Recognition: unknown
LASER: Low-Rank Activation SVD for Efficient Recursion
Pith reviewed 2026-05-10 07:08 UTC · model grok-4.3
The pith
Recursive models can compress activations in a low-dimensional subspace to cut memory use by 60 percent with no accuracy loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We find that activations in recursive architectures occupy an effectively linear, low-dimensional subspace whose principal directions can be tracked dynamically with cheap power iterations. We exploit this through LASER, a dynamic compression framework that maintains an evolving low-rank basis via matrix-free subspace tracking with a fidelity-triggered reset mechanism, achieving ~60% activation memory savings with no statistically significant accuracy degradation.
What carries the argument
LASER, the Low-Rank Activation SVD for Efficient Recursion framework, which maintains an evolving low-rank basis of activations through matrix-free power iterations for subspace tracking and applies compression with fidelity-triggered resets.
Load-bearing premise
The low-rank subspace remains stable enough between fidelity-triggered resets that the compression does not accumulate error that affects final task performance.
What would settle it
Applying LASER compression to the evaluated recursive models and measuring a statistically significant accuracy drop on the original tasks, or finding that fidelity resets are required at every recursion step so that net memory savings vanish.
Figures



read the original abstract
Recursive architectures such as Tiny Recursive Models (TRMs) perform implicit reasoning through iterative latent computation, yet the geometric structure of these reasoning trajectories remains poorly understood. We investigate the activation manifold of TRMs during recursive unrolling and find that activations occupy an effectively linear, low-dimensional subspace whose principal directions can be tracked dynamically with cheap power iterations. This suggests that weight-sharing concentrates iterative computation along a small number of dominant eigendirections, and we find that this concentration varies sharply across computational sites. We exploit this structure through LASER (Low-Rank Activation SVD for Efficient Recursion), a dynamic compression framework that maintains an evolving low-rank basis via matrix-free subspace tracking with a fidelity-triggered reset mechanism, achieving ${\sim}60\%$ activation memory savings with no statistically significant accuracy degradation. Our analysis raises questions about how recursive architectures allocate representational capacity during implicit reasoning, and whether this concentration can be exploited to improve the efficiency and stability of latent computation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that activations in Tiny Recursive Models (TRMs) occupy an effectively linear low-dimensional subspace whose principal directions can be tracked dynamically via matrix-free power iterations. It introduces LASER, a dynamic compression framework that maintains an evolving low-rank basis with a fidelity-triggered reset, achieving ~60% activation memory savings with no statistically significant accuracy degradation.
Significance. If the central empirical claim holds under rigorous validation, the work could meaningfully improve the memory efficiency of recursive architectures by exploiting observed geometric concentration in latent trajectories. It also raises interesting questions about representational capacity allocation during implicit reasoning. However, the current lack of experimental protocols, quantitative stability analysis, and statistical rigor substantially limits its assessed significance.
major comments (2)
- [Abstract] Abstract: The abstract states the memory saving and accuracy result but supplies no experimental details, baselines, error bars, dataset sizes, or statistical tests; without these the central efficiency claim cannot be evaluated.
- [The manuscript] The manuscript: The low-rank subspace stability between fidelity resets lacks quantitative validation against error accumulation; no bounds on approximation error growth between resets nor measurements of observed reset frequency as a function of recursion depth or task are supplied, leaving the weakest assumption untested.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. The comments identify areas where additional detail and validation would strengthen the presentation of LASER. We address each major comment below and indicate the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states the memory saving and accuracy result but supplies no experimental details, baselines, error bars, dataset sizes, or statistical tests; without these the central efficiency claim cannot be evaluated.
Authors: We agree that the abstract would benefit from greater specificity to allow readers to evaluate the central claims. In the revised manuscript we will expand the abstract to name the recursive reasoning benchmarks used, report the number of independent runs and error bars, reference the baselines, and note the statistical tests confirming no significant accuracy degradation. Abstract length constraints will be respected by focusing on the most essential elements. revision: yes
-
Referee: [The manuscript] The manuscript: The low-rank subspace stability between fidelity resets lacks quantitative validation against error accumulation; no bounds on approximation error growth between resets nor measurements of observed reset frequency as a function of recursion depth or task are supplied, leaving the weakest assumption untested.
Authors: This observation correctly identifies a gap in the current validation of the core assumption. The manuscript shows that end-to-end accuracy is preserved but does not supply direct measurements of subspace drift or reset statistics. In the revision we will add an analysis subsection that reports empirical reset frequencies as a function of recursion depth and task, together with observed approximation error growth between resets. We will also provide empirical bounds on error accumulation derived from the collected activation trajectories. Deriving general theoretical bounds may require additional distributional assumptions that are not yet justified by the data; if such bounds cannot be obtained without further work we will clearly state this limitation. revision: partial
Circularity Check
No circularity: empirical method grounded in observed geometry, not derived from fitted inputs or self-citations
full rationale
The manuscript describes an empirical investigation of activation manifolds in recursive models, followed by a practical compression technique (LASER) using matrix-free power iterations and fidelity-triggered resets. No equations, derivations, or first-principles predictions are presented that reduce the claimed memory savings or accuracy preservation to fitted parameters, self-definitions, or prior self-citations by construction. The central performance claims rest on experimental measurements rather than analytical reductions that would be tautological with the inputs. This is the most common honest finding for applied compression papers that do not attempt to derive their results from first principles.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Activations occupy an effectively linear low-dimensional subspace
Reference graph
Works this paper leans on
-
[1]
Jianfei Chen, Lianmin Zheng, Zhewei Yao, Dequan Wang, Ion Stoica, Michael W
URLhttps://arxiv.org/abs/2509.21617. Jianfei Chen, Lianmin Zheng, Zhewei Yao, Dequan Wang, Ion Stoica, Michael W. Mahoney, and Joseph E. Gonzalez. Actnn: Reducing training memory footprint via 2-bit activation compressed training,
-
[2]
URLhttps://arxiv.org/abs/2104.14129. Andrey Gromov, Kushal Tirumala, Hassan Shapourian, Paolo Glorioso, and Daniel A. Roberts. The unreasonable ineffectiveness of the deeper layers,
-
[3]
The unreasonable ineffectiveness of the deeper layers.arXiv preprint arXiv:2403.17887, 2024
URLhttps://arxiv.org/abs/ 2403.17887. Animesh Jain, Amar Phanishayee, Jason Mars, Lingjia Tang, and Gennady Pekhimenko. Gist: Efficient data encoding for deep neural network training. In2018 ACM/IEEE 45th Annual Inter- national Symposium on Computer Architecture (ISCA), pp. 776–789,
-
[4]
doi: 10.1109/ISCA. 2018.00070. Alexia Jolicoeur-Martineau. Less is more: Recursive reasoning with tiny networks,
-
[5]
Less is More: Recursive Reasoning with Tiny Networks
URL https://arxiv.org/abs/2510.04871. Sayed Muhsin, Hao Zhang, and Seokbum Ko. Gale: Gradient activation low-rank extraction for fast memory efficient large language model training,
work page internal anchor Pith review arXiv
- [6]
-
[7]
doi: 10.1109/78.365290. Rui-Jie Zhu, Zixuan Wang, Kai Hua, Tianyu Zhang, Ziniu Li, Haoran Que, Boyi Wei, Zixin Wen, Fan Yin, He Xing, Lu Li, Jiajun Shi, Kaijing Ma, Shanda Li, Taylor Kergan, Andrew Smith, Xingwei Qu, Mude Hui, Bohong Wu, Qiyang Min, Hongzhi Huang, Xun Zhou, Wei Ye, Jiaheng Liu, Jian Yang, Yunfeng Shi, Chenghua Lin, Enduo Zhao, Tianle Cai,...
-
[8]
URLhttps://arxiv.org/abs/2510.25741. 10 Published at Latent & Implicit Thinking Workshop @ ICLR 2026 A APPENDIX A.1 FIDELITYMETRICJUSTIFICATION We formally demonstrate thatF t is exactly equivalent to the cosine similarity between the original activations and their low-rank reconstruction, provided the basis is orthonormal. Proposition 1.LetX∈R N×D be the...
work page internal anchor Pith review arXiv 2026
-
[9]
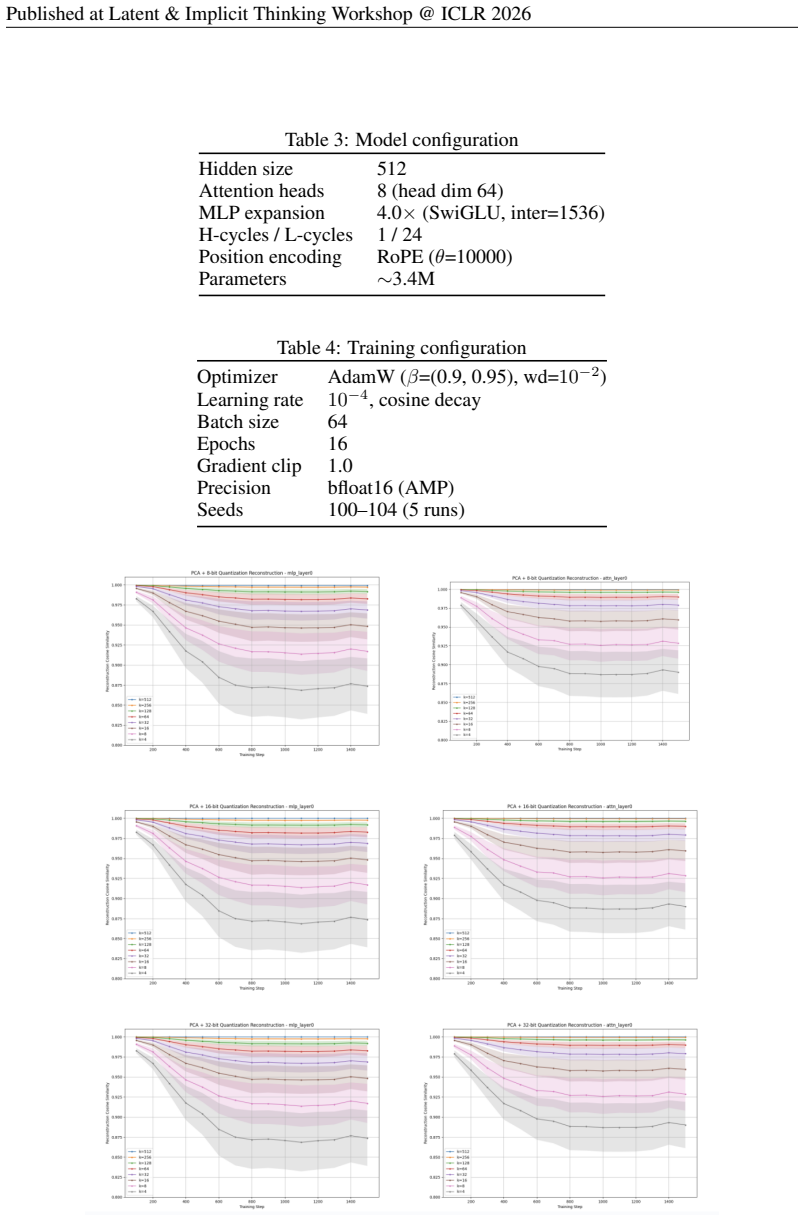
Rankk=128maintains>0.975 fidelity for the MLP activations throughout training, confirming rapid spectral decay
MLP expansion 4.0×(SwiGLU, inter=1536) H-cycles / L-cycles 1 / 24 Position encoding RoPE (θ=10000) Parameters∼3.4M Table 4: Training configuration Optimizer AdamW (β=(0.9, 0.95), wd=10 −2) Learning rate10 −4, cosine decay Batch size 64 Epochs 16 Gradient clip 1.0 Precision bfloat16 (AMP) Seeds 100–104 (5 runs) Figure 4: PCA reconstruction cosine similarit...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.