Recognition: unknown
A Rapid Deployment Pipeline for Autonomous Humanoid Grasping Based on Foundation Models
Pith reviewed 2026-05-10 06:12 UTC · model grok-4.3
The pith
Foundation models chain together to let a humanoid robot grasp new objects after roughly 30 minutes of preparation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
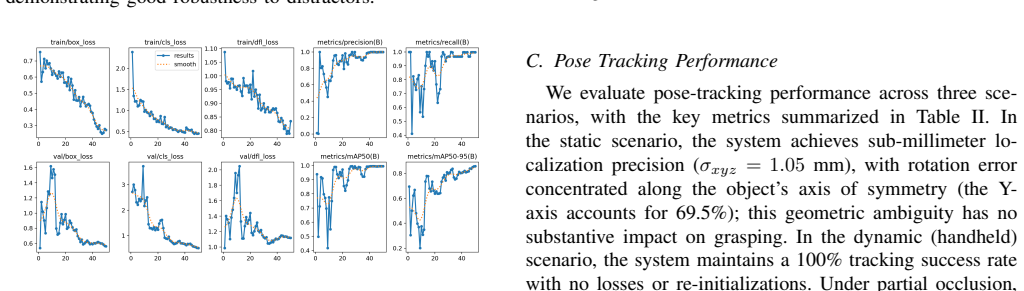
By wiring automatic annotation, image-based 3D reconstruction, and zero-shot pose estimation into one pipeline, the system compresses the onboarding time for a new object from one-to-two days down to about 30 minutes while still producing detection mAP@0.5 of 0.995, pose standard deviation below 1.05 mm, and repeatable real-robot grasps.
What carries the argument
The end-to-end pipeline that links Roboflow annotation, SAM 3D mesh generation, FoundationPose tracking, and Unity-based inverse kinematics to drive the humanoid without custom scanners or per-object training.
If this is right
- Object detection reaches mAP@0.5 = 0.995 after quick auto-annotation.
- Pose tracking maintains precision of σ < 1.05 mm across workspace positions.
- The robot executes successful grasps at five distinct locations.
- The same pipeline transfers to a non-grasping task such as automobile-window glue application.
- Everyday phone imagery replaces dedicated laser scanners for 3D model creation.
Where Pith is reading between the lines
- The method could let non-roboticists bring humanoids into small-batch or one-off tasks without hiring specialists for data labeling or model tuning.
- Further tests on moving objects or crowded scenes would reveal whether the current zero-shot tracking holds when the assumption of static, well-lit conditions is relaxed.
- As the underlying foundation models improve, the 30-minute figure may shrink further or extend to more dexterous two-handed operations.
Load-bearing premise
Zero-shot 6-DoF pose tracking stays accurate and stable for any new object under ordinary lighting and partial occlusion when the only template is the SAM 3D mesh.
What would settle it
A trial in which the FoundationPose tracker produces errors larger than 2 mm or loses lock on an object with specular highlights or heavy occlusion, causing the robot to miss the grasp.
Figures







read the original abstract
Deploying a humanoid robot to manipulate a new object has traditionally required one to two days of effort: data collection, manual annotation, 3D model acquisition, and model training. This paper presents an end-to-end rapid deployment pipeline that integrates three foundation-model components to shorten the onboarding cycle for a new object to approximately 30 minutes: (i) Roboflow-based automatic annotation to assist in training a YOLOv8 object detector; (ii) 3D reconstruction based on Meta SAM 3D, which eliminates the need for a dedicated laser scanner; and (iii) zero-shot 6-DoF pose tracking based on FoundationPose, using the SAM~3D-generated mesh directly as the template. The estimated pose drives a Unity-based inverse kinematics planner, whose joint commands are streamed via UDP to a Unitree~G1 humanoid and executed through the Unitree SDK. We demonstrate detection accuracy of mAP@0.5 = 0.995, pose tracking precision of $\sigma < 1.05$ mm, and successful grasping on a real robot at five positions within the workspace. We further verify the generality of the pipeline on an automobile-window glue-application task. The results show that combining foundation models for perception with everyday imaging devices (e.g., smartphones) can substantially lower the deployment barrier for humanoid manipulation tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce an end-to-end rapid deployment pipeline for humanoid robot grasping of new objects that integrates YOLOv8 detection (assisted by Roboflow annotation), Meta SAM 3D for mesh reconstruction from smartphone images, and FoundationPose for zero-shot 6-DoF pose tracking using the SAM-generated mesh as template. This is asserted to reduce onboarding time from 1-2 days to approximately 30 minutes, with the pose estimates driving Unity-based IK and real-time control on a Unitree G1 humanoid. Reported results include mAP@0.5 = 0.995 for detection, pose precision σ < 1.05 mm, successful grasps at five workspace positions, and verification on an automobile-window glue application task.
Significance. If the zero-shot components deliver reliable performance for arbitrary objects, the work could meaningfully lower barriers to humanoid deployment in manipulation tasks by replacing specialized hardware and lengthy training with foundation models and consumer imaging devices. The end-to-end integration of perception models with robot control is a practical contribution, though its impact depends on demonstrated generality beyond the limited cases shown.
major comments (2)
- [Abstract] Abstract: The central claim of ~30-minute onboarding for arbitrary new objects and the reported pose tracking precision (σ < 1.05 mm) with successful grasps at five positions rest on the assumption that FoundationPose will remain accurate using SAM 3D meshes as templates under real-world lighting, occlusion, and surface variations, but no evidence or analysis addresses degradation for non-Lambertian objects or partial views.
- [Results] Results (implied by metrics): The detection mAP@0.5 = 0.995, pose σ < 1.05 mm, and 5-position grasp success are presented without experimental protocol details, number of trials, object diversity, statistical variance, baseline comparisons to traditional pipelines, or failure-case analysis, preventing verification of the time-reduction and generality assertions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, indicating where revisions will be made to improve clarity, transparency, and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of ~30-minute onboarding for arbitrary new objects and the reported pose tracking precision (σ < 1.05 mm) with successful grasps at five positions rest on the assumption that FoundationPose will remain accurate using SAM 3D meshes as templates under real-world lighting, occlusion, and surface variations, but no evidence or analysis addresses degradation for non-Lambertian objects or partial views.
Authors: We agree that the manuscript would be strengthened by explicitly discussing the operating assumptions and limitations of combining SAM 3D meshes with FoundationPose. Our reported results were obtained in indoor settings with moderate lighting and objects that are predominantly Lambertian, including the automobile-window glue task that introduced some surface reflectivity. We did not perform a controlled ablation on highly specular or transparent surfaces nor on severe partial views. In the revision we will add a Limitations subsection that states these boundary conditions, reports any qualitative observations from our trials under varying illumination, and outlines future robustness improvements such as multi-view fusion or domain randomization. revision: yes
-
Referee: [Results] Results (implied by metrics): The detection mAP@0.5 = 0.995, pose σ < 1.05 mm, and 5-position grasp success are presented without experimental protocol details, number of trials, object diversity, statistical variance, baseline comparisons to traditional pipelines, or failure-case analysis, preventing verification of the time-reduction and generality assertions.
Authors: We concur that additional methodological detail is required for reproducibility and to substantiate the time-reduction and generality claims. The revised Results and Experimental Setup sections will specify: the exact protocol and timing breakdown for the 30-minute pipeline, the number of independent trials performed for detection and pose estimation together with standard deviations, the set of objects used (including those in the glue-application verification), and a concise failure-case analysis (e.g., loss-of-track events and recovery behavior). While the core contribution is the integrated rapid-deployment workflow rather than an exhaustive benchmark, we will add a short qualitative comparison to a conventional manual-annotation-plus-laser-scanner pipeline in terms of elapsed time and achieved accuracy, using data collected during our own development process. revision: yes
Circularity Check
No circularity: empirical integration of external foundation models
full rationale
The paper describes a systems integration pipeline that combines three pre-existing foundation models (YOLOv8, Meta SAM 3D, and FoundationPose) with off-the-shelf hardware and a Unity IK planner. No mathematical derivations, equations, or first-principles results are presented. No parameters are fitted to data subsets and then relabeled as predictions. No self-citations, uniqueness theorems, or ansatzes from prior author work are invoked to justify core claims. All reported outcomes (mAP@0.5 = 0.995, pose tracking σ < 1.05 mm, five-position grasping success) are empirical measurements from real-robot trials on specific objects and tasks. The derivation chain is therefore self-contained and consists solely of engineering assembly plus external model usage, producing no circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Foundation models (SAM 3D and FoundationPose) can produce accurate 3D meshes and zero-shot 6-DoF pose estimates for arbitrary new objects from ordinary images without fine-tuning.
Reference graph
Works this paper leans on
-
[1]
Segment Anything,
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W. Lo, P. Doll ´ar, and R. B. Gir- shick, “Segment Anything,” inProc. IEEE/CVF Int. Conf. Computer Vision (ICCV), 2023, pp. 3992–4003
2023
-
[2]
FoundationPose: Unified 6D pose estimation and tracking of novel objects,
B. Wen, W. Yang, J. Kautz, and S. T. Birchfield, “FoundationPose: Unified 6D pose estimation and tracking of novel objects,” inProc. IEEE/CVF Conf. Computer Vision and Pattern Recognition (CVPR), 2024, pp. 17868–17879
2024
-
[3]
SAM 3D: 3Dfy Anything in Images
X. Chen, F. J. Chu, P. Gleize, K. J. Liang, A. Sax, H. Tang,et al., and SAM 3D Team, “SAM 3D: 3Dfy anything in images,”arXiv preprint arXiv:2511.16624, 2025
work page internal anchor Pith review arXiv 2025
-
[4]
RT-2: Vision-language-action models transfer web knowledge to robotic control,
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia,et al., and K. Han, “RT-2: Vision-language-action models transfer web knowledge to robotic control,” inConf. Robot Learning (CoRL), PMLR, 2023, pp. 2165–2183
2023
-
[5]
OpenVLA: An Open-Source Vision-Language-Action Model
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, et al., and C. Finn, “OpenVLA: An open-source vision-language-action model,”arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review arXiv 2024
-
[6]
PoseCNN: A convolutional neural network for 6D object pose estimation in cluttered scenes,
Y . Xiang, T. Schmidt, V . Narayanan, and D. Fox, “PoseCNN: A convolutional neural network for 6D object pose estimation in cluttered scenes,”arXiv preprint arXiv:1711.00198, 2017
-
[7]
PVNet: Pixel-wise voting network for 6DoF object pose estimation,
S. Peng, X. Zhou, Y . Liu, H. Lin, Q. Huang, and H. Bao, “PVNet: Pixel-wise voting network for 6DoF object pose estimation,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 44, no. 6, pp. 3212–3223, Jun. 2022
2022
-
[8]
MegaPose: 6D pose estimation of novel objects via render & compare,
Y . Labb´e, L. Manuelli, A. Mousavian, S. Tyree, S. Birchfield, J. Trem- blay, J. Carpentier, M. Aubry, D. Fox, and J. Sivic, “MegaPose: 6D pose estimation of novel objects via render & compare,” inConf. Robot Learning (CoRL), 2022
2022
-
[9]
NeRF: Representing scenes as neural radiance fields for view synthesis,
B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoor- thi, and R. Ng, “NeRF: Representing scenes as neural radiance fields for view synthesis,”Commun. ACM, vol. 65, no. 1, pp. 99–106, 2021
2021
-
[10]
BundleSDF: Neural 6-DoF tracking and 3D reconstruction of unknown objects,
B. Wen, J. Tremblay, V . Blukis, S. Tyree, T. Muller, A. Evans, D. Fox, J. Kautz, and S. Birchfield, “BundleSDF: Neural 6-DoF tracking and 3D reconstruction of unknown objects,” inProc. IEEE/CVF Conf. Computer Vision and Pattern Recognition (CVPR), 2023, pp. 606–617
2023
-
[11]
M. Yaseen, “What is YOLOv8: An in-depth exploration of the in- ternal features of the next-generation object detector,”arXiv preprint arXiv:2408.15857, 2024
-
[12]
Generalizable humanoid manipulation with 3D diffusion policies,
Y . Ze, Z. Chen, W. Wang, T. Chen, X. He, Y . Yuan,et al., and J. Wu, “Generalizable humanoid manipulation with 3D diffusion policies,” inProc. IEEE/RSJ Int. Conf. Intelligent Robots and Systems (IROS), 2025, pp. 2873–2880
2025
-
[13]
X. Cheng, J. Li, S. Yang, G. Yang, and X. Wang, “Open-TeleVision: Teleoperation with immersive active visual feedback,”arXiv preprint arXiv:2407.01516, 2024
-
[14]
Domain randomization for transferring deep networks from simula- tion to the real world,
J. Tobin, R. Fong, A. Ray, J. Schneider, W. Zaremba, and P. Abbeel, “Domain randomization for transferring deep networks from simula- tion to the real world,” inProc. IEEE/RSJ Int. Conf. Intelligent Robots and Systems (IROS), 2017, pp. 23–30
2017
-
[15]
Intel RealSense stereoscopic depth cameras,
L. Keselman, J. I. Woodfill, A. Grunnet-Jepsen, and A. Bhowmik, “Intel RealSense stereoscopic depth cameras,” inProc. IEEE Conf. Computer Vision and Pattern Recognition Workshops (CVPRW), 2017, pp. 1–10
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.