3 backbone, enabling fair comparison across learning settings. Our results showed that fine-tuned LLaMA3 surpasses zero-shot and few-shot approaches by 63.11% and 35.63%, respectivel respectively, achieving an F1 score of 81.24% in granular medical entity extraction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates the open-source LLaMA3 model for fine-grained medical entity recognition across 18 clinically detailed categories extracted from clinical notes. It compares three paradigms—zero-shot prompting, few-shot prompting with token- and sentence-level similarity selection via BioBERT, and parameter-efficient fine-tuning with LoRA—while keeping the underlying model fixed for methodological consistency. The central claim is that fine-tuned LLaMA3 reaches an F1 score of 81.24%, outperforming zero-shot by 63.11% and few-shot by 35.63%.
Significance. If substantiated, the work demonstrates that LoRA-based fine-tuning on a single open-source LLM backbone can deliver substantial gains over in-context learning for granular clinical entity extraction, a setting where prior studies often mix model families. The embedding-based few-shot selection methods provide a concrete, reproducible enhancement to prompting strategies. This contributes a controlled empirical comparison that is useful for practitioners choosing between prompting and tuning in medical NLP.
major comments (3)
- [Experimental Setup] The Experimental Setup section provides no dataset size, train/test split ratios, source of the clinical notes, annotation guidelines, or inter-annotator agreement statistics. These omissions are load-bearing because the reported F1 of 81.24% and the relative improvements cannot be assessed for robustness or reproducibility without them.
- [Results] In the Results section, absolute baseline F1 scores, confidence intervals, and any statistical significance tests (e.g., paired t-test or McNemar) for the 63.11% and 35.63% improvements are absent. This prevents evaluation of whether the margins are reliable or practically meaningful.
- [Introduction and Discussion] The paper assumes the 18 custom categories and test notes are representative of real-world clinical documentation, yet no external validation corpus, multi-site data, or mapping to standard resources (UMLS/SNOMED) is provided. This assumption directly underpins the general claim that fine-tuning is superior for the task.
minor comments (3)
- [Abstract] Abstract contains the repeated fragment 'respectivel respectively'; correct to 'respectively'.
- [Methods] The exact number of few-shot examples and the similarity threshold values used in the BioBERT-based selection methods are not stated, limiting reproducibility.
- A summary table listing the 18 entity categories with brief definitions and example spans would improve clarity and allow readers to judge category granularity.
Simulated Author's Rebuttal
Thank you for the constructive and detailed feedback on our manuscript. We have reviewed each major comment carefully and provide point-by-point responses below. We will incorporate revisions to address the concerns raised regarding reproducibility, statistical rigor, and generalizability.
read point-by-point responses
-
Referee: [Experimental Setup] The Experimental Setup section provides no dataset size, train/test split ratios, source of the clinical notes, annotation guidelines, or inter-annotator agreement statistics. These omissions are load-bearing because the reported F1 of 81.24% and the relative improvements cannot be assessed for robustness or reproducibility without them.
Authors: We agree that these details are essential for reproducibility and assessing robustness. In the revised manuscript, we will expand the Experimental Setup section with the total number of clinical notes and annotated entities, the exact train/test split ratios used, the source of the notes (including any institutional or public origin), the annotation guidelines followed, and inter-annotator agreement statistics. This will directly support evaluation of the reported F1 scores and improvements. revision: yes
-
Referee: [Results] In the Results section, absolute baseline F1 scores, confidence intervals, and any statistical significance tests (e.g., paired t-test or McNemar) for the 63.11% and 35.63% improvements are absent. This prevents evaluation of whether the margins are reliable or practically meaningful.
Authors: We acknowledge the need for absolute values and statistical support. We will update the Results section to present absolute F1 scores for zero-shot, few-shot, and fine-tuned settings in a consolidated table. We will also add bootstrap-derived confidence intervals for the F1 metrics and report results from appropriate statistical tests (e.g., McNemar's test on paired predictions) to establish the significance of the 63.11% and 35.63% relative improvements. revision: yes
-
Referee: [Introduction and Discussion] The paper assumes the 18 custom categories and test notes are representative of real-world clinical documentation, yet no external validation corpus, multi-site data, or mapping to standard resources (UMLS/SNOMED) is provided. This assumption directly underpins the general claim that fine-tuning is superior for the task.
Authors: We recognize this limitation on generalizability. Our categories were designed to capture clinically actionable fine-grained distinctions not addressed by standard coarse-grained schemas. In the revised Introduction and Discussion, we will explicitly state this scope, provide a high-level mapping of our categories to relevant UMLS/SNOMED concepts where overlaps exist, and discuss the absence of multi-site or external validation as a limitation with suggested directions for future work. The controlled comparison across paradigms on a single backbone remains a core, reproducible contribution. revision: partial
Circularity Check
No circularity: purely empirical comparison on fixed dataset
full rationale
The paper conducts an empirical evaluation of zero-shot, few-shot (with embedding-based example selection), and LoRA fine-tuning on LLaMA3 for 18 custom medical entity categories. No equations, derivations, or first-principles claims appear; performance numbers (F1 81.24%, relative gains) are direct outputs of standard train/test splits and metrics on the authors' dataset. No self-definitional loops, fitted parameters renamed as predictions, or load-bearing self-citations reduce the central claim to its inputs. The work is self-contained as an experimental benchmark.
Axiom & Free-Parameter Ledger
free parameters (2)
- LoRA rank and scaling factors
- Number of few-shot examples and similarity threshold
axioms (2)
- domain assumption The 18 categories capture clinically relevant distinctions that matter for downstream tasks
- domain assumption Embedding similarity from BioBERT selects useful examples for few-shot prompting
Reference graph
Works this paper leans on
-
[1]
Nucleic Acids Research , author =
O. Bodenreider. The Unified Medical Language System (UMLS): in- tegrating biomedical terminology.Nucleic Acids Research, 32(90001): 267D–270, Jan. 2004. ISSN 1362-4962. doi: 10.1093/nar/gkh061. URL https://academic.oup.com/nar/article-lookup/doi/10.1093/nar/gkh061
-
[2]
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert- V oss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Am...
work page internal anchor Pith review arXiv 2020
-
[3]
D. Capurro, M. Y . PhD, E. van Eaton, R. Black, and P. Tarczy-Hornoch. Availability of Structured and Unstructured Clinical Data for Compara- tive Effectiveness Research and Quality Improvement: A Multisite As- sessment.EGEMS, 2(1):1079, July 2014. ISSN 2327-9214. doi: Figure 6.Overall F1-Score, Precision, and Recall Across Different Models. The numbers i...
-
[4]
Devlin, M.-W
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, May
-
[5]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
URL http://arxiv.org/abs/1810.04805. arXiv:1810.04805 [cs]
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Q. Dong, L. Li, D. Dai, C. Zheng, J. Ma, R. Li, H. Xia, J. Xu, Z. Wu, T. Liu, B. Chang, X. Sun, L. Li, and Z. Sui. A Survey on In-context Learning, Oct. 2024. URL http://arxiv.org/abs/2301.00234. arXiv:2301.00234 [cs]
work page internal anchor Pith review arXiv 2024
- [7]
-
[8]
Y . Gu, R. Tinn, H. Cheng, M. Lucas, N. Usuyama, X. Liu, T. Naumann, J. Gao, and H. Poon. Domain-Specific Language Model Pretraining for Biomedical Natural Language Processing.ACM Transactions on Com- puting for Healthcare, 3(1):1–23, Jan. 2022. ISSN 2691-1957, 2637-
2022
-
[9]
Sylvie Gibet and Pierre-François Marteau
doi: 10.1145/3458754. URL http://arxiv.org/abs/2007.15779. arXiv:2007.15779 [cs]
-
[10]
S. Hochreiter and J. Schmidhuber. Long Short-Term Memory.Neural Computation, 9(8):1735–1780, Nov. 1997. ISSN 0899-7667. doi: 10. Figure 8.Per-Entity F1 Score (Selected Models) 1162/neco.1997.9.8.1735. URL https://doi.org/10.1162/neco.1997.9.8. 1735
-
[11]
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen. LoRA: Low-Rank Adaptation of Large Language Models, Oct. 2021. URL http://arxiv.org/abs/2106.09685. arXiv:2106.09685 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[12]
Y . Hu, Q. Chen, J. Du, X. Peng, V . K. Keloth, X. Zuo, Y . Zhou, Z. Li, X. Jiang, Z. Lu, K. Roberts, and H. Xu. Improving large language models for clinical named entity recognition via prompt engineering. Journal of the American Medical Informatics Association, 31(9):1812– 1820, Sept. 2024. ISSN 1527-974X. doi: 10.1093/jamia/ocad259. URL https://doi.org...
-
[13]
Y . Hu, X. Zuo, Y . Zhou, X. Peng, J. Huang, V . K. Keloth, V . J. Zhang, R.-L. Weng, Q. Chen, X. Jiang, K. E. Roberts, and H. Xu. Informa- tion Extraction from Clinical Notes: Are We Ready to Switch to Large Language Models?, Jan. 2025. URL http://arxiv.org/abs/2411.10020. arXiv:2411.10020 [cs]
-
[14]
arXiv preprint arXiv:1508.01991 (2015)
Z. Huang, W. Xu, and K. Yu. Bidirectional LSTM-CRF Models for Sequence Tagging, Aug. 2015. URL http://arxiv.org/abs/1508.01991. arXiv:1508.01991 [cs]
-
[15]
P. B. Jensen, L. J. Jensen, and S. Brunak. Mining electronic health records: towards better research applications and clinical care.Nature Reviews Genetics, 13(6):395–405, June 2012. ISSN 1471-0064. doi: 10.1038/nrg3208. URL https://www.nature.com/articles/nrg3208. Pub- lisher: Nature Publishing Group
-
[16]
Lafferty, A
J. Lafferty, A. McCallum, and F. Pereira. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data. Nov. 1997
1997
-
[17]
J. Lee, W. Yoon, S. Kim, D. Kim, S. Kim, C. H. So, and J. Kang. BioBERT: a pre-trained biomedical language representation model for biomedical text mining.Bioinformatics, 36(4):1234–1240, Feb
-
[18]
BioBERT: a pre-trained biomedical language representation model for biomedical text mining,
ISSN 1367-4803, 1367-4811. doi: 10.1093/bioinformatics/ btz682. URL https://academic.oup.com/bioinformatics/article/36/4/ 1234/5566506
-
[19]
Y . Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V . Stoyanov. RoBERTa: A Robustly Optimized BERT Pretraining Approach, July 2019. URL http://arxiv.org/abs/1907. 11692. arXiv:1907.11692 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[20]
Meta. The Llama 3 Herd of Models, Nov. 2024. URL http://arxiv.org/ abs/2407.21783. arXiv:2407.21783 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
P. M. Nadkarni, L. Ohno-Machado, and W. W. Chapman. Natural lan- guage processing: an introduction.Journal of the American Medi- cal Informatics Association, 18(5):544–551, Sept. 2011. ISSN 1067-
2011
-
[22]
doi: 10.1136/amiajnl-2011-000464. URL https://doi.org/10. 1136/amiajnl-2011-000464
-
[23]
Nakayama, T
H. Nakayama, T. Kubo, J. Kamura, Y . Taniguchi, and X. Liang. doc- cano: Text Annotation Tool for Human, 2018. URL https://github.com/ doccano/doccano
2018
-
[24]
OpenAI. GPT-4 Technical Report, Mar. 2024. URL http://arxiv.org/ abs/2303.08774. arXiv:2303.08774 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Pradhan, A
S. Pradhan, A. Moschitti, N. Xue, H. T. Ng, A. Björkelund, O. Uryupina, Y . Zhang, and Z. Zhong. Towards Robust Linguistic Analysis using OntoNotes. In J. Hockenmaier and S. Riedel, editors, Proceedings of the Seventeenth Conference on Computational Natural Language Learning, pages 143–152, Sofia, Bulgaria, Aug. 2013. As- sociation for Computational Lingu...
2013
-
[26]
S. Raza, D. J. Reji, F. Shajan, and S. R. Bashir. Large-scale application of named entity recognition to biomedicine and epidemiology.PLOS Digital Health, 1(12):e0000152, Dec. 2022. ISSN 2767-3170. doi: 10. 1371/journal.pdig.0000152. URL https://www.ncbi.nlm.nih.gov/pmc/ articles/PMC9931203/
2022
-
[27]
E. F. T. K. Sang and F. D. Meulder. Introduction to the CoNLL-2003 Shared Task: Language-Independent Named Entity Recognition, June
2003
-
[28]
Introduction to the CoNLL-2003 Shared Task: Language-Independent Named Entity Recognition
URL http://arxiv.org/abs/cs/0306050. arXiv:cs/0306050
work page internal anchor Pith review arXiv
-
[29]
1997, IEEE Transactions on Signal Processing, 45, 2673, doi: 10.1109/78.650093
M. Schuster and K. Paliwal. Bidirectional recurrent neural net- works.IEEE Transactions on Signal Processing, 45(11):2673–2681, Nov. 1997. ISSN 1053587X. doi: 10.1109/78.650093. URL http: //ieeexplore.ieee.org/document/650093/
-
[30]
W. Sun, A. Rumshisky, and O. Uzuner. Evaluating temporal rela- tions in clinical text: 2012 i2b2 Challenge.Journal of the Ameri- can Medical Informatics Association : JAMIA, 20(5):806–813, Sept
2012
-
[31]
doi: 10.1136/amiajnl-2013-001628
ISSN 1067-5027. doi: 10.1136/amiajnl-2013-001628. URL https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3756273/
- [32]
- [33]
- [34]
- [35]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.